[Moondream](https://github.com/vikhyat/moondream) is a computer-vision model can answer real-world questions about images. It's tiny by today's models, with only 1.6B parameters. That enables it to run on a variety of devices, including mobile phones and edge devices.
This example demonstrates how to run [ONNX](https://github.com/onnx/onnx) based models in Candle.
It contains small variants of two models, [SqueezeNet](https://arxiv.org/pdf/1602.07360.pdf)(default) and [EfficientNet](https://arxiv.org/pdf/1905.11946.pdf).
You can run the examples with following commands:
```bash
cargo run --example onnx --features=onnx --release----image candle-examples/examples/yolo-v8/assets/bike.jpg
```
Use the `--which` flag to specify explicitly which network to use, i.e.
```bash
$ cargo run --example onnx --features=onnx --release----which squeeze-net --image candle-examples/examples/yolo-v8/assets/bike.jpg
# candle-phi: 1.3b and 2.7b LLM with state of the art performance for <10b models.
[Phi-1.5](https://huggingface.co/microsoft/phi-1_5) and
[Phi-2](https://huggingface.co/microsoft/phi-2) are language models using
only 1.3 and 2.7 billion parameters but with state of the art performance compared to
models with up to 10 billion parameters.
The candle implementation provides both the standard version as well as a
quantized variant.
## Running some examples
For the v2 version.
```bash
$ cargo run --example phi --release----model 2 \
--prompt"A skier slides down a frictionless slope of height 40m and length 80m. What's the skier speed at the bottom?"
A skier slides down a frictionless slope of height 40m and length 80m. What's the skier speed at the bottom?
Solution:
The potential energy of the skier is converted into kinetic energy as it slides down the slope. The formula for potential energy is mgh, where m is mass, g is acceleration due to gravity (9.8 m/s^2), and h is height. Since there's no friction, all the potential energy is converted into kinetic energy at the bottom of the slope. The formula for kinetic energy is 1/2mv^2, where v is velocity. We can equate these two formulas:
mgh = 1/2mv^2
Solving for v, we get:
v = sqrt(2gh)
Substituting the given values, we get:
v = sqrt(2*9.8*40)= 28 m/s
Therefore, the skier speed at the bottom of the slope is 28 m/s.
```
For the v1.5 version.
```bash
$ cargo run --example phi --release----prompt"def print_prime(n): "
def print_prime(n):
print("Printing prime numbers")
for i in range(2, n+1):
if is_prime(i):
print(i)
def is_prime(n):
if n <= 1:
return False
for i in range(2, int(math.sqrt(n))+1):
if n % i == 0:
return False
return True
$ cargo run --example phi --release--\
--prompt"Explain how to find the median of an array and write the corresponding python function.\nAnswer:"\
--quantized--sample-len 200
Explain how to find the median of an array and write the corresponding python function.
Answer: The median is the middle value in an array. If the array has an even number of elements, the median is the average of the two middle values.
def median(arr):
arr.sort()
n = len(arr)
if n % 2 == 0:
return(arr[n//2 - 1] + arr[n//2]) / 2
else:
return arr[n//2]
```
This also supports the [Puffin Phi v2
model](https://huggingface.co/teknium/Puffin-Phi-v2) for human interaction.
```
$ cargo run --example phi --release -- \
--prompt "USER: What would you do on a sunny day in Paris?\nASSISTANT:" \
MADLAD-400 is a series of multilingual machine translation T5 models trained on 250 billion tokens covering over 450 languages using publicly available data. These models are competitive with significantly larger models.
> The best thing about coding in rust is 1.) that I don’t need to worry about memory leaks, 2.) speed and 3.) my program will compile even on old machines.
```
Using the mixtral sparse mixture of expert model:
```bash
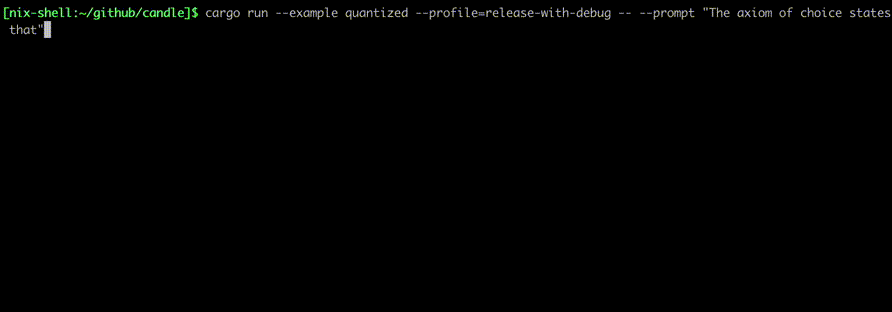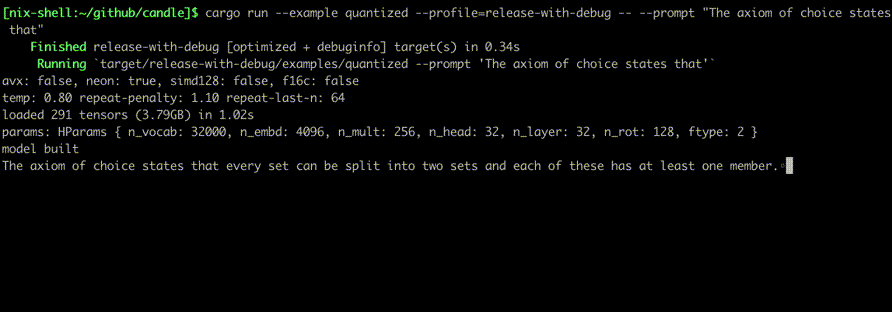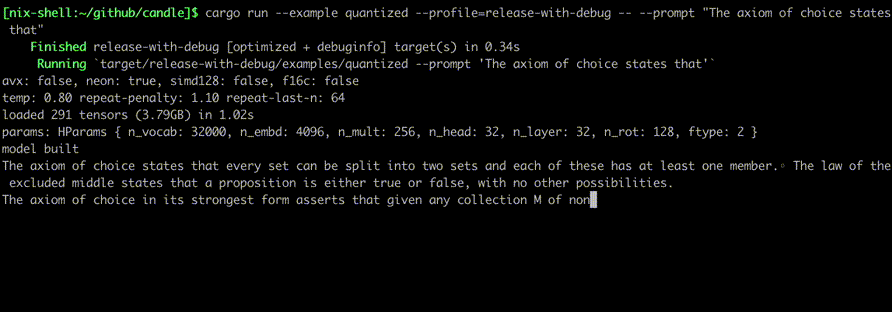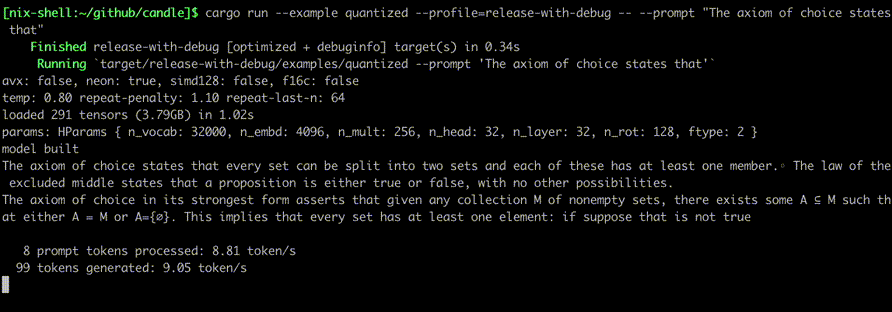
$ cargo run --example quantized --release----which mixtral --prompt"Lebesgue's integral is superior to Riemann's because "
Lebesgue's integral is superior to Riemann's because 1. it is defined for a wider class of functions, those which are absolutely integrable; 2. the definition does not involve limits in two variables---one being computed before the other (which makes some computations more difficult); and 3. interchange of order of integration is easier to establish than with Riemann's integral. On the other hand, Lebesgue's integral applies only for bounded functions defined on finite intervals; it does not provide numerical values for improper integrals. The latter are best evaluated using Cauchy's limit definition.
The reason $f(x) = x^2$ is discontinuous at the ends of its interval of definition, and Riemann's integral requires continuity on the whole of an open interval containing it (see our earlier post), sine no such function exists with this property, is that the endpoints are infinite in measure for Lebesgue's integral.
```
## Command-line flags
Run with `--help` to see all options.
-`--which`: specify the model to use, e.g. `7b`, `13-chat`, `7b-code`.
-`--prompt interactive`: interactive mode where multiple prompts can be
entered.
-`--model mymodelfile.gguf`: use a local model file rather than getting one

{kind=link}