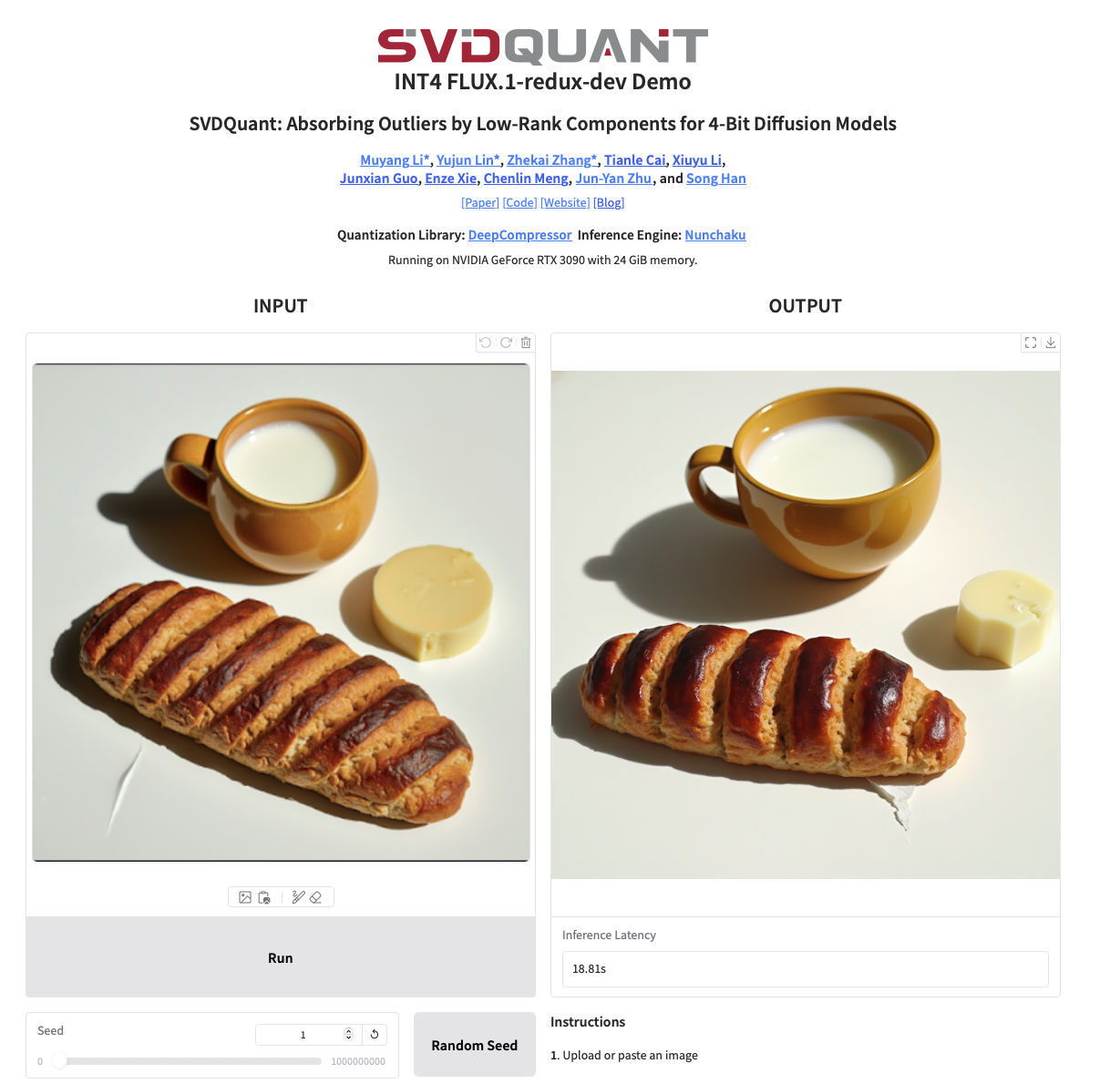
This interactive Gradio application allows you to interactively generate image variations. The base model is [FLUX.1-dev](https://huggingface.co/black-forest-labs/FLUX.1-dev). We use [FLUX.1-Redux-dev](https://huggingface.co/black-forest-labs/FLUX.1-Redux-dev) to preprocess the image before inputting it into Flux.1-dev. To launch the application, run:
```shell
python run_gradio.py
```
* By default, we use our INT4 model. Use `-p bf16` to switch to the BF16 model.

{kind=link}