
docs: Add documentation for Dynamo Architecture and key features (#207)
Showing
docs/architecture.md
0 → 100644
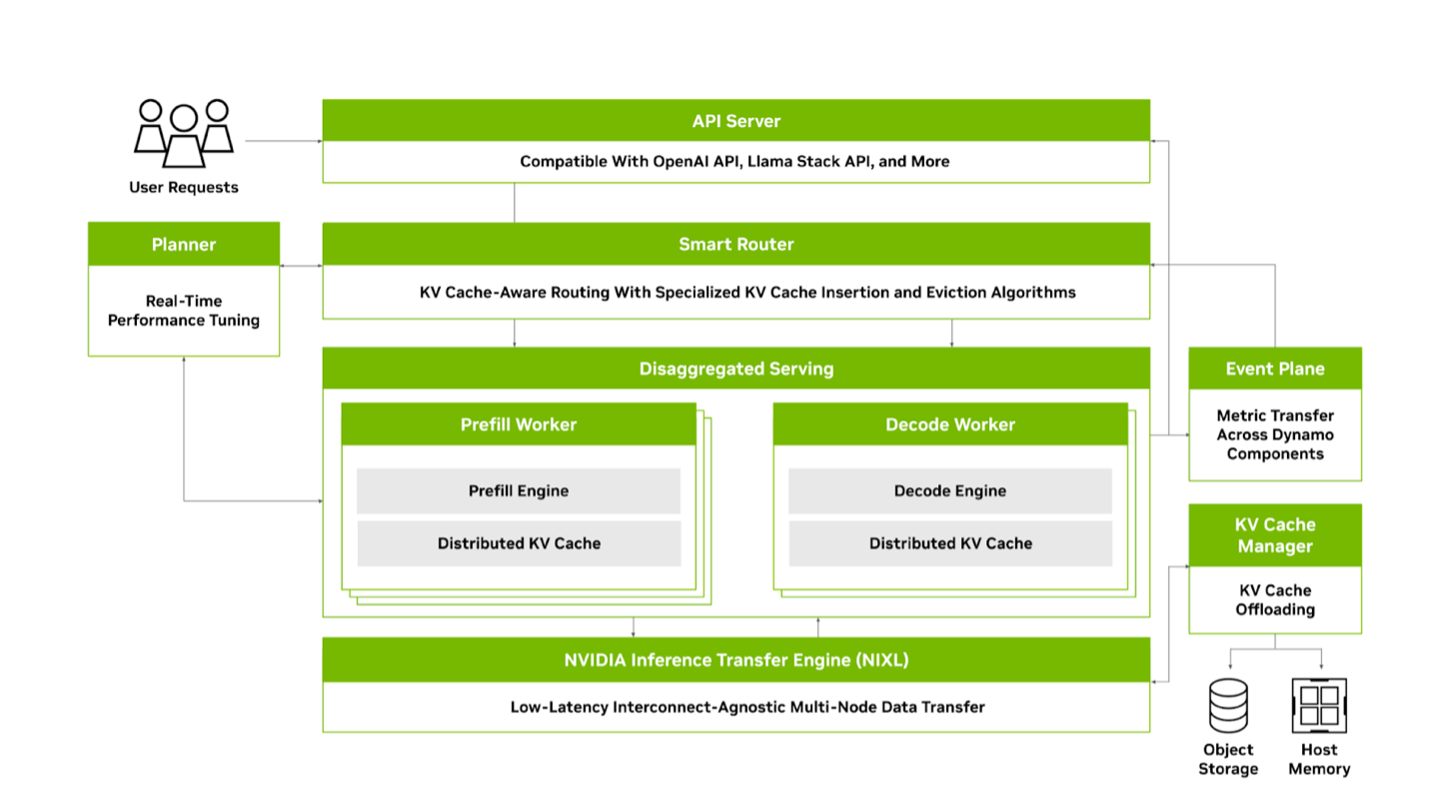
docs/images/architecture.png
0 → 100644
{kind=link}
184 KB
{kind=link}
55 KB
{kind=link}
40.8 KB
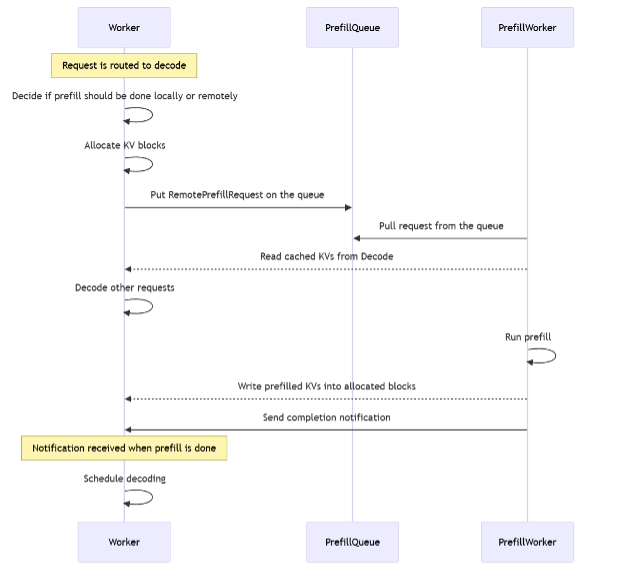
docs/images/kv_routing.png
0 → 100644
{kind=link}
147 KB
docs/images/kv_transfer.png
0 → 100644
{kind=link}
53 KB
docs/images/nixl.png
0 → 100644
{kind=link}
22.1 KB