
Merge pull request #1 from PaddlePaddle/develop
update-2020-7-17
Showing
Too many changes to show.
To preserve performance only 270 of 270+ files are displayed.
{kind=link}
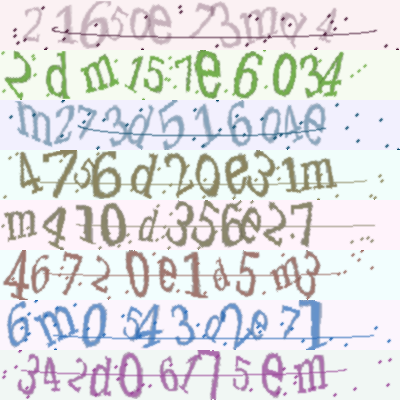
166 KB
doc/datasets/ccpd_demo.png
0 → 100644
{kind=link}

305 KB
doc/datasets/ch_doc1.jpg
0 → 100644
{kind=link}
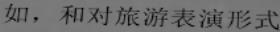
2.17 KB
doc/datasets/ch_doc2.jpg
0 → 100644
{kind=link}

2.42 KB
doc/datasets/ch_doc3.jpg
0 → 100644
{kind=link}
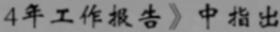
2.07 KB
{kind=link}

100 KB
{kind=link}

114 KB
doc/datasets/cmb_demo.jpg
0 → 100644
{kind=link}

90 KB
doc/datasets/labelimg.jpg
0 → 100644
{kind=link}
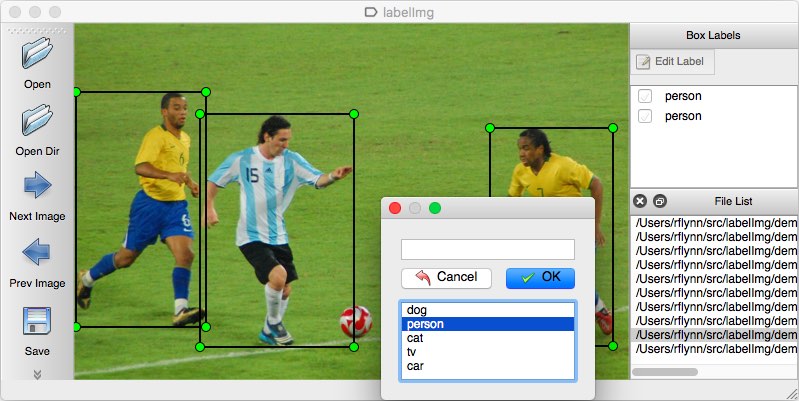
89.1 KB
doc/datasets/labelme.jpg
0 → 100644
{kind=link}
953 KB
doc/datasets/nist_demo.png
0 → 100644
{kind=link}

4.12 KB
doc/datasets/rctw.jpg
0 → 100644
{kind=link}
93.1 KB
doc/datasets/roLabelImg.png
0 → 100644
{kind=link}
3.78 MB
doc/doc_ch/FAQ.md
0 → 100644
doc/doc_ch/benchmark.md
0 → 100644
doc/doc_ch/customize.md
0 → 100644
doc/doc_ch/data_synthesis.md
0 → 100644
doc/doc_ch/datasets.md
0 → 100644