
[major] Support ComfyUI; Improve model loading;
Showing
assets/comfyui.jpg
0 → 100644
{kind=link}
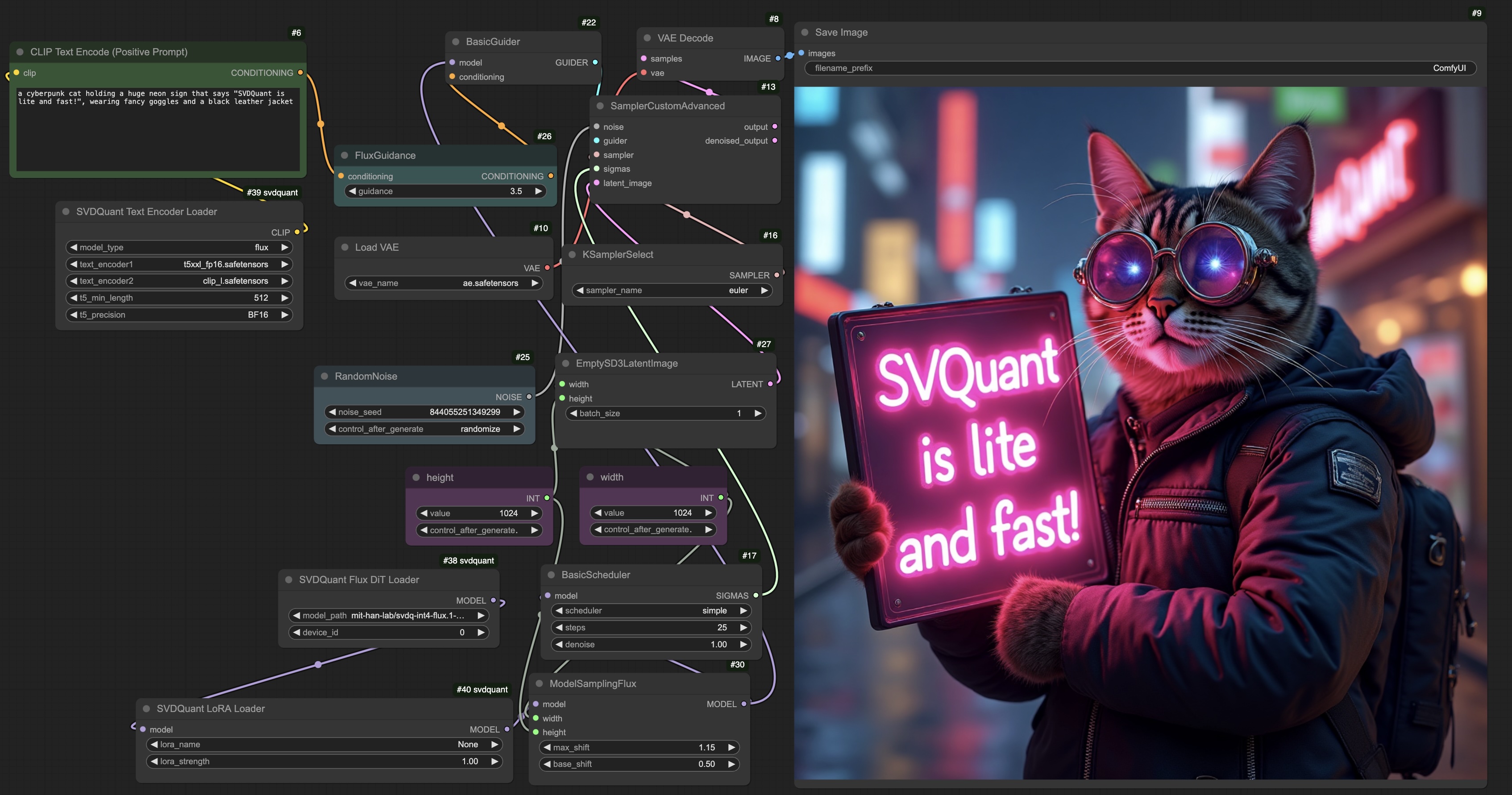
969 KB
comfyui/README.md
0 → 100644
comfyui/__init__.py
0 → 100644
comfyui/nodes.py
0 → 100644
This diff is collapsed.