Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
wangsen
paddle_dbnet
Commits
112ad00d
Commit
112ad00d
authored
Apr 23, 2022
by
Manan Goel
Browse files
Fixed merge conflict in README.md
parents
b7aa10e5
95ac9c0e
Changes
99
Hide whitespace changes
Inline
Side-by-side
Showing
20 changed files
with
406 additions
and
111 deletions
+406
-111
doc/ocr-android-easyedge.png
doc/ocr-android-easyedge.png
+0
-0
doc/overview.png
doc/overview.png
+0
-0
ppocr/modeling/heads/det_fce_head.py
ppocr/modeling/heads/det_fce_head.py
+2
-2
ppstructure/README_ch.md
ppstructure/README_ch.md
+45
-28
ppstructure/docs/inference.md
ppstructure/docs/inference.md
+50
-0
ppstructure/docs/inference_en.md
ppstructure/docs/inference_en.md
+50
-0
ppstructure/docs/models_list.md
ppstructure/docs/models_list.md
+14
-9
ppstructure/docs/models_list_en.md
ppstructure/docs/models_list_en.md
+56
-0
ppstructure/docs/quickstart.md
ppstructure/docs/quickstart.md
+51
-72
ppstructure/docs/quickstart_en.md
ppstructure/docs/quickstart_en.md
+138
-0
ppstructure/docs/table/1.png
ppstructure/docs/table/1.png
+0
-0
ppstructure/docs/table/layout.jpg
ppstructure/docs/table/layout.jpg
+0
-0
ppstructure/docs/table/paper-image.jpg
ppstructure/docs/table/paper-image.jpg
+0
-0
ppstructure/docs/table/pipeline.jpg
ppstructure/docs/table/pipeline.jpg
+0
-0
ppstructure/docs/table/pipeline_en.jpg
ppstructure/docs/table/pipeline_en.jpg
+0
-0
ppstructure/docs/table/ppstructure.GIF
ppstructure/docs/table/ppstructure.GIF
+0
-0
ppstructure/docs/table/result_all.jpg
ppstructure/docs/table/result_all.jpg
+0
-0
ppstructure/docs/table/result_text.jpg
ppstructure/docs/table/result_text.jpg
+0
-0
ppstructure/docs/table/table.jpg
ppstructure/docs/table/table.jpg
+0
-0
ppstructure/docs/table/tableocr_pipeline.jpg
ppstructure/docs/table/tableocr_pipeline.jpg
+0
-0
No files found.
doc/ocr-android-easyedge.png
deleted
100644 → 0
View file @
b7aa10e5
292 KB
doc/overview.png
deleted
100644 → 0
View file @
b7aa10e5
143 KB
ppocr/modeling/heads/det_fce_head.py
View file @
112ad00d
...
...
@@ -63,7 +63,7 @@ class FCEHead(nn.Layer):
weight_attr
=
ParamAttr
(
name
=
'cls_weights'
,
initializer
=
Normal
(
mean
=
paddle
.
to_tensor
(
0.
)
,
std
=
paddle
.
to_tensor
(
0.01
))
)
,
mean
=
0.
,
std
=
0.01
)),
bias_attr
=
True
)
self
.
out_conv_reg
=
nn
.
Conv2D
(
in_channels
=
self
.
in_channels
,
...
...
@@ -75,7 +75,7 @@ class FCEHead(nn.Layer):
weight_attr
=
ParamAttr
(
name
=
'reg_weights'
,
initializer
=
Normal
(
mean
=
paddle
.
to_tensor
(
0.
)
,
std
=
paddle
.
to_tensor
(
0.01
))
)
,
mean
=
0.
,
std
=
0.01
)),
bias_attr
=
True
)
def
forward
(
self
,
feats
,
targets
=
None
):
...
...
ppstructure/README_ch.md
View file @
112ad00d
[
English
](
README.md
)
| 简体中文
-
[
1. 简介
](
#1-简介
)
-
[
2. 近期更新
](
#2-近期更新
)
-
[
3. 特性
](
#3-特性
)
-
[
4. 效果展示
](
#4-效果展示
)
-
[
4.1 版面分析和表格识别
](
#41-版面分析和表格识别
)
-
[
4.2 DOC-VQA
](
#42-doc-vqa
)
-
[
5. 快速体验
](
#5-快速体验
)
-
[
6. PP-Structure 介绍
](
#6-pp-structure-介绍
)
-
[
6.1 版面分析+表格识别
](
#61-版面分析表格识别
)
-
[
6.1.1 版面分析
](
#611-版面分析
)
-
[
6.1.2 表格识别
](
#612-表格识别
)
-
[
6.2 DOC-VQA
](
#62-doc-vqa
)
-
[
7. 模型库
](
#7-模型库
)
-
[
7.1 版面分析模型
](
#71-版面分析模型
)
-
[
7.2 OCR和表格识别模型
](
#72-ocr和表格识别模型
)
-
[
7.2 DOC-VQA 模型
](
#72-doc-vqa-模型
)
# PP-Structure 文档分析
-
[
1. 简介
](
#1
)
-
[
2. 近期更新
](
#2
)
-
[
3. 特性
](
#3
)
-
[
4. 效果展示
](
#4
)
-
[
4.1 版面分析和表格识别
](
#41
)
-
[
4.2 DocVQA
](
#42
)
-
[
5. 快速体验
](
#5
)
-
[
6. PP-Structure 介绍
](
#6
)
-
[
6.1 版面分析+表格识别
](
#61
)
-
[
6.1.1 版面分析
](
#611
)
-
[
6.1.2 表格识别
](
#612
)
-
[
6.2 DocVQA
](
#62
)
-
[
7. 模型库
](
#7
)
-
[
7.1 版面分析模型
](
#71
)
-
[
7.2 OCR和表格识别模型
](
#72
)
-
[
7.3 DocVQA 模型
](
#73
)
<a
name=
"1"
></a>
## 1. 简介
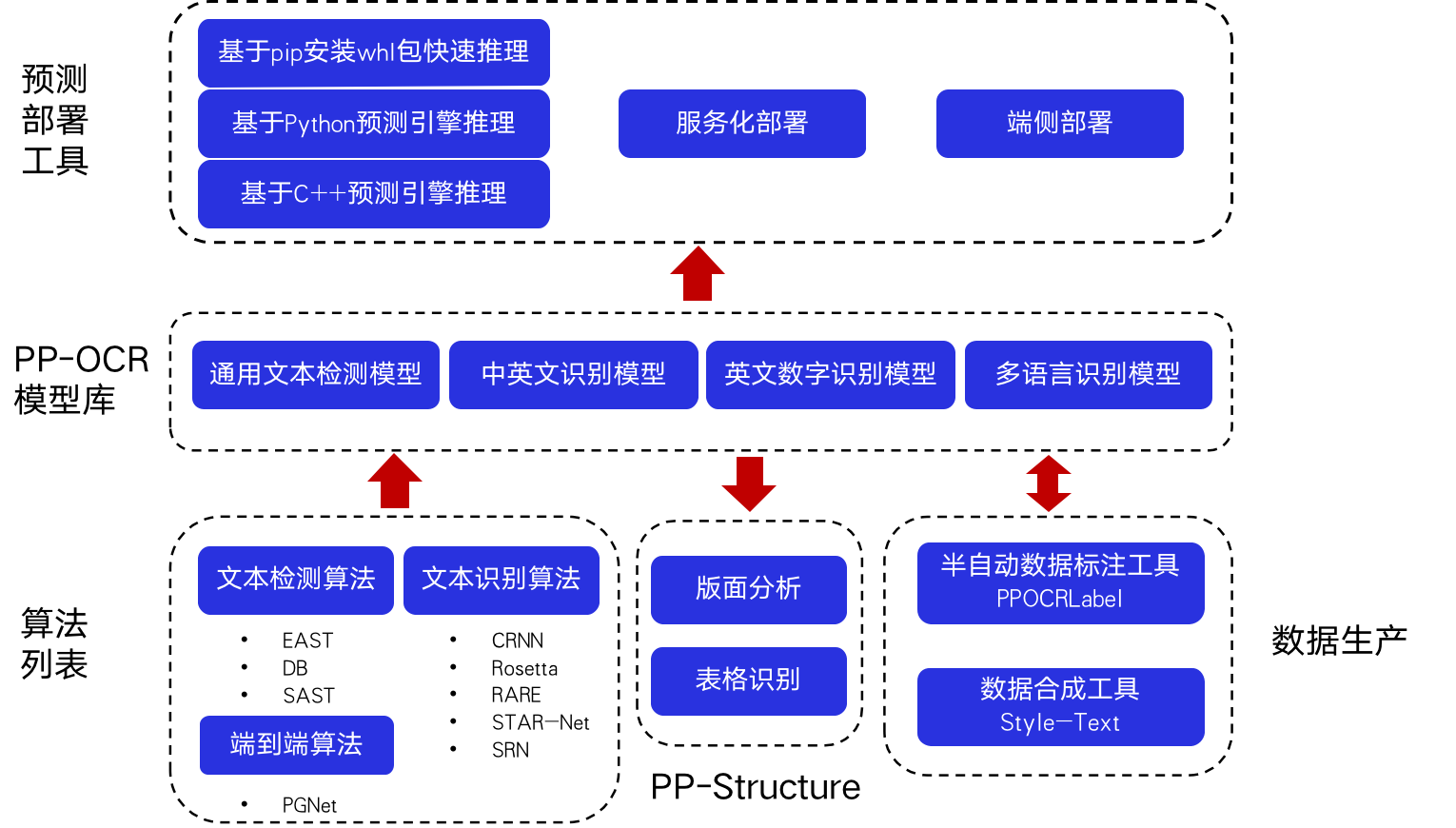
PP-Structure是一个可用于复杂文档结构分析和处理的OCR工具包,旨在帮助开发者更好的完成文档理解相关任务。
<a
name=
"2"
></a>
## 2. 近期更新
*
2022.02.12 D
OC-
VQA增加LayoutLMv2模型。
*
2022.02.12 D
oc
VQA增加LayoutLMv2模型。
*
2021.12.07 新增
[
DOC-VQA任务SER和RE
](
vqa/README.md
)
。
<a
name=
"3"
></a>
## 3. 特性
PP-Structure的主要特性如下:
...
...
@@ -33,21 +37,24 @@ PP-Structure的主要特性如下:
-
支持表格区域进行结构化分析,最终结果输出Excel文件
-
支持python whl包和命令行两种方式,简单易用
-
支持版面分析和表格结构化两类任务自定义训练
-
支持文档视觉问答(Document Visual Question Answering,D
OC-
VQA)任务-语义实体识别(Semantic Entity Recognition,SER)和关系抽取(Relation Extraction,RE)
-
支持文档视觉问答(Document Visual Question Answering,D
oc
VQA)任务-语义实体识别(Semantic Entity Recognition,SER)和关系抽取(Relation Extraction,RE)
<a
name=
"4"
></a>
## 4. 效果展示
<a
name=
"41"
></a>
### 4.1 版面分析和表格识别
<img
src=
".
.
/doc/table/ppstructure.GIF"
width=
"100%"
/>
<img
src=
"./doc
s
/table/ppstructure.GIF"
width=
"100%"
/>
图中展示了版面分析+表格识别的整体流程,图片先有版面分析划分为图像、文本、标题和表格四种区域,然后对图像、文本和标题三种区域进行OCR的检测识别,对表格进行表格识别,其中图像还会被存储下来以便使用。
<a
name=
"42"
></a>
### 4.2 DOC-VQA
*
SER

| !
[](
.
.
/doc/vqa/result_ser/zh_val_42_ser.jpg
)

| !
[](
./doc
s
/vqa/result_ser/zh_val_42_ser.jpg
)
---|---
图中不同颜色的框表示不同的类别,对于XFUN数据集,有
`QUESTION`
,
`ANSWER`
,
`HEADER`
3种类别
...
...
@@ -60,46 +67,55 @@ PP-Structure的主要特性如下:
*
RE

| !
[](
.
.
/doc/vqa/result_re/zh_val_40_re.jpg
)

| !
[](
./doc
s
/vqa/result_re/zh_val_40_re.jpg
)
---|---
图中红色框表示问题,蓝色框表示答案,问题和答案之间使用绿色线连接。在OCR检测框的左上方也标出了对应的类别和OCR识别结果。
<a
name=
"5"
></a>
## 5. 快速体验
请参考
[
快速
安装
](
./docs/quickstart.md
)
教程。
请参考
[
快速
使用
](
./docs/quickstart.md
)
教程。
<a
name=
"6"
></a>
## 6. PP-Structure 介绍
<a
name=
"61"
></a>
### 6.1 版面分析+表格识别


在PP-Structure中,图片会先经由Layout-Parser进行版面分析,在版面分析中,会对图片里的区域进行分类,包括
**文字、标题、图片、列表和表格**
5类。对于前4类区域,直接使用PP-OCR完成对应区域文字检测与识别。对于表格类区域,经过表格结构化处理后,表格图片转换为相同表格样式的Excel文件。
<a
name=
"611"
></a>
#### 6.1.1 版面分析
版面分析对文档数据进行区域分类,其中包括版面分析工具的Python脚本使用、提取指定类别检测框、性能指标以及自定义训练版面分析模型,详细内容可以参考
[
文档
](
layout/README_ch.md
)
。
<a
name=
"612"
></a>
#### 6.1.2 表格识别
表格识别将表格图片转换为excel文档,其中包含对于表格文本的检测和识别以及对于表格结构和单元格坐标的预测,详细说明参考
[
文档
](
table/README_ch.md
)
。
### 6.2 DOC-VQA
<a
name=
"62"
></a>
### 6.2 DocVQA
D
OC-
VQA指文档视觉问答,其中包括语义实体识别 (Semantic Entity Recognition, SER) 和关系抽取 (Relation Extraction, RE) 任务。基于 SER 任务,可以完成对图像中的文本识别与分类;基于 RE 任务,可以完成对图象中的文本内容的关系提取,如判断问题对(pair),详细说明参考
[
文档
](
vqa/README.md
)
。
D
oc
VQA指文档视觉问答,其中包括语义实体识别 (Semantic Entity Recognition, SER) 和关系抽取 (Relation Extraction, RE) 任务。基于 SER 任务,可以完成对图像中的文本识别与分类;基于 RE 任务,可以完成对图象中的文本内容的关系提取,如判断问题对(pair),详细说明参考
[
文档
](
vqa/README.md
)
。
<a
name=
"7"
></a>
## 7. 模型库
PP-Structure系列模型列表(更新中)
<a
name=
"71"
></a>
### 7.1 版面分析模型
|模型名称|模型简介|下载地址| label_map|
| --- | --- | --- | --- |
| ppyolov2_r50vd_dcn_365e_publaynet | PubLayNet 数据集训练的版面分析模型,可以划分
**文字、标题、表格、图片以及列表**
5类区域 |
[
PubLayNet
](
https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_publaynet.tar
)
| {0: "Text", 1: "Title", 2: "List", 3:"Table", 4:"Figure"}|
<a
name=
"72"
></a>
### 7.2 OCR和表格识别模型
|模型名称|模型简介|模型大小|下载地址|
...
...
@@ -108,7 +124,8 @@ PP-Structure系列模型列表(更新中)
|ch_PP-OCRv2_rec_slim|【最新】slim量化版超轻量模型,支持中英文、数字识别| 9M |
[
推理模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_train.tar
)
|
|en_ppocr_mobile_v2.0_table_structure|PubLayNet数据集训练的英文表格场景的表格结构预测|18.6M|
[
推理模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_structure_train.tar
)
|
### 7.2 DOC-VQA 模型
<a
name=
"73"
></a>
### 7.3 DocVQA 模型
|模型名称|模型简介|模型大小|下载地址|
| --- | --- | --- | --- |
...
...
ppstructure/docs/inference.md
0 → 100644
View file @
112ad00d
# 基于Python预测引擎推理
-
[
版面分析+表格识别
](
#1
)
-
[
DocVQA
](
#2
)
<a
name=
"1"
></a>
## 1. 版面分析+表格识别
```
bash
cd
ppstructure
# 下载模型
mkdir
inference
&&
cd
inference
# 下载PP-OCRv2文本检测模型并解压
wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_slim_quant_infer.tar
&&
tar
xf ch_PP-OCRv2_det_slim_quant_infer.tar
# 下载PP-OCRv2文本识别模型并解压
wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar
&&
tar
xf ch_PP-OCRv2_rec_slim_quant_infer.tar
# 下载超轻量级英文表格预测模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar
&&
tar
xf en_ppocr_mobile_v2.0_table_structure_infer.tar
cd
..
python3 predict_system.py
--det_model_dir
=
inference/ch_PP-OCRv2_det_slim_quant_infer
\
--rec_model_dir
=
inference/ch_PP-OCRv2_rec_slim_quant_infer
\
--table_model_dir
=
inference/en_ppocr_mobile_v2.0_table_structure_infer
\
--image_dir
=
../doc/table/1.png
\
--rec_char_dict_path
=
../ppocr/utils/ppocr_keys_v1.txt
\
--table_char_dict_path
=
../ppocr/utils/dict/table_structure_dict.txt
\
--output
=
../output/table
\
--vis_font_path
=
../doc/fonts/simfang.ttf
```
运行完成后,每张图片会在
`output`
字段指定的目录下的
`talbe`
目录下有一个同名目录,图片里的每个表格会存储为一个excel,图片区域会被裁剪之后保存下来,excel文件和图片名名为表格在图片里的坐标。
<a
name=
"2"
></a>
## 2. DocVQA
```
bash
cd
ppstructure
# 下载模型
mkdir
inference
&&
cd
inference
# 下载SER xfun 模型并解压
wget https://paddleocr.bj.bcebos.com/pplayout/PP-Layout_v1.0_ser_pretrained.tar
&&
tar
xf PP-Layout_v1.0_ser_pretrained.tar
cd
..
python3 predict_system.py
--model_name_or_path
=
vqa/PP-Layout_v1.0_ser_pretrained/
\
--mode
=
vqa
\
--image_dir
=
vqa/images/input/zh_val_0.jpg
\
--vis_font_path
=
../doc/fonts/simfang.ttf
```
运行完成后,每张图片会在
`output`
字段指定的目录下的
`vqa`
目录下存放可视化之后的图片,图片名和输入图片名一致。
\ No newline at end of file
ppstructure/docs/inference_en.md
0 → 100644
View file @
112ad00d
# 基于Python预测引擎推理
-
[
版面分析+表格识别
](
#1
)
-
[
DocVQA
](
#2
)
<a
name=
"1"
></a>
## 1. 版面分析+表格识别
```
bash
cd
ppstructure
# 下载模型
mkdir
inference
&&
cd
inference
# 下载PP-OCRv2文本检测模型并解压
wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_slim_quant_infer.tar
&&
tar
xf ch_PP-OCRv2_det_slim_quant_infer.tar
# 下载PP-OCRv2文本识别模型并解压
wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar
&&
tar
xf ch_PP-OCRv2_rec_slim_quant_infer.tar
# 下载超轻量级英文表格预测模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar
&&
tar
xf en_ppocr_mobile_v2.0_table_structure_infer.tar
cd
..
python3 predict_system.py
--det_model_dir
=
inference/ch_PP-OCRv2_det_slim_quant_infer
\
--rec_model_dir
=
inference/ch_PP-OCRv2_rec_slim_quant_infer
\
--table_model_dir
=
inference/en_ppocr_mobile_v2.0_table_structure_infer
\
--image_dir
=
../doc/table/1.png
\
--rec_char_dict_path
=
../ppocr/utils/ppocr_keys_v1.txt
\
--table_char_dict_path
=
../ppocr/utils/dict/table_structure_dict.txt
\
--output
=
../output/table
\
--vis_font_path
=
../doc/fonts/simfang.ttf
```
运行完成后,每张图片会在
`output`
字段指定的目录下的
`talbe`
目录下有一个同名目录,图片里的每个表格会存储为一个excel,图片区域会被裁剪之后保存下来,excel文件和图片名名为表格在图片里的坐标。
<a
name=
"2"
></a>
## 2. DocVQA
```
bash
cd
ppstructure
# 下载模型
mkdir
inference
&&
cd
inference
# 下载SER xfun 模型并解压
wget https://paddleocr.bj.bcebos.com/pplayout/PP-Layout_v1.0_ser_pretrained.tar
&&
tar
xf PP-Layout_v1.0_ser_pretrained.tar
cd
..
python3 predict_system.py
--model_name_or_path
=
vqa/PP-Layout_v1.0_ser_pretrained/
\
--mode
=
vqa
\
--image_dir
=
vqa/images/input/zh_val_0.jpg
\
--vis_font_path
=
../doc/fonts/simfang.ttf
```
运行完成后,每张图片会在
`output`
字段指定的目录下的
`vqa`
目录下存放可视化之后的图片,图片名和输入图片名一致。
\ No newline at end of file
ppstructure/docs/models_list.md
View file @
112ad00d
-
[
PP-Structure 系列模型列表
](
#pp-structure-系列模型列表
)
-
[
1. LayoutParser 模型
](
#1-layoutparser-模型
)
-
[
2. OCR和表格识别模型
](
#2-ocr和表格识别模型
)
-
[
2.1 OCR
](
#21-ocr
)
-
[
2.2 表格识别模型
](
#22-表格识别模型
)
-
[
3. VQA模型
](
#3-vqa模型
)
-
[
4. KIE模型
](
#4-kie模型
)
# PP-Structure 系列模型列表
-
[
1. 版面分析模型
](
#1
)
-
[
2. OCR和表格识别模型
](
#2
)
-
[
2.1 OCR
](
#21
)
-
[
2.2 表格识别模型
](
#22
)
-
[
3. VQA模型
](
#3
)
-
[
4. KIE模型
](
#4
)
## 1. LayoutParser 模型
<a
name=
"1"
></a>
## 1. 版面分析模型
|模型名称|模型简介|下载地址|label_map|
| --- | --- | --- | --- |
...
...
@@ -17,8 +17,10 @@
| ppyolov2_r50vd_dcn_365e_tableBank_word | TableBank Word 数据集训练的版面分析模型,只能检测表格 |
[
推理模型
](
https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_tableBank_word.tar
)
| {0:"Table"}|
| ppyolov2_r50vd_dcn_365e_tableBank_latex | TableBank Latex 数据集训练的版面分析模型,只能检测表格 |
[
推理模型
](
https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_tableBank_latex.tar
)
| {0:"Table"}|
<a
name=
"2"
></a>
## 2. OCR和表格识别模型
<a
name=
"21"
></a>
### 2.1 OCR
|模型名称|模型简介|推理模型大小|下载地址|
...
...
@@ -28,12 +30,14 @@
如需要使用其他OCR模型,可以在
[
PP-OCR model_list
](
../../doc/doc_ch/models_list.md
)
下载模型或者使用自己训练好的模型配置到
`det_model_dir`
,
`rec_model_dir`
两个字段即可。
<a
name=
"22"
></a>
### 2.2 表格识别模型
|模型名称|模型简介|推理模型大小|下载地址|
| --- | --- | --- | --- |
|en_ppocr_mobile_v2.0_table_structure|PubLayNet数据集训练的英文表格场景的表格结构预测|18.6M|
[
推理模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_structure_train.tar
)
|
<a
name=
"3"
></a>
## 3. VQA模型
|模型名称|模型简介|推理模型大小|下载地址|
...
...
@@ -44,6 +48,7 @@
|re_LayoutLMv2_xfun_zh|基于LayoutLMv2在xfun中文数据集上训练的RE模型|765M|
[
推理模型 coming soon
](
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/pplayout/re_LayoutLMv2_xfun_zh.tar
)
|
|ser_LayoutLM_xfun_zh|基于LayoutLM在xfun中文数据集上训练的SER模型|430M|
[
推理模型 coming soon
](
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutLM_xfun_zh.tar
)
|
<a
name=
"4"
></a>
## 4. KIE模型
|模型名称|模型简介|模型大小|下载地址|
...
...
ppstructure/docs/models_list_en.md
0 → 100644
View file @
112ad00d
# PP-Structure 系列模型列表
-
[
1. 版面分析模型
](
#1
)
-
[
2. OCR和表格识别模型
](
#2
)
-
[
2.1 OCR
](
#21
)
-
[
2.2 表格识别模型
](
#22
)
-
[
3. VQA模型
](
#3
)
-
[
4. KIE模型
](
#4
)
<a
name=
"1"
></a>
## 1. 版面分析模型
|模型名称|模型简介|下载地址|label_map|
| --- | --- | --- | --- |
| ppyolov2_r50vd_dcn_365e_publaynet | PubLayNet 数据集训练的版面分析模型,可以划分
**文字、标题、表格、图片以及列表**
5类区域 |
[
推理模型
](
https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_publaynet.tar
)
/
[
训练模型
](
https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_publaynet_pretrained.pdparams
)
|{0: "Text", 1: "Title", 2: "List", 3:"Table", 4:"Figure"}|
| ppyolov2_r50vd_dcn_365e_tableBank_word | TableBank Word 数据集训练的版面分析模型,只能检测表格 |
[
推理模型
](
https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_tableBank_word.tar
)
| {0:"Table"}|
| ppyolov2_r50vd_dcn_365e_tableBank_latex | TableBank Latex 数据集训练的版面分析模型,只能检测表格 |
[
推理模型
](
https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_tableBank_latex.tar
)
| {0:"Table"}|
<a
name=
"2"
></a>
## 2. OCR和表格识别模型
<a
name=
"21"
></a>
### 2.1 OCR
|模型名称|模型简介|推理模型大小|下载地址|
| --- | --- | --- | --- |
|en_ppocr_mobile_v2.0_table_det|PubLayNet数据集训练的英文表格场景的文字检测|4.7M|
[
推理模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_det_infer.tar
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_det_train.tar
)
|
|en_ppocr_mobile_v2.0_table_rec|PubLayNet数据集训练的英文表格场景的文字识别|6.9M|
[
推理模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_rec_infer.tar
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_rec_train.tar
)
|
如需要使用其他OCR模型,可以在
[
PP-OCR model_list
](
../../doc/doc_ch/models_list.md
)
下载模型或者使用自己训练好的模型配置到
`det_model_dir`
,
`rec_model_dir`
两个字段即可。
<a
name=
"22"
></a>
### 2.2 表格识别模型
|模型名称|模型简介|推理模型大小|下载地址|
| --- | --- | --- | --- |
|en_ppocr_mobile_v2.0_table_structure|PubLayNet数据集训练的英文表格场景的表格结构预测|18.6M|
[
推理模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_structure_train.tar
)
|
<a
name=
"3"
></a>
## 3. VQA模型
|模型名称|模型简介|推理模型大小|下载地址|
| --- | --- | --- | --- |
|ser_LayoutXLM_xfun_zh|基于LayoutXLM在xfun中文数据集上训练的SER模型|1.4G|
[
推理模型 coming soon
](
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar
)
|
|re_LayoutXLM_xfun_zh|基于LayoutXLM在xfun中文数据集上训练的RE模型|1.4G|
[
推理模型 coming soon
](
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar
)
|
|ser_LayoutLMv2_xfun_zh|基于LayoutLMv2在xfun中文数据集上训练的SER模型|778M|
[
推理模型 coming soon
](
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutLMv2_xfun_zh.tar
)
|
|re_LayoutLMv2_xfun_zh|基于LayoutLMv2在xfun中文数据集上训练的RE模型|765M|
[
推理模型 coming soon
](
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/pplayout/re_LayoutLMv2_xfun_zh.tar
)
|
|ser_LayoutLM_xfun_zh|基于LayoutLM在xfun中文数据集上训练的SER模型|430M|
[
推理模型 coming soon
](
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutLM_xfun_zh.tar
)
|
<a
name=
"4"
></a>
## 4. KIE模型
|模型名称|模型简介|模型大小|下载地址|
| --- | --- | --- | --- |
|SDMGR|关键信息提取模型|78M|
[
推理模型 coming soon
](
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.1/kie/kie_vgg16.tar
)
|
ppstructure/docs/quickstart.md
View file @
112ad00d
# PP-Structure 快速开始
-
[
PP-Structure 快速开始
](
#pp-structure-快速开始
)
-
[
1. 安装依赖包
](
#1-安装依赖包
)
-
[
2. 便捷使用
](
#2-便捷使用
)
-
[
2.1 命令行使用
](
#21-命令行使用
)
-
[
2.2 Python脚本使用
](
#22-python脚本使用
)
-
[
2.3 返回结果说明
](
#23-返回结果说明
)
-
[
2.4 参数说明
](
#24-参数说明
)
-
[
3. Python脚本使用
](
#3-python脚本使用
)
-
[
1. 安装依赖包
](
#1
)
-
[
2. 便捷使用
](
#2
)
-
[
2.1 命令行使用
](
#21
)
-
[
2.1.1 版面分析+表格识别
](
#211
)
-
[
2.1.2 DocVQA
](
#212
)
-
[
2.2 Python脚本使用
](
#22
)
-
[
2.2.1 版面分析+表格识别
](
#221
)
-
[
2.2.2 DocVQA
](
#222
)
-
[
2.3 返回结果说明
](
#23
)
-
[
2.3.1 版面分析+表格识别
](
#231
)
-
[
2.3.2 DocVQA
](
#232
)
-
[
2.4 参数说明
](
#24
)
<a
name=
"1"
></a>
## 1. 安装依赖包
```
bash
pip
install
"paddleocr>=2.3.0.2"
# 推荐使用2.3.0.2+版本
pip3
install
-U
https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
# 安装 PaddleNLP
git clone https://github.com/PaddlePaddle/PaddleNLP
-b
develop
cd
PaddleNLP
pip3
install
-e
.
# 安装 paddleocr,推荐使用2.3.0.2+版本
pip3
install
"paddleocr>=2.3.0.2"
# 安装 版面分析依赖包layoutparser(如不需要版面分析功能,可跳过)
pip3
install
-U
https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
# 安装 DocVQA依赖包paddlenlp(如不需要DocVQA功能,可跳过)
pip
install
paddlenlp
```
<a
name=
"2"
></a>
## 2. 便捷使用
### 2.1 命令行使用
*
版面分析+表格识别
<a
name=
"21"
></a>
### 2.1 命令行使用
<a
name=
"211"
></a>
#### 2.1.1 版面分析+表格识别
```
bash
paddleocr
--image_dir
=
../doc/table/1.png
--type
=
structure
```
*
VQA
<a
name=
"212"
></a>
#### 2.1.2 DocVQA
请参考:
[
文档视觉问答
](
../vqa/README.md
)
。
<a
name=
"22"
></a>
### 2.2 Python脚本使用
*
版面分析+表格识别
<a
name=
"221"
></a>
#### 2.2.1 版面分析+表格识别
```
python
import
os
import
cv2
...
...
@@ -64,14 +76,17 @@ im_show = Image.fromarray(im_show)
im_show
.
save
(
'result.jpg'
)
```
*
VQA
<a
name=
"222"
></a>
#### 2.2.2 DocVQA
请参考:
[
文档视觉问答
](
../vqa/README.md
)
。
<a
name=
"23"
></a>
### 2.3 返回结果说明
PP-Structure的返回结果为一个dict组成的list,示例如下
*
版面分析+表格识别
<a
name=
"231"
></a>
#### 2.3.1 版面分析+表格识别
```
shell
[
{
'type'
:
'Text'
,
...
...
@@ -89,10 +104,22 @@ dict 里各个字段说明如下
|bbox|图片区域的在原图的坐标,分别[左上角x,左上角y,右下角x,右下角y]|
|res|图片区域的OCR或表格识别结果。
<br>
表格: 表格的HTML字符串;
<br>
OCR: 一个包含各个单行文字的检测坐标和识别结果的元组|
*
VQA
运行完成后,每张图片会在
`output`
字段指定的目录下有一个同名目录,图片里的每个表格会存储为一个excel,图片区域会被裁剪之后保存下来,excel文件和图片名为表格在图片里的坐标。
```
/output/table/1/
└─ res.txt
└─ [454, 360, 824, 658].xlsx 表格识别结果
└─ [16, 2, 828, 305].jpg 被裁剪出的图片区域
└─ [17, 361, 404, 711].xlsx 表格识别结果
```
<a
name=
"232"
></a>
#### 2.3.2 DocVQA
请参考:
[
文档视觉问答
](
../vqa/README.md
)
。
<a
name=
"24"
></a>
### 2.4 参数说明
| 字段 | 说明 | 默认值 |
...
...
@@ -109,51 +136,3 @@ dict 里各个字段说明如下
| mode | pipeline预测模式,structure: 版面分析+表格识别; VQA: SER文档信息抽取 | structure |
大部分参数和PaddleOCR whl包保持一致,见
[
whl包文档
](
../../doc/doc_ch/whl.md
)
运行完成后,每张图片会在
`output`
字段指定的目录下有一个同名目录,图片里的每个表格会存储为一个excel,图片区域会被裁剪之后保存下来,excel文件和图片名名为表格在图片里的坐标。
## 3. Python脚本使用
*
版面分析+表格识别
```
bash
cd
ppstructure
# 下载模型
mkdir
inference
&&
cd
inference
# 下载PP-OCRv2文本检测模型并解压
wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_slim_quant_infer.tar
&&
tar
xf ch_PP-OCRv2_det_slim_quant_infer.tar
# 下载PP-OCRv2文本识别模型并解压
wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar
&&
tar
xf ch_PP-OCRv2_rec_slim_quant_infer.tar
# 下载超轻量级英文表格预测模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar
&&
tar
xf en_ppocr_mobile_v2.0_table_structure_infer.tar
cd
..
python3 predict_system.py
--det_model_dir
=
inference/ch_PP-OCRv2_det_slim_quant_infer
\
--rec_model_dir
=
inference/ch_PP-OCRv2_rec_slim_quant_infer
\
--table_model_dir
=
inference/en_ppocr_mobile_v2.0_table_structure_infer
\
--image_dir
=
../doc/table/1.png
\
--rec_char_dict_path
=
../ppocr/utils/ppocr_keys_v1.txt
\
--table_char_dict_path
=
../ppocr/utils/dict/table_structure_dict.txt
\
--output
=
../output/table
\
--vis_font_path
=
../doc/fonts/simfang.ttf
```
运行完成后,每张图片会在
`output`
字段指定的目录下的
`talbe`
目录下有一个同名目录,图片里的每个表格会存储为一个excel,图片区域会被裁剪之后保存下来,excel文件和图片名名为表格在图片里的坐标。
*
VQA
```
bash
cd
ppstructure
# 下载模型
mkdir
inference
&&
cd
inference
# 下载SER xfun 模型并解压
wget https://paddleocr.bj.bcebos.com/pplayout/PP-Layout_v1.0_ser_pretrained.tar
&&
tar
xf PP-Layout_v1.0_ser_pretrained.tar
cd
..
python3 predict_system.py
--model_name_or_path
=
vqa/PP-Layout_v1.0_ser_pretrained/
\
--mode
=
vqa
\
--image_dir
=
vqa/images/input/zh_val_0.jpg
\
--vis_font_path
=
../doc/fonts/simfang.ttf
```
运行完成后,每张图片会在
`output`
字段指定的目录下的
`vqa`
目录下存放可视化之后的图片,图片名和输入图片名一致。
ppstructure/docs/quickstart_en.md
0 → 100644
View file @
112ad00d
# PP-Structure 快速开始
-
[
1. 安装依赖包
](
#1
)
-
[
2. 便捷使用
](
#2
)
-
[
2.1 命令行使用
](
#21
)
-
[
2.1.1 版面分析+表格识别
](
#211
)
-
[
2.1.2 DocVQA
](
#212
)
-
[
2.2 Python脚本使用
](
#22
)
-
[
2.2.1 版面分析+表格识别
](
#221
)
-
[
2.2.2 DocVQA
](
#222
)
-
[
2.3 返回结果说明
](
#23
)
-
[
2.3.1 版面分析+表格识别
](
#231
)
-
[
2.3.2 DocVQA
](
#232
)
-
[
2.4 参数说明
](
#24
)
<a
name=
"1"
></a>
## 1. 安装依赖包
```
bash
# 安装 paddleocr,推荐使用2.3.0.2+版本
pip3
install
"paddleocr>=2.3.0.2"
# 安装 版面分析依赖包layoutparser(如不需要版面分析功能,可跳过)
pip3
install
-U
https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
# 安装 DocVQA依赖包paddlenlp(如不需要DocVQA功能,可跳过)
pip
install
paddlenlp
```
<a
name=
"2"
></a>
## 2. 便捷使用
<a
name=
"21"
></a>
### 2.1 命令行使用
<a
name=
"211"
></a>
#### 2.1.1 版面分析+表格识别
```
bash
paddleocr
--image_dir
=
../doc/table/1.png
--type
=
structure
```
<a
name=
"212"
></a>
#### 2.1.2 DocVQA
请参考:
[
文档视觉问答
](
../vqa/README.md
)
。
<a
name=
"22"
></a>
### 2.2 Python脚本使用
<a
name=
"221"
></a>
#### 2.2.1 版面分析+表格识别
```
python
import
os
import
cv2
from
paddleocr
import
PPStructure
,
draw_structure_result
,
save_structure_res
table_engine
=
PPStructure
(
show_log
=
True
)
save_folder
=
'./output/table'
img_path
=
'../doc/table/1.png'
img
=
cv2
.
imread
(
img_path
)
result
=
table_engine
(
img
)
save_structure_res
(
result
,
save_folder
,
os
.
path
.
basename
(
img_path
).
split
(
'.'
)[
0
])
for
line
in
result
:
line
.
pop
(
'img'
)
print
(
line
)
from
PIL
import
Image
font_path
=
'../doc/fonts/simfang.ttf'
# PaddleOCR下提供字体包
image
=
Image
.
open
(
img_path
).
convert
(
'RGB'
)
im_show
=
draw_structure_result
(
image
,
result
,
font_path
=
font_path
)
im_show
=
Image
.
fromarray
(
im_show
)
im_show
.
save
(
'result.jpg'
)
```
<a
name=
"222"
></a>
#### 2.2.2 DocVQA
请参考:
[
文档视觉问答
](
../vqa/README.md
)
。
<a
name=
"23"
></a>
### 2.3 返回结果说明
PP-Structure的返回结果为一个dict组成的list,示例如下
<a
name=
"231"
></a>
#### 2.3.1 版面分析+表格识别
```
shell
[
{
'type'
:
'Text'
,
'bbox'
:
[
34, 432, 345, 462],
'res'
:
([[
36.0, 437.0, 341.0, 437.0, 341.0, 446.0, 36.0, 447.0],
[
41.0, 454.0, 125.0, 453.0, 125.0, 459.0, 41.0, 460.0]],
[(
'Tigure-6. The performance of CNN and IPT models using difforen'
, 0.90060663
)
,
(
'Tent '
, 0.465441
)])
}
]
```
dict 里各个字段说明如下
| 字段 | 说明 |
| --------------- | -------------|
|type|图片区域的类型|
|bbox|图片区域的在原图的坐标,分别[左上角x,左上角y,右下角x,右下角y]|
|res|图片区域的OCR或表格识别结果。
<br>
表格: 表格的HTML字符串;
<br>
OCR: 一个包含各个单行文字的检测坐标和识别结果的元组|
运行完成后,每张图片会在
`output`
字段指定的目录下有一个同名目录,图片里的每个表格会存储为一个excel,图片区域会被裁剪之后保存下来,excel文件和图片名为表格在图片里的坐标。
```
/output/table/1/
└─ res.txt
└─ [454, 360, 824, 658].xlsx 表格识别结果
└─ [16, 2, 828, 305].jpg 被裁剪出的图片区域
└─ [17, 361, 404, 711].xlsx 表格识别结果
```
<a
name=
"232"
></a>
#### 2.3.2 DocVQA
请参考:
[
文档视觉问答
](
../vqa/README.md
)
。
<a
name=
"24"
></a>
### 2.4 参数说明
| 字段 | 说明 | 默认值 |
| --------------- | ---------------------------------------- | ------------------------------------------- |
| output | excel和识别结果保存的地址 | ./output/table |
| table_max_len | 表格结构模型预测时,图像的长边resize尺度 | 488 |
| table_model_dir | 表格结构模型 inference 模型地址 | None |
| table_char_dict_path | 表格结构模型所用字典地址 | ../ppocr/utils/dict/table_structure_dict.txt |
| layout_path_model | 版面分析模型模型地址,可以为在线地址或者本地地址,当为本地地址时,需要指定 layout_label_map, 命令行模式下可通过--layout_label_map='{0: "Text", 1: "Title", 2: "List", 3:"Table", 4:"Figure"}' 指定 | lp://PubLayNet/ppyolov2_r50vd_dcn_365e_publaynet/config |
| layout_label_map | 版面分析模型模型label映射字典 | None |
| model_name_or_path | VQA SER模型地址 | None |
| max_seq_length | VQA SER模型最大支持token长度 | 512 |
| label_map_path | VQA SER 标签文件地址 | ./vqa/labels/labels_ser.txt |
| mode | pipeline预测模式,structure: 版面分析+表格识别; VQA: SER文档信息抽取 | structure |
大部分参数和PaddleOCR whl包保持一致,见
[
whl包文档
](
../../doc/doc_ch/whl.md
)
doc/table/1.png
→
ppstructure/
doc
s
/table/1.png
View file @
112ad00d
File moved
doc/table/layout.jpg
→
ppstructure/
doc
s
/table/layout.jpg
View file @
112ad00d
File moved
doc/table/paper-image.jpg
→
ppstructure/
doc
s
/table/paper-image.jpg
View file @
112ad00d
File moved
doc/table/pipeline.jpg
→
ppstructure/
doc
s
/table/pipeline.jpg
View file @
112ad00d
File moved
doc/table/pipeline_en.jpg
→
ppstructure/
doc
s
/table/pipeline_en.jpg
View file @
112ad00d
File moved
doc/table/ppstructure.GIF
→
ppstructure/
doc
s
/table/ppstructure.GIF
View file @
112ad00d
File moved
doc/table/result_all.jpg
→
ppstructure/
doc
s
/table/result_all.jpg
View file @
112ad00d
File moved
doc/table/result_text.jpg
→
ppstructure/
doc
s
/table/result_text.jpg
View file @
112ad00d
File moved
doc/table/table.jpg
→
ppstructure/
doc
s
/table/table.jpg
View file @
112ad00d
File moved
doc/table/tableocr_pipeline.jpg
→
ppstructure/
doc
s
/table/tableocr_pipeline.jpg
View file @
112ad00d
File moved
Prev
1
2
3
4
5
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}