Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
XUSR-SG
LLaMA_Tencentpretrain_pytorch
Commits
884640da
Commit
884640da
authored
Oct 19, 2023
by
zhaoying1
Browse files
UPDATE
parent
bdd7113b
Changes
10
Hide whitespace changes
Inline
Side-by-side
Showing
10 changed files
with
205 additions
and
22 deletions
+205
-22
README.md
README.md
+44
-18
data/media/llamaa.png
data/media/llamaa.png
+0
-0
model.properties
model.properties
+2
-2
multi_node/hostfile
multi_node/hostfile
+2
-0
multi_node/run-13b-pretrain-single.sh
multi_node/run-13b-pretrain-single.sh
+58
-0
multi_node/run-13b-pretrain.sh
multi_node/run-13b-pretrain.sh
+21
-0
multi_node/run-13b-single.sh
multi_node/run-13b-single.sh
+56
-0
multi_node/run-13b.sh
multi_node/run-13b.sh
+20
-0
requirements.txt
requirements.txt
+1
-0
slurm_scripts/run-13b-pretrain-single.sh
slurm_scripts/run-13b-pretrain-single.sh
+1
-2
No files found.
README.md
View file @
884640da
## LLaMA
## LLaMA
& LLaMA2
## 论文
## 论文
`LLaMA: Open and Efficient Foundation Language Models`
`LLaMA: Open and Efficient Foundation Language Models`
...
@@ -10,6 +10,8 @@
...
@@ -10,6 +10,8 @@
-
[
https://arxiv.org/abs/2307.09288
](
https://arxiv.org/abs/2307.09288
)
-
[
https://arxiv.org/abs/2307.09288
](
https://arxiv.org/abs/2307.09288
)
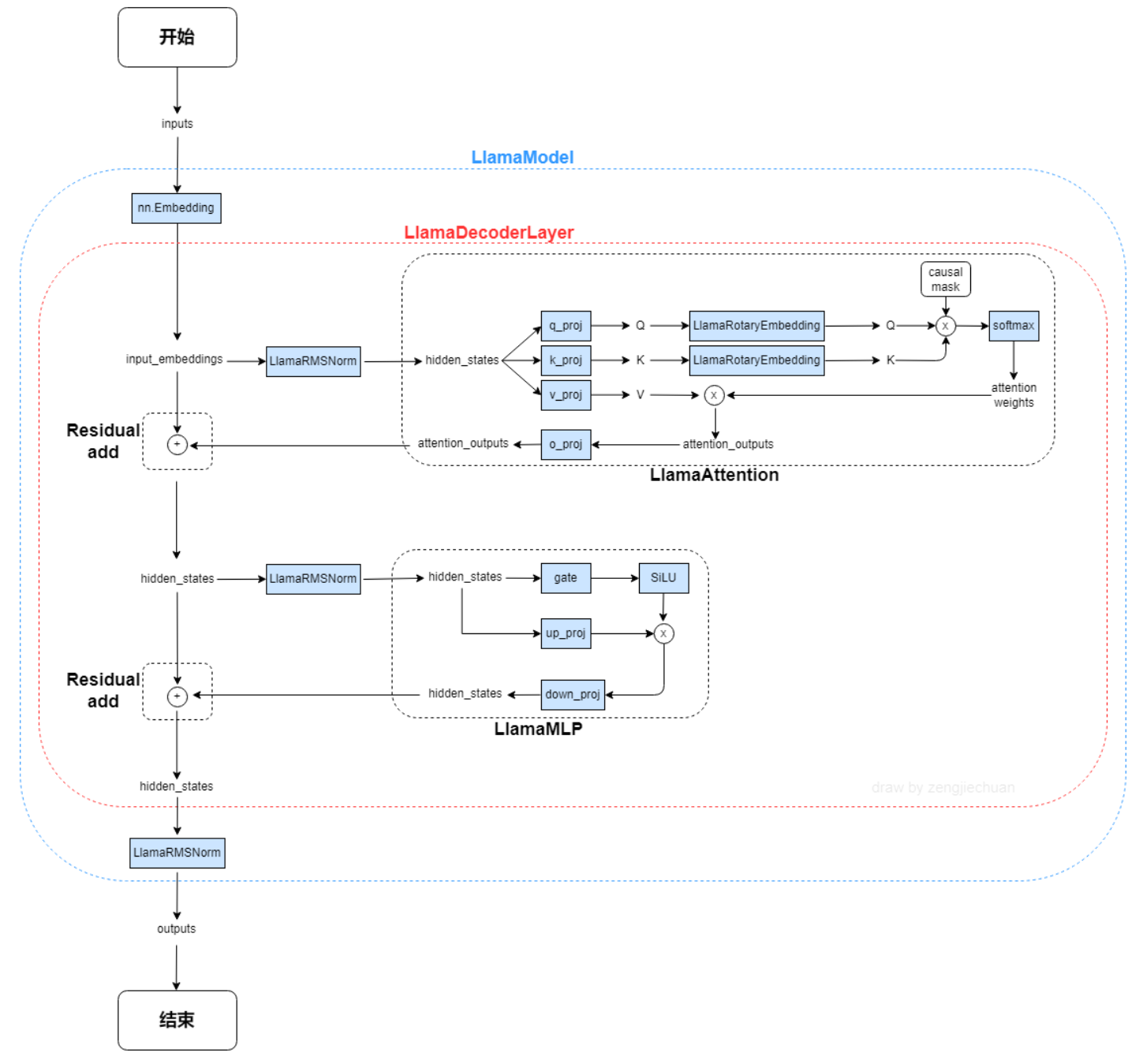
## 模型结构
## 模型结构
**注意**
:本仓库在llama2部分仅支持7b和13b模型。
LLaMA,这是一个基础语言模型的集合,参数范围从7B到65B。在数万亿的tokens上训练出的模型,并表明可以专门使用公开可用的数据集来训练最先进的模型,而不依赖于专有的和不可访问的数据集。特别是,llama 13B在大多数基准测试中优于GPT-3 (175B), LLaMA 65B与最好的模型Chinchilla-70B和PaLM-540B具有竞争力。LLAMA网络基于 Transformer 架构。提出了各种改进,并用于不同的模型,例如 PaLM。
LLaMA,这是一个基础语言模型的集合,参数范围从7B到65B。在数万亿的tokens上训练出的模型,并表明可以专门使用公开可用的数据集来训练最先进的模型,而不依赖于专有的和不可访问的数据集。特别是,llama 13B在大多数基准测试中优于GPT-3 (175B), LLaMA 65B与最好的模型Chinchilla-70B和PaLM-540B具有竞争力。LLAMA网络基于 Transformer 架构。提出了各种改进,并用于不同的模型,例如 PaLM。
...
@@ -23,7 +25,7 @@ LLaMA模型具体参数:
...
@@ -23,7 +25,7 @@ LLaMA模型具体参数:
<div
align=
"center"
>
<div
align=
"center"
>
<img
src=
"./data/media/llama
a
.png"
width=
"600"
height=
"500"
>
<img
src=
"./data/media/llama
模型结构
.png"
width=
"600"
height=
"500"
>
</div>
</div>
LLaMA 2是LLaMA的新一代版本,具有商业友好的许可证。 LLaMA 2 有 3 种不同的尺寸:7B、13B 和 70B。Llama 2训练语料相比LLaMA多出40%,上下文长度是由之前的2048升级到4096,可以理解和生成更长的文本。Llama 2采用了 Llama 1 的大部分预训练设置和模型架构,使用标准Transformer 架构,使用 RMSNorm 应用预归一化、使用 SwiGLU 激活函数和旋转位置嵌入RoPE。
LLaMA 2是LLaMA的新一代版本,具有商业友好的许可证。 LLaMA 2 有 3 种不同的尺寸:7B、13B 和 70B。Llama 2训练语料相比LLaMA多出40%,上下文长度是由之前的2048升级到4096,可以理解和生成更长的文本。Llama 2采用了 Llama 1 的大部分预训练设置和模型架构,使用标准Transformer 架构,使用 RMSNorm 应用预归一化、使用 SwiGLU 激活函数和旋转位置嵌入RoPE。
...
@@ -31,6 +33,9 @@ LLaMA 2是LLaMA的新一代版本,具有商业友好的许可证。 LLaMA 2
...
@@ -31,6 +33,9 @@ LLaMA 2是LLaMA的新一代版本,具有商业友好的许可证。 LLaMA 2
## 算法原理
## 算法原理
<div
align=
"center"
>
<img
src=
"./data/media/llama算法原理.png"
width=
"300"
height=
"500"
>
</div>
以下是与原始架构的主要区别:
以下是与原始架构的主要区别:
...
@@ -82,7 +87,9 @@ pip install -r requirements.txt
...
@@ -82,7 +87,9 @@ pip install -r requirements.txt
## 数据集
## 数据集
我们在
[
data
](
./data
)
目录下集成了中文公开指令数据集
[
alpaca_gpt4_data_zh.json
](
https://huggingface.co/datasets/shibing624/alpaca-zh
)
,供用户快速验证:
我们在
[
data
](
./data
)
目录下集成了中文公开指令数据集
[
alpaca_gpt4_data_zh.json
](
https://huggingface.co/datasets/shibing624/alpaca-zh
)
,供用户快速验证:
```
```
./data/alpaca_gpt4_data_zh.json
$ tree ./data/
── alpaca_gpt4_data_zh.json
── dataset.pt
```
```
## 模型权重下载
## 模型权重下载
...
@@ -93,8 +100,10 @@ python3 scripts/convert_llama_from_huggingface_to_tencentpretrain.py --input_mod
...
@@ -93,8 +100,10 @@ python3 scripts/convert_llama_from_huggingface_to_tencentpretrain.py --input_mod
```
```
2.
方式二:也可以直接下载
[
TencentPretrain对应格式模型
](
https://huggingface.co/Linly-AI/
)
进行微调训练,不需要转换格式。
2.
方式二:也可以直接下载
[
TencentPretrain对应格式模型
](
https://huggingface.co/Linly-AI/
)
进行微调训练,不需要转换格式。
## 全参数增量预训练
### 数据预处理
## 训练
### 全参数增量预训练
#### 数据预处理
1.
构建预训练数据集
1.
构建预训练数据集
txt预训练语料:多个txt需要合并到一个 .txt 文件并按行随机打乱,语料格式如下:
txt预训练语料:多个txt需要合并到一个 .txt 文件并按行随机打乱,语料格式如下:
...
@@ -118,7 +127,7 @@ python3 preprocess.py --corpus_path $CORPUS_PATH --spm_model_path $LLaMA_PATH/to
...
@@ -118,7 +127,7 @@ python3 preprocess.py --corpus_path $CORPUS_PATH --spm_model_path $LLaMA_PATH/to
可选参数: --json_format_corpus:使用jsonl格式数据;
可选参数: --json_format_corpus:使用jsonl格式数据;
--full_sentences:对长度不足的样本使用其他样本进行填充(没有 pad token);
--full_sentences:对长度不足的样本使用其他样本进行填充(没有 pad token);
### 训练
###
#
训练
1.
单机
1.
单机
```
commandline
```
commandline
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_config.json --enable_zero3 \
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_config.json --enable_zero3 \
...
@@ -130,14 +139,17 @@ deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_conf
...
@@ -130,14 +139,17 @@ deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_conf
--total_steps 300000 --save_checkpoint_steps 5000 --batch_size 24
--total_steps 300000 --save_checkpoint_steps 5000 --batch_size 24
```
```
2.
集群
2.
多机
```
commandline
```
commandline
cd slurm_scripts
cd multi_node
bash run-pt.sh
```
进入节点1,根据环境修改hostfile,保证两节点文件路径一致,配置相同,按需修改run-13b-pretrain.sh中--mca btl_tcp_if_include enp97s0f1,enp97s0f1改为ip a命令后对应节点ip的网卡名,numa可以根据当前节点拓扑更改绑定,微调命令:
```
commandline
bash run-13b-pretrain.sh
```
```
## 全参数指令微调
##
#
全参数指令微调
#### 数据预处理
#### 数据预处理
1.
构建指令数据集:指令数据为 json 格式,包含instruction、input、output三个字段(可以为空),每行一条样本。
1.
构建指令数据集:指令数据为 json 格式,包含instruction、input、output三个字段(可以为空),每行一条样本。
示例:
示例:
...
@@ -150,7 +162,7 @@ bash run-pt.sh
...
@@ -150,7 +162,7 @@ bash run-pt.sh
python3 preprocess.py --corpus_path $INSTRUCTION_PATH --spm_model_path $LLaMA_PATH/tokenizer.model \
python3 preprocess.py --corpus_path $INSTRUCTION_PATH --spm_model_path $LLaMA_PATH/tokenizer.model \
--dataset_path $OUTPUT_DATASET_PATH --data_processor alpaca --seq_length 1024
--dataset_path $OUTPUT_DATASET_PATH --data_processor alpaca --seq_length 1024
```
```
### 训练
###
#
训练
1.
单机
1.
单机
```
commandline
```
commandline
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_config.json --enable_zero3 \
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_config.json --enable_zero3 \
...
@@ -162,12 +174,14 @@ deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_conf
...
@@ -162,12 +174,14 @@ deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_conf
--total_steps 20000 --save_checkpoint_steps 2000 --batch_size 24
--total_steps 20000 --save_checkpoint_steps 2000 --batch_size 24
```
```
2.
集群
2.
多机
```
commandline
```
commandline
cd slurm_scripts
cd multi_node
bash run-ift.sh
```
进入节点1,根据环境修改hostfile,保证两节点文件路径一致,配置相同,按需修改run-13b.sh中--mca btl_tcp_if_include enp97s0f1,enp97s0f1改为ip a命令后对应节点ip的网卡名,numa可以根据当前节点拓扑更改绑定,微调命令:
```
commandline
bash run-13b.sh
```
```
## 模型分块
## 模型分块
训练初始化时,每张卡会加载一个模型的拷贝,因此内存需求为模型大小
*
GPU数量。内存不足时可以通过以下方式将模型分块,然后使用分块加载。
训练初始化时,每张卡会加载一个模型的拷贝,因此内存需求为模型大小
*
GPU数量。内存不足时可以通过以下方式将模型分块,然后使用分块加载。
...
@@ -182,8 +196,17 @@ python3 scripts/convert_model_into_blocks.py \
...
@@ -182,8 +196,17 @@ python3 scripts/convert_model_into_blocks.py \
## 推理
## 推理
TencentPretrain格式模型推理请参考
[
llama_inference_pytorch
](
https://developer.hpccube.com/codes/modelzoo/llama_inference_pytorch
)
TencentPretrain格式模型推理请参考
[
llama_inference_pytorch
](
https://developer.hpccube.com/codes/modelzoo/llama_inference_pytorch
)
## Result
-input
```
请问“手臂”的英文是什么
```
-output
```
手臂的英文是“arm”。
```
##
# Results
##
精度
-
利用公开指令数据集
[
alpaca_gpt4_data_zh.json
](
https://huggingface.co/datasets/shibing624/alpaca-zh
)
,基于汉化ChineseLLaMA的7B、13B基础模型,我们进行指令微调训练实验,以下为训练Loss:
-
利用公开指令数据集
[
alpaca_gpt4_data_zh.json
](
https://huggingface.co/datasets/shibing624/alpaca-zh
)
,基于汉化ChineseLLaMA的7B、13B基础模型,我们进行指令微调训练实验,以下为训练Loss:
<div
align=
"center"
>
<div
align=
"center"
>
<figure
class=
"half"
>
<figure
class=
"half"
>
...
@@ -197,6 +220,9 @@ TencentPretrain格式模型推理请参考[llama_inference_pytorch](https://deve
...
@@ -197,6 +220,9 @@ TencentPretrain格式模型推理请参考[llama_inference_pytorch](https://deve
<img
src=
"./data/media/ift_llama2_7B_bs2_32node_128cards.jpg"
width=
"300"
height=
"250"
>
<img
src=
"./data/media/ift_llama2_7B_bs2_32node_128cards.jpg"
width=
"300"
height=
"250"
>
</div>
</div>
## 应用场景
## 应用场景
### 算法类别
### 算法类别
...
@@ -205,13 +231,13 @@ TencentPretrain格式模型推理请参考[llama_inference_pytorch](https://deve
...
@@ -205,13 +231,13 @@ TencentPretrain格式模型推理请参考[llama_inference_pytorch](https://deve
### 热点应用行业
### 热点应用行业
`
nlp,智能聊天助手,科研
`
`
医疗,教育,科研,金融
`
## 源码仓库及问题反馈
## 源码仓库及问题反馈
-
https://developer.hpccube.com/codes/modelzoo/llama_tencentpretrain_pytorch
-
https://developer.hpccube.com/codes/modelzoo/llama_tencentpretrain_pytorch
## 参考
## 参考
资料
*
https://github.com/CVI-SZU/Linly
*
https://github.com/CVI-SZU/Linly
*
https://github.com/Tencent/TencentPretrain/
*
https://github.com/Tencent/TencentPretrain/
...
...
data/media/llamaa.png
deleted
100644 → 0
View file @
bdd7113b
188 KB
model.properties
View file @
884640da
...
@@ -3,8 +3,8 @@ modelCode=408
...
@@ -3,8 +3,8 @@ modelCode=408
# 模型名称
# 模型名称
modelName
=
llama_tencentpretrain_pytorch
modelName
=
llama_tencentpretrain_pytorch
# 模型描述
# 模型描述
modelDescription
=
基于tencentpretrain训练框架的llama
modelDescription
=
基于tencentpretrain训练框架的llama
& llama2
# 应用场景
# 应用场景
appScenario
=
训练,推理,
train,inference,nlp,智能聊天助手
appScenario
=
训练,推理,
医疗,教育,科研,金融
# 框架类型
# 框架类型
frameType
=
Pytorch,Transformers,Deepspeed
frameType
=
Pytorch,Transformers,Deepspeed
multi_node/hostfile
0 → 100644
View file @
884640da
10.0.21.163 slots=8
10.0.21.116 slots=8
multi_node/run-13b-pretrain-single.sh
0 → 100644
View file @
884640da
#!/bin/bash
# export NCCL_IB_HCA=mlx5
export
HSA_FORCE_FINE_GRAIN_PCIE
=
1
export
MIOPEN_FIND_MODE
=
3
export
MIOPEN_COMPILE_PARALLEL_LEVEL
=
1
# export NCCL_PLUGIN_P2P=ucx
export
NCCL_SOCKET_IFNAME
=
ib0
export
NCCL_P2P_LEVEL
=
5
export
RCCL_NCHANNELS
=
2
export
NCCL_IB_HCA
=
mlx5_0
lrank
=
$OMPI_COMM_WORLD_LOCAL_RANK
echo
"LRANK===============================
$lrank
"
RANK
=
$OMPI_COMM_WORLD_RANK
WORLD_SIZE
=
$OMPI_COMM_WORLD_SIZE
DATASET_PATH
=
../data/dataset.pt
MODEL_PATH
=
model_scope/Linly-llama-13b-base/model
SPM_MODEL_PATH
=
model_scope/Linly-llama-13b-base/tokenizer.model
APP
=
"python3 ../pretrain.py --deepspeed --deepspeed_config ../models/deepspeed_zero3_config.json
\
--pretrained_model_path
$MODEL_PATH
\
--dataset_path
$DATASET_PATH
--spm_model_path
$SPM_MODEL_PATH
\
--config_path ../models/llama/13b_config.json
\
--output_model_path output/13b/ --deepspeed_checkpoint_activations
\
--world_size
${
2
}
--data_processor lm
\
--total_steps 10000 --save_checkpoint_steps 1000 --batch_size 2 --enable_zero3
\
"
case
${
lrank
}
in
[
0]
)
export
HIP_VISIBLE_DEVICES
=
0,1,2,3
export
UCX_NET_DEVICES
=
mlx5_0:1
export
UCX_IB_PCI_BW
=
mlx5_0:50Gbs
numactl
--cpunodebind
=
0
--membind
=
0
${
APP
}
;;
[
1]
)
export
HIP_VISIBLE_DEVICES
=
0,1,2,3
export
UCX_NET_DEVICES
=
mlx5_1:1
export
UCX_IB_PCI_BW
=
mlx5_1:50Gbs
numactl
--cpunodebind
=
1
--membind
=
1
${
APP
}
;;
[
2]
)
export
HIP_VISIBLE_DEVICES
=
0,1,2,3
export
UCX_NET_DEVICES
=
mlx5_2:1
export
UCX_IB_PCI_BW
=
mlx5_2:50Gbs
numactl
--cpunodebind
=
2
--membind
=
2
${
APP
}
;;
[
3]
)
export
HIP_VISIBLE_DEVICES
=
0,1,2,3
export
UCX_NET_DEVICES
=
mlx5_3:1
export
UCX_IB_PCI_BW
=
mlx5_3:50Gbs
numactl
--cpunodebind
=
3
--membind
=
3
${
APP
}
;;
esac
multi_node/run-13b-pretrain.sh
0 → 100644
View file @
884640da
ulimit
-u
200000
export
HSA_FORCE_FINE_GRAIN_PCIE
=
1
export
MIOPEN_FIND_MODE
=
3
export
MIOPEN_COMPILE_PARALLEL_LEVEL
=
1
export
NCCL_DEBUG
=
INFO
export
NCCL_SOCKET_IFNAME
=
ib0
export
NCCL_P2P_LEVEL
=
5
rm
-rf
./hostfile/
*
echo
"START TIME:
$(
date
)
"
hostfile
=
./hostfile
np
=
$(
cat
$hostfile
|sort|uniq |wc
-l
)
np
=
$((
$np
*
8
))
which mpirun
mpirun
-np
$np
--allow-run-as-root
--hostfile
hostfile
--bind-to
none
--mca
btl_tcp_if_include enp97s0f1
`
pwd
`
/run-13b-pretrain-single.sh 8
echo
"END TIME:
$(
date
)
"
\ No newline at end of file
multi_node/run-13b-single.sh
0 → 100644
View file @
884640da
#!/bin/bash
export
HSA_FORCE_FINE_GRAIN_PCIE
=
1
export
MIOPEN_FIND_MODE
=
3
export
MIOPEN_COMPILE_PARALLEL_LEVEL
=
1
export
NCCL_SOCKET_IFNAME
=
ib0
export
NCCL_P2P_LEVEL
=
5
export
RCCL_NCHANNELS
=
2
export
NCCL_IB_HCA
=
mlx5_0
lrank
=
$OMPI_COMM_WORLD_LOCAL_RANK
echo
"LRANK===============================
$lrank
"
RANK
=
$OMPI_COMM_WORLD_RANK
WORLD_SIZE
=
$OMPI_COMM_WORLD_SIZE
DATASET_PATH
=
../data/dataset.pt
MODEL_PATH
=
model_scope/Llama-2-7b-chat-hf/llama-7b.bin
SPM_MODEL_PATH
=
model_scope/Llama-2-7b-chat-hf/tokenizer.model
APP
=
"python3 ../pretrain.py --deepspeed --deepspeed_config ../models/deepspeed_zero3_config.json
\
--pretrained_model_path
$MODEL_PATH
\
--dataset_path
$DATASET_PATH
--spm_model_path
$SPM_MODEL_PATH
\
--config_path ../models/llama/7b_config.json
\
--output_model_path output/7b/ --deepspeed_checkpoint_activations
\
--world_size
${
2
}
--data_processor alpaca --prefix_lm_loss
\
--total_steps 10000 --save_checkpoint_steps 500 --batch_size 2 --enable_zero3
\
"
case
${
lrank
}
in
[
0]
)
export
HIP_VISIBLE_DEVICES
=
0,1,2,3
export
UCX_NET_DEVICES
=
mlx5_0:1
export
UCX_IB_PCI_BW
=
mlx5_0:50Gbs
numactl
--cpunodebind
=
0
--membind
=
0
${
APP
}
;;
[
1]
)
export
HIP_VISIBLE_DEVICES
=
0,1,2,3
export
UCX_NET_DEVICES
=
mlx5_1:1
export
UCX_IB_PCI_BW
=
mlx5_1:50Gbs
numactl
--cpunodebind
=
1
--membind
=
1
${
APP
}
;;
[
2]
)
export
HIP_VISIBLE_DEVICES
=
0,1,2,3
export
UCX_NET_DEVICES
=
mlx5_2:1
export
UCX_IB_PCI_BW
=
mlx5_2:50Gbs
numactl
--cpunodebind
=
2
--membind
=
2
${
APP
}
;;
[
3]
)
export
HIP_VISIBLE_DEVICES
=
0,1,2,3
export
UCX_NET_DEVICES
=
mlx5_3:1
export
UCX_IB_PCI_BW
=
mlx5_3:50Gbs
numactl
--cpunodebind
=
3
--membind
=
3
${
APP
}
;;
esac
multi_node/run-13b.sh
0 → 100644
View file @
884640da
ulimit
-u
200000
export
HSA_FORCE_FINE_GRAIN_PCIE
=
1
export
MIOPEN_FIND_MODE
=
3
export
MIOPEN_COMPILE_PARALLEL_LEVEL
=
1
export
NCCL_DEBUG
=
INFO
export
NCCL_SOCKET_IFNAME
=
ib0
export
NCCL_P2P_LEVEL
=
5
rm
-rf
./hostfile/
*
echo
"START TIME:
$(
date
)
"
hostfile
=
./hostfile/
$SLURM_JOB_ID
np
=
$(
cat
$hostfile
|sort|uniq |wc
-l
)
np
=
$((
$np
*
4
))
which mpirun
mpirun
-np
$np
--allow-run-as-root
--hostfile
hostfile
--bind-to
none
--mca
btl_tcp_if_include enp97s0f1
`
pwd
`
/run-13b-single.sh 8
echo
"END TIME:
$(
date
)
"
\ No newline at end of file
requirements.txt
View file @
884640da
...
@@ -3,3 +3,4 @@ six>=1.12.0
...
@@ -3,3 +3,4 @@ six>=1.12.0
packaging
packaging
numpy
numpy
regex
regex
sentencepiece
\ No newline at end of file
slurm_scripts/run-13b-pretrain-single.sh
View file @
884640da
#!/bin/bash
#!/bin/bash
# export NCCL_IB_HCA=mlx5
export
HSA_FORCE_FINE_GRAIN_PCIE
=
1
export
HSA_FORCE_FINE_GRAIN_PCIE
=
1
export
MIOPEN_FIND_MODE
=
3
export
MIOPEN_FIND_MODE
=
3
export
MIOPEN_COMPILE_PARALLEL_LEVEL
=
1
export
MIOPEN_COMPILE_PARALLEL_LEVEL
=
1
# export NCCL_PLUGIN_P2P=ucx
export
NCCL_SOCKET_IFNAME
=
ib0
export
NCCL_SOCKET_IFNAME
=
ib0
export
NCCL_P2P_LEVEL
=
5
export
NCCL_P2P_LEVEL
=
5
export
RCCL_NCHANNELS
=
2
export
RCCL_NCHANNELS
=
2
...
...
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}