
fix conflict
Showing
doc/table/pipeline.jpg
0 → 100644
{kind=link}
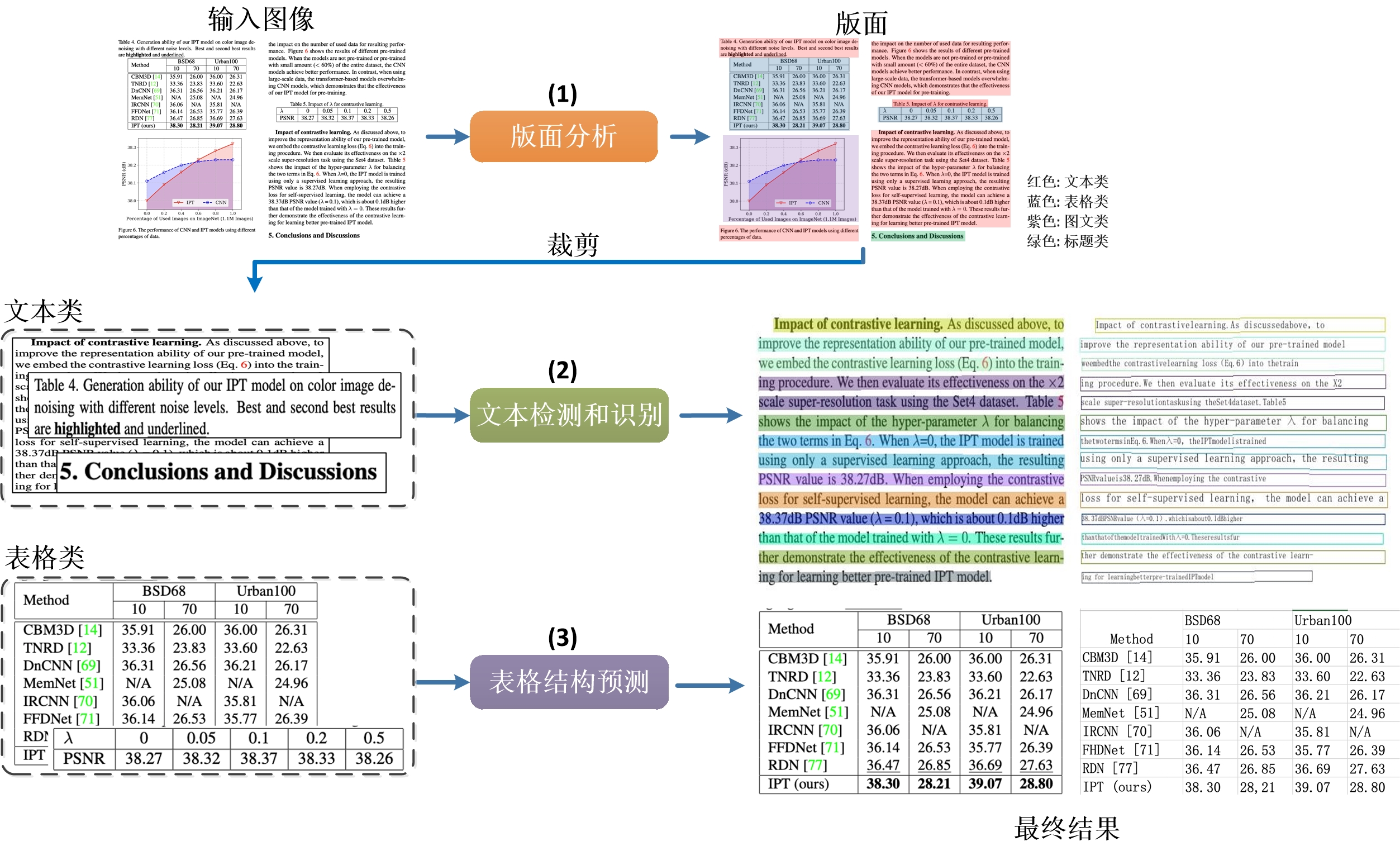
1.46 MB
doc/table/pipeline_en.jpg
0 → 100644
{kind=link}
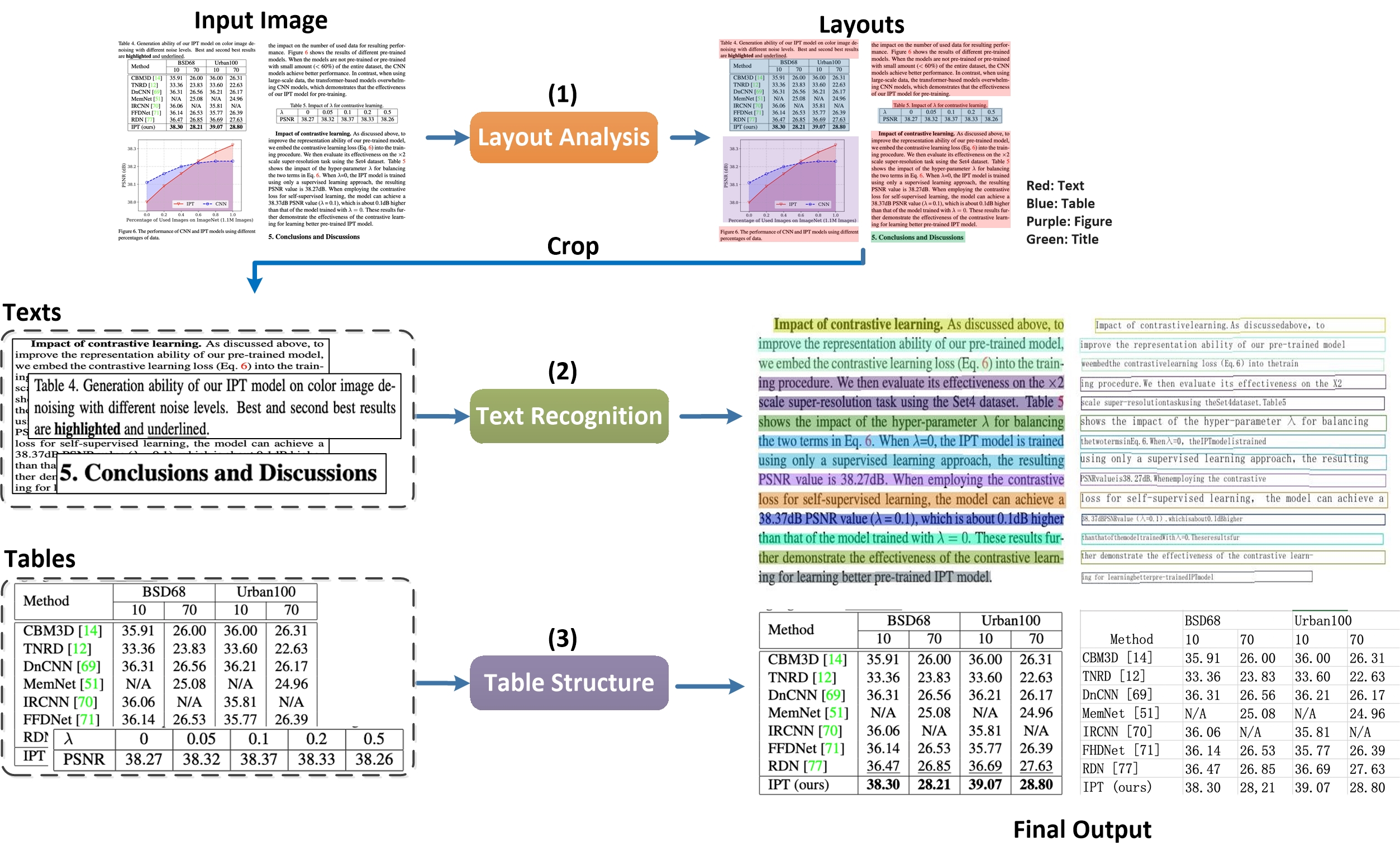
1.45 MB
doc/table/ppstructure.GIF
0 → 100644
{kind=link}

2.49 MB
doc/table/result_all.jpg
0 → 100644
{kind=link}
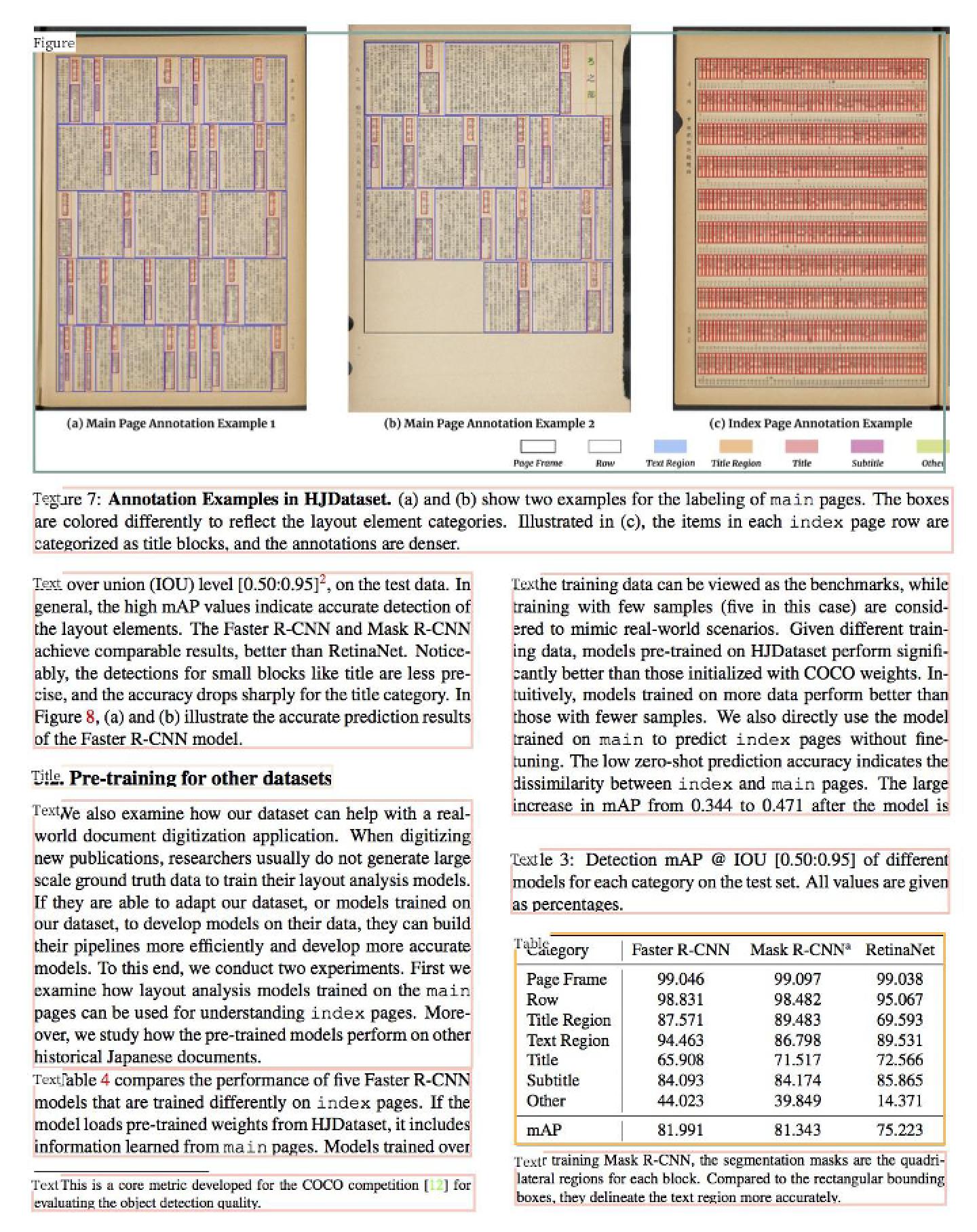
521 KB
doc/table/result_text.jpg
0 → 100644
{kind=link}

146 KB
doc/table/table.jpg
0 → 100644
{kind=link}

24.1 KB
{kind=link}
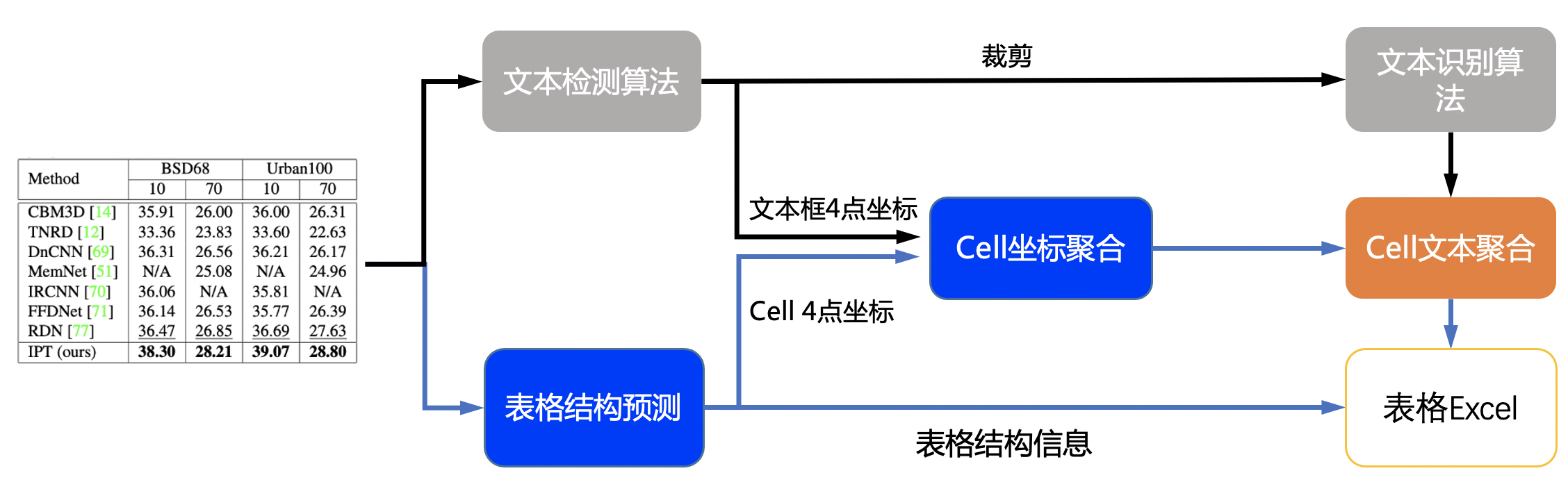
552 KB
{kind=link}

416 KB
This diff is collapsed.
ppocr/data/pubtab_dataset.py
0 → 100644
ppocr/losses/basic_loss.py
0 → 100644