
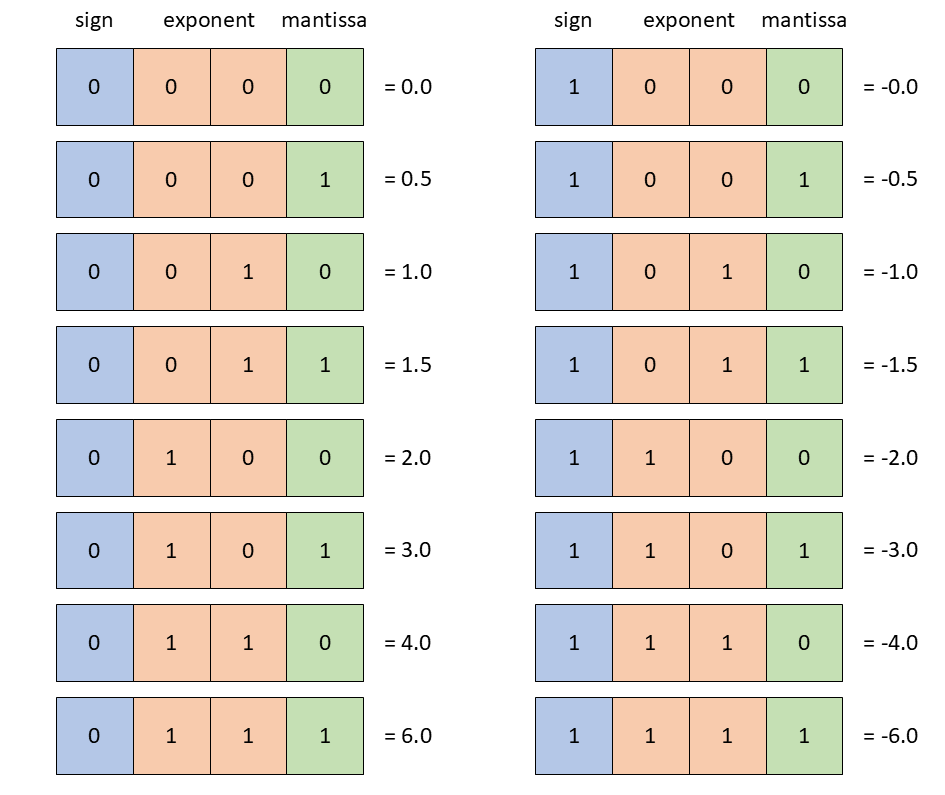
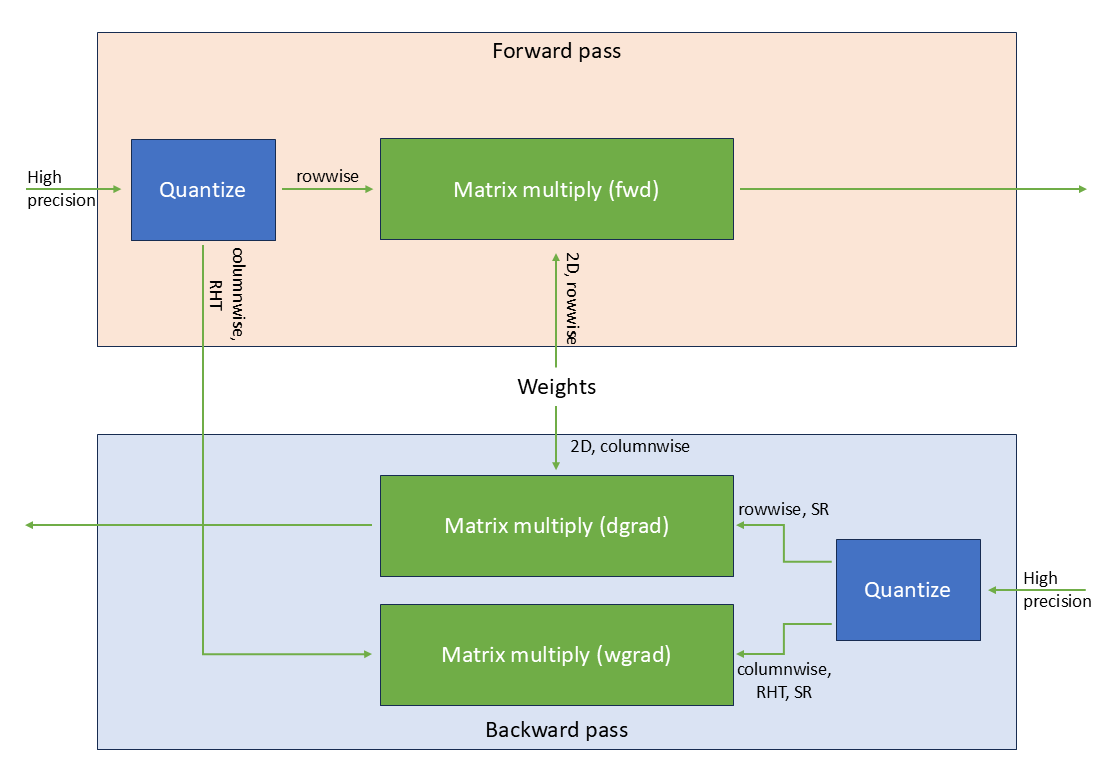
Added the NVFP4 section to the low precision training tutorial (#2237)
* Added the NVFP4 part to the low precision tutorial Signed-off-by:Przemek Tredak <ptredak@nvidia.com> * Added the runtime results Signed-off-by:
Copilot <175728472+Copilot@users.noreply.github.com> Signed-off-by:
Kirthi Shankar Sivamani <ksivamani@nvidia.com> * Update docs/examples/fp8_primer.ipynb Signed-off-by:
Showing
docs/examples/FP4_format.png
0 → 100644
{kind=link}
49.8 KB
docs/examples/FP4_linear.png
0 → 100644
{kind=link}
52.8 KB