
Merge remote-tracking branch 'origin/dygraph' into dy1
Showing
{kind=link}

921 KB
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
doc/pgnet_framework.png
0 → 100644
{kind=link}

242 KB
doc/table/1.png
0 → 100644
{kind=link}

758 KB
doc/table/layout.jpg
0 → 100644
{kind=link}

671 KB
doc/table/paper-image.jpg
0 → 100644
{kind=link}

671 KB
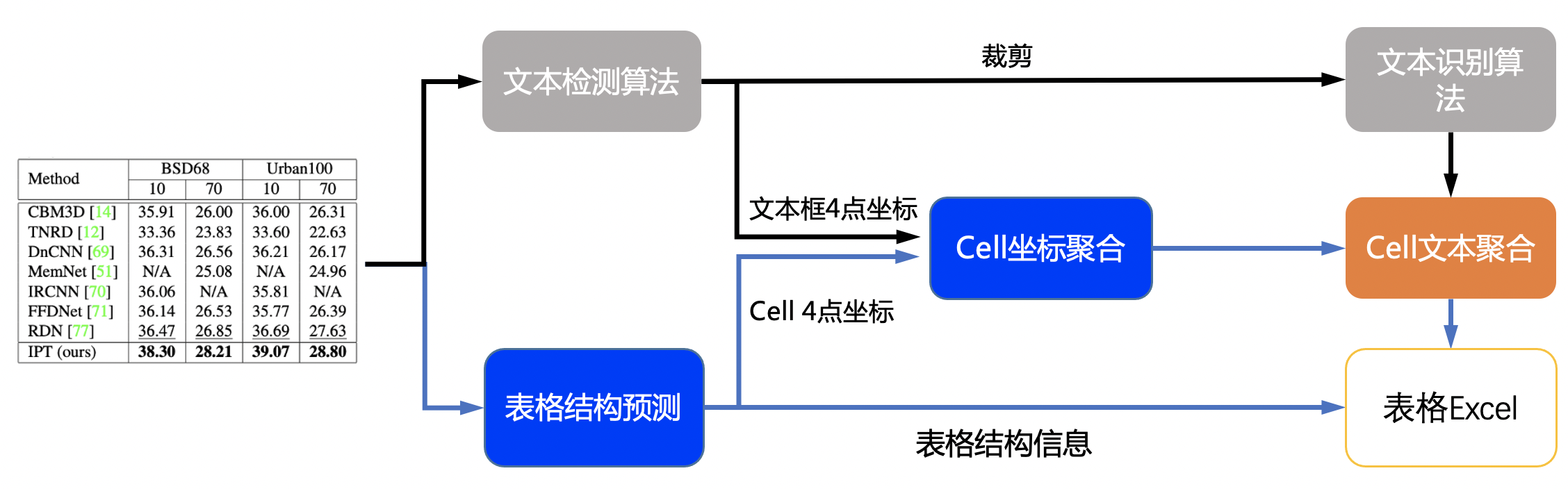
doc/table/pipeline.jpg
0 → 100644
{kind=link}

1.46 MB
doc/table/pipeline_en.jpg
0 → 100644
{kind=link}

1.45 MB
doc/table/ppstructure.GIF
0 → 100644
{kind=link}

2.49 MB
doc/table/result_all.jpg
0 → 100644
{kind=link}

521 KB
doc/table/result_text.jpg
0 → 100644
{kind=link}

146 KB
doc/table/table.jpg
0 → 100644
{kind=link}

58 KB
{kind=link}
552 KB
{kind=link}

416 KB