
Ported 1Cycle tutorial. (#47)
* Importing 1Cycle tutorial. * image paths * Added LR schedule figure * line wrap * lowercase name * Updating README links * typo
Showing
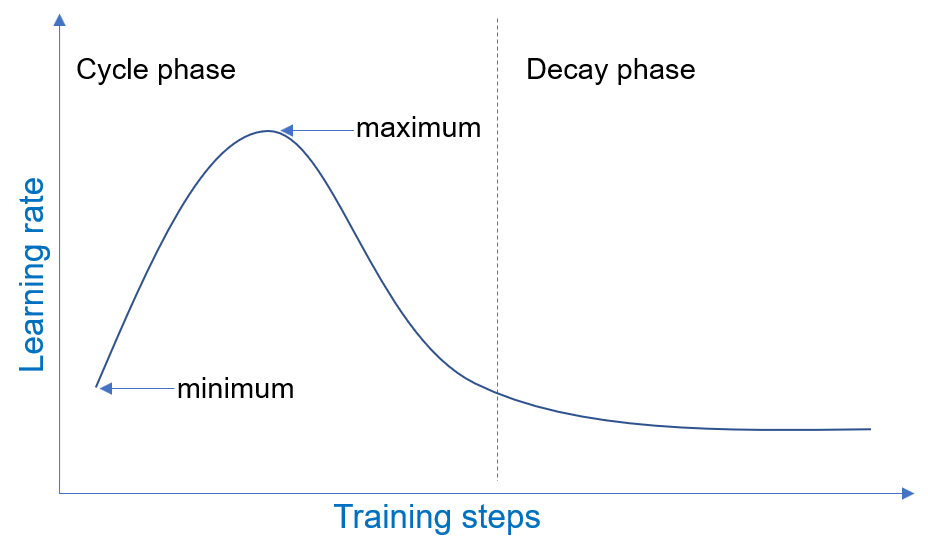
docs/figures/1cycle_lr.png
0 → 100644
{kind=link}
24.5 KB
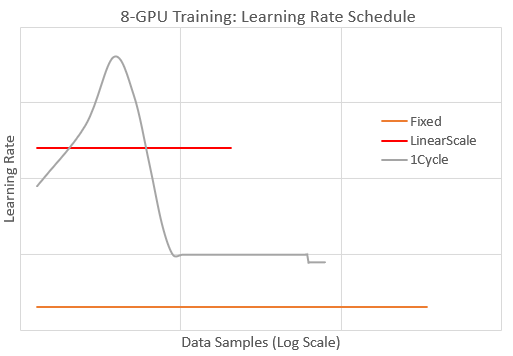
docs/figures/lr_schedule.png
0 → 100644
{kind=link}
11.5 KB
{kind=link}
12.4 KB
docs/tutorials/1Cycle.md
0 → 100644