
Update documentation for 1-bit Adam (#388)
Co-authored-by:  Jeff Rasley <jerasley@microsoft.com>
Jeff Rasley <jerasley@microsoft.com>
Showing
{kind=link}
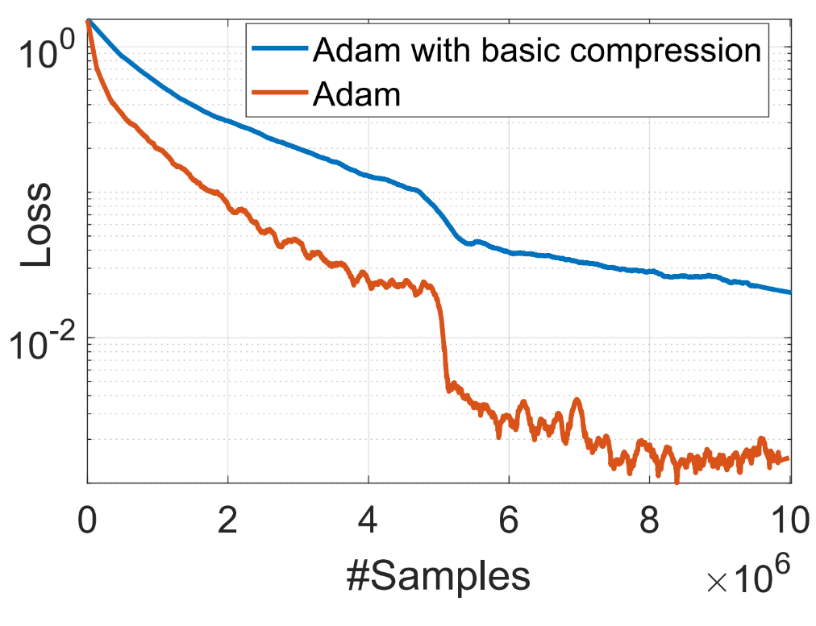
102 KB
{kind=link}
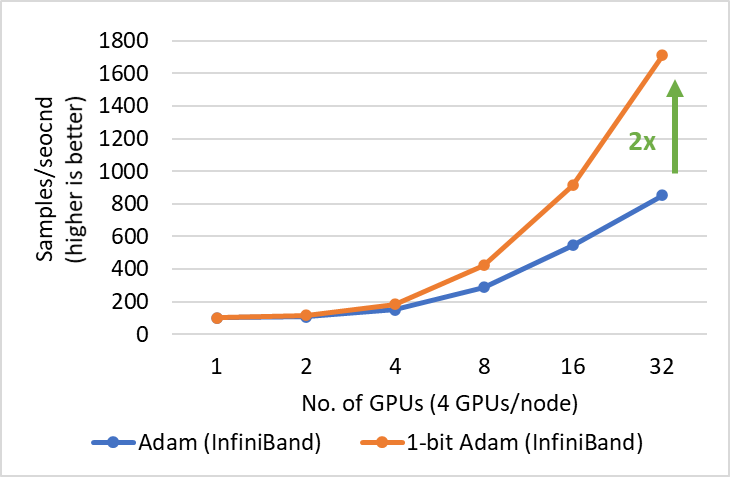
26.7 KB
{kind=link}
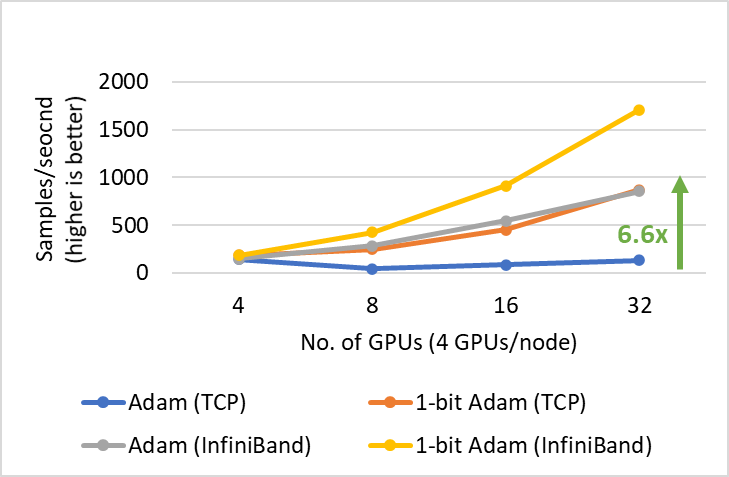
27.3 KB
{kind=link}
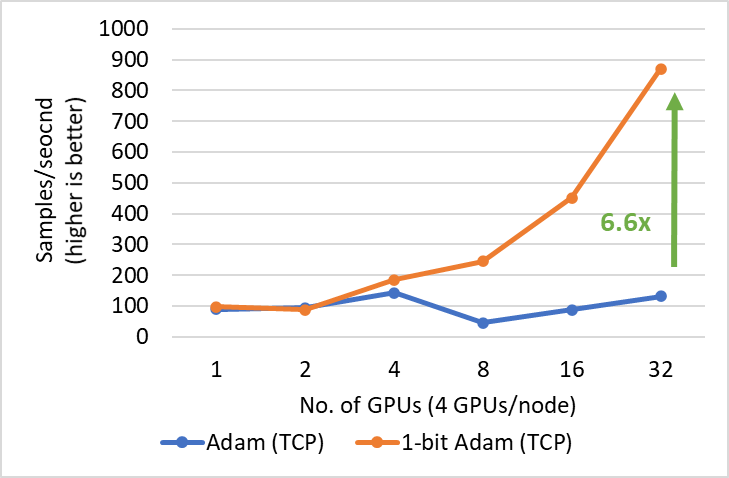
26.2 KB
{kind=link}
29.9 KB
{kind=link}
116 KB
{kind=link}
61.3 KB
{kind=link}

18.9 KB
{kind=link}
27 KB
{kind=link}
18.6 KB
Co-authored-by: Jeff Rasley <jerasley@microsoft.com>
102 KB
26.7 KB
27.3 KB
26.2 KB
29.9 KB
116 KB
61.3 KB
18.9 KB
27 KB
18.6 KB