# TinyChat: Efficient and Lightweight Chatbot with AWQ
We introduce TinyChat, a cutting-edge chatbot interface designed for lightweight resource consumption and fast inference speed on GPU platforms. It allows for seamless deployment on consumer-level GPUs such as 3090/4090 and low-power edge devices like the NVIDIA Jetson Orin, empowering users with a responsive conversational experience like never before.
The current release supports:
- LLaMA-2-7B/13B-chat;
- Vicuna;
- MPT-chat;
- Falcon-instruct.
## Contents
-[Examples](#examples)
-[Benchmarks](#benchmarks)
-[Usage](#usage)
-[Reference](#reference)
## Examples
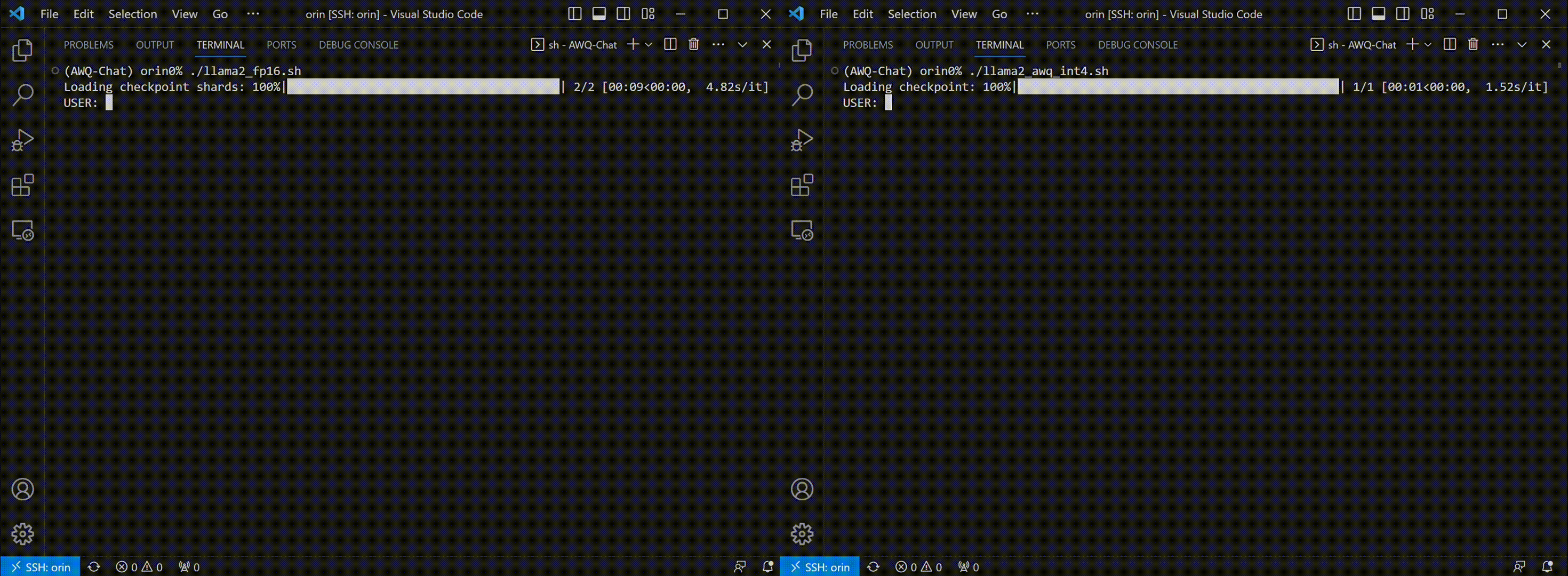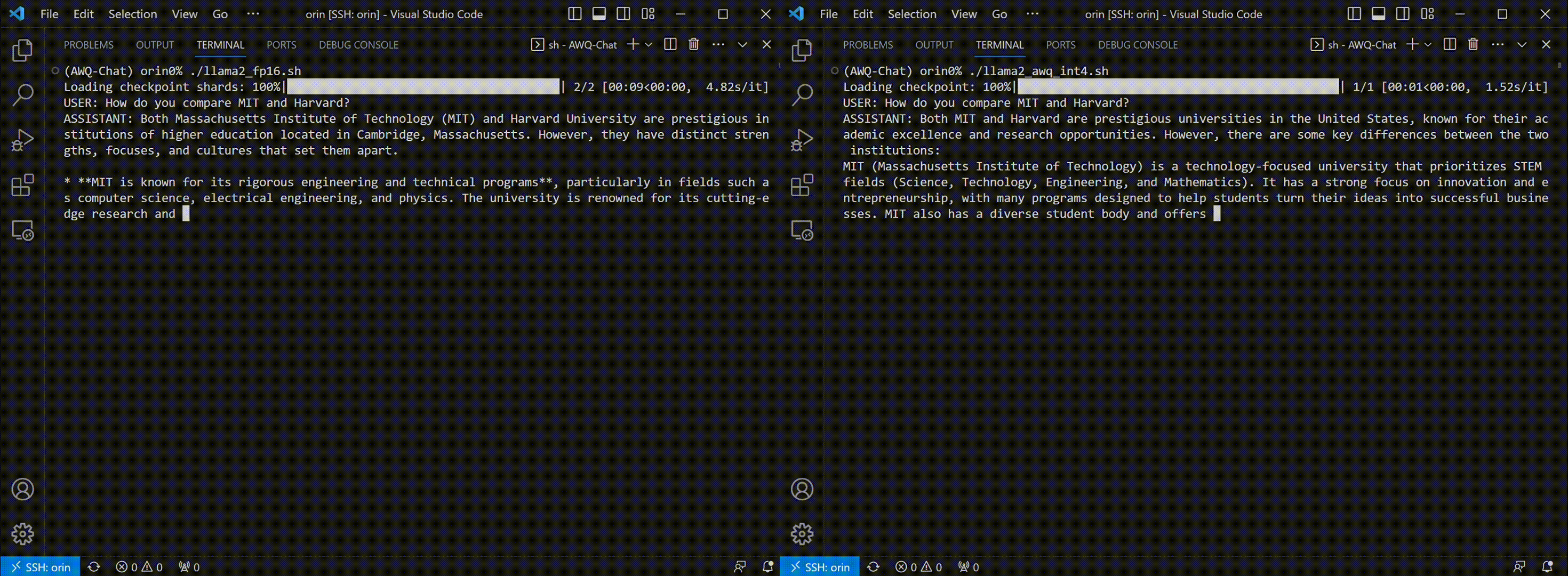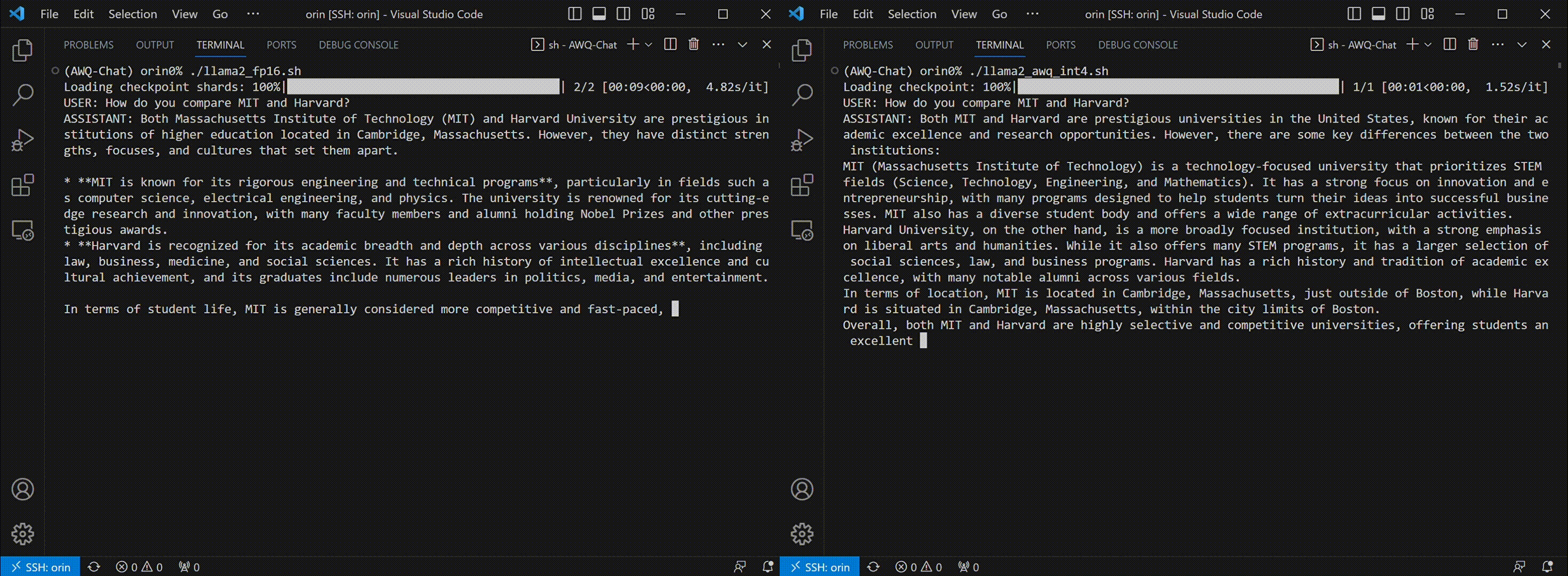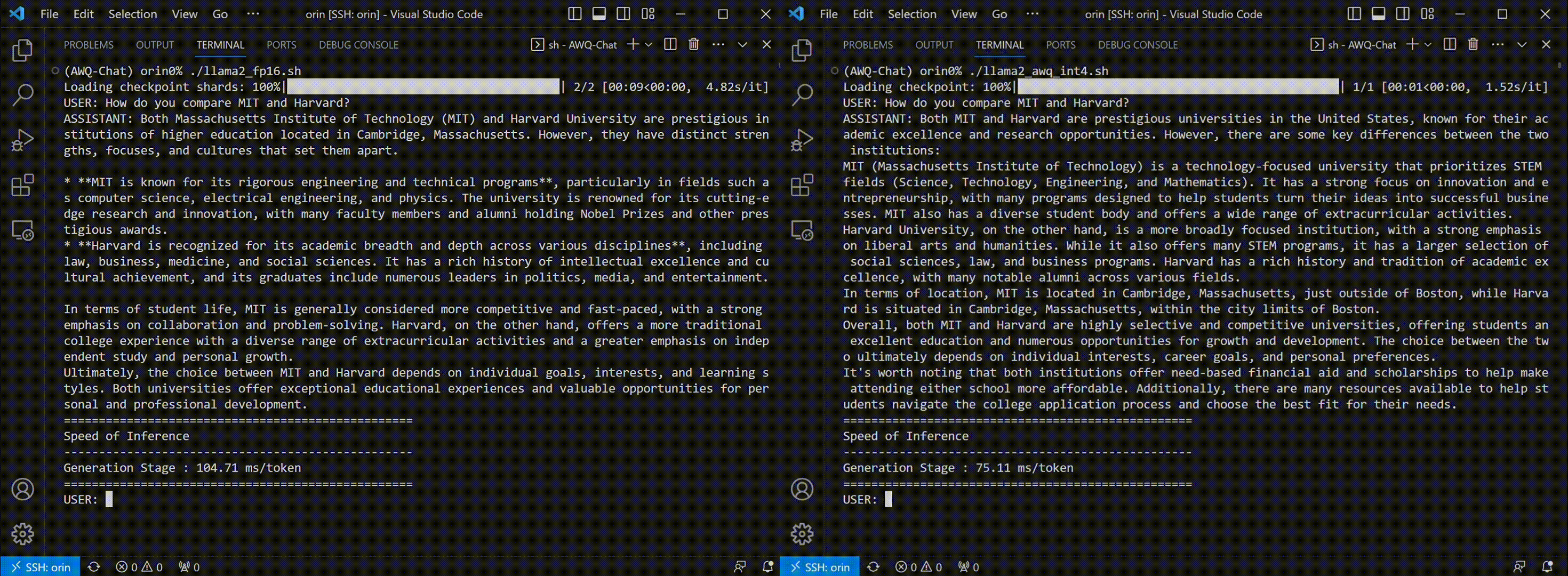
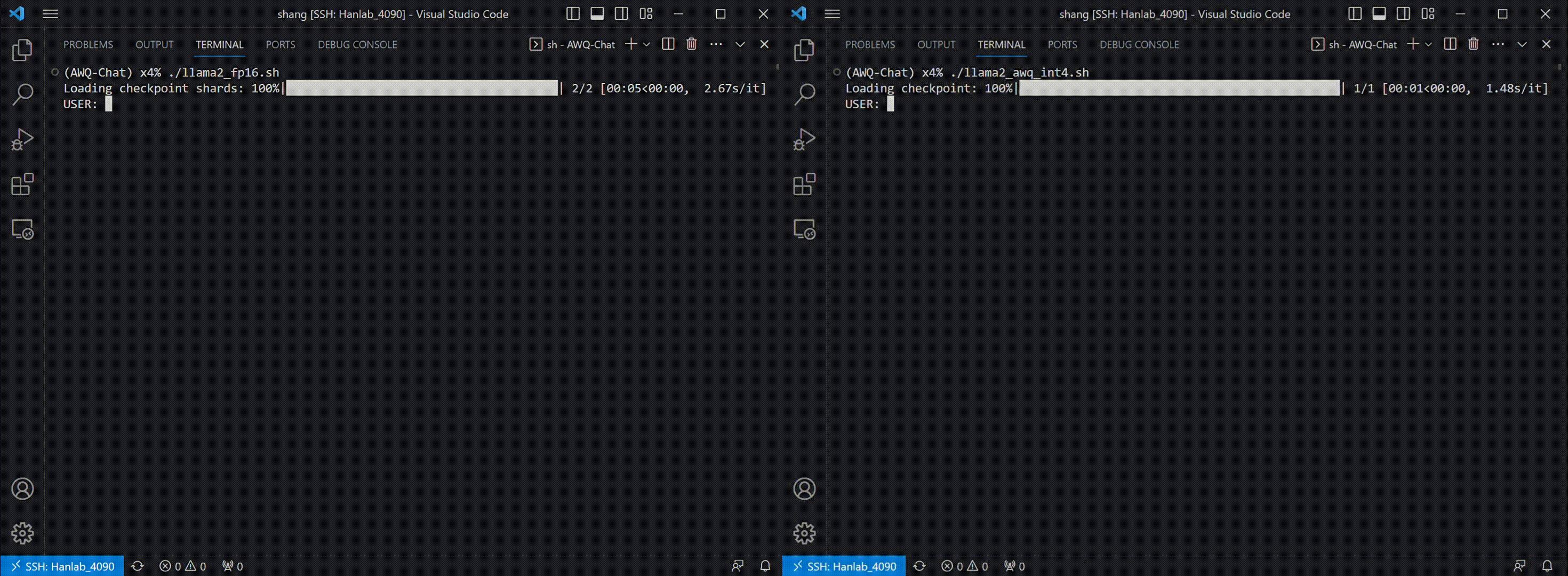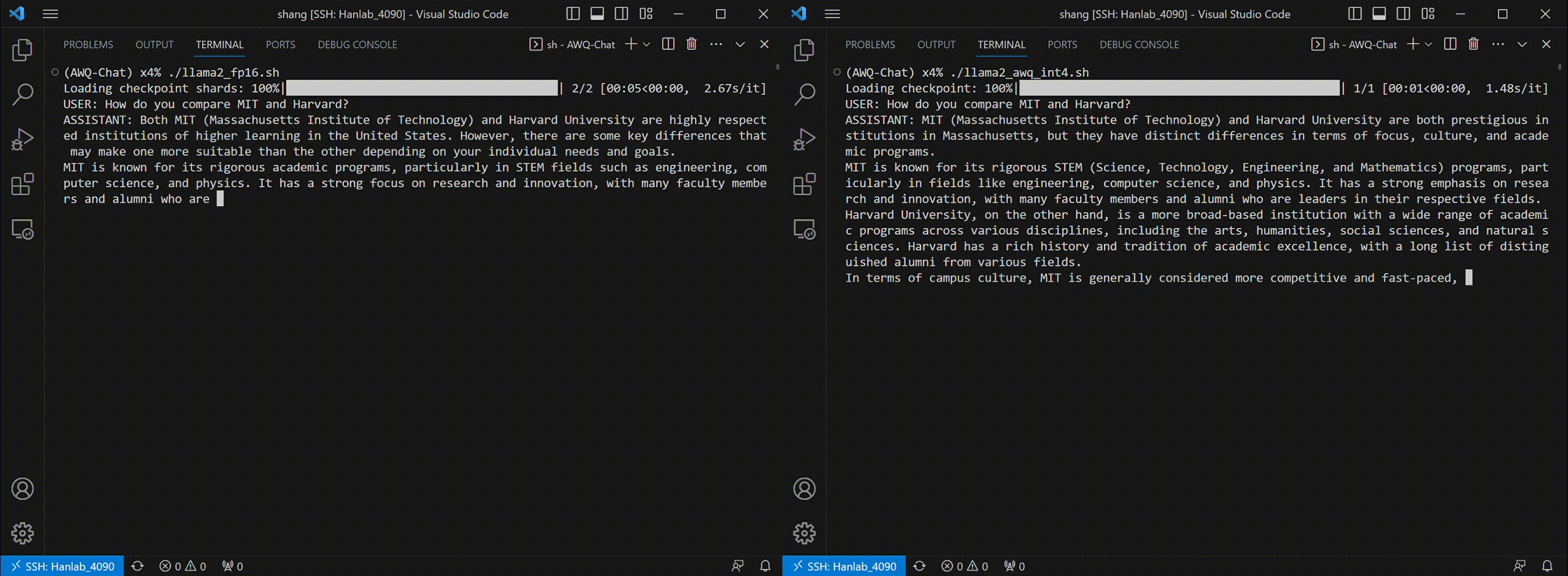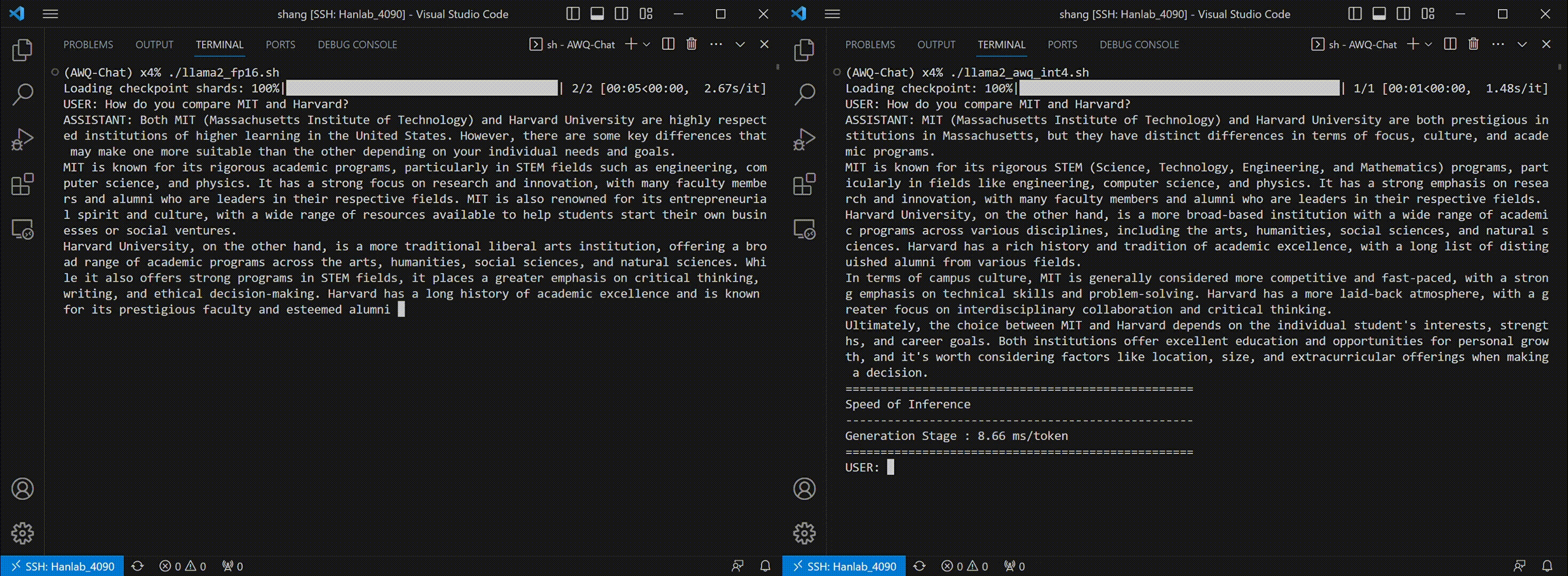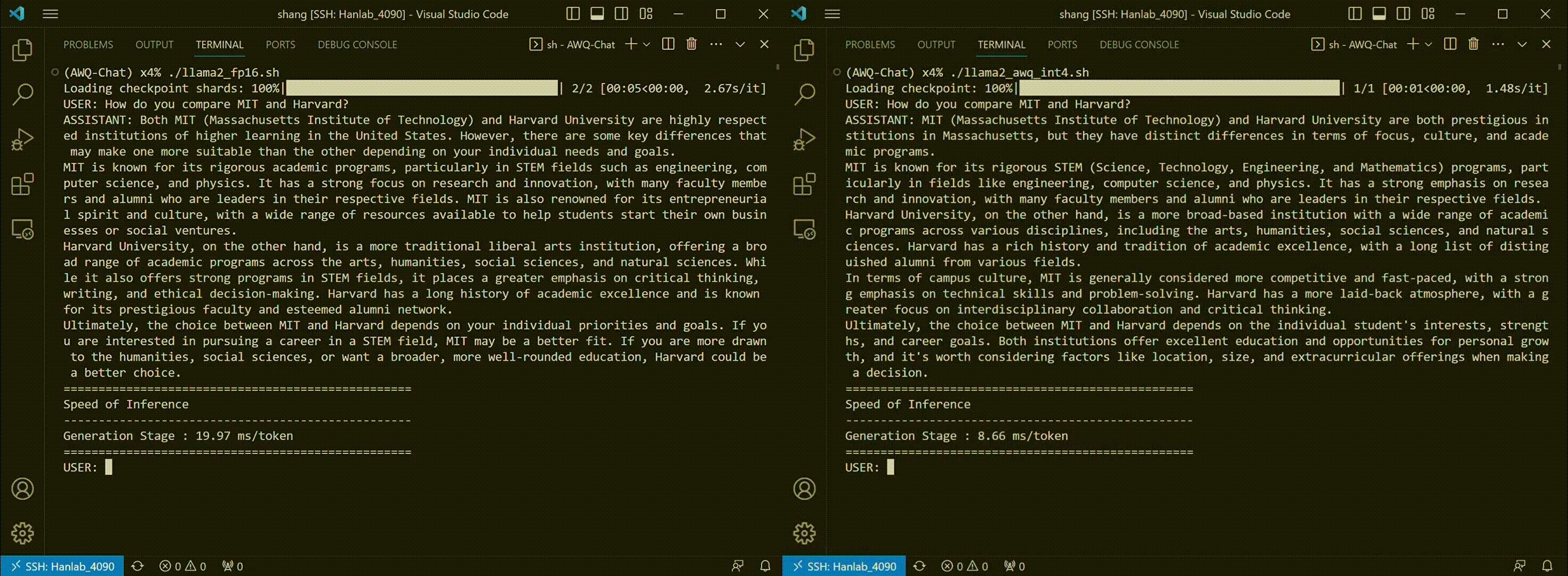
Thanks to AWQ, TinyChat can now deliver more prompt responses through 4-bit inference. The following examples showcase that TinyChat's W4A16 generation is 2.3x faster on RTX 4090 and 1.4x faster on Jetson Orin, compared to the FP16 baselines. (Tested with [LLaMA-2-7b](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) model.)
* TinyChat on RTX 4090:

* TinyChat on Jetson Orin:

## Benchmarks
We benchmark TinyChat on A6000 (server-class GPU), 4090 (desktop GPU) and Orin (edge GPU).
We use the default implementation from Huggingface for the FP16 baseline. The INT4 implementation applies AWQ and utilizes our fast W4A16 GPU kernel. Please notice that the end-to-end runtime for INT4 TinyChat could be further improved if we reduce the framework overhead from Huggingface (e.g. utilizing the implementation from TGI). We are working on a new release with even faster inference performance, please stay tuned!
The latency reported in all tables are per-token latency for the generation stage.
TinyChat is inspired by the following open-source projects: [FasterTransformer](https://github.com/NVIDIA/FasterTransformer), [vLLM](https://github.com/vllm-project/vllm), [FastChat](https://github.com/lm-sys/FastChat).
assertlen(oneshot_example)==2,"One-shot example must be a List of 2 strs."
self.user_example=oneshot_example[0]
self.assistant_example=oneshot_example[1]
self.insert_prompt(self.user_example)
self.update_template(self.assistant_example)
classVicunaPrompter(BasePrompter):
def__init__(self):
system_inst="A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions."
system_inst="A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions."
role1="### Human"
role2="### Assistant"
sen_spliter="\n"
qa_spliter="</s>"
user_example="Got any creative ideas for a 10 year old's birthday?"
assistant_example="Of course! Here are some creative ideas for a 10-year-old's birthday party:\n" \
+"1. Treasure Hunt: Organize a treasure hunt in your backyard or nearby park. Create clues and riddles for the kids to solve, leading them to hidden treasures and surprises.\n" \
+"2. Science Party: Plan a science-themed party where kids can engage in fun and interactive experiments. You can set up different stations with activities like making slime, erupting volcanoes, or creating simple chemical reactions.\n" \
+"3. Outdoor Movie Night: Set up a backyard movie night with a projector and a large screen or white sheet. Create a cozy seating area with blankets and pillows, and serve popcorn and snacks while the kids enjoy a favorite movie under the stars.\n" \
+"4. DIY Crafts Party: Arrange a craft party where kids can unleash their creativity. Provide a variety of craft supplies like beads, paints, and fabrics, and let them create their own unique masterpieces to take home as party favors.\n" \
+"5. Sports Olympics: Host a mini Olympics event with various sports and games. Set up different stations for activities like sack races, relay races, basketball shooting, and obstacle courses. Give out medals or certificates to the participants.\n" \
+"6. Cooking Party: Have a cooking-themed party where the kids can prepare their own mini pizzas, cupcakes, or cookies. Provide toppings, frosting, and decorating supplies, and let them get hands-on in the kitchen.\n" \
+"7. Superhero Training Camp: Create a superhero-themed party where the kids can engage in fun training activities. Set up an obstacle course, have them design their own superhero capes or masks, and organize superhero-themed games and challenges.\n" \
+"8. Outdoor Adventure: Plan an outdoor adventure party at a local park or nature reserve. Arrange activities like hiking, nature scavenger hunts, or a picnic with games. Encourage exploration and appreciation for the outdoors.\n" \
+"Remember to tailor the activities to the birthday child's interests and preferences. Have a great celebration!"
system_inst="A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions."

{kind=link}
{kind=link}