
update capsule tutorials
Showing
{kind=link}
{kind=link}
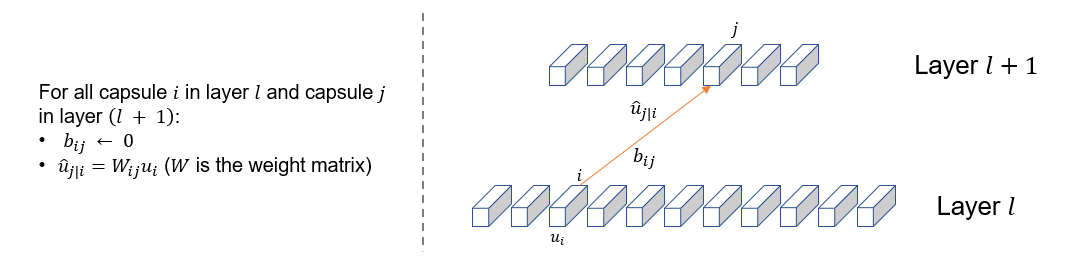
| W: | H:
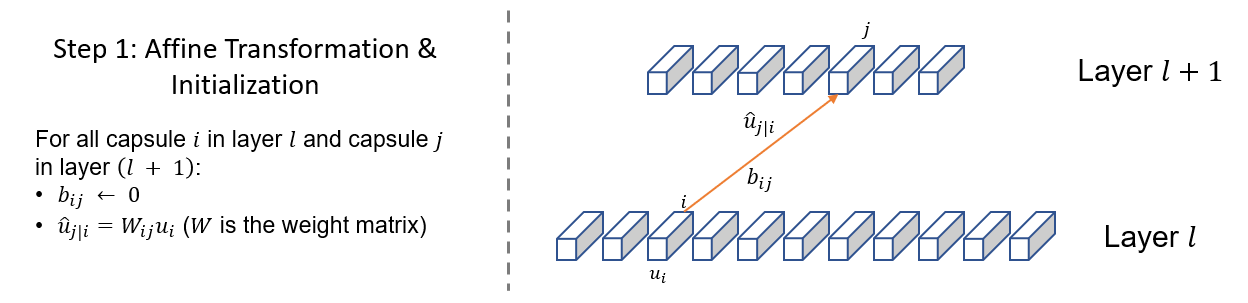
| W: | H:
{kind=link}
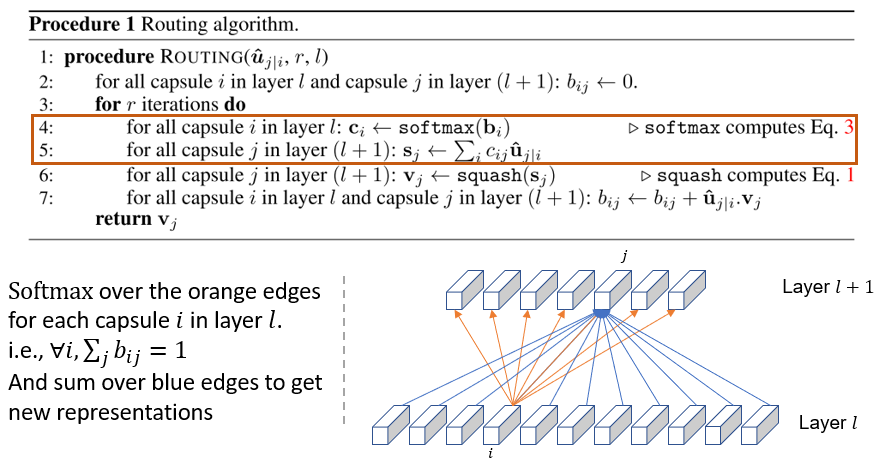
80.7 KB
tutorial/capsule/squash.png
0 → 100644
{kind=link}
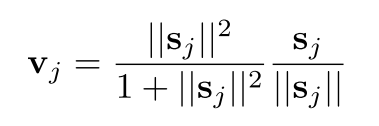
5.82 KB
tutorial/capsule/step6.png
0 → 100644
{kind=link}

9.85 KB
tutorial/capsule/step7.png
0 → 100644
{kind=link}
9.25 KB