Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
XUSR-SG
LLaMA_Fastchat_pytorch
Commits
6fc2587d
Commit
6fc2587d
authored
Sep 27, 2023
by
“yuguo”
Browse files
update readme
parent
3813ef17
Changes
3
Hide whitespace changes
Inline
Side-by-side
Showing
3 changed files
with
6 additions
and
68 deletions
+6
-68
README.md
README.md
+4
-66
llama算法原理.png
llama算法原理.png
+0
-0
model.properties
model.properties
+2
-2
No files found.
README.md
View file @
6fc2587d
...
@@ -30,6 +30,8 @@ LLaMA,这是一个基础语言模型的集合,参数范围从7B到65B。在
...
@@ -30,6 +30,8 @@ LLaMA,这是一个基础语言模型的集合,参数范围从7B到65B。在
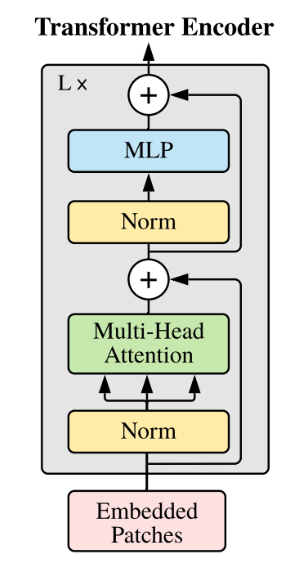
## 算法原理
## 算法原理
以下是与原始 Transformer 架构的主要区别:
以下是与原始 Transformer 架构的主要区别:
**预归一化**
。为了提高训练稳定性,对每个transformer 子层的输入进行归一化,而不是对输出进行归一化。使用 RMSNorm 归一化函数。
**预归一化**
。为了提高训练稳定性,对每个transformer 子层的输入进行归一化,而不是对输出进行归一化。使用 RMSNorm 归一化函数。
...
@@ -44,71 +46,7 @@ LLaMA,这是一个基础语言模型的集合,参数范围从7B到65B。在
...
@@ -44,71 +46,7 @@ LLaMA,这是一个基础语言模型的集合,参数范围从7B到65B。在
./FastChat-main/playground/data/alpaca-data-conversation.json
./FastChat-main/playground/data/alpaca-data-conversation.json
## LLAMA-13B微调(使用mpi)
## LLAMA-13B微调(slurm)
### 环境配置
要求DCU集群Slurm环境正常。
依赖开发者社区torch1.10,deepspeed 0.6.3,apex0.1(可选):https://developer.hpccube.com/tool/
推荐用户使用预编译好的python3.8包来快速建立python3虚拟环境:
cp -r slurm/* ./
根据当前系统更改env.sh中相关路径
virtualenv -p /python_bin_path/python3 --system-site-packages venv_torch3.8
source env.sh #进入venv_torch3.8虚拟环境
pip3 install --upgrade pip -i https://mirrors.aliyun.com/pypi/simple #更新pip
cd FastChat-main
pip3 install -e .
cd ../transformers-main
pip3 install -e .
cd ..
pip3 install torch-1.10.0a0+git2040069.dtk2210-cp38-cp38-manylinux2014_x86_64.whl
pip3 install deepspeed-0.6.3+1b2721a.dtk2210-cp38-cp38-manylinux2014_x86_64.whl
pip3 install apex-0.1+gitdb7007a.dtk2210-cp38-cp38-manylinux2014_x86_64.whl(可选)
### 训练
该训练脚本需要8节点,每节点4张DCU-Z100-16G。
并行配置采用zero3,使用fp16精度微调,如果想使能apex adamw_apex_fused优化器,更改./FastChat-main/fastchat/train/train.py:55行优化器改成adamw_apex_fused。deepspeed config.json如下:
```
{
"train_micro_batch_size_per_gpu": 1,
"gradient_accumulation_steps":4,
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"initial_scale_power": 16,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 3,
"cpu_offload": false,
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"overlap_comm": false,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"contiguous_gradients" : true
}
}
```
进入登陆节点,微调命令:
source submit_job.sh
tail -f log/xxx.out.log #查看输出log
tail -f log/xxx.err.log #查看错误log
## LLAMA-13B微调(无slurm,使用mpi)
### 环境配置
### 环境配置
...
@@ -165,7 +103,7 @@ pip3 install apex-0.1+gitdb7007a.dtk2210-cp38-cp38-manylinux2014_x86_64.whl(
...
@@ -165,7 +103,7 @@ pip3 install apex-0.1+gitdb7007a.dtk2210-cp38-cp38-manylinux2014_x86_64.whl(
source mpi_job.sh
source mpi_job.sh
```
```
##
模型
精度
## 精度
训练数据:
[
./FastChat-main/playground/data/alpaca-data-conversation.json
](
链接
)
训练数据:
[
./FastChat-main/playground/data/alpaca-data-conversation.json
](
链接
)
...
...
llama算法原理.png
0 → 100644
View file @
6fc2587d
32.7 KB
model.properties
View file @
6fc2587d
# 模型唯一标识
# 模型唯一标识
modelCode
=
407
modelCode
=
407
# 模型名称
# 模型名称
modelName
=
LLaMA_F
astchat_pytorch
modelName
=
llama_f
astchat_pytorch
# 模型描述
# 模型描述
modelDescription
=
基于Pytorch框架的llama-13b
modelDescription
=
基于Pytorch框架的llama-13b
# 应用场景(多个标签以英文逗号分割)
# 应用场景(多个标签以英文逗号分割)
appScenario
=
训练,推理,
train,inference,
nlp,智能聊天助手
appScenario
=
训练,推理,nlp,智能聊天助手
,科研
# 框架类型(多个标签以英文逗号分割)
# 框架类型(多个标签以英文逗号分割)
frameType
=
Pytorch,Transformers,Deepspeed
frameType
=
Pytorch,Transformers,Deepspeed
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}