
更新代码
Showing
GPT_pretraining.sh
deleted
100644 → 0
This diff is collapsed.
Llama_pretraining.sh
deleted
100644 → 0
This diff is collapsed.
{kind=link}
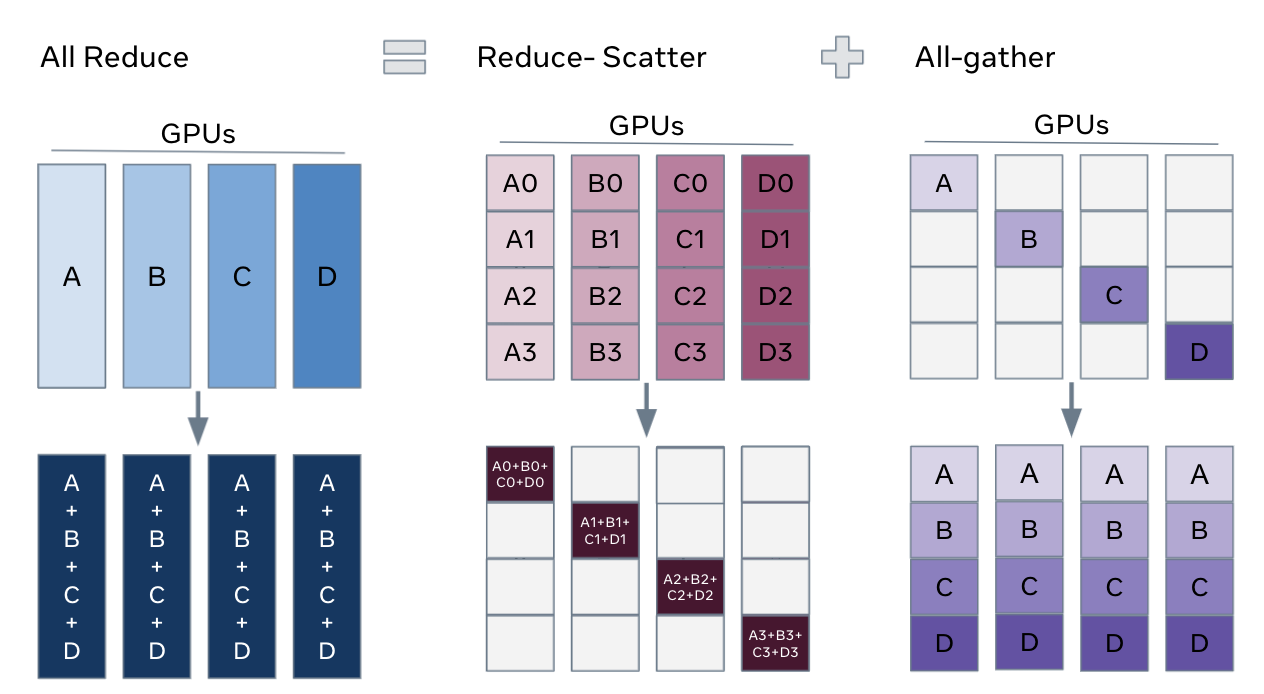
84.5 KB
{kind=link}
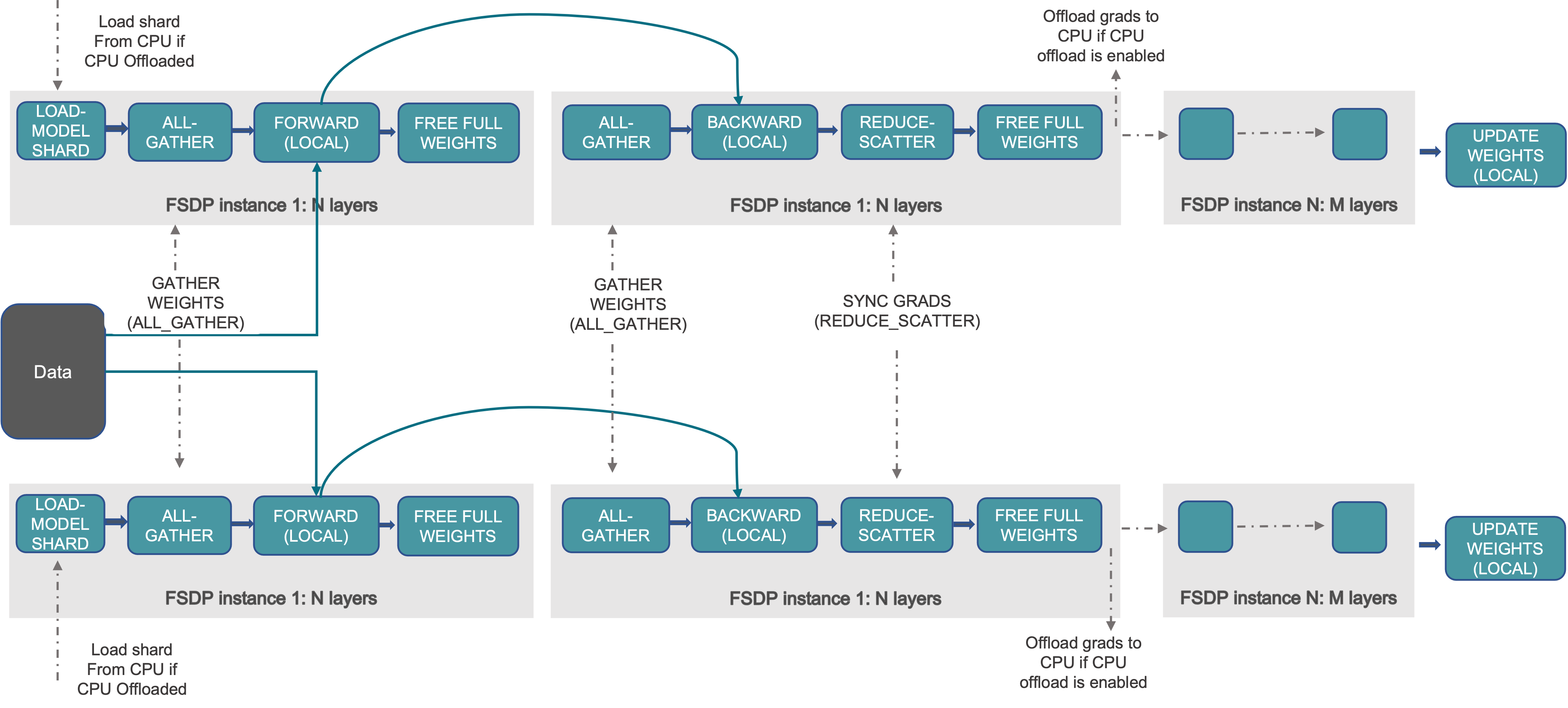
555 KB
{kind=link}

499 KB
File mode changed from 100644 to 100755
File mode changed from 100644 to 100755