For data parallel, no extra coding is needed. FastMoE works seamlessly with PyTorch's `DataParallel` or `DistributedDataParallel`.
For data parallel, no extra coding is needed. FastMoE works seamlessly with PyTorch's `DataParallel` or `DistributedDataParallel`.
The only drawback of data parallel is that the number of experts is constrained by each worker's memory.
The only drawback of data parallel is that the number of experts is constrained by each worker's memory.
#### Model Parallel
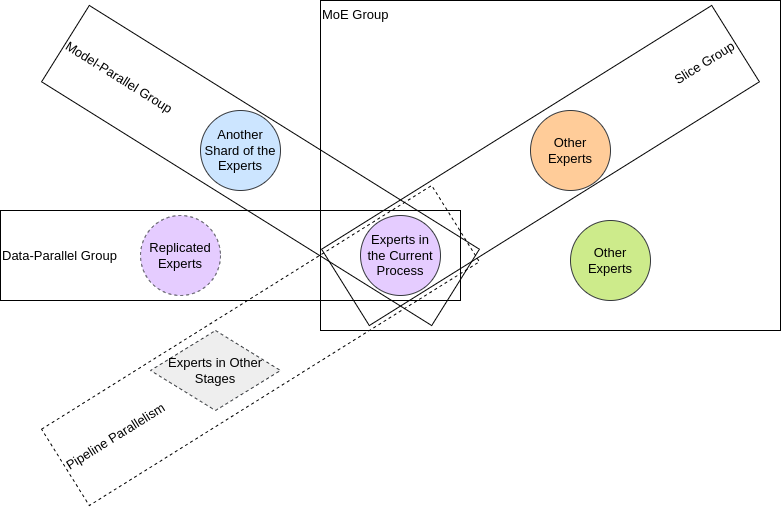
#### Expert Parallel (also called Model Parlallel in some previous versions)
In FastMoE's model parallel mode, the gate network is still replicated on each worker but
In FastMoE's expert parallel mode, the gate network is still replicated on each worker but
experts are placed separately across workers.
experts are placed separately across workers.
Thus, by introducing additional communication cost, FastMoE enjoys a large expert pool whose size is proportional to the number of workers.
Thus, by introducing additional communication cost, FastMoE enjoys a large expert pool whose size is proportional to the number of workers.
The following figure shows the forward pass of a 6-expert MoE with 2-way model parallel. Note that experts 1-3 are located in worker 1 while experts 4-6 are located in worker 2.
The following figure shows the forward pass of a 6-expert MoE with 2-way model parallel. Note that experts 1-3 are located in worker 1 while experts 4-6 are located in worker 2.

{kind=link}
{kind=link}
{kind=link}