
First commit.
Showing
.gitignore
0 → 100644
LICENSE
0 → 100644
Makefile
0 → 100644
README_en.md
0 → 100644
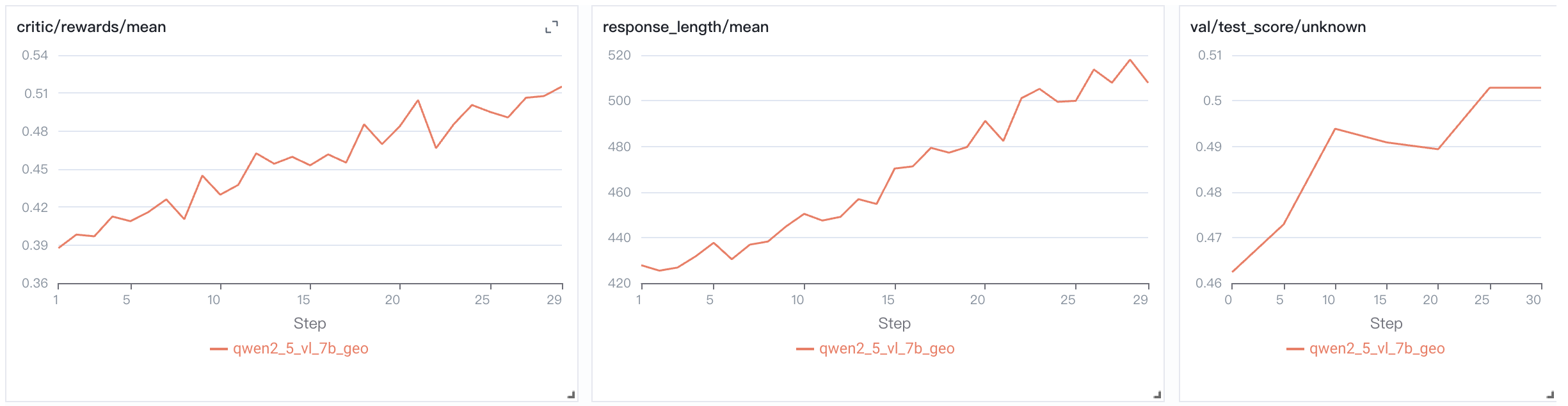
assets/qwen2_5_vl_7b_geo.png
0 → 100644
{kind=link}
71.9 KB
assets/wechat.jpg
0 → 100644
{kind=link}

162 KB
docker/Dockerfile
0 → 100644
examples/grpo_example.yaml
0 → 100644
examples/remax_example.yaml
0 → 100644
examples/runtime_env.yaml
0 → 100644
pyproject.toml
0 → 100644
requirements.txt
0 → 100644
| accelerate | |||
| codetiming | |||
| datasets | |||
| flash-attn>=2.4.3 | |||
| liger-kernel | |||
| mathruler | |||
| numpy | |||
| omegaconf | |||
| pandas | |||
| peft | |||
| pillow | |||
| pyarrow>=15.0.0 | |||
| pylatexenc | |||
| qwen-vl-utils | |||
| ray | |||
| tensordict | |||
| transformers>=4.49.0 | |||
| vllm>=0.7.3 | |||
| wandb |
scripts/model_merger.py
0 → 100644