
fix conflict
Showing
{kind=link}
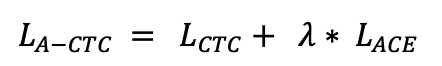
10.2 KB
{kind=link}
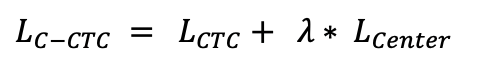
10.6 KB
{kind=link}
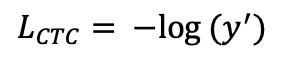
9.33 KB
{kind=link}
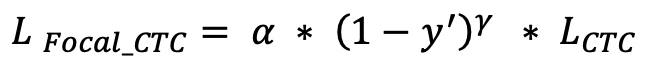
14.5 KB
{kind=link}
23.3 KB
{kind=link}
125 KB
doc/doc_ch/models.md
0 → 100644
{kind=link}
224 KB
doc/doc_ch/thirdparty.md
0 → 100644
10.2 KB
10.6 KB
9.33 KB
14.5 KB
23.3 KB
125 KB
224 KB