# 算法名简写(英文简写大写)
## 论文
`此处填写实现本项目的算法论文名称`
- 此处填写算法论文的在线pdf地址
## 模型结构
此处一句话简要介绍模型结构
## 算法原理
此处一句话简要介绍算法原理
## 环境配置
### Docker(方法一)
此处提供[光源](https://www.sourcefind.cn/#/service-details)拉取docker镜像的地址与使用步骤
```
docker pull xxx
docker run xxx
```
### Dockerfile(方法二)
此处提供dockerfile的使用方法
```
docker build --no-cache -t xxx:latest .
docker run xxx
```
### Anaconda(方法三)
此处提供本地配置、编译的详细步骤,例如:
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
DTK驱动:dtk23.04
python:python3.8
paddle:2.4.2
```
`Tips:以上dtk驱动、python、paddle等DCU相关工具版本需要严格一一对应`
其它非深度学习库参照requirements.txt安装:
```
pip install -r requirements.txt
```
## 数据集
`此处填写公开数据集名称`
- 此处填写公开数据集下载地址
此处提供数据预处理脚本的使用方法
```
python xxx.py
```
项目中已提供用于试验训练的迷你数据集,训练数据目录结构如下,用于正常训练的完整数据集请按此目录结构进行制备:
```
── dataset
│ ├── label_1
│ ├── xxx.png
│ ├── xxx.png
│ └── ...
│ └── label_2
│ ├── xxx.png
│ ├── xxx.png
│ └── ...
```
## 训练
一般情况下,ModelZoo上的项目提供单机训练的启动方法即可,单机多卡、单机单卡至少提供其一训练方法。
### 单机多卡
```
sh xxx.sh # 或python xxx.py
```
### 单机单卡
```
sh xxx.sh 或python xxx.py
```
## 推理
```
sh xxx.sh 或python xxx.py
```
## result
此处填算法效果测试图
### 精度
测试数据:[test data](链接),使用的加速卡:xxx。
根据测试结果情况填写表格:
| xxx | xxx | xxx | xxx | xxx |
| :------: | :------: | :------: | :------: |:------: |
| xxx | xxx | xxx | xxx | xxx |
| xxx | xx | xxx | xxx | xxx |
## 应用场景
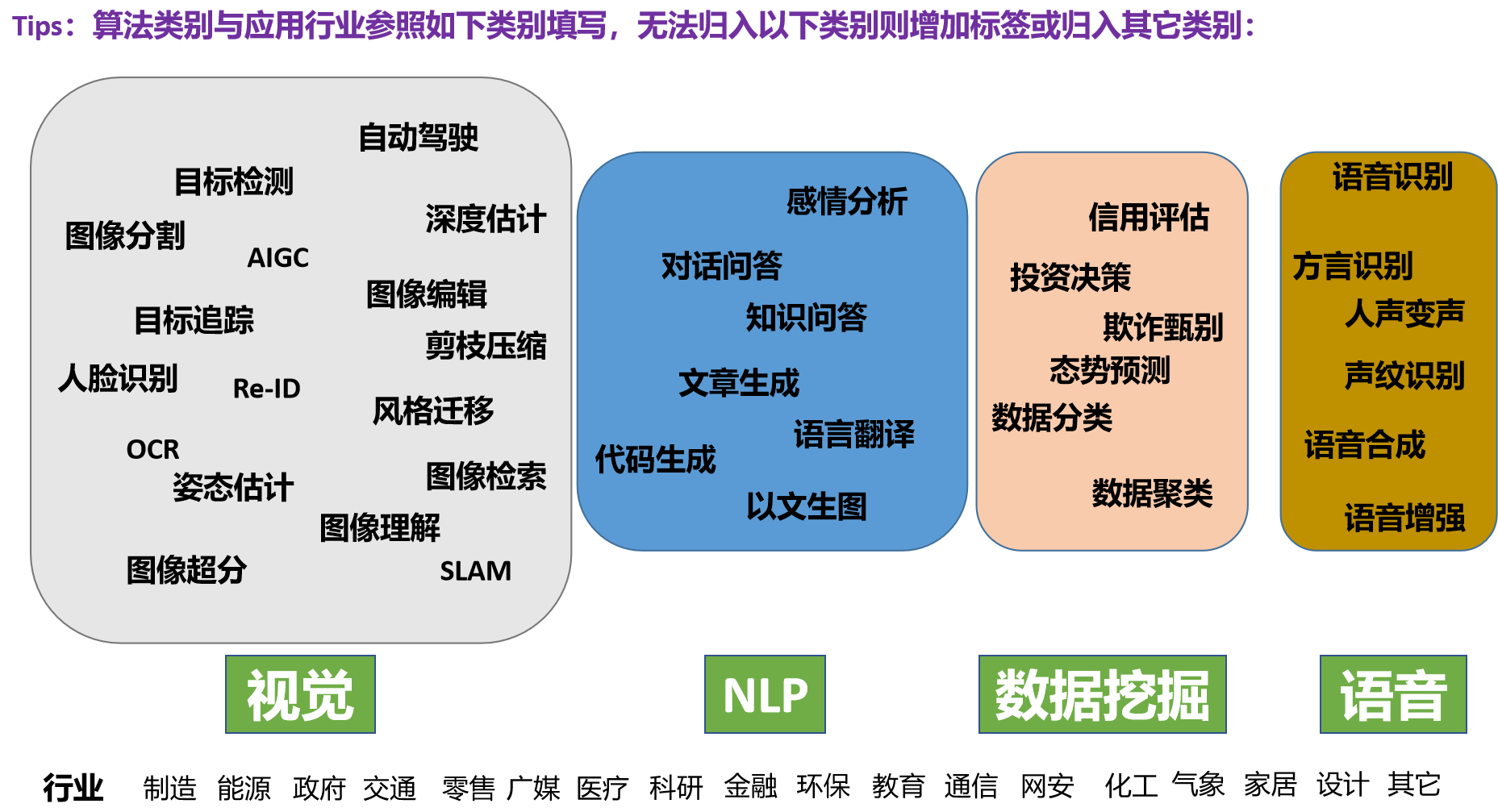
### 算法类别
参考此分类方法(上传时请去除参考图片):
超出以上分类的类别命名也可参考此网址中的类别名:https://huggingface.co/
`此处填算法类别`
### 热点应用行业
应用行业的填写需要做大量调研,从而为使用者提供专业、全面的推荐,除特殊算法,通常推荐数量>=3。
`此处填应用行业`
## 预训练权重
`(若为github原预训练权重此标题可去除。)`
## 源码仓库及问题反馈
- 此处填本项目gitlab地址
## 参考资料
- 此处填源github地址(方便使用者查看原github issue)
- 此处填参考项目或教程网址
- ......