**Nunchaku** is a high-performance inference engine optimized for 4-bit neural networks, as introduced in our paper [SVDQuant](http://arxiv.org/abs/2411.05007). For the underlying quantization library, check out [DeepCompressor](https://github.com/mit-han-lab/deepcompressor).
**Nunchaku** is a high-performance inference engine optimized for 4-bit neural networks, as introduced in our paper [SVDQuant](http://arxiv.org/abs/2411.05007). For the underlying quantization library, check out [DeepCompressor](https://github.com/mit-han-lab/deepcompressor).
...
@@ -15,6 +15,7 @@ Join our user groups on [**Slack**](https://join.slack.com/t/nunchaku/shared_inv
...
@@ -15,6 +15,7 @@ Join our user groups on [**Slack**](https://join.slack.com/t/nunchaku/shared_inv
## News
## News
-**[2025-04-16]** 🎥 Released tutorial videos in both [**English**](https://youtu.be/YHAVe-oM7U8?si=cM9zaby_aEHiFXk0) and [**Chinese**](https://www.bilibili.com/video/BV1BTocYjEk5/?share_source=copy_web&vd_source=8926212fef622f25cc95380515ac74ee) to assist installation and usage.
-**[2025-04-09]** 📢 Published the [April roadmap](https://github.com/mit-han-lab/nunchaku/issues/266) and an [FAQ](https://github.com/mit-han-lab/nunchaku/discussions/262) to help the community get started and stay up to date with Nunchaku’s development.
-**[2025-04-09]** 📢 Published the [April roadmap](https://github.com/mit-han-lab/nunchaku/issues/266) and an [FAQ](https://github.com/mit-han-lab/nunchaku/discussions/262) to help the community get started and stay up to date with Nunchaku’s development.
-**[2025-04-05]** 🚀 **Nunchaku v0.2.0 released!** This release brings [**multi-LoRA**](examples/flux.1-dev-multiple-lora.py) and [**ControlNet**](examples/flux.1-dev-controlnet-union-pro.py) support with even faster performance powered by [**FP16 attention**](#fp16-attention) and [**First-Block Cache**](#first-block-cache). We've also added compatibility for [**20-series GPUs**](examples/flux.1-dev-turing.py) — Nunchaku is now more accessible than ever!
-**[2025-04-05]** 🚀 **Nunchaku v0.2.0 released!** This release brings [**multi-LoRA**](examples/flux.1-dev-multiple-lora.py) and [**ControlNet**](examples/flux.1-dev-controlnet-union-pro.py) support with even faster performance powered by [**FP16 attention**](#fp16-attention) and [**First-Block Cache**](#first-block-cache). We've also added compatibility for [**20-series GPUs**](examples/flux.1-dev-turing.py) — Nunchaku is now more accessible than ever!
-**[2025-03-17]** 🚀 Released NVFP4 4-bit [Shuttle-Jaguar](https://huggingface.co/mit-han-lab/svdq-int4-shuttle-jaguar) and FLUX.1-tools and also upgraded the INT4 FLUX.1-tool models. Download and update your models from our [HuggingFace](https://huggingface.co/collections/mit-han-lab/svdquant-67493c2c2e62a1fc6e93f45c) or [ModelScope](https://modelscope.cn/collections/svdquant-468e8f780c2641) collections!
-**[2025-03-17]** 🚀 Released NVFP4 4-bit [Shuttle-Jaguar](https://huggingface.co/mit-han-lab/svdq-int4-shuttle-jaguar) and FLUX.1-tools and also upgraded the INT4 FLUX.1-tool models. Download and update your models from our [HuggingFace](https://huggingface.co/collections/mit-han-lab/svdquant-67493c2c2e62a1fc6e93f45c) or [ModelScope](https://modelscope.cn/collections/svdquant-468e8f780c2641) collections!
...
@@ -63,9 +64,10 @@ SVDQuant is a post-training quantization technique for 4-bit weights and activat
...
@@ -63,9 +64,10 @@ SVDQuant is a post-training quantization technique for 4-bit weights and activat
## Performance
## Performance
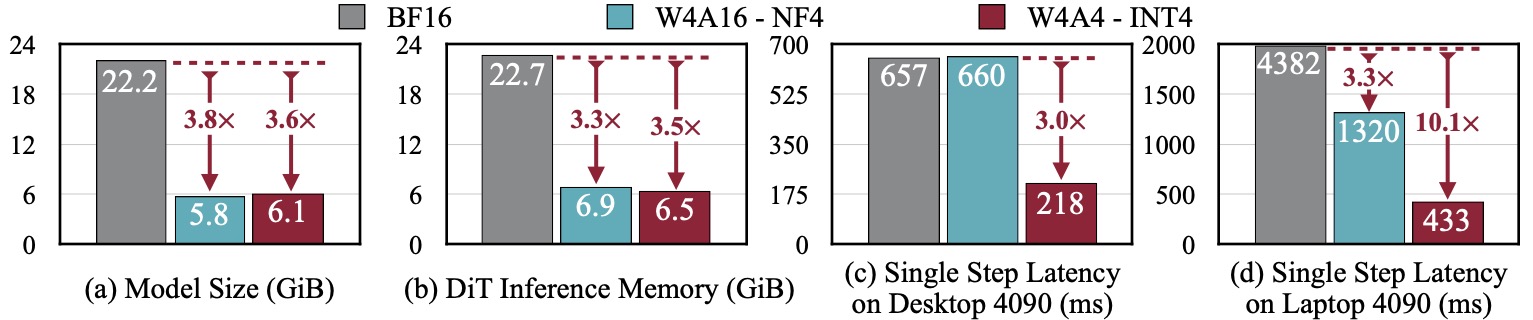
SVDQuant reduces the model size of the 12B FLUX.1 by 3.6×. Additionally, Nunchaku, further cuts memory usage of the 16-bit model by 3.5× and delivers 3.0× speedups over the NF4 W4A16 baseline on both the desktop and laptop NVIDIA RTX 4090 GPUs. Remarkably, on laptop 4090, it achieves in total 10.1× speedup by eliminating CPU offloading.
SVDQuant reduces the 12B FLUX.1 model size by 3.6× and cuts the 16-bit model's memory usage by 3.5×. With Nunchaku, our INT4 model runs 3.0× faster than the NF4 W4A16 baseline on both desktop and laptop NVIDIA RTX 4090 GPUs. Notably, on the laptop 4090, it achieves a total 10.1× speedup by eliminating CPU offloading. Our NVFP4 model is also 3.1× faster than both BF16 and NF4 on the RTX 5090 GPU.
## Installation
## Installation
We provide tutorial videos to help you install and use Nunchaku on Windows, available in both [**English**](https://youtu.be/YHAVe-oM7U8?si=cM9zaby_aEHiFXk0) and [**Chinese**](https://www.bilibili.com/video/BV1BTocYjEk5/?share_source=copy_web&vd_source=8926212fef622f25cc95380515ac74ee). You can also follow the corresponding step-by-step text guide at [`docs/setup_windows.md`](docs/setup_windows.md). If you run into issues, these resources are a good place to start.
### Wheels
### Wheels
...
@@ -163,10 +165,6 @@ If you're using a Blackwell GPU (e.g., 50-series GPUs), install a wheel with PyT
...
@@ -163,10 +165,6 @@ If you're using a Blackwell GPU (e.g., 50-series GPUs), install a wheel with PyT
Make sure to set the environment variable `NUNCHAKU_INSTALL_MODE` to `ALL`. Otherwise, the generated wheels will only work on GPUs with the same architecture as the build machine.
Make sure to set the environment variable `NUNCHAKU_INSTALL_MODE` to `ALL`. Otherwise, the generated wheels will only work on GPUs with the same architecture as the build machine.
### Docker (Coming soon)
**[Optional]** You can verify your installation by running: `python -m nunchaku.test`. This command will download and run our 4-bit FLUX.1-schnell model.
## Usage Example
## Usage Example
In [examples](examples), we provide minimal scripts for running INT4 [FLUX.1](https://github.com/black-forest-labs/flux) and [SANA](https://github.com/NVlabs/Sana) models with Nunchaku. It shares the same APIs as [diffusers](https://github.com/huggingface/diffusers) and can be used in a similar way. For example, the [script](examples/flux.1-dev.py) for [FLUX.1-dev](https://huggingface.co/black-forest-labs/FLUX.1-dev) is as follows:
In [examples](examples), we provide minimal scripts for running INT4 [FLUX.1](https://github.com/black-forest-labs/flux) and [SANA](https://github.com/NVlabs/Sana) models with Nunchaku. It shares the same APIs as [diffusers](https://github.com/huggingface/diffusers) and can be used in a similar way. For example, the [script](examples/flux.1-dev.py) for [FLUX.1-dev](https://huggingface.co/black-forest-labs/FLUX.1-dev) is as follows:
@@ -157,6 +157,14 @@ Please use CMD instead of PowerShell for building.
...
@@ -157,6 +157,14 @@ Please use CMD instead of PowerShell for building.
"G:\ComfyuI\python\python.exe"-m nunchaku.test
"G:\ComfyuI\python\python.exe"-m nunchaku.test
```
```
- (Optional) Step 5: Building wheel for Portable Python
If building directly with portable Python fails, you can first build the wheel in a working Conda environment, then install the `.whl` file using your portable Python:
@@ -209,7 +217,7 @@ Alternatively, install using [ComfyUI-Manager](https://github.com/Comfy-Org/Comf
...
@@ -209,7 +217,7 @@ Alternatively, install using [ComfyUI-Manager](https://github.com/Comfy-Org/Comf
## 3. Set Up Workflows
## 3. Set Up Workflows
To use the official workflows, download them from the [ComfyUI-nunchaku repository](https://github.com/mit-han-lab/ComfyUI-nunchaku/tree/main/workflows) and place them in your `ComfyUI/user/default/workflows` directory. The command can be
To use the official workflows, download them from the [ComfyUI-nunchaku](https://github.com/mit-han-lab/ComfyUI-nunchaku/tree/main/workflows) and place them in your `ComfyUI/user/default/workflows` directory. The command can be

{kind=link}
{kind=link}

{kind=link}
{kind=link}

