
0402 update
Showing
.pre-commit-config.yaml
0 → 100644
Dockerfile
0 → 100644
Dockerfile.nightly
0 → 100644
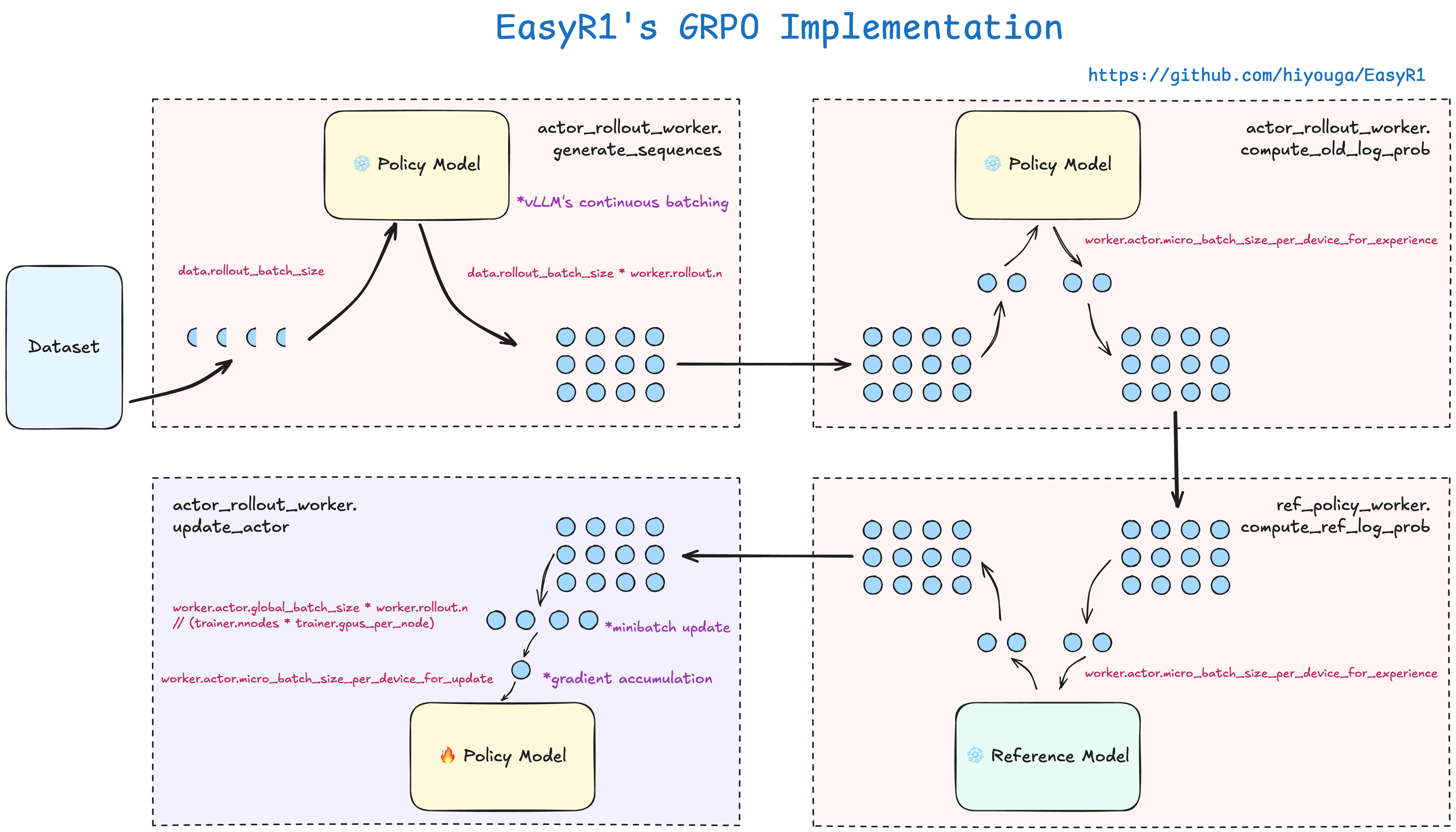
assets/easyr1_grpo.png
0 → 100644
{kind=link}
845 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
examples/config.yaml
0 → 100644