* 编译时,如果报错`错误:C1083 无法打开包括文件:"dirent.h":No such file or directory`,可以参考该[文档](https://blog.csdn.net/Dora_blank/article/details/117740837#41_C1083_direnthNo_such_file_or_directory_54),新建`dirent.h`文件,并添加到`VC++`的包含目录中。
* First of all, you need to download the source code compiled package in the Linux environment from the opencv official website. Taking opencv3.4.7 as an example, the download command is as follows.
* First of all, you need to download the source code compiled package in the Linux environment from the opencv official website. Taking opencv3.4.7 as an example, the download command is as follows.
**For SAST curved text detection model inference, you need to set the parameter `--det_algorithm="SAST"` and `--det_sast_polygon=True`**, run the following command:
For SAST curved text detection model inference, you need to set the parameter `--det_algorithm="SAST"` and `--det_sast_polygon=True`, run the following command:
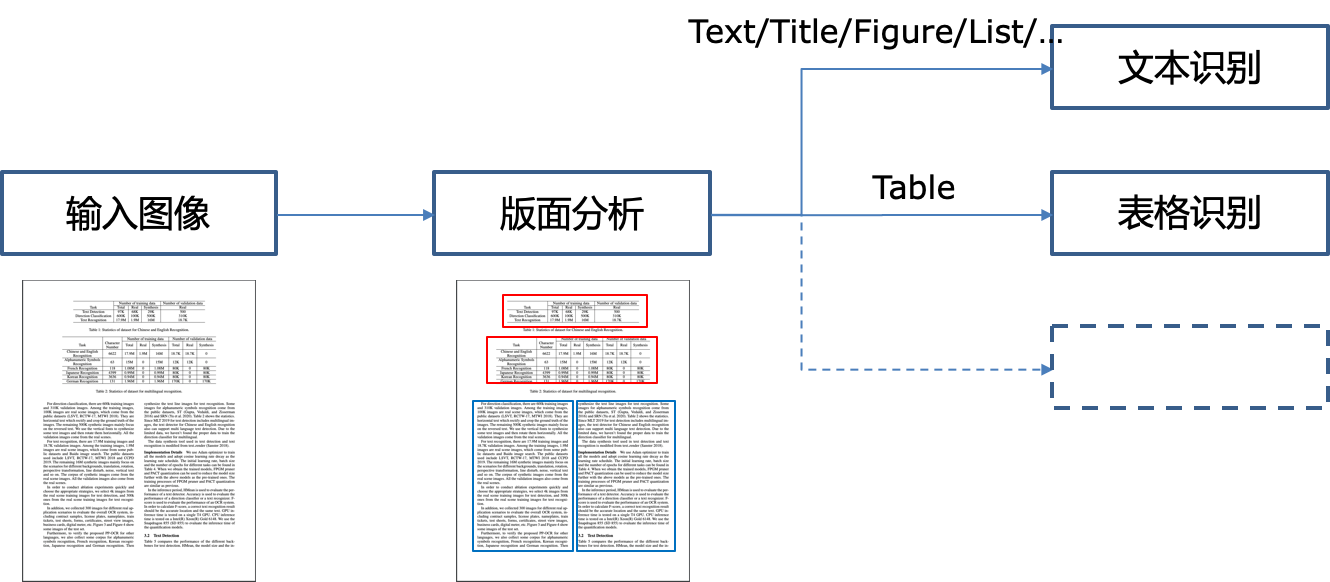
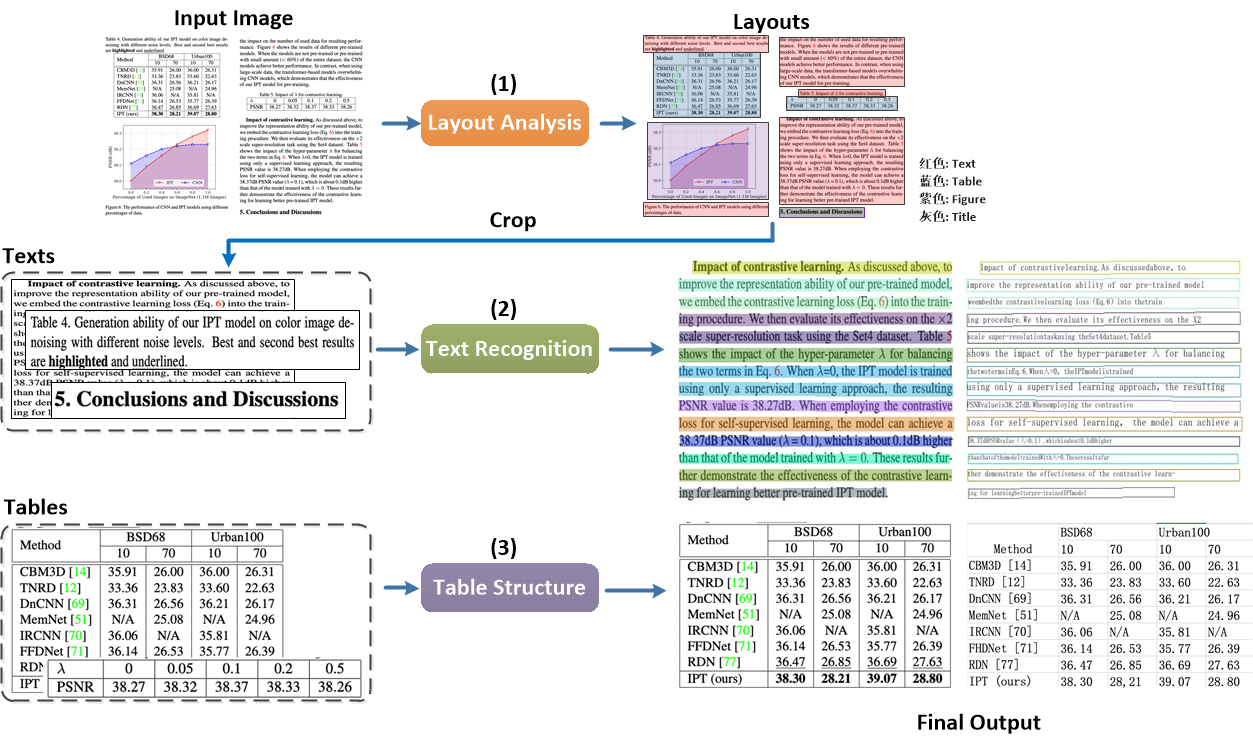
PaddleStructure is a toolkit for complex layout text OCR, the process is as follows
PaddleStructure is a toolkit for complex layout text OCR, the process is as follows


In PaddleStructure, the image will be analyzed by layoutparser first. In the layout analysis, the area in the image will be classified, and the OCR process will be carried out according to the category.
In PaddleStructure, the image will be analyzed by layoutparser first. In the layout analysis, the area in the image will be classified, and the OCR process will be carried out according to the category.

{kind=link}
{kind=link}


{kind=link}
{kind=link}