Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
wangsen
paddle_dbnet
Commits
41a1b292
Commit
41a1b292
authored
Jan 20, 2022
by
Leif
Browse files
Merge remote-tracking branch 'origin/dygraph' into dygraph
parents
9471054e
3d30899b
Changes
162
Hide whitespace changes
Inline
Side-by-side
Showing
20 changed files
with
1683 additions
and
4 deletions
+1683
-4
test_tipc/supplementary/optimizer.py
test_tipc/supplementary/optimizer.py
+325
-0
test_tipc/supplementary/readme.md
test_tipc/supplementary/readme.md
+67
-0
test_tipc/supplementary/requirements.txt
test_tipc/supplementary/requirements.txt
+1
-0
test_tipc/supplementary/slim/__init__.py
test_tipc/supplementary/slim/__init__.py
+0
-0
test_tipc/supplementary/slim/slim_fpgm.py
test_tipc/supplementary/slim/slim_fpgm.py
+22
-0
test_tipc/supplementary/slim/slim_quant.py
test_tipc/supplementary/slim/slim_quant.py
+48
-0
test_tipc/supplementary/test_tipc/common_func.sh
test_tipc/supplementary/test_tipc/common_func.sh
+65
-0
test_tipc/supplementary/test_tipc/test_train_python.sh
test_tipc/supplementary/test_tipc/test_train_python.sh
+117
-0
test_tipc/supplementary/test_tipc/tipc_train.png
test_tipc/supplementary/test_tipc/tipc_train.png
+0
-0
test_tipc/supplementary/test_tipc/train_infer_python.txt
test_tipc/supplementary/test_tipc/train_infer_python.txt
+17
-0
test_tipc/supplementary/test_tipc/train_infer_python_FPGM.txt
..._tipc/supplementary/test_tipc/train_infer_python_FPGM.txt
+17
-0
test_tipc/supplementary/test_tipc/train_infer_python_PACT.txt
..._tipc/supplementary/test_tipc/train_infer_python_PACT.txt
+17
-0
test_tipc/supplementary/train.py
test_tipc/supplementary/train.py
+474
-0
test_tipc/supplementary/train.sh
test_tipc/supplementary/train.sh
+5
-0
test_tipc/supplementary/utils.py
test_tipc/supplementary/utils.py
+164
-0
test_tipc/test_train_inference_python.sh
test_tipc/test_train_inference_python.sh
+7
-2
tools/eval.py
tools/eval.py
+2
-1
tools/export_model.py
tools/export_model.py
+1
-1
tools/infer_vqa_token_ser.py
tools/infer_vqa_token_ser.py
+135
-0
tools/infer_vqa_token_ser_re.py
tools/infer_vqa_token_ser_re.py
+199
-0
No files found.
test_tipc/supplementary/optimizer.py
0 → 100644
View file @
41a1b292
import
sys
import
math
from
paddle.optimizer.lr
import
LinearWarmup
from
paddle.optimizer.lr
import
PiecewiseDecay
from
paddle.optimizer.lr
import
CosineAnnealingDecay
from
paddle.optimizer.lr
import
ExponentialDecay
import
paddle
import
paddle.regularizer
as
regularizer
from
copy
import
deepcopy
class
Cosine
(
CosineAnnealingDecay
):
"""
Cosine learning rate decay
lr = 0.05 * (math.cos(epoch * (math.pi / epochs)) + 1)
Args:
lr(float): initial learning rate
step_each_epoch(int): steps each epoch
epochs(int): total training epochs
"""
def
__init__
(
self
,
lr
,
step_each_epoch
,
epochs
,
**
kwargs
):
super
(
Cosine
,
self
).
__init__
(
learning_rate
=
lr
,
T_max
=
step_each_epoch
*
epochs
,
)
self
.
update_specified
=
False
class
Piecewise
(
PiecewiseDecay
):
"""
Piecewise learning rate decay
Args:
lr(float): initial learning rate
step_each_epoch(int): steps each epoch
decay_epochs(list): piecewise decay epochs
gamma(float): decay factor
"""
def
__init__
(
self
,
lr
,
step_each_epoch
,
decay_epochs
,
gamma
=
0.1
,
**
kwargs
):
boundaries
=
[
step_each_epoch
*
e
for
e
in
decay_epochs
]
lr_values
=
[
lr
*
(
gamma
**
i
)
for
i
in
range
(
len
(
boundaries
)
+
1
)]
super
(
Piecewise
,
self
).
__init__
(
boundaries
=
boundaries
,
values
=
lr_values
)
self
.
update_specified
=
False
class
CosineWarmup
(
LinearWarmup
):
"""
Cosine learning rate decay with warmup
[0, warmup_epoch): linear warmup
[warmup_epoch, epochs): cosine decay
Args:
lr(float): initial learning rate
step_each_epoch(int): steps each epoch
epochs(int): total training epochs
warmup_epoch(int): epoch num of warmup
"""
def
__init__
(
self
,
lr
,
step_each_epoch
,
epochs
,
warmup_epoch
=
5
,
**
kwargs
):
assert
epochs
>
warmup_epoch
,
"total epoch({}) should be larger than warmup_epoch({}) in CosineWarmup."
.
format
(
epochs
,
warmup_epoch
)
warmup_step
=
warmup_epoch
*
step_each_epoch
start_lr
=
0.0
end_lr
=
lr
lr_sch
=
Cosine
(
lr
,
step_each_epoch
,
epochs
-
warmup_epoch
)
super
(
CosineWarmup
,
self
).
__init__
(
learning_rate
=
lr_sch
,
warmup_steps
=
warmup_step
,
start_lr
=
start_lr
,
end_lr
=
end_lr
)
self
.
update_specified
=
False
class
ExponentialWarmup
(
LinearWarmup
):
"""
Exponential learning rate decay with warmup
[0, warmup_epoch): linear warmup
[warmup_epoch, epochs): Exponential decay
Args:
lr(float): initial learning rate
step_each_epoch(int): steps each epoch
decay_epochs(float): decay epochs
decay_rate(float): decay rate
warmup_epoch(int): epoch num of warmup
"""
def
__init__
(
self
,
lr
,
step_each_epoch
,
decay_epochs
=
2.4
,
decay_rate
=
0.97
,
warmup_epoch
=
5
,
**
kwargs
):
warmup_step
=
warmup_epoch
*
step_each_epoch
start_lr
=
0.0
end_lr
=
lr
lr_sch
=
ExponentialDecay
(
lr
,
decay_rate
)
super
(
ExponentialWarmup
,
self
).
__init__
(
learning_rate
=
lr_sch
,
warmup_steps
=
warmup_step
,
start_lr
=
start_lr
,
end_lr
=
end_lr
)
# NOTE: hac method to update exponential lr scheduler
self
.
update_specified
=
True
self
.
update_start_step
=
warmup_step
self
.
update_step_interval
=
int
(
decay_epochs
*
step_each_epoch
)
self
.
step_each_epoch
=
step_each_epoch
class
LearningRateBuilder
():
"""
Build learning rate variable
https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/layers_cn.html
Args:
function(str): class name of learning rate
params(dict): parameters used for init the class
"""
def
__init__
(
self
,
function
=
'Linear'
,
params
=
{
'lr'
:
0.1
,
'steps'
:
100
,
'end_lr'
:
0.0
}):
self
.
function
=
function
self
.
params
=
params
def
__call__
(
self
):
mod
=
sys
.
modules
[
__name__
]
lr
=
getattr
(
mod
,
self
.
function
)(
**
self
.
params
)
return
lr
class
L1Decay
(
object
):
"""
L1 Weight Decay Regularization, which encourages the weights to be sparse.
Args:
factor(float): regularization coeff. Default:0.0.
"""
def
__init__
(
self
,
factor
=
0.0
):
super
(
L1Decay
,
self
).
__init__
()
self
.
factor
=
factor
def
__call__
(
self
):
reg
=
regularizer
.
L1Decay
(
self
.
factor
)
return
reg
class
L2Decay
(
object
):
"""
L2 Weight Decay Regularization, which encourages the weights to be sparse.
Args:
factor(float): regularization coeff. Default:0.0.
"""
def
__init__
(
self
,
factor
=
0.0
):
super
(
L2Decay
,
self
).
__init__
()
self
.
factor
=
factor
def
__call__
(
self
):
reg
=
regularizer
.
L2Decay
(
self
.
factor
)
return
reg
class
Momentum
(
object
):
"""
Simple Momentum optimizer with velocity state.
Args:
learning_rate (float|Variable) - The learning rate used to update parameters.
Can be a float value or a Variable with one float value as data element.
momentum (float) - Momentum factor.
regularization (WeightDecayRegularizer, optional) - The strategy of regularization.
"""
def
__init__
(
self
,
learning_rate
,
momentum
,
parameter_list
=
None
,
regularization
=
None
,
**
args
):
super
(
Momentum
,
self
).
__init__
()
self
.
learning_rate
=
learning_rate
self
.
momentum
=
momentum
self
.
parameter_list
=
parameter_list
self
.
regularization
=
regularization
def
__call__
(
self
):
opt
=
paddle
.
optimizer
.
Momentum
(
learning_rate
=
self
.
learning_rate
,
momentum
=
self
.
momentum
,
parameters
=
self
.
parameter_list
,
weight_decay
=
self
.
regularization
)
return
opt
class
RMSProp
(
object
):
"""
Root Mean Squared Propagation (RMSProp) is an unpublished, adaptive learning rate method.
Args:
learning_rate (float|Variable) - The learning rate used to update parameters.
Can be a float value or a Variable with one float value as data element.
momentum (float) - Momentum factor.
rho (float) - rho value in equation.
epsilon (float) - avoid division by zero, default is 1e-6.
regularization (WeightDecayRegularizer, optional) - The strategy of regularization.
"""
def
__init__
(
self
,
learning_rate
,
momentum
,
rho
=
0.95
,
epsilon
=
1e-6
,
parameter_list
=
None
,
regularization
=
None
,
**
args
):
super
(
RMSProp
,
self
).
__init__
()
self
.
learning_rate
=
learning_rate
self
.
momentum
=
momentum
self
.
rho
=
rho
self
.
epsilon
=
epsilon
self
.
parameter_list
=
parameter_list
self
.
regularization
=
regularization
def
__call__
(
self
):
opt
=
paddle
.
optimizer
.
RMSProp
(
learning_rate
=
self
.
learning_rate
,
momentum
=
self
.
momentum
,
rho
=
self
.
rho
,
epsilon
=
self
.
epsilon
,
parameters
=
self
.
parameter_list
,
weight_decay
=
self
.
regularization
)
return
opt
class
OptimizerBuilder
(
object
):
"""
Build optimizer
Args:
function(str): optimizer name of learning rate
params(dict): parameters used for init the class
regularizer (dict): parameters used for create regularization
"""
def
__init__
(
self
,
function
=
'Momentum'
,
params
=
{
'momentum'
:
0.9
},
regularizer
=
None
):
self
.
function
=
function
self
.
params
=
params
# create regularizer
if
regularizer
is
not
None
:
mod
=
sys
.
modules
[
__name__
]
reg_func
=
regularizer
[
'function'
]
+
'Decay'
del
regularizer
[
'function'
]
reg
=
getattr
(
mod
,
reg_func
)(
**
regularizer
)()
self
.
params
[
'regularization'
]
=
reg
def
__call__
(
self
,
learning_rate
,
parameter_list
=
None
):
mod
=
sys
.
modules
[
__name__
]
opt
=
getattr
(
mod
,
self
.
function
)
return
opt
(
learning_rate
=
learning_rate
,
parameter_list
=
parameter_list
,
**
self
.
params
)()
def
create_optimizer
(
config
,
parameter_list
=
None
):
"""
Create an optimizer using config, usually including
learning rate and regularization.
Args:
config(dict): such as
{
'LEARNING_RATE':
{'function': 'Cosine',
'params': {'lr': 0.1}
},
'OPTIMIZER':
{'function': 'Momentum',
'params':{'momentum': 0.9},
'regularizer':
{'function': 'L2', 'factor': 0.0001}
}
}
Returns:
an optimizer instance
"""
# create learning_rate instance
lr_config
=
config
[
'LEARNING_RATE'
]
lr_config
[
'params'
].
update
({
'epochs'
:
config
[
'epoch'
],
'step_each_epoch'
:
config
[
'total_images'
]
//
config
[
'TRAIN'
][
'batch_size'
],
})
lr
=
LearningRateBuilder
(
**
lr_config
)()
# create optimizer instance
opt_config
=
deepcopy
(
config
[
'OPTIMIZER'
])
opt
=
OptimizerBuilder
(
**
opt_config
)
return
opt
(
lr
,
parameter_list
),
lr
def
create_multi_optimizer
(
config
,
parameter_list
=
None
):
"""
"""
# create learning_rate instance
lr_config
=
config
[
'LEARNING_RATE'
]
lr_config
[
'params'
].
update
({
'epochs'
:
config
[
'epoch'
],
'step_each_epoch'
:
config
[
'total_images'
]
//
config
[
'TRAIN'
][
'batch_size'
],
})
lr
=
LearningRateBuilder
(
**
lr_config
)()
# create optimizer instance
opt_config
=
deepcopy
.
copy
(
config
[
'OPTIMIZER'
])
opt
=
OptimizerBuilder
(
**
opt_config
)
return
opt
(
lr
,
parameter_list
),
lr
test_tipc/supplementary/readme.md
0 → 100644
View file @
41a1b292
# TIPC Linux端补充训练功能测试
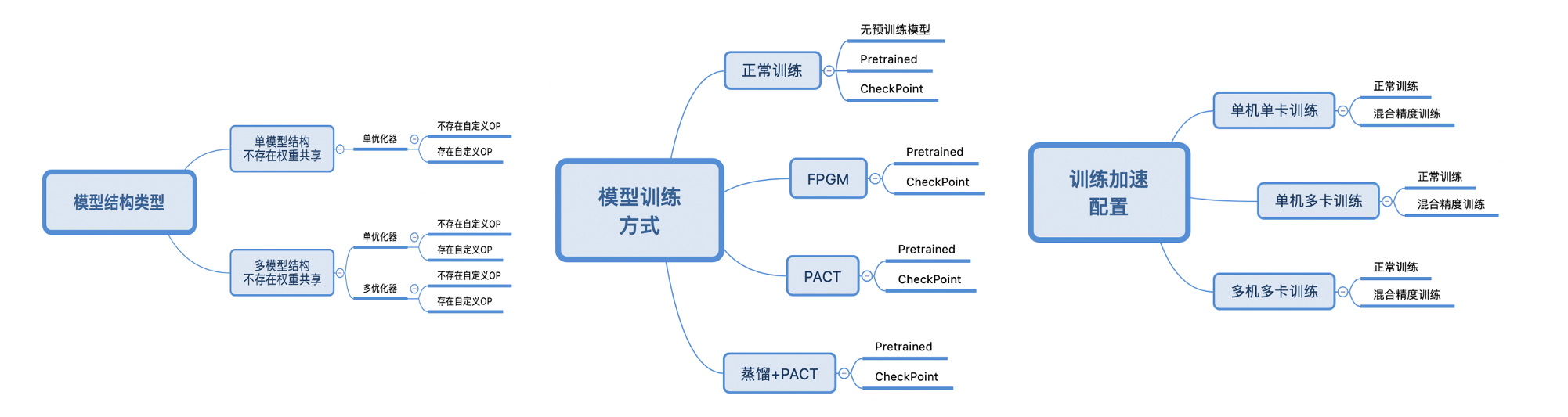
Linux端基础训练预测功能测试的主程序为test_train_python.sh,可以测试基于Python的模型训练、评估等基本功能,包括裁剪、量化、蒸馏训练。

测试链条如上图所示,主要测试内容有带共享权重,自定义OP的模型的正常训练和slim相关功能训练流程是否正常。
# 2. 测试流程
本节介绍补充链条的测试流程
## 2.1 安装依赖
-
安装PaddlePaddle >= 2.2
-
安装其他依赖
```
pip3 install -r requirements.txt
```
## 2.2 功能测试
`test_train_python.sh`
包含2种运行模式,每种模式的运行数据不同,分别用于测试训练是否正常,分别是:
-
模式1:lite_train_lite_infer,使用少量数据训练,用于快速验证训练到预测的走通流程,不验证精度和速度;
```
bash test_tipc/test_train_python.sh ./test_tipc/ch_ppocr_mobile_v2.0_det/train_infer_python.txt 'lite_train_lite_infer'
```
-
模式2:whole_train_whole_infer,使用全量数据训练,用于快速验证训练到预测的走通流程,验证模型最终训练精度;
```
bash test_tipc/test_train_python.sh ./test_tipc/ch_ppocr_mobile_v2.0_det/train_infer_python.txt 'whole_train_whole_infer'
```
如果是运行量化裁剪等训练方式,需要使用不同的配置文件。量化训练的测试指令如下:
```
bash test_tipc/test_train_python.sh ./test_tipc/ch_ppocr_mobile_v2.0_det/train_infer_python_PACT.txt 'lite_train_lite_infer'
```
同理,FPGM裁剪的运行方式如下:
```
bash test_tipc/test_train_python.sh ./test_tipc/ch_ppocr_mobile_v2.0_det/train_infer_python_FPGM.txt 'lite_train_lite_infer'
```
运行相应指令后,在
`test_tipc/output`
文件夹下自动会保存运行日志。如'lite_train_lite_infer'模式运行后,在test_tipc/extra_output文件夹有以下文件:
```
test_tipc/output/
|- results_python.log # 运行指令状态的日志
```
其中results_python.log中包含了每条指令的运行状态,如果运行成功会输出:
```
Run successfully with command - python3.7 train.py -c mv3_large_x0_5.yml -o use_gpu=True epoch=20 AMP.use_amp=True TRAIN.batch_size=1280 use_custom_relu=False model_type=cls MODEL.siamese=False !
Run successfully with command - python3.7 train.py -c mv3_large_x0_5.yml -o use_gpu=True epoch=2 AMP.use_amp=True TRAIN.batch_size=1280 use_custom_relu=False model_type=cls MODEL.siamese=False !
Run successfully with command - python3.7 train.py -c mv3_large_x0_5.yml -o use_gpu=True epoch=2 AMP.use_amp=True TRAIN.batch_size=1280 use_custom_relu=False model_type=cls MODEL.siamese=True !
Run successfully with command - python3.7 train.py -c mv3_large_x0_5.yml -o use_gpu=True epoch=2 AMP.use_amp=True TRAIN.batch_size=1280 use_custom_relu=False model_type=cls_distill MODEL.siamese=False !
Run successfully with command - python3.7 train.py -c mv3_large_x0_5.yml -o use_gpu=True epoch=2 AMP.use_amp=True TRAIN.batch_size=1280 use_custom_relu=False model_type=cls_distill MODEL.siamese=True !
Run successfully with command - python3.7 train.py -c mv3_large_x0_5.yml -o use_gpu=True epoch=2 AMP.use_amp=True TRAIN.batch_size=1280 use_custom_relu=False model_type=cls_distill_multiopt MODEL.siamese=False !
```
test_tipc/supplementary/requirements.txt
0 → 100644
View file @
41a1b292
paddleslim==2.2.1
test_tipc/supplementary/slim/__init__.py
0 → 100644
View file @
41a1b292
test_tipc/supplementary/slim/slim_fpgm.py
0 → 100644
View file @
41a1b292
import
paddleslim
import
paddle
import
numpy
as
np
from
paddleslim.dygraph
import
FPGMFilterPruner
def
prune_model
(
model
,
input_shape
,
prune_ratio
=
0.1
):
flops
=
paddle
.
flops
(
model
,
input_shape
)
pruner
=
FPGMFilterPruner
(
model
,
input_shape
)
params_sensitive
=
{}
for
param
in
model
.
parameters
():
if
'transpose'
not
in
param
.
name
and
'linear'
not
in
param
.
name
:
# set prune ratio as 10%. The larger the value, the more convolution weights will be cropped
params_sensitive
[
param
.
name
]
=
prune_ratio
plan
=
pruner
.
prune_vars
(
params_sensitive
,
[
0
])
flops
=
paddle
.
flops
(
model
,
input_shape
)
return
model
test_tipc/supplementary/slim/slim_quant.py
0 → 100644
View file @
41a1b292
import
paddle
import
numpy
as
np
import
os
import
paddle.nn
as
nn
import
paddleslim
class
PACT
(
paddle
.
nn
.
Layer
):
def
__init__
(
self
):
super
(
PACT
,
self
).
__init__
()
alpha_attr
=
paddle
.
ParamAttr
(
name
=
self
.
full_name
()
+
".pact"
,
initializer
=
paddle
.
nn
.
initializer
.
Constant
(
value
=
20
),
learning_rate
=
1.0
,
regularizer
=
paddle
.
regularizer
.
L2Decay
(
2e-5
))
self
.
alpha
=
self
.
create_parameter
(
shape
=
[
1
],
attr
=
alpha_attr
,
dtype
=
'float32'
)
def
forward
(
self
,
x
):
out_left
=
paddle
.
nn
.
functional
.
relu
(
x
-
self
.
alpha
)
out_right
=
paddle
.
nn
.
functional
.
relu
(
-
self
.
alpha
-
x
)
x
=
x
-
out_left
+
out_right
return
x
quant_config
=
{
# weight preprocess type, default is None and no preprocessing is performed.
'weight_preprocess_type'
:
None
,
# activation preprocess type, default is None and no preprocessing is performed.
'activation_preprocess_type'
:
None
,
# weight quantize type, default is 'channel_wise_abs_max'
'weight_quantize_type'
:
'channel_wise_abs_max'
,
# activation quantize type, default is 'moving_average_abs_max'
'activation_quantize_type'
:
'moving_average_abs_max'
,
# weight quantize bit num, default is 8
'weight_bits'
:
8
,
# activation quantize bit num, default is 8
'activation_bits'
:
8
,
# data type after quantization, such as 'uint8', 'int8', etc. default is 'int8'
'dtype'
:
'int8'
,
# window size for 'range_abs_max' quantization. default is 10000
'window_size'
:
10000
,
# The decay coefficient of moving average, default is 0.9
'moving_rate'
:
0.9
,
# for dygraph quantization, layers of type in quantizable_layer_type will be quantized
'quantizable_layer_type'
:
[
'Conv2D'
,
'Linear'
],
}
test_tipc/supplementary/test_tipc/common_func.sh
0 → 100644
View file @
41a1b292
#!/bin/bash
function
func_parser_key
(){
strs
=
$1
IFS
=
":"
array
=(
${
strs
}
)
tmp
=
${
array
[0]
}
echo
${
tmp
}
}
function
func_parser_value
(){
strs
=
$1
IFS
=
":"
array
=(
${
strs
}
)
tmp
=
${
array
[1]
}
echo
${
tmp
}
}
function
func_set_params
(){
key
=
$1
value
=
$2
if
[
${
key
}
x
=
"null"
x
]
;
then
echo
" "
elif
[[
${
value
}
=
"null"
]]
||
[[
${
value
}
=
" "
]]
||
[
${#
value
}
-le
0
]
;
then
echo
" "
else
echo
"
${
key
}
=
${
value
}
"
fi
}
function
func_parser_params
(){
strs
=
$1
MODE
=
$2
IFS
=
":"
array
=(
${
strs
}
)
key
=
${
array
[0]
}
tmp
=
${
array
[1]
}
IFS
=
"|"
res
=
""
for
_params
in
${
tmp
[*]
}
;
do
IFS
=
"="
array
=(
${
_params
}
)
mode
=
${
array
[0]
}
value
=
${
array
[1]
}
if
[[
${
mode
}
=
${
MODE
}
]]
;
then
IFS
=
"|"
#echo $(func_set_params "${mode}" "${value}")
echo
$value
break
fi
IFS
=
"|"
done
echo
${
res
}
}
function
status_check
(){
last_status
=
$1
# the exit code
run_command
=
$2
run_log
=
$3
if
[
$last_status
-eq
0
]
;
then
echo
-e
"
\0
33[33m Run successfully with command -
${
run_command
}
!
\0
33[0m"
|
tee
-a
${
run_log
}
else
echo
-e
"
\0
33[33m Run failed with command -
${
run_command
}
!
\0
33[0m"
|
tee
-a
${
run_log
}
fi
}
\ No newline at end of file
test_tipc/supplementary/test_tipc/test_train_python.sh
0 → 100644
View file @
41a1b292
#!/bin/bash
source
test_tipc/common_func.sh
FILENAME
=
$1
# MODE be one of ['lite_train_lite_infer' 'lite_train_whole_infer']
MODE
=
$2
dataline
=
$(
awk
'NR==1, NR==51{print}'
$FILENAME
)
# parser params
IFS
=
$'
\n
'
lines
=(
${
dataline
}
)
model_name
=
$(
func_parser_value
"
${
lines
[1]
}
"
)
python
=
$(
func_parser_value
"
${
lines
[2]
}
"
)
gpu_list
=
$(
func_parser_value
"
${
lines
[3]
}
"
)
train_use_gpu_key
=
$(
func_parser_key
"
${
lines
[4]
}
"
)
train_use_gpu_value
=
$(
func_parser_value
"
${
lines
[4]
}
"
)
autocast_list
=
$(
func_parser_value
"
${
lines
[5]
}
"
)
autocast_key
=
$(
func_parser_key
"
${
lines
[5]
}
"
)
epoch_key
=
$(
func_parser_key
"
${
lines
[6]
}
"
)
epoch_num
=
$(
func_parser_params
"
${
lines
[6]
}
"
"
${
MODE
}
"
)
save_model_key
=
$(
func_parser_key
"
${
lines
[7]
}
"
)
train_batch_key
=
$(
func_parser_key
"
${
lines
[8]
}
"
)
train_batch_value
=
$(
func_parser_params
"
${
lines
[8]
}
"
"
${
MODE
}
"
)
pretrain_model_key
=
$(
func_parser_key
"
${
lines
[9]
}
"
)
pretrain_model_value
=
$(
func_parser_value
"
${
lines
[9]
}
"
)
checkpoints_key
=
$(
func_parser_key
"
${
lines
[10]
}
"
)
checkpoints_value
=
$(
func_parser_value
"
${
lines
[10]
}
"
)
use_custom_key
=
$(
func_parser_key
"
${
lines
[11]
}
"
)
use_custom_list
=
$(
func_parser_value
"
${
lines
[11]
}
"
)
model_type_key
=
$(
func_parser_key
"
${
lines
[12]
}
"
)
model_type_list
=
$(
func_parser_value
"
${
lines
[12]
}
"
)
use_share_conv_key
=
$(
func_parser_key
"
${
lines
[13]
}
"
)
use_share_conv_list
=
$(
func_parser_value
"
${
lines
[13]
}
"
)
run_train_py
=
$(
func_parser_value
"
${
lines
[14]
}
"
)
LOG_PATH
=
"./test_tipc/extra_output"
mkdir
-p
${
LOG_PATH
}
status_log
=
"
${
LOG_PATH
}
/results_python.log"
if
[
${
MODE
}
=
"lite_train_lite_infer"
]
||
[
${
MODE
}
=
"whole_train_whole_infer"
]
;
then
IFS
=
"|"
export
Count
=
0
USE_GPU_KEY
=(
${
train_use_gpu_value
}
)
# select cpu\gpu\distribute training
for
gpu
in
${
gpu_list
[*]
}
;
do
train_use_gpu
=
${
USE_GPU_KEY
[Count]
}
Count
=
$((
$Count
+
1
))
ips
=
""
if
[
${
gpu
}
=
"-1"
]
;
then
env
=
""
elif
[
${#
gpu
}
-le
1
]
;
then
env
=
"export CUDA_VISIBLE_DEVICES=
${
gpu
}
"
eval
${
env
}
elif
[
${#
gpu
}
-le
15
]
;
then
IFS
=
","
array
=(
${
gpu
}
)
env
=
"export CUDA_VISIBLE_DEVICES=
${
array
[0]
}
"
IFS
=
"|"
else
IFS
=
";"
array
=(
${
gpu
}
)
ips
=
${
array
[0]
}
gpu
=
${
array
[1]
}
IFS
=
"|"
env
=
" "
fi
for
autocast
in
${
autocast_list
[*]
}
;
do
# set amp
if
[
${
autocast
}
=
"amp"
]
;
then
set_amp_config
=
"AMP.use_amp=True"
else
set_amp_config
=
" "
fi
if
[
${
run_train_py
}
=
"null"
]
;
then
continue
fi
set_autocast
=
$(
func_set_params
"
${
autocast_key
}
"
"
${
autocast
}
"
)
set_epoch
=
$(
func_set_params
"
${
epoch_key
}
"
"
${
epoch_num
}
"
)
set_pretrain
=
$(
func_set_params
"
${
pretrain_model_key
}
"
"
${
pretrain_model_value
}
"
)
set_checkpoints
=
$(
func_set_params
"
${
checkpoints_key
}
"
"
${
checkpoints_value
}
"
)
set_batchsize
=
$(
func_set_params
"
${
train_batch_key
}
"
"
${
train_batch_value
}
"
)
set_use_gpu
=
$(
func_set_params
"
${
train_use_gpu_key
}
"
"
${
train_use_gpu
}
"
)
for
custom_op
in
${
use_custom_list
[*]
}
;
do
for
model_type
in
${
model_type_list
[*]
}
;
do
for
share_conv
in
${
use_share_conv_list
[*]
}
;
do
set_use_custom_op
=
$(
func_set_params
"
${
use_custom_key
}
"
"
${
custom_op
}
"
)
set_model_type
=
$(
func_set_params
"
${
model_type_key
}
"
"
${
model_type
}
"
)
set_use_share_conv
=
$(
func_set_params
"
${
use_share_conv_key
}
"
"
${
share_conv
}
"
)
set_save_model
=
$(
func_set_params
"
${
save_model_key
}
"
"
${
save_log
}
"
)
if
[
${#
gpu
}
-le
2
]
;
then
# train with cpu or single gpu
cmd
=
"
${
python
}
${
run_train_py
}
${
set_use_gpu
}
${
set_save_model
}
${
set_epoch
}
${
set_pretrain
}
${
set_checkpoints
}
${
set_autocast
}
${
set_batchsize
}
${
set_use_custom_op
}
${
set_model_type
}
${
set_use_share_conv
}
${
set_amp_config
}
"
elif
[
${#
ips
}
-le
26
]
;
then
# train with multi-gpu
cmd
=
"
${
python
}
-m paddle.distributed.launch --gpus=
${
gpu
}
${
run_train_py
}
${
set_use_gpu
}
${
set_save_model
}
${
set_epoch
}
${
set_pretrain
}
${
set_checkpoints
}
${
set_autocast
}
${
set_batchsize
}
${
set_use_custom_op
}
${
set_model_type
}
${
set_use_share_conv
}
${
set_amp_config
}
"
fi
# run train
eval
"unset CUDA_VISIBLE_DEVICES"
# echo $cmd
eval
$cmd
status_check
$?
"
${
cmd
}
"
"
${
status_log
}
"
done
done
done
done
done
fi
test_tipc/supplementary/test_tipc/tipc_train.png
0 → 100644
View file @
41a1b292
1.02 MB
test_tipc/supplementary/test_tipc/train_infer_python.txt
0 → 100644
View file @
41a1b292
===========================train_params===========================
model_name:ch_PPOCRv2_det
python:python3.7
gpu_list:0|0,1
use_gpu:True|True
AMP.use_amp:True|False
epoch:lite_train_lite_infer=2|whole_train_whole_infer=1000
save_model_dir:./output/
TRAIN.batch_size:lite_train_lite_infer=1280|whole_train_whole_infer=1280
pretrained_model:null
checkpoints:null
use_custom_relu:False|True
model_type:cls|cls_distill|cls_distill_multiopt
MODEL.siamese:False|True
norm_train:train.py -c mv3_large_x0_5.yml -o
quant_train:False
prune_train:False
test_tipc/supplementary/test_tipc/train_infer_python_FPGM.txt
0 → 100644
View file @
41a1b292
===========================train_params===========================
model_name:ch_PPOCRv2_det
python:python3.7
gpu_list:0|0,1
use_gpu:True|True
AMP.use_amp:True|False
epoch:lite_train_lite_infer=20|whole_train_whole_infer=1000
save_model_dir:./output/
TRAIN.batch_size:lite_train_lite_infer=2|whole_train_whole_infer=4
pretrained_model:null
checkpoints:null
use_custom_relu:False|True
model_type:cls|cls_distill|cls_distill_multiopt
MODEL.siamese:False|True
norm_train:train.py -c mv3_large_x0_5.yml -o prune_train=True
quant_train:False
prune_train:False
test_tipc/supplementary/test_tipc/train_infer_python_PACT.txt
0 → 100644
View file @
41a1b292
===========================train_params===========================
model_name:ch_PPOCRv2_det
python:python3.7
gpu_list:0|0,1
use_gpu:True|True
AMP.use_amp:True|False
epoch:lite_train_lite_infer=20|whole_train_whole_infer=1000
save_model_dir:./output/
TRAIN.batch_size:lite_train_lite_infer=2|whole_train_whole_infer=4
pretrained_model:null
checkpoints:null
use_custom_relu:False|True
model_type:cls|cls_distill|cls_distill_multiopt
MODEL.siamese:False|True
norm_train:train.py -c mv3_large_x0_5.yml -o quant_train=True
quant_train:False
prune_train:False
test_tipc/supplementary/train.py
0 → 100644
View file @
41a1b292
import
paddle
import
numpy
as
np
import
os
import
paddle.nn
as
nn
import
paddle.distributed
as
dist
dist
.
get_world_size
()
dist
.
init_parallel_env
()
from
loss
import
build_loss
,
LossDistill
,
DMLLoss
,
KLJSLoss
from
optimizer
import
create_optimizer
from
data_loader
import
build_dataloader
from
metric
import
create_metric
from
mv3
import
MobileNetV3_large_x0_5
,
distillmv3_large_x0_5
,
build_model
from
config
import
preprocess
import
time
from
paddleslim.dygraph.quant
import
QAT
from
slim.slim_quant
import
PACT
,
quant_config
from
slim.slim_fpgm
import
prune_model
from
utils
import
load_model
def
_mkdir_if_not_exist
(
path
,
logger
):
"""
mkdir if not exists, ignore the exception when multiprocess mkdir together
"""
if
not
os
.
path
.
exists
(
path
):
try
:
os
.
makedirs
(
path
)
except
OSError
as
e
:
if
e
.
errno
==
errno
.
EEXIST
and
os
.
path
.
isdir
(
path
):
logger
.
warning
(
'be happy if some process has already created {}'
.
format
(
path
))
else
:
raise
OSError
(
'Failed to mkdir {}'
.
format
(
path
))
def
save_model
(
model
,
optimizer
,
model_path
,
logger
,
is_best
=
False
,
prefix
=
'ppocr'
,
**
kwargs
):
"""
save model to the target path
"""
_mkdir_if_not_exist
(
model_path
,
logger
)
model_prefix
=
os
.
path
.
join
(
model_path
,
prefix
)
paddle
.
save
(
model
.
state_dict
(),
model_prefix
+
'.pdparams'
)
if
type
(
optimizer
)
is
list
:
paddle
.
save
(
optimizer
[
0
].
state_dict
(),
model_prefix
+
'.pdopt'
)
paddle
.
save
(
optimizer
[
1
].
state_dict
(),
model_prefix
+
"_1"
+
'.pdopt'
)
else
:
paddle
.
save
(
optimizer
.
state_dict
(),
model_prefix
+
'.pdopt'
)
# # save metric and config
# with open(model_prefix + '.states', 'wb') as f:
# pickle.dump(kwargs, f, protocol=2)
if
is_best
:
logger
.
info
(
'save best model is to {}'
.
format
(
model_prefix
))
else
:
logger
.
info
(
"save model in {}"
.
format
(
model_prefix
))
def
amp_scaler
(
config
):
if
'AMP'
in
config
and
config
[
'AMP'
][
'use_amp'
]
is
True
:
AMP_RELATED_FLAGS_SETTING
=
{
'FLAGS_cudnn_batchnorm_spatial_persistent'
:
1
,
'FLAGS_max_inplace_grad_add'
:
8
,
}
paddle
.
fluid
.
set_flags
(
AMP_RELATED_FLAGS_SETTING
)
scale_loss
=
config
[
"AMP"
].
get
(
"scale_loss"
,
1.0
)
use_dynamic_loss_scaling
=
config
[
"AMP"
].
get
(
"use_dynamic_loss_scaling"
,
False
)
scaler
=
paddle
.
amp
.
GradScaler
(
init_loss_scaling
=
scale_loss
,
use_dynamic_loss_scaling
=
use_dynamic_loss_scaling
)
return
scaler
else
:
return
None
def
set_seed
(
seed
):
paddle
.
seed
(
seed
)
np
.
random
.
seed
(
seed
)
def
train
(
config
,
scaler
=
None
):
EPOCH
=
config
[
'epoch'
]
topk
=
config
[
'topk'
]
batch_size
=
config
[
'TRAIN'
][
'batch_size'
]
num_workers
=
config
[
'TRAIN'
][
'num_workers'
]
train_loader
=
build_dataloader
(
'train'
,
batch_size
=
batch_size
,
num_workers
=
num_workers
)
# build metric
metric_func
=
create_metric
# build model
# model = MobileNetV3_large_x0_5(class_dim=100)
model
=
build_model
(
config
)
# build_optimizer
optimizer
,
lr_scheduler
=
create_optimizer
(
config
,
parameter_list
=
model
.
parameters
())
# load model
pre_best_model_dict
=
load_model
(
config
,
model
,
optimizer
)
if
len
(
pre_best_model_dict
)
>
0
:
pre_str
=
'The metric of loaded metric as follows {}'
.
format
(
', '
.
join
(
[
'{}: {}'
.
format
(
k
,
v
)
for
k
,
v
in
pre_best_model_dict
.
items
()]))
logger
.
info
(
pre_str
)
# about slim prune and quant
if
"quant_train"
in
config
and
config
[
'quant_train'
]
is
True
:
quanter
=
QAT
(
config
=
quant_config
,
act_preprocess
=
PACT
)
quanter
.
quantize
(
model
)
elif
"prune_train"
in
config
and
config
[
'prune_train'
]
is
True
:
model
=
prune_model
(
model
,
[
1
,
3
,
32
,
32
],
0.1
)
else
:
pass
# distribution
model
.
train
()
model
=
paddle
.
DataParallel
(
model
)
# build loss function
loss_func
=
build_loss
(
config
)
data_num
=
len
(
train_loader
)
best_acc
=
{}
for
epoch
in
range
(
EPOCH
):
st
=
time
.
time
()
for
idx
,
data
in
enumerate
(
train_loader
):
img_batch
,
label
=
data
img_batch
=
paddle
.
transpose
(
img_batch
,
[
0
,
3
,
1
,
2
])
label
=
paddle
.
unsqueeze
(
label
,
-
1
)
if
scaler
is
not
None
:
with
paddle
.
amp
.
auto_cast
():
outs
=
model
(
img_batch
)
else
:
outs
=
model
(
img_batch
)
# cal metric
acc
=
metric_func
(
outs
,
label
)
# cal loss
avg_loss
=
loss_func
(
outs
,
label
)
if
scaler
is
None
:
# backward
avg_loss
.
backward
()
optimizer
.
step
()
optimizer
.
clear_grad
()
else
:
scaled_avg_loss
=
scaler
.
scale
(
avg_loss
)
scaled_avg_loss
.
backward
()
scaler
.
minimize
(
optimizer
,
scaled_avg_loss
)
if
not
isinstance
(
lr_scheduler
,
float
):
lr_scheduler
.
step
()
if
idx
%
10
==
0
:
et
=
time
.
time
()
strs
=
f
"epoch: [
{
epoch
}
/
{
EPOCH
}
], iter: [
{
idx
}
/
{
data_num
}
], "
strs
+=
f
"loss:
{
avg_loss
.
numpy
()[
0
]
}
"
strs
+=
f
", acc_topk1:
{
acc
[
'top1'
].
numpy
()[
0
]
}
, acc_top5:
{
acc
[
'top5'
].
numpy
()[
0
]
}
"
strs
+=
f
", batch_time:
{
round
(
et
-
st
,
4
)
}
s"
logger
.
info
(
strs
)
st
=
time
.
time
()
if
epoch
%
10
==
0
:
acc
=
eval
(
config
,
model
)
if
len
(
best_acc
)
<
1
or
acc
[
'top5'
].
numpy
()[
0
]
>
best_acc
[
'top5'
]:
best_acc
=
acc
best_acc
[
'epoch'
]
=
epoch
is_best
=
True
else
:
is_best
=
False
logger
.
info
(
f
"The best acc: acc_topk1:
{
best_acc
[
'top1'
].
numpy
()[
0
]
}
, acc_top5:
{
best_acc
[
'top5'
].
numpy
()[
0
]
}
, best_epoch:
{
best_acc
[
'epoch'
]
}
"
)
save_model
(
model
,
optimizer
,
config
[
'save_model_dir'
],
logger
,
is_best
,
prefix
=
"cls"
)
def
train_distill
(
config
,
scaler
=
None
):
EPOCH
=
config
[
'epoch'
]
topk
=
config
[
'topk'
]
batch_size
=
config
[
'TRAIN'
][
'batch_size'
]
num_workers
=
config
[
'TRAIN'
][
'num_workers'
]
train_loader
=
build_dataloader
(
'train'
,
batch_size
=
batch_size
,
num_workers
=
num_workers
)
# build metric
metric_func
=
create_metric
# model = distillmv3_large_x0_5(class_dim=100)
model
=
build_model
(
config
)
# pact quant train
if
"quant_train"
in
config
and
config
[
'quant_train'
]
is
True
:
quanter
=
QAT
(
config
=
quant_config
,
act_preprocess
=
PACT
)
quanter
.
quantize
(
model
)
elif
"prune_train"
in
config
and
config
[
'prune_train'
]
is
True
:
model
=
prune_model
(
model
,
[
1
,
3
,
32
,
32
],
0.1
)
else
:
pass
# build_optimizer
optimizer
,
lr_scheduler
=
create_optimizer
(
config
,
parameter_list
=
model
.
parameters
())
# load model
pre_best_model_dict
=
load_model
(
config
,
model
,
optimizer
)
if
len
(
pre_best_model_dict
)
>
0
:
pre_str
=
'The metric of loaded metric as follows {}'
.
format
(
', '
.
join
(
[
'{}: {}'
.
format
(
k
,
v
)
for
k
,
v
in
pre_best_model_dict
.
items
()]))
logger
.
info
(
pre_str
)
model
.
train
()
model
=
paddle
.
DataParallel
(
model
)
# build loss function
loss_func_distill
=
LossDistill
(
model_name_list
=
[
'student'
,
'student1'
])
loss_func_dml
=
DMLLoss
(
model_name_pairs
=
[
'student'
,
'student1'
])
loss_func_js
=
KLJSLoss
(
mode
=
'js'
)
data_num
=
len
(
train_loader
)
best_acc
=
{}
for
epoch
in
range
(
EPOCH
):
st
=
time
.
time
()
for
idx
,
data
in
enumerate
(
train_loader
):
img_batch
,
label
=
data
img_batch
=
paddle
.
transpose
(
img_batch
,
[
0
,
3
,
1
,
2
])
label
=
paddle
.
unsqueeze
(
label
,
-
1
)
if
scaler
is
not
None
:
with
paddle
.
amp
.
auto_cast
():
outs
=
model
(
img_batch
)
else
:
outs
=
model
(
img_batch
)
# cal metric
acc
=
metric_func
(
outs
[
'student'
],
label
)
# cal loss
avg_loss
=
loss_func_distill
(
outs
,
label
)[
'student'
]
+
\
loss_func_distill
(
outs
,
label
)[
'student1'
]
+
\
loss_func_dml
(
outs
,
label
)[
'student_student1'
]
# backward
if
scaler
is
None
:
avg_loss
.
backward
()
optimizer
.
step
()
optimizer
.
clear_grad
()
else
:
scaled_avg_loss
=
scaler
.
scale
(
avg_loss
)
scaled_avg_loss
.
backward
()
scaler
.
minimize
(
optimizer
,
scaled_avg_loss
)
if
not
isinstance
(
lr_scheduler
,
float
):
lr_scheduler
.
step
()
if
idx
%
10
==
0
:
et
=
time
.
time
()
strs
=
f
"epoch: [
{
epoch
}
/
{
EPOCH
}
], iter: [
{
idx
}
/
{
data_num
}
], "
strs
+=
f
"loss:
{
avg_loss
.
numpy
()[
0
]
}
"
strs
+=
f
", acc_topk1:
{
acc
[
'top1'
].
numpy
()[
0
]
}
, acc_top5:
{
acc
[
'top5'
].
numpy
()[
0
]
}
"
strs
+=
f
", batch_time:
{
round
(
et
-
st
,
4
)
}
s"
logger
.
info
(
strs
)
st
=
time
.
time
()
if
epoch
%
10
==
0
:
acc
=
eval
(
config
,
model
.
_layers
.
student
)
if
len
(
best_acc
)
<
1
or
acc
[
'top5'
].
numpy
()[
0
]
>
best_acc
[
'top5'
]:
best_acc
=
acc
best_acc
[
'epoch'
]
=
epoch
is_best
=
True
else
:
is_best
=
False
logger
.
info
(
f
"The best acc: acc_topk1:
{
best_acc
[
'top1'
].
numpy
()[
0
]
}
, acc_top5:
{
best_acc
[
'top5'
].
numpy
()[
0
]
}
, best_epoch:
{
best_acc
[
'epoch'
]
}
"
)
save_model
(
model
,
optimizer
,
config
[
'save_model_dir'
],
logger
,
is_best
,
prefix
=
"cls_distill"
)
def
train_distill_multiopt
(
config
,
scaler
=
None
):
EPOCH
=
config
[
'epoch'
]
topk
=
config
[
'topk'
]
batch_size
=
config
[
'TRAIN'
][
'batch_size'
]
num_workers
=
config
[
'TRAIN'
][
'num_workers'
]
train_loader
=
build_dataloader
(
'train'
,
batch_size
=
batch_size
,
num_workers
=
num_workers
)
# build metric
metric_func
=
create_metric
# model = distillmv3_large_x0_5(class_dim=100)
model
=
build_model
(
config
)
# build_optimizer
optimizer
,
lr_scheduler
=
create_optimizer
(
config
,
parameter_list
=
model
.
student
.
parameters
())
optimizer1
,
lr_scheduler1
=
create_optimizer
(
config
,
parameter_list
=
model
.
student1
.
parameters
())
# load model
pre_best_model_dict
=
load_model
(
config
,
model
,
optimizer
)
if
len
(
pre_best_model_dict
)
>
0
:
pre_str
=
'The metric of loaded metric as follows {}'
.
format
(
', '
.
join
(
[
'{}: {}'
.
format
(
k
,
v
)
for
k
,
v
in
pre_best_model_dict
.
items
()]))
logger
.
info
(
pre_str
)
# quant train
if
"quant_train"
in
config
and
config
[
'quant_train'
]
is
True
:
quanter
=
QAT
(
config
=
quant_config
,
act_preprocess
=
PACT
)
quanter
.
quantize
(
model
)
elif
"prune_train"
in
config
and
config
[
'prune_train'
]
is
True
:
model
=
prune_model
(
model
,
[
1
,
3
,
32
,
32
],
0.1
)
else
:
pass
model
.
train
()
model
=
paddle
.
DataParallel
(
model
)
# build loss function
loss_func_distill
=
LossDistill
(
model_name_list
=
[
'student'
,
'student1'
])
loss_func_dml
=
DMLLoss
(
model_name_pairs
=
[
'student'
,
'student1'
])
loss_func_js
=
KLJSLoss
(
mode
=
'js'
)
data_num
=
len
(
train_loader
)
best_acc
=
{}
for
epoch
in
range
(
EPOCH
):
st
=
time
.
time
()
for
idx
,
data
in
enumerate
(
train_loader
):
img_batch
,
label
=
data
img_batch
=
paddle
.
transpose
(
img_batch
,
[
0
,
3
,
1
,
2
])
label
=
paddle
.
unsqueeze
(
label
,
-
1
)
if
scaler
is
not
None
:
with
paddle
.
amp
.
auto_cast
():
outs
=
model
(
img_batch
)
else
:
outs
=
model
(
img_batch
)
# cal metric
acc
=
metric_func
(
outs
[
'student'
],
label
)
# cal loss
avg_loss
=
loss_func_distill
(
outs
,
label
)[
'student'
]
+
loss_func_dml
(
outs
,
label
)[
'student_student1'
]
avg_loss1
=
loss_func_distill
(
outs
,
label
)[
'student1'
]
+
loss_func_dml
(
outs
,
label
)[
'student_student1'
]
if
scaler
is
None
:
# backward
avg_loss
.
backward
(
retain_graph
=
True
)
optimizer
.
step
()
optimizer
.
clear_grad
()
avg_loss1
.
backward
()
optimizer1
.
step
()
optimizer1
.
clear_grad
()
else
:
scaled_avg_loss
=
scaler
.
scale
(
avg_loss
)
scaled_avg_loss
.
backward
()
scaler
.
minimize
(
optimizer
,
scaled_avg_loss
)
scaled_avg_loss
=
scaler
.
scale
(
avg_loss1
)
scaled_avg_loss
.
backward
()
scaler
.
minimize
(
optimizer1
,
scaled_avg_loss
)
if
not
isinstance
(
lr_scheduler
,
float
):
lr_scheduler
.
step
()
if
not
isinstance
(
lr_scheduler1
,
float
):
lr_scheduler1
.
step
()
if
idx
%
10
==
0
:
et
=
time
.
time
()
strs
=
f
"epoch: [
{
epoch
}
/
{
EPOCH
}
], iter: [
{
idx
}
/
{
data_num
}
], "
strs
+=
f
"loss:
{
avg_loss
.
numpy
()[
0
]
}
, loss1:
{
avg_loss1
.
numpy
()[
0
]
}
"
strs
+=
f
", acc_topk1:
{
acc
[
'top1'
].
numpy
()[
0
]
}
, acc_top5:
{
acc
[
'top5'
].
numpy
()[
0
]
}
"
strs
+=
f
", batch_time:
{
round
(
et
-
st
,
4
)
}
s"
logger
.
info
(
strs
)
st
=
time
.
time
()
if
epoch
%
10
==
0
:
acc
=
eval
(
config
,
model
.
_layers
.
student
)
if
len
(
best_acc
)
<
1
or
acc
[
'top5'
].
numpy
()[
0
]
>
best_acc
[
'top5'
]:
best_acc
=
acc
best_acc
[
'epoch'
]
=
epoch
is_best
=
True
else
:
is_best
=
False
logger
.
info
(
f
"The best acc: acc_topk1:
{
best_acc
[
'top1'
].
numpy
()[
0
]
}
, acc_top5:
{
best_acc
[
'top5'
].
numpy
()[
0
]
}
, best_epoch:
{
best_acc
[
'epoch'
]
}
"
)
save_model
(
model
,
[
optimizer
,
optimizer1
],
config
[
'save_model_dir'
],
logger
,
is_best
,
prefix
=
"cls_distill_multiopt"
)
def
eval
(
config
,
model
):
batch_size
=
config
[
'VALID'
][
'batch_size'
]
num_workers
=
config
[
'VALID'
][
'num_workers'
]
valid_loader
=
build_dataloader
(
'test'
,
batch_size
=
batch_size
,
num_workers
=
num_workers
)
# build metric
metric_func
=
create_metric
outs
=
[]
labels
=
[]
for
idx
,
data
in
enumerate
(
valid_loader
):
img_batch
,
label
=
data
img_batch
=
paddle
.
transpose
(
img_batch
,
[
0
,
3
,
1
,
2
])
label
=
paddle
.
unsqueeze
(
label
,
-
1
)
out
=
model
(
img_batch
)
outs
.
append
(
out
)
labels
.
append
(
label
)
outs
=
paddle
.
concat
(
outs
,
axis
=
0
)
labels
=
paddle
.
concat
(
labels
,
axis
=
0
)
acc
=
metric_func
(
outs
,
labels
)
strs
=
f
"The metric are as follows: acc_topk1:
{
acc
[
'top1'
].
numpy
()[
0
]
}
, acc_top5:
{
acc
[
'top5'
].
numpy
()[
0
]
}
"
logger
.
info
(
strs
)
return
acc
if
__name__
==
"__main__"
:
config
,
logger
=
preprocess
(
is_train
=
False
)
# AMP scaler
scaler
=
amp_scaler
(
config
)
model_type
=
config
[
'model_type'
]
if
model_type
==
"cls"
:
train
(
config
)
elif
model_type
==
"cls_distill"
:
train_distill
(
config
)
elif
model_type
==
"cls_distill_multiopt"
:
train_distill_multiopt
(
config
)
else
:
raise
ValueError
(
"model_type should be one of ['']"
)
test_tipc/supplementary/train.sh
0 → 100644
View file @
41a1b292
# single GPU
python3.7 train.py
-c
mv3_large_x0_5.yml
# distribute training
python3.7
-m
paddle.distributed.launch
--log_dir
=
./debug/
--gpus
'0,1'
train.py
-c
mv3_large_x0_5.yml
test_tipc/supplementary/utils.py
0 → 100644
View file @
41a1b292
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import
os
import
sys
import
logging
import
functools
import
paddle.distributed
as
dist
logger_initialized
=
{}
def
print_dict
(
d
,
logger
,
delimiter
=
0
):
"""
Recursively visualize a dict and
indenting acrrording by the relationship of keys.
"""
for
k
,
v
in
sorted
(
d
.
items
()):
if
isinstance
(
v
,
dict
):
logger
.
info
(
"{}{} : "
.
format
(
delimiter
*
" "
,
str
(
k
)))
print_dict
(
v
,
logger
,
delimiter
+
4
)
elif
isinstance
(
v
,
list
)
and
len
(
v
)
>=
1
and
isinstance
(
v
[
0
],
dict
):
logger
.
info
(
"{}{} : "
.
format
(
delimiter
*
" "
,
str
(
k
)))
for
value
in
v
:
print_dict
(
value
,
logger
,
delimiter
+
4
)
else
:
logger
.
info
(
"{}{} : {}"
.
format
(
delimiter
*
" "
,
k
,
v
))
@
functools
.
lru_cache
()
def
get_logger
(
name
=
'root'
,
log_file
=
None
,
log_level
=
logging
.
DEBUG
):
"""Initialize and get a logger by name.
If the logger has not been initialized, this method will initialize the
logger by adding one or two handlers, otherwise the initialized logger will
be directly returned. During initialization, a StreamHandler will always be
added. If `log_file` is specified a FileHandler will also be added.
Args:
name (str): Logger name.
log_file (str | None): The log filename. If specified, a FileHandler
will be added to the logger.
log_level (int): The logger level. Note that only the process of
rank 0 is affected, and other processes will set the level to
"Error" thus be silent most of the time.
Returns:
logging.Logger: The expected logger.
"""
logger
=
logging
.
getLogger
(
name
)
if
name
in
logger_initialized
:
return
logger
for
logger_name
in
logger_initialized
:
if
name
.
startswith
(
logger_name
):
return
logger
formatter
=
logging
.
Formatter
(
'[%(asctime)s] %(name)s %(levelname)s: %(message)s'
,
datefmt
=
"%Y/%m/%d %H:%M:%S"
)
stream_handler
=
logging
.
StreamHandler
(
stream
=
sys
.
stdout
)
stream_handler
.
setFormatter
(
formatter
)
logger
.
addHandler
(
stream_handler
)
if
log_file
is
not
None
and
dist
.
get_rank
()
==
0
:
log_file_folder
=
os
.
path
.
split
(
log_file
)[
0
]
os
.
makedirs
(
log_file_folder
,
exist_ok
=
True
)
file_handler
=
logging
.
FileHandler
(
log_file
,
'a'
)
file_handler
.
setFormatter
(
formatter
)
logger
.
addHandler
(
file_handler
)
if
dist
.
get_rank
()
==
0
:
logger
.
setLevel
(
log_level
)
else
:
logger
.
setLevel
(
logging
.
ERROR
)
logger_initialized
[
name
]
=
True
return
logger
def
load_model
(
config
,
model
,
optimizer
=
None
):
"""
load model from checkpoint or pretrained_model
"""
logger
=
get_logger
()
checkpoints
=
config
.
get
(
'checkpoints'
)
pretrained_model
=
config
.
get
(
'pretrained_model'
)
best_model_dict
=
{}
if
checkpoints
:
if
checkpoints
.
endswith
(
'.pdparams'
):
checkpoints
=
checkpoints
.
replace
(
'.pdparams'
,
''
)
assert
os
.
path
.
exists
(
checkpoints
+
".pdparams"
),
\
"The {}.pdparams does not exists!"
.
format
(
checkpoints
)
# load params from trained model
params
=
paddle
.
load
(
checkpoints
+
'.pdparams'
)
state_dict
=
model
.
state_dict
()
new_state_dict
=
{}
for
key
,
value
in
state_dict
.
items
():
if
key
not
in
params
:
logger
.
warning
(
"{} not in loaded params {} !"
.
format
(
key
,
params
.
keys
()))
continue
pre_value
=
params
[
key
]
if
list
(
value
.
shape
)
==
list
(
pre_value
.
shape
):
new_state_dict
[
key
]
=
pre_value
else
:
logger
.
warning
(
"The shape of model params {} {} not matched with loaded params shape {} !"
.
format
(
key
,
value
.
shape
,
pre_value
.
shape
))
model
.
set_state_dict
(
new_state_dict
)
if
optimizer
is
not
None
:
if
os
.
path
.
exists
(
checkpoints
+
'.pdopt'
):
optim_dict
=
paddle
.
load
(
checkpoints
+
'.pdopt'
)
optimizer
.
set_state_dict
(
optim_dict
)
else
:
logger
.
warning
(
"{}.pdopt is not exists, params of optimizer is not loaded"
.
format
(
checkpoints
))
if
os
.
path
.
exists
(
checkpoints
+
'.states'
):
with
open
(
checkpoints
+
'.states'
,
'rb'
)
as
f
:
states_dict
=
pickle
.
load
(
f
)
if
six
.
PY2
else
pickle
.
load
(
f
,
encoding
=
'latin1'
)
best_model_dict
=
states_dict
.
get
(
'best_model_dict'
,
{})
if
'epoch'
in
states_dict
:
best_model_dict
[
'start_epoch'
]
=
states_dict
[
'epoch'
]
+
1
logger
.
info
(
"resume from {}"
.
format
(
checkpoints
))
elif
pretrained_model
:
load_pretrained_params
(
model
,
pretrained_model
)
else
:
logger
.
info
(
'train from scratch'
)
return
best_model_dict
def
load_pretrained_params
(
model
,
path
):
logger
=
get_logger
()
if
path
.
endswith
(
'.pdparams'
):
path
=
path
.
replace
(
'.pdparams'
,
''
)
assert
os
.
path
.
exists
(
path
+
".pdparams"
),
\
"The {}.pdparams does not exists!"
.
format
(
path
)
params
=
paddle
.
load
(
path
+
'.pdparams'
)
state_dict
=
model
.
state_dict
()
new_state_dict
=
{}
for
k1
in
params
.
keys
():
if
k1
not
in
state_dict
.
keys
():
logger
.
warning
(
"The pretrained params {} not in model"
.
format
(
k1
))
else
:
if
list
(
state_dict
[
k1
].
shape
)
==
list
(
params
[
k1
].
shape
):
new_state_dict
[
k1
]
=
params
[
k1
]
else
:
logger
.
warning
(
"The shape of model params {} {} not matched with loaded params {} {} !"
.
format
(
k1
,
state_dict
[
k1
].
shape
,
k1
,
params
[
k1
].
shape
))
model
.
set_state_dict
(
new_state_dict
)
logger
.
info
(
"load pretrain successful from {}"
.
format
(
path
))
return
model
test_tipc/test_train_inference_python.sh
View file @
41a1b292
...
@@ -183,7 +183,7 @@ function func_inference(){
...
@@ -183,7 +183,7 @@ function func_inference(){
if
[[
${
precision
}
=
~
"fp16"
||
${
precision
}
=
~
"int8"
]]
&&
[
${
use_trt
}
=
"False"
]
;
then
if
[[
${
precision
}
=
~
"fp16"
||
${
precision
}
=
~
"int8"
]]
&&
[
${
use_trt
}
=
"False"
]
;
then
continue
continue
fi
fi
if
[[
${
use_trt
}
=
"False"
||
${
precision
}
=
~
"int8"
]]
&&
[
${
_flag_quant
}
=
"True"
]
;
then
if
[[
${
use_trt
}
=
"False"
&&
${
precision
}
=
~
"int8"
]]
&&
[
${
_flag_quant
}
=
"True"
]
;
then
continue
continue
fi
fi
for
batch_size
in
${
batch_size_list
[*]
}
;
do
for
batch_size
in
${
batch_size_list
[*]
}
;
do
...
@@ -227,7 +227,12 @@ if [ ${MODE} = "whole_infer" ] || [ ${MODE} = "klquant_whole_infer" ]; then
...
@@ -227,7 +227,12 @@ if [ ${MODE} = "whole_infer" ] || [ ${MODE} = "klquant_whole_infer" ]; then
for
infer_model
in
${
infer_model_dir_list
[*]
}
;
do
for
infer_model
in
${
infer_model_dir_list
[*]
}
;
do
# run export
# run export
if
[
${
infer_run_exports
[Count]
}
!=
"null"
]
;
then
if
[
${
infer_run_exports
[Count]
}
!=
"null"
]
;
then
save_infer_dir
=
$(
dirname
$infer_model
)
if
[
${
MODE
}
=
"klquant_whole_infer"
]
;
then
save_infer_dir
=
"
${
infer_model
}
_klquant"
fi
if
[
${
MODE
}
=
"whole_infer"
]
;
then
save_infer_dir
=
"
${
infer_model
}
"
fi
set_export_weight
=
$(
func_set_params
"
${
export_weight
}
"
"
${
infer_model
}
"
)
set_export_weight
=
$(
func_set_params
"
${
export_weight
}
"
"
${
infer_model
}
"
)
set_save_infer_key
=
$(
func_set_params
"
${
save_infer_key
}
"
"
${
save_infer_dir
}
"
)
set_save_infer_key
=
$(
func_set_params
"
${
save_infer_key
}
"
"
${
save_infer_dir
}
"
)
export_cmd
=
"
${
python
}
${
infer_run_exports
[Count]
}
${
set_export_weight
}
${
set_save_infer_key
}
"
export_cmd
=
"
${
python
}
${
infer_run_exports
[Count]
}
${
set_export_weight
}
${
set_save_infer_key
}
"
...
...
tools/eval.py
View file @
41a1b292
...
@@ -61,7 +61,8 @@ def main():
...
@@ -61,7 +61,8 @@ def main():
else
:
else
:
model_type
=
None
model_type
=
None
best_model_dict
=
load_model
(
config
,
model
)
best_model_dict
=
load_model
(
config
,
model
,
model_type
=
config
[
'Architecture'
][
"model_type"
])
if
len
(
best_model_dict
):
if
len
(
best_model_dict
):
logger
.
info
(
'metric in ckpt ***************'
)
logger
.
info
(
'metric in ckpt ***************'
)
for
k
,
v
in
best_model_dict
.
items
():
for
k
,
v
in
best_model_dict
.
items
():
...
...
tools/export_model.py
View file @
41a1b292
...
@@ -85,7 +85,7 @@ def export_single_model(model, arch_config, save_path, logger):
...
@@ -85,7 +85,7 @@ def export_single_model(model, arch_config, save_path, logger):
def
main
():
def
main
():
FLAGS
=
ArgsParser
().
parse_args
()
FLAGS
=
ArgsParser
().
parse_args
()
config
=
load_config
(
FLAGS
.
config
)
config
=
load_config
(
FLAGS
.
config
)
merge_config
(
FLAGS
.
opt
)
config
=
merge_config
(
config
,
FLAGS
.
opt
)
logger
=
get_logger
()
logger
=
get_logger
()
# build post process
# build post process
...
...
tools/infer_vqa_token_ser.py
0 → 100755
View file @
41a1b292
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from
__future__
import
absolute_import
from
__future__
import
division
from
__future__
import
print_function
import
numpy
as
np
import
os
import
sys
__dir__
=
os
.
path
.
dirname
(
os
.
path
.
abspath
(
__file__
))
sys
.
path
.
append
(
__dir__
)
sys
.
path
.
append
(
os
.
path
.
abspath
(
os
.
path
.
join
(
__dir__
,
'..'
)))
os
.
environ
[
"FLAGS_allocator_strategy"
]
=
'auto_growth'
import
cv2
import
json
import
paddle
from
ppocr.data
import
create_operators
,
transform
from
ppocr.modeling.architectures
import
build_model
from
ppocr.postprocess
import
build_post_process
from
ppocr.utils.save_load
import
load_model
from
ppocr.utils.visual
import
draw_ser_results
from
ppocr.utils.utility
import
get_image_file_list
,
load_vqa_bio_label_maps
import
tools.program
as
program
def
to_tensor
(
data
):
import
numbers
from
collections
import
defaultdict
data_dict
=
defaultdict
(
list
)
to_tensor_idxs
=
[]
for
idx
,
v
in
enumerate
(
data
):
if
isinstance
(
v
,
(
np
.
ndarray
,
paddle
.
Tensor
,
numbers
.
Number
)):
if
idx
not
in
to_tensor_idxs
:
to_tensor_idxs
.
append
(
idx
)
data_dict
[
idx
].
append
(
v
)
for
idx
in
to_tensor_idxs
:
data_dict
[
idx
]
=
paddle
.
to_tensor
(
data_dict
[
idx
])
return
list
(
data_dict
.
values
())
class
SerPredictor
(
object
):
def
__init__
(
self
,
config
):
global_config
=
config
[
'Global'
]
# build post process
self
.
post_process_class
=
build_post_process
(
config
[
'PostProcess'
],
global_config
)
# build model
self
.
model
=
build_model
(
config
[
'Architecture'
])
load_model
(
config
,
self
.
model
,
model_type
=
config
[
'Architecture'
][
"model_type"
])
from
paddleocr
import
PaddleOCR
self
.
ocr_engine
=
PaddleOCR
(
use_angle_cls
=
False
,
show_log
=
False
)
# create data ops
transforms
=
[]
for
op
in
config
[
'Eval'
][
'dataset'
][
'transforms'
]:
op_name
=
list
(
op
)[
0
]
if
'Label'
in
op_name
:
op
[
op_name
][
'ocr_engine'
]
=
self
.
ocr_engine
elif
op_name
==
'KeepKeys'
:
op
[
op_name
][
'keep_keys'
]
=
[
'input_ids'
,
'labels'
,
'bbox'
,
'image'
,
'attention_mask'
,
'token_type_ids'
,
'segment_offset_id'
,
'ocr_info'
,
'entities'
]
transforms
.
append
(
op
)
global_config
[
'infer_mode'
]
=
True
self
.
ops
=
create_operators
(
config
[
'Eval'
][
'dataset'
][
'transforms'
],
global_config
)
self
.
model
.
eval
()
def
__call__
(
self
,
img_path
):
with
open
(
img_path
,
'rb'
)
as
f
:
img
=
f
.
read
()
data
=
{
'image'
:
img
}
batch
=
transform
(
data
,
self
.
ops
)
batch
=
to_tensor
(
batch
)
preds
=
self
.
model
(
batch
)
post_result
=
self
.
post_process_class
(
preds
,
attention_masks
=
batch
[
4
],
segment_offset_ids
=
batch
[
6
],
ocr_infos
=
batch
[
7
])
return
post_result
,
batch
if
__name__
==
'__main__'
:
config
,
device
,
logger
,
vdl_writer
=
program
.
preprocess
()
os
.
makedirs
(
config
[
'Global'
][
'save_res_path'
],
exist_ok
=
True
)
ser_engine
=
SerPredictor
(
config
)
infer_imgs
=
get_image_file_list
(
config
[
'Global'
][
'infer_img'
])
with
open
(
os
.
path
.
join
(
config
[
'Global'
][
'save_res_path'
],
"infer_results.txt"
),
"w"
,
encoding
=
'utf-8'
)
as
fout
:
for
idx
,
img_path
in
enumerate
(
infer_imgs
):
save_img_path
=
os
.
path
.
join
(
config
[
'Global'
][
'save_res_path'
],
os
.
path
.
splitext
(
os
.
path
.
basename
(
img_path
))[
0
]
+
"_ser.jpg"
)
logger
.
info
(
"process: [{}/{}], save result to {}"
.
format
(
idx
,
len
(
infer_imgs
),
save_img_path
))
result
,
_
=
ser_engine
(
img_path
)
result
=
result
[
0
]
fout
.
write
(
img_path
+
"
\t
"
+
json
.
dumps
(
{
"ocr_info"
:
result
,
},
ensure_ascii
=
False
)
+
"
\n
"
)
img_res
=
draw_ser_results
(
img_path
,
result
)
cv2
.
imwrite
(
save_img_path
,
img_res
)
tools/infer_vqa_token_ser_re.py
0 → 100755
View file @
41a1b292
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from
__future__
import
absolute_import
from
__future__
import
division
from
__future__
import
print_function
import
numpy
as
np
import
os
import
sys
__dir__
=
os
.
path
.
dirname
(
os
.
path
.
abspath
(
__file__
))
sys
.
path
.
append
(
__dir__
)
sys
.
path
.
append
(
os
.
path
.
abspath
(
os
.
path
.
join
(
__dir__
,
'..'
)))
os
.
environ
[
"FLAGS_allocator_strategy"
]
=
'auto_growth'
import
cv2
import
json
import
paddle
import
paddle.distributed
as
dist
from
ppocr.data
import
create_operators
,
transform
from
ppocr.modeling.architectures
import
build_model
from
ppocr.postprocess
import
build_post_process
from
ppocr.utils.save_load
import
load_model
from
ppocr.utils.visual
import
draw_re_results
from
ppocr.utils.logging
import
get_logger
from
ppocr.utils.utility
import
get_image_file_list
,
load_vqa_bio_label_maps
,
print_dict
from
tools.program
import
ArgsParser
,
load_config
,
merge_config
,
check_gpu
from
tools.infer_vqa_token_ser
import
SerPredictor
class
ReArgsParser
(
ArgsParser
):
def
__init__
(
self
):
super
(
ReArgsParser
,
self
).
__init__
()
self
.
add_argument
(
"-c_ser"
,
"--config_ser"
,
help
=
"ser configuration file to use"
)
self
.
add_argument
(
"-o_ser"
,
"--opt_ser"
,
nargs
=
'+'
,
help
=
"set ser configuration options "
)
def
parse_args
(
self
,
argv
=
None
):
args
=
super
(
ReArgsParser
,
self
).
parse_args
(
argv
)
assert
args
.
config_ser
is
not
None
,
\
"Please specify --config_ser=ser_configure_file_path."
args
.
opt_ser
=
self
.
_parse_opt
(
args
.
opt_ser
)
return
args
def
make_input
(
ser_inputs
,
ser_results
):
entities_labels
=
{
'HEADER'
:
0
,
'QUESTION'
:
1
,
'ANSWER'
:
2
}
entities
=
ser_inputs
[
8
][
0
]
ser_results
=
ser_results
[
0
]
assert
len
(
entities
)
==
len
(
ser_results
)
# entities
start
=
[]
end
=
[]
label
=
[]
entity_idx_dict
=
{}
for
i
,
(
res
,
entity
)
in
enumerate
(
zip
(
ser_results
,
entities
)):
if
res
[
'pred'
]
==
'O'
:
continue
entity_idx_dict
[
len
(
start
)]
=
i
start
.
append
(
entity
[
'start'
])
end
.
append
(
entity
[
'end'
])
label
.
append
(
entities_labels
[
res
[
'pred'
]])
entities
=
dict
(
start
=
start
,
end
=
end
,
label
=
label
)
# relations
head
=
[]
tail
=
[]
for
i
in
range
(
len
(
entities
[
"label"
])):
for
j
in
range
(
len
(
entities
[
"label"
])):
if
entities
[
"label"
][
i
]
==
1
and
entities
[
"label"
][
j
]
==
2
:
head
.
append
(
i
)
tail
.
append
(
j
)
relations
=
dict
(
head
=
head
,
tail
=
tail
)
batch_size
=
ser_inputs
[
0
].
shape
[
0
]
entities_batch
=
[]
relations_batch
=
[]
entity_idx_dict_batch
=
[]
for
b
in
range
(
batch_size
):
entities_batch
.
append
(
entities
)
relations_batch
.
append
(
relations
)
entity_idx_dict_batch
.
append
(
entity_idx_dict
)
ser_inputs
[
8
]
=
entities_batch
ser_inputs
.
append
(
relations_batch
)
# remove ocr_info segment_offset_id and label in ser input
ser_inputs
.
pop
(
7
)
ser_inputs
.
pop
(
6
)
ser_inputs
.
pop
(
1
)
return
ser_inputs
,
entity_idx_dict_batch
class
SerRePredictor
(
object
):
def
__init__
(
self
,
config
,
ser_config
):
self
.
ser_engine
=
SerPredictor
(
ser_config
)
# init re model
global_config
=
config
[
'Global'
]
# build post process
self
.
post_process_class
=
build_post_process
(
config
[
'PostProcess'
],
global_config
)
# build model
self
.
model
=
build_model
(
config
[
'Architecture'
])
load_model
(
config
,
self
.
model
,
model_type
=
config
[
'Architecture'
][
"model_type"
])
self
.
model
.
eval
()
def
__call__
(
self
,
img_path
):
ser_results
,
ser_inputs
=
self
.
ser_engine
(
img_path
)
paddle
.
save
(
ser_inputs
,
'ser_inputs.npy'
)
paddle
.
save
(
ser_results
,
'ser_results.npy'
)
re_input
,
entity_idx_dict_batch
=
make_input
(
ser_inputs
,
ser_results
)
preds
=
self
.
model
(
re_input
)
post_result
=
self
.
post_process_class
(
preds
,
ser_results
=
ser_results
,
entity_idx_dict_batch
=
entity_idx_dict_batch
)
return
post_result
def
preprocess
():
FLAGS
=
ReArgsParser
().
parse_args
()
config
=
load_config
(
FLAGS
.
config
)
config
=
merge_config
(
config
,
FLAGS
.
opt
)
ser_config
=
load_config
(
FLAGS
.
config_ser
)
ser_config
=
merge_config
(
ser_config
,
FLAGS
.
opt_ser
)
logger
=
get_logger
(
name
=
'root'
)
# check if set use_gpu=True in paddlepaddle cpu version
use_gpu
=
config
[
'Global'
][
'use_gpu'
]
check_gpu
(
use_gpu
)
device
=
'gpu:{}'
.
format
(
dist
.
ParallelEnv
().
dev_id
)
if
use_gpu
else
'cpu'
device
=
paddle
.
set_device
(
device
)
logger
.
info
(
'{} re config {}'
.
format
(
'*'
*
10
,
'*'
*
10
))
print_dict
(
config
,
logger
)
logger
.
info
(
'
\n
'
)
logger
.
info
(
'{} ser config {}'
.
format
(
'*'
*
10
,
'*'
*
10
))
print_dict
(
ser_config
,
logger
)
logger
.
info
(
'train with paddle {} and device {}'
.
format
(
paddle
.
__version__
,
device
))
return
config
,
ser_config
,
device
,
logger
if
__name__
==
'__main__'
:
config
,
ser_config
,
device
,
logger
=
preprocess
()
os
.
makedirs
(
config
[
'Global'
][
'save_res_path'
],
exist_ok
=
True
)
ser_re_engine
=
SerRePredictor
(
config
,
ser_config
)
infer_imgs
=
get_image_file_list
(
config
[
'Global'
][
'infer_img'
])
with
open
(
os
.
path
.
join
(
config
[
'Global'
][
'save_res_path'
],
"infer_results.txt"
),
"w"
,
encoding
=
'utf-8'
)
as
fout
:
for
idx
,
img_path
in
enumerate
(
infer_imgs
):
save_img_path
=
os
.
path
.
join
(
config
[
'Global'
][
'save_res_path'
],
os
.
path
.
splitext
(
os
.
path
.
basename
(
img_path
))[
0
]
+
"_ser.jpg"
)
logger
.
info
(
"process: [{}/{}], save result to {}"
.
format
(
idx
,
len
(
infer_imgs
),
save_img_path
))
result
=
ser_re_engine
(
img_path
)
result
=
result
[
0
]
fout
.
write
(
img_path
+
"
\t
"
+
json
.
dumps
(
{
"ser_resule"
:
result
,
},
ensure_ascii
=
False
)
+
"
\n
"
)
img_res
=
draw_re_results
(
img_path
,
result
)
cv2
.
imwrite
(
save_img_path
,
img_res
)
Prev
1
…
4
5
6
7
8
9
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}