
Web edits (#147)
Showing
docs/_pages/config_json.md
0 → 100644
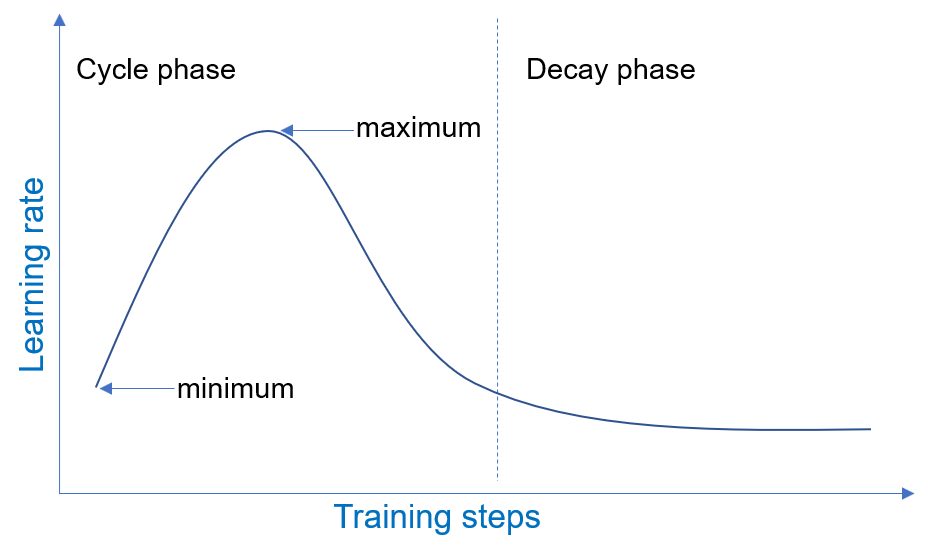
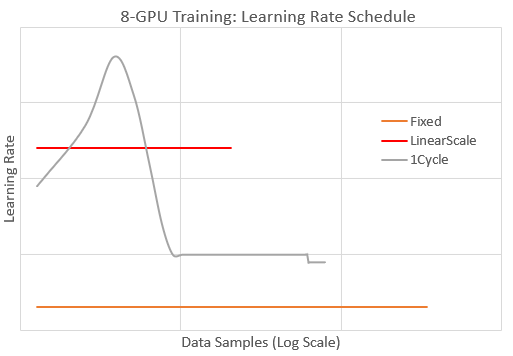
docs/_tutorials/1Cycle.md
0 → 100644
docs/_tutorials/azure.md
0 → 100644
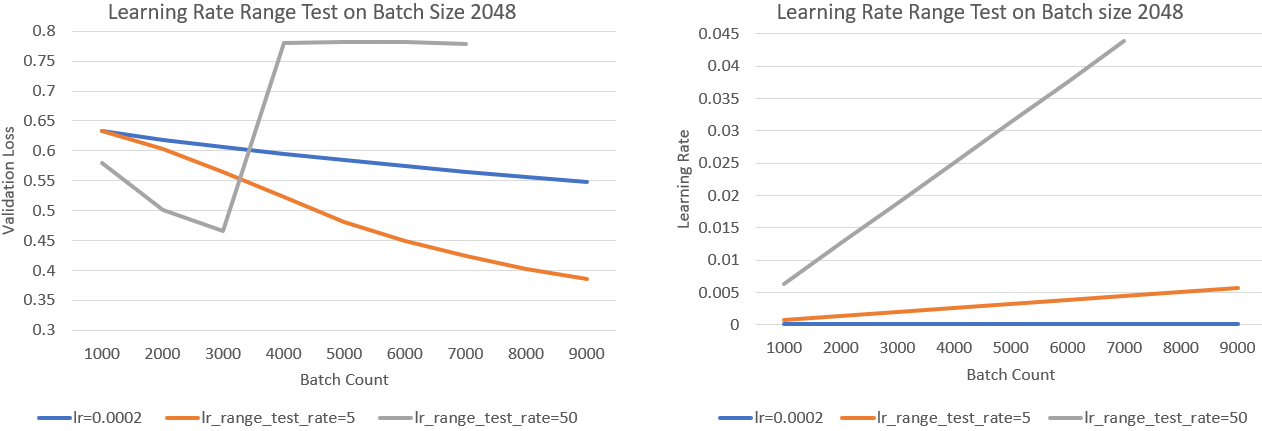
docs/_tutorials/lrrt.md
0 → 100644
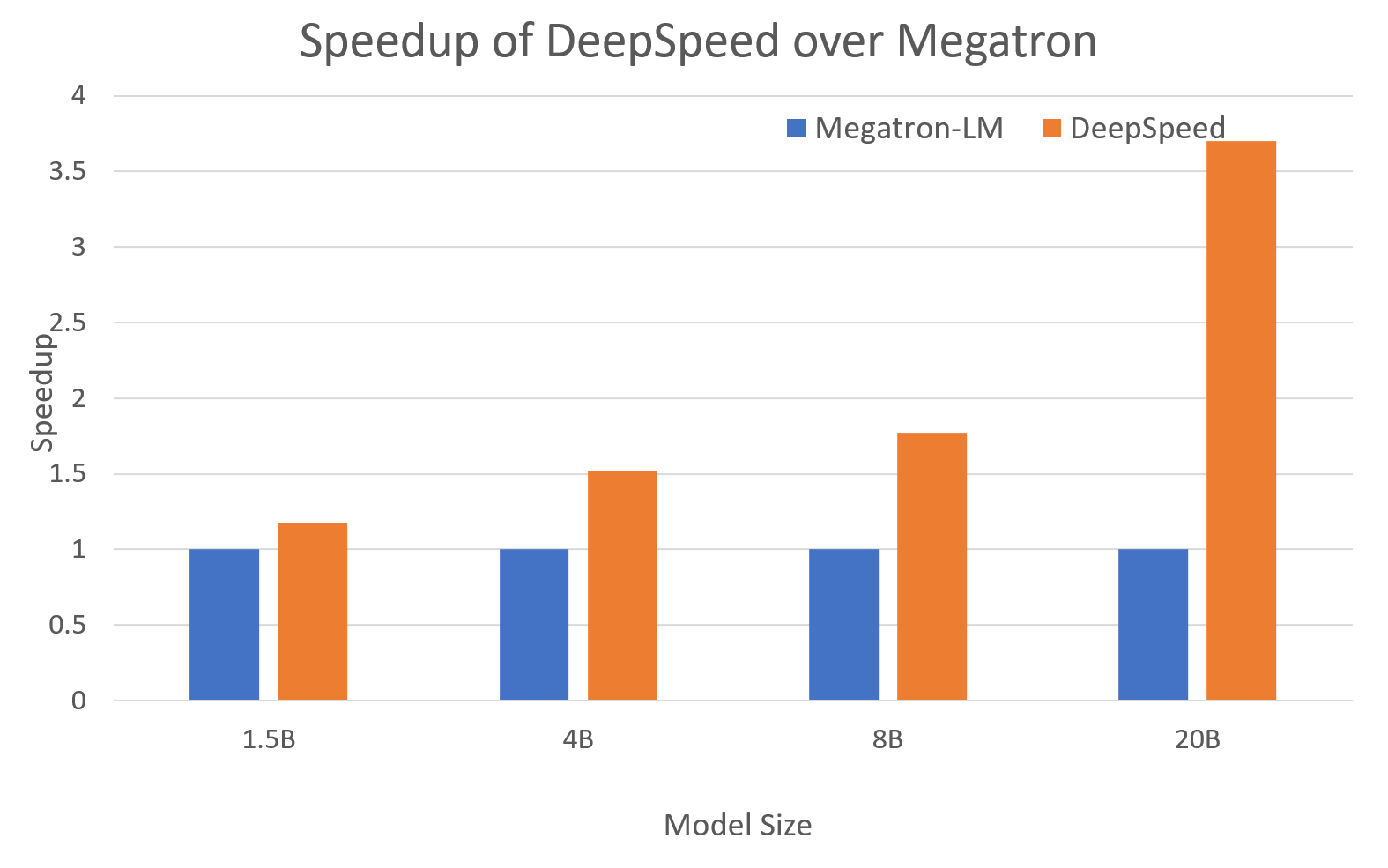
docs/_tutorials/megatron.md
0 → 100644
{kind=link}
24.5 KB
{kind=link}
40.7 KB
{kind=link}
11.5 KB
{kind=link}
41.1 KB
{kind=link}
12.4 KB
docs/contributing.md
0 → 100644