Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
wangsen
paddle_dbnet
Commits
025692aa
Commit
025692aa
authored
Oct 19, 2021
by
stephon
Browse files
Merge branch 'dygraph' of
https://github.com/PaddlePaddle/PaddleOCR
into feature_amp_train
parents
82f19a31
3bc7670f
Changes
32
Hide whitespace changes
Inline
Side-by-side
Showing
12 changed files
with
115 additions
and
91 deletions
+115
-91
PTDN/readme.md
PTDN/readme.md
+38
-26
PTDN/results/cpp_ppocr_det_mobile_results_fp16.txt
PTDN/results/cpp_ppocr_det_mobile_results_fp16.txt
+0
-0
PTDN/results/cpp_ppocr_det_mobile_results_fp32.txt
PTDN/results/cpp_ppocr_det_mobile_results_fp32.txt
+0
-0
PTDN/results/python_ppocr_det_mobile_results_fp16.txt
PTDN/results/python_ppocr_det_mobile_results_fp16.txt
+0
-0
PTDN/results/python_ppocr_det_mobile_results_fp32.txt
PTDN/results/python_ppocr_det_mobile_results_fp32.txt
+0
-0
PTDN/test_inference_cpp.sh
PTDN/test_inference_cpp.sh
+5
-1
PTDN/test_serving.sh
PTDN/test_serving.sh
+39
-35
PTDN/test_train_inference_python.sh
PTDN/test_train_inference_python.sh
+11
-6
doc/doc_ch/enhanced_ctc_loss.md
doc/doc_ch/enhanced_ctc_loss.md
+3
-3
ppocr/losses/ace_loss.py
ppocr/losses/ace_loss.py
+1
-2
ppocr/losses/center_loss.py
ppocr/losses/center_loss.py
+18
-18
tests/docs/test.png
tests/docs/test.png
+0
-0
No files found.
tests
/readme.md
→
PTDN
/readme.md
View file @
025692aa
# 推理部署导航
飞桨除了基本的模型训练和预测,还提供了支持多端多平台的高性能推理部署工具。本文档提供了PaddleOCR中所有模型的推理部署导航,方便用户查阅每种模型的推理部署打通情况,并可以进行一键测试。
## 1. 简介
飞桨除了基本的模型训练和预测,还提供了支持多端多平台的高性能推理部署工具。本文档提供了PaddleOCR中所有模型的推理部署导航PTDN(Paddle Train Deploy Navigation),方便用户查阅每种模型的推理部署打通情况,并可以进行一键测试。
<div
align=
"center"
>
<img
src=
"docs/guide.png"
width=
"1000"
>
</div>
## 2. 汇总信息
打通情况汇总如下,已填写的部分表示可以使用本工具进行一键测试,未填写的表示正在支持中。
| 算法论文 | 模型名称 | 模型类型 | python训练预测 | 其他 |
| :--- | :--- | :---- | :-------- | :---- |
| DB |ch_ppocr_mobile_v2.0_det | 检测 | 支持 | Paddle Inference: C++预测
<br>
Paddle Serving: Python, C++
<br>
Paddle-Lite: Python, C++ / ARM CPU |
| DB |ch_ppocr_server_v2.0_det | 检测 | 支持 | Paddle Inference: C++预测
<br>
Paddle Serving: Python, C++
<br>
Paddle-Lite: Python, C++ / ARM CPU |
**字段说明:**
-
基础训练预测:包括模型训练、Paddle Inference Python预测。
-
其他:包括Paddle Inference C++预测、Paddle Serving部署、Paddle-Lite部署等。
| 算法论文 | 模型名称 | 模型类型 | 基础训练预测 | 其他 |
| :--- | :--- | :----: | :--------: | :---- |
| DB |ch_ppocr_mobile_v2.0_det | 检测 | 支持 | Paddle Inference: C++
<br>
Paddle Serving: Python, C++
<br>
Paddle-Lite:
<br>
(1) ARM CPU(C++) |
| DB |ch_ppocr_server_v2.0_det | 检测 | 支持 | Paddle Inference: C++
<br>
Paddle Serving: Python, C++
<br>
Paddle-Lite:
<br>
(1) ARM CPU(C++) |
| DB |ch_PP-OCRv2_det | 检测 |
| CRNN |ch_ppocr_mobile_v2.0_rec | 识别 | 支持 | Paddle Inference: C++
预测
<br>
Paddle Serving: Python, C++
<br>
Paddle-Lite:
Python, C++ /
ARM CPU |
| CRNN |ch_ppocr_server_v2.0_rec | 识别 | 支持 | Paddle Inference: C++
预测
<br>
Paddle Serving: Python, C++
<br>
Paddle-Lite:
Python, C++ /
ARM CPU |
| CRNN |ch_ppocr_mobile_v2.0_rec | 识别 | 支持 | Paddle Inference: C++
<br>
Paddle Serving: Python, C++
<br>
Paddle-Lite:
<br>
(1)
ARM CPU
(C++)
|
| CRNN |ch_ppocr_server_v2.0_rec | 识别 | 支持 | Paddle Inference: C++
<br>
Paddle Serving: Python, C++
<br>
Paddle-Lite:
<br>
(1)
ARM CPU
(C++)
|
| CRNN |ch_PP-OCRv2_rec | 识别 |
| PP-OCR |ch_ppocr_mobile_v2.0 | 检测+识别 | 支持 | Paddle Inference: C++
<br>
Paddle Serving: Python, C++
<br>
Paddle-Lite:
<br>
(1) ARM CPU(C++) |
| PP-OCR |ch_ppocr_server_v2.0 | 检测+识别 | 支持 | Paddle Inference: C++
<br>
Paddle Serving: Python, C++
<br>
Paddle-Lite:
<br>
(1) ARM CPU(C++) |
|PP-OCRv2|ch_PP-OCRv2 | 检测+识别 | 支持 | Paddle Inference: C++
<br>
Paddle Serving: Python, C++
<br>
Paddle-Lite:
<br>
(1) ARM CPU(C++) |
| DB |det_mv3_db_v2.0 | 检测 |
| DB |det_r50_vd_db_v2.0 | 检测 |
| EAST |det_mv3_east_v2.0 | 检测 |
...
...
@@ -39,7 +51,7 @@
## 一键测试工具使用
##
3.
一键测试工具使用
### 目录介绍
```
shell
...
...
@@ -56,18 +68,18 @@ tests/
├── ppocr_rec_server_params.txt
# 测试server版ppocr识别模型的参数配置文件
├── ...
├── results/
# 预先保存的预测结果,用于和实际预测结果进行精读比对
├── ppocr_det_mobile_results_fp32.txt
# 预存的mobile版ppocr检测模型fp32精度的结果
├── ppocr_det_mobile_results_fp16.txt
# 预存的mobile版ppocr检测模型fp16精度的结果
├── ppocr_det_mobile_results_fp32
_cpp
.txt
# 预存的mobile版ppocr检测模型c++预测的fp32精度的结果
├── ppocr_det_mobile_results_fp16
_cpp
.txt
# 预存的mobile版ppocr检测模型c++预测的fp16精度的结果
├──
python_
ppocr_det_mobile_results_fp32.txt
# 预存的mobile版ppocr检测模型
python预测
fp32精度的结果
├──
python_
ppocr_det_mobile_results_fp16.txt
# 预存的mobile版ppocr检测模型
python预测
fp16精度的结果
├──
cpp_
ppocr_det_mobile_results_fp32.txt
# 预存的mobile版ppocr检测模型c++预测的fp32精度的结果
├──
cpp_
ppocr_det_mobile_results_fp16.txt
# 预存的mobile版ppocr检测模型c++预测的fp16精度的结果
├── ...
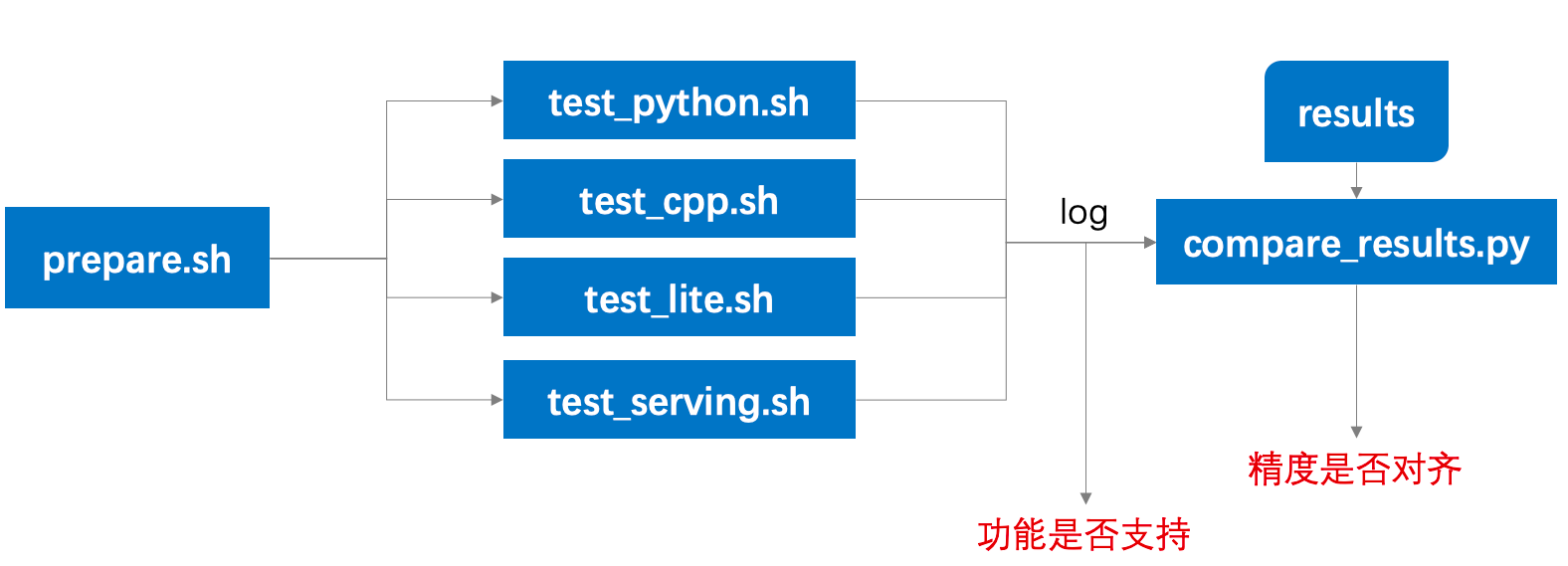
├── prepare.sh
# 完成test_*.sh运行所需要的数据和模型下载
├── test_python.sh
# 测试python训练预测的主程序
├── test_cpp.sh
# 测试c++预测的主程序
├── test_serving.sh
# 测试serving部署预测的主程序
├── test_lite.sh
# 测试lite部署预测的主程序
├── compare_results.py
# 用于对比log中的预测结果与results中的预存结果精度误差是否在限定范围内
└── readme.md
# 使用文档
├── prepare.sh
# 完成test_*.sh运行所需要的数据和模型下载
├── test_
train_inference_
python.sh
# 测试python训练预测的主程序
├── test_
inference_
cpp.sh
# 测试c++预测的主程序
├── test_serving.sh
# 测试serving部署预测的主程序
├── test_lite.sh
# 测试lite部署预测的主程序
├── compare_results.py
# 用于对比log中的预测结果与results中的预存结果精度误差是否在限定范围内
└── readme.md
# 使用文档
```
### 测试流程
...
...
@@ -81,13 +93,13 @@ tests/
3.
用
`compare_results.py`
对比log中的预测结果和预存在results目录下的结果,判断预测精度是否符合预期(在误差范围内)。
其中,有4个测试主程序,功能如下:
-
`test_python.sh`
:测试基于Python的模型训练、评估、推理等基本功能,包括裁剪、量化、蒸馏。
-
`test_cpp.sh`
:测试基于C++的模型推理。
-
`test_
train_inference_
python.sh`
:测试基于Python的模型训练、评估、推理等基本功能,包括裁剪、量化、蒸馏。
-
`test_
inference_
cpp.sh`
:测试基于C++的模型推理。
-
`test_serving.sh`
:测试基于Paddle Serving的服务化部署功能。
-
`test_lite.sh`
:测试基于Paddle-Lite的端侧预测部署功能。
各功能测试中涉及
GPU/CPU、
mkldnn、Tensorrt等多种参数配置,点击相应链接了解更多细节和使用教程:
[
test_python使用
](
docs/test_python.md
)
[
test_cpp使用
](
docs/test_cpp.md
)
[
test_serving使用
](
docs/test_serving.md
)
[
test_lite使用
](
docs/test_lite.md
)
各功能测试中涉及
混合精度、裁剪、量化等训练相关,及
mkldnn、Tensorrt等多种
预测相关
参数配置,
请
点击
下方
相应链接了解更多细节和使用教程:
[
test_
train_inference_
python
使用
](
docs/test_
train_inference_
python.md
)
[
test_
inference_
cpp
使用
](
docs/test_
inference_
cpp.md
)
[
test_serving
使用
](
docs/test_serving.md
)
[
test_lite
使用
](
docs/test_lite.md
)
tests
/results/ppocr_det_mobile_results_fp16
_cpp
.txt
→
PTDN
/results/
cpp_
ppocr_det_mobile_results_fp16.txt
View file @
025692aa
File moved
tests
/results/ppocr_det_mobile_results_fp32
_cpp
.txt
→
PTDN
/results/
cpp_
ppocr_det_mobile_results_fp32.txt
View file @
025692aa
File moved
tests
/results/ppocr_det_mobile_results_fp16.txt
→
PTDN
/results/
python_
ppocr_det_mobile_results_fp16.txt
View file @
025692aa
File moved
tests
/results/ppocr_det_mobile_results_fp32.txt
→
PTDN
/results/
python_
ppocr_det_mobile_results_fp32.txt
View file @
025692aa
File moved
tests/test
_cpp.sh
→
PTDN/test_inference
_cpp.sh
View file @
025692aa
...
...
@@ -56,7 +56,11 @@ function func_cpp_inference(){
fi
for
threads
in
${
cpp_cpu_threads_list
[*]
}
;
do
for
batch_size
in
${
cpp_batch_size_list
[*]
}
;
do
_save_log_path
=
"
${
_log_path
}
/cpp_infer_cpu_usemkldnn_
${
use_mkldnn
}
_threads_
${
threads
}
_batchsize_
${
batch_size
}
.log"
precision
=
"fp32"
if
[
${
use_mkldnn
}
=
"False"
]
&&
[
${
_flag_quant
}
=
"True"
]
;
then
precison
=
"int8"
fi
_save_log_path
=
"
${
_log_path
}
/cpp_infer_cpu_usemkldnn_
${
use_mkldnn
}
_threads_
${
threads
}
_precision_
${
precision
}
_batchsize_
${
batch_size
}
.log"
set_infer_data
=
$(
func_set_params
"
${
cpp_image_dir_key
}
"
"
${
_img_dir
}
"
)
set_benchmark
=
$(
func_set_params
"
${
cpp_benchmark_key
}
"
"
${
cpp_benchmark_value
}
"
)
set_batchsize
=
$(
func_set_params
"
${
cpp_batch_size_key
}
"
"
${
batch_size
}
"
)
...
...
tests
/test_serving.sh
→
PTDN
/test_serving.sh
View file @
025692aa
...
...
@@ -2,44 +2,44 @@
source
tests/common_func.sh
FILENAME
=
$1
dataline
=
$(
awk
'NR==67, NR==8
1
{print}'
$FILENAME
)
dataline
=
$(
awk
'NR==67, NR==8
3
{print}'
$FILENAME
)
# parser params
IFS
=
$'
\n
'
lines
=(
${
dataline
}
)
# parser serving
trans_model_py
=
$(
func_parser_value
"
${
lines
[1]
}
"
)
infer_model_dir_key
=
$(
func_parser_key
"
${
lines
[2]
}
"
)
infer_model_dir_value
=
$(
func_parser_value
"
${
lines
[2]
}
"
)
model_filename_key
=
$(
func_parser_key
"
${
lines
[3]
}
"
)
model_filename_value
=
$(
func_parser_value
"
${
lines
[3]
}
"
)
params_filename_key
=
$(
func_parser_key
"
${
lines
[4]
}
"
)
params_filename_value
=
$(
func_parser_value
"
${
lines
[4]
}
"
)
serving_server_key
=
$(
func_parser_key
"
${
lines
[5]
}
"
)
serving_server_value
=
$(
func_parser_value
"
${
lines
[5]
}
"
)
serving_client_key
=
$(
func_parser_key
"
${
lines
[6]
}
"
)
serving_client_value
=
$(
func_parser_value
"
${
lines
[6]
}
"
)
serving_dir_value
=
$(
func_parser_value
"
${
lines
[7]
}
"
)
web_service_py
=
$(
func_parser_value
"
${
lines
[8]
}
"
)
web_use_gpu_key
=
$(
func_parser_key
"
${
lines
[9]
}
"
)
web_use_gpu_list
=
$(
func_parser_value
"
${
lines
[9]
}
"
)
web_use_mkldnn_key
=
$(
func_parser_key
"
${
lines
[10]
}
"
)
web_use_mkldnn_list
=
$(
func_parser_value
"
${
lines
[10]
}
"
)
web_cpu_threads_key
=
$(
func_parser_key
"
${
lines
[11]
}
"
)
web_cpu_threads_list
=
$(
func_parser_value
"
${
lines
[11]
}
"
)
web_use_trt_key
=
$(
func_parser_key
"
${
lines
[12]
}
"
)
web_use_trt_list
=
$(
func_parser_value
"
${
lines
[12]
}
"
)
web_precision_key
=
$(
func_parser_key
"
${
lines
[13]
}
"
)
web_precision_list
=
$(
func_parser_value
"
${
lines
[13]
}
"
)
pipeline_py
=
$(
func_parser_value
"
${
lines
[14]
}
"
)
model_name
=
$(
func_parser_value
"
${
lines
[1]
}
"
)
python
=
$(
func_parser_value
"
${
lines
[2]
}
"
)
trans_model_py
=
$(
func_parser_value
"
${
lines
[3]
}
"
)
infer_model_dir_key
=
$(
func_parser_key
"
${
lines
[4]
}
"
)
infer_model_dir_value
=
$(
func_parser_value
"
${
lines
[4]
}
"
)
model_filename_key
=
$(
func_parser_key
"
${
lines
[5]
}
"
)
model_filename_value
=
$(
func_parser_value
"
${
lines
[5]
}
"
)
params_filename_key
=
$(
func_parser_key
"
${
lines
[6]
}
"
)
params_filename_value
=
$(
func_parser_value
"
${
lines
[6]
}
"
)
serving_server_key
=
$(
func_parser_key
"
${
lines
[7]
}
"
)
serving_server_value
=
$(
func_parser_value
"
${
lines
[7]
}
"
)
serving_client_key
=
$(
func_parser_key
"
${
lines
[8]
}
"
)
serving_client_value
=
$(
func_parser_value
"
${
lines
[8]
}
"
)
serving_dir_value
=
$(
func_parser_value
"
${
lines
[9]
}
"
)
web_service_py
=
$(
func_parser_value
"
${
lines
[10]
}
"
)
web_use_gpu_key
=
$(
func_parser_key
"
${
lines
[11]
}
"
)
web_use_gpu_list
=
$(
func_parser_value
"
${
lines
[11]
}
"
)
web_use_mkldnn_key
=
$(
func_parser_key
"
${
lines
[12]
}
"
)
web_use_mkldnn_list
=
$(
func_parser_value
"
${
lines
[12]
}
"
)
web_cpu_threads_key
=
$(
func_parser_key
"
${
lines
[13]
}
"
)
web_cpu_threads_list
=
$(
func_parser_value
"
${
lines
[13]
}
"
)
web_use_trt_key
=
$(
func_parser_key
"
${
lines
[14]
}
"
)
web_use_trt_list
=
$(
func_parser_value
"
${
lines
[14]
}
"
)
web_precision_key
=
$(
func_parser_key
"
${
lines
[15]
}
"
)
web_precision_list
=
$(
func_parser_value
"
${
lines
[15]
}
"
)
pipeline_py
=
$(
func_parser_value
"
${
lines
[16]
}
"
)
LOG_PATH
=
"./tests/output"
mkdir
-p
${
LOG_PATH
}
LOG_PATH
=
"../../tests/output"
mkdir
-p
./tests/output
status_log
=
"
${
LOG_PATH
}
/results_serving.log"
function
func_serving
(){
IFS
=
'|'
_python
=
$1
...
...
@@ -65,12 +65,12 @@ function func_serving(){
continue
fi
for
threads
in
${
web_cpu_threads_list
[*]
}
;
do
_save_log_path
=
"
${
_log_path
}
/serv
er_cpu_usemkldnn_
${
use_mkldnn
}
_threads_
${
threads
}
_batchsize_1.log"
_save_log_path
=
"
${
LOG_PATH
}
/server_inf
er_cpu_usemkldnn_
${
use_mkldnn
}
_threads_
${
threads
}
_batchsize_1.log"
set_cpu_threads
=
$(
func_set_params
"
${
web_cpu_threads_key
}
"
"
${
threads
}
"
)
web_service_cmd
=
"
${
python
}
${
web_service_py
}
${
web_use_gpu_key
}
=
${
use_gpu
}
${
web_use_mkldnn_key
}
=
${
use_mkldnn
}
${
set_cpu_threads
}
&>
${
_save_log_path
}
&"
web_service_cmd
=
"
${
python
}
${
web_service_py
}
${
web_use_gpu_key
}
=
${
use_gpu
}
${
web_use_mkldnn_key
}
=
${
use_mkldnn
}
${
set_cpu_threads
}
&"
eval
$web_service_cmd
sleep
2s
pipeline_cmd
=
"
${
python
}
${
pipeline_py
}
"
pipeline_cmd
=
"
${
python
}
${
pipeline_py
}
>
${
_save_log_path
}
2>&1
"
eval
$pipeline_cmd
last_status
=
${
PIPESTATUS
[0]
}
eval
"cat
${
_save_log_path
}
"
...
...
@@ -93,13 +93,13 @@ function func_serving(){
if
[[
${
use_trt
}
=
"False"
||
${
precision
}
=
~
"int8"
]]
&&
[[
${
_flag_quant
}
=
"True"
]]
;
then
continue
fi
_save_log_path
=
"
${
_log_path
}
/
infer_gpu_usetrt_
${
use_trt
}
_precision_
${
precision
}
_batchsize_1.log"
_save_log_path
=
"
${
LOG_PATH
}
/server_
infer_gpu_usetrt_
${
use_trt
}
_precision_
${
precision
}
_batchsize_1.log"
set_tensorrt
=
$(
func_set_params
"
${
web_use_trt_key
}
"
"
${
use_trt
}
"
)
set_precision
=
$(
func_set_params
"
${
web_precision_key
}
"
"
${
precision
}
"
)
web_service_cmd
=
"
${
python
}
${
web_service_py
}
${
web_use_gpu_key
}
=
${
use_gpu
}
${
set_tensorrt
}
${
set_precision
}
&>
${
_save_log_path
}
& "
web_service_cmd
=
"
${
python
}
${
web_service_py
}
${
web_use_gpu_key
}
=
${
use_gpu
}
${
set_tensorrt
}
${
set_precision
}
& "
eval
$web_service_cmd
sleep
2s
pipeline_cmd
=
"
${
python
}
${
pipeline_py
}
"
pipeline_cmd
=
"
${
python
}
${
pipeline_py
}
>
${
_save_log_path
}
2>&1
"
eval
$pipeline_cmd
last_status
=
${
PIPESTATUS
[0]
}
eval
"cat
${
_save_log_path
}
"
...
...
@@ -129,3 +129,7 @@ eval $env
echo
"################### run test ###################"
export
Count
=
0
IFS
=
"|"
func_serving
"
${
web_service_cmd
}
"
tests/test
_python.sh
→
PTDN/test_train_inference
_python.sh
View file @
025692aa
...
...
@@ -5,11 +5,7 @@ FILENAME=$1
# MODE be one of ['lite_train_infer' 'whole_infer' 'whole_train_infer', 'infer', 'klquant_infer']
MODE
=
$2
if
[
${
MODE
}
=
"klquant_infer"
]
;
then
dataline
=
$(
awk
'NR==82, NR==98{print}'
$FILENAME
)
else
dataline
=
$(
awk
'NR==1, NR==51{print}'
$FILENAME
)
fi
dataline
=
$(
awk
'NR==1, NR==51{print}'
$FILENAME
)
# parser params
IFS
=
$'
\n
'
...
...
@@ -93,6 +89,8 @@ infer_value1=$(func_parser_value "${lines[50]}")
# parser klquant_infer
if
[
${
MODE
}
=
"klquant_infer"
]
;
then
dataline
=
$(
awk
'NR==82, NR==98{print}'
$FILENAME
)
lines
=(
${
dataline
}
)
# parser inference model
infer_model_dir_list
=
$(
func_parser_value
"
${
lines
[1]
}
"
)
infer_export_list
=
$(
func_parser_value
"
${
lines
[2]
}
"
)
...
...
@@ -143,7 +141,11 @@ function func_inference(){
fi
for
threads
in
${
cpu_threads_list
[*]
}
;
do
for
batch_size
in
${
batch_size_list
[*]
}
;
do
_save_log_path
=
"
${
_log_path
}
/python_infer_cpu_usemkldnn_
${
use_mkldnn
}
_threads_
${
threads
}
_batchsize_
${
batch_size
}
.log"
precison
=
"fp32"
if
[
${
use_mkldnn
}
=
"False"
]
&&
[
${
_flag_quant
}
=
"True"
]
;
then
precision
=
"int8"
fi
_save_log_path
=
"
${
_log_path
}
/python_infer_cpu_usemkldnn_
${
use_mkldnn
}
_threads_
${
threads
}
_precision_
${
precision
}
_batchsize_
${
batch_size
}
.log"
set_infer_data
=
$(
func_set_params
"
${
image_dir_key
}
"
"
${
_img_dir
}
"
)
set_benchmark
=
$(
func_set_params
"
${
benchmark_key
}
"
"
${
benchmark_value
}
"
)
set_batchsize
=
$(
func_set_params
"
${
batch_size_key
}
"
"
${
batch_size
}
"
)
...
...
@@ -224,6 +226,9 @@ if [ ${MODE} = "infer" ] || [ ${MODE} = "klquant_infer" ]; then
fi
#run inference
is_quant
=
${
infer_quant_flag
[Count]
}
if
[
${
MODE
}
=
"klquant_infer"
]
;
then
is_quant
=
"True"
fi
func_inference
"
${
python
}
"
"
${
inference_py
}
"
"
${
save_infer_dir
}
"
"
${
LOG_PATH
}
"
"
${
infer_img_dir
}
"
${
is_quant
}
Count
=
$((
$Count
+
1
))
done
...
...
doc/doc_ch/enhanced_ctc_loss.md
View file @
025692aa
...
...
@@ -16,7 +16,7 @@ Focal Loss 出自论文《Focal Loss for Dense Object Detection》, 该loss最
从上图可以看到, 当
γ
> 0时,调整系数(1-y’)^
γ
赋予易分类样本损失一个更小的权重,使得网络更关注于困难的、错分的样本。 调整因子
γ
用于调节简单样本权重降低的速率,当
γ
为0时即为交叉熵损失函数,当
γ
增加时,调整因子的影响也会随之增大。实验发现
γ
为2是最优。平衡因子
α
用来平衡正负样本本身的比例不均,文中
α
取0.25。
对于经典的CTC算法,假设某个特征序列(f
<sub>
1
</sub>
, f
<sub>
2
</sub>
, ......f
<sub>
t
</sub>
), 经过CTC解码之后结果等于label的概率为y’, 则CTC解码结果不为label的概率即为(1-y’);不难发现 CTCLoss值和y’有如下关系:
对于经典的CTC算法,假设某个特征序列(f
<sub>
1
</sub>
, f
<sub>
2
</sub>
, ......f
<sub>
t
</sub>
), 经过CTC解码之后结果等于label的概率为y’, 则CTC解码结果不为label的概率即为(1-y’);不难发现
,
CTCLoss值和y’有如下关系:
<div
align=
"center"
>
<img
src=
"./equation_ctcloss.png"
width =
"250"
/>
</div>
...
...
@@ -38,7 +38,7 @@ A-CTC Loss是CTC Loss + ACE Loss的简称。 其中ACE Loss出自论文< Aggrega
<img
src=
"./rec_algo_compare.png"
width =
"1000"
/>
</div>
虽然ACELoss确实如上图所说,可以处理2D预测,在内存占用及推理速度方面具备优势,但在实践过程中,我们发现单独使用ACE Loss, 识别效果并不如CTCLoss. 因此,我们尝试将CTCLoss和ACELoss进行
组
合,同时以CTCLoss为主,将ACELoss 定位为一个辅助监督loss。 这一尝试收到了效果,在我们内部的实验数据集上,相比单独使用CTCLoss,识别准确率可以提升1%左右。
虽然ACELoss确实如上图所说,可以处理2D预测,在内存占用及推理速度方面具备优势,但在实践过程中,我们发现单独使用ACE Loss, 识别效果并不如CTCLoss. 因此,我们尝试将CTCLoss和ACELoss进行
结
合,同时以CTCLoss为主,将ACELoss 定位为一个辅助监督loss。 这一尝试收到了效果,在我们内部的实验数据集上,相比单独使用CTCLoss,识别准确率可以提升1%左右。
A_CTC Loss定义如下:
<div
align=
"center"
>
<img
src=
"./equation_a_ctc.png"
width =
"300"
/>
...
...
@@ -47,7 +47,7 @@ A_CTC Loss定义如下:
实验中,λ = 0.1. ACE loss实现代码见:
[
ace_loss.py
](
../../ppocr/losses/ace_loss.py
)
## 3. C-CTC Loss
C-CTC Loss是CTC Loss + Center Loss的简称。 其中Center Loss出自论文
<
A
Discriminative
Feature
Learning
Approach
for
Deep
Face
Recognition
>
. 最早用于人脸识别任务,用于增大
累
间距离,减小类内距离, 是Metric Learning领域一种较早的、也比较常用的一种算法。
C-CTC Loss是CTC Loss + Center Loss的简称。 其中Center Loss出自论文
<
A
Discriminative
Feature
Learning
Approach
for
Deep
Face
Recognition
>
. 最早用于人脸识别任务,用于增大
类
间距离,减小类内距离, 是Metric Learning领域一种较早的、也比较常用的一种算法。
在中文OCR识别任务中,通过对badcase分析, 我们发现中文识别的一大难点是相似字符多,容易误识。 由此我们想到是否可以借鉴Metric Learing的想法, 增大相似字符的类间距,从而提高识别准确率。然而,MetricLearning主要用于图像识别领域,训练数据的标签为一个固定的值;而对于OCR识别来说,其本质上是一个序列识别任务,特征和label之间并不具有显式的对齐关系,因此两者如何结合依然是一个值得探索的方向。
通过尝试Arcmargin, Cosmargin等方法, 我们最终发现Centerloss 有助于进一步提升识别的准确率。C_CTC Loss定义如下:
<div
align=
"center"
>
...
...
ppocr/losses/ace_loss.py
View file @
025692aa
...
...
@@ -32,6 +32,7 @@ class ACELoss(nn.Layer):
def
__call__
(
self
,
predicts
,
batch
):
if
isinstance
(
predicts
,
(
list
,
tuple
)):
predicts
=
predicts
[
-
1
]
B
,
N
=
predicts
.
shape
[:
2
]
div
=
paddle
.
to_tensor
([
N
]).
astype
(
'float32'
)
...
...
@@ -42,9 +43,7 @@ class ACELoss(nn.Layer):
length
=
batch
[
2
].
astype
(
"float32"
)
batch
=
batch
[
3
].
astype
(
"float32"
)
batch
[:,
0
]
=
paddle
.
subtract
(
div
,
length
)
batch
=
paddle
.
divide
(
batch
,
div
)
loss
=
self
.
loss_func
(
aggregation_preds
,
batch
)
return
{
"loss_ace"
:
loss
}
ppocr/losses/center_loss.py
View file @
025692aa
...
...
@@ -27,7 +27,6 @@ class CenterLoss(nn.Layer):
"""
Reference: Wen et al. A Discriminative Feature Learning Approach for Deep Face Recognition. ECCV 2016.
"""
def
__init__
(
self
,
num_classes
=
6625
,
feat_dim
=
96
,
...
...
@@ -37,8 +36,7 @@ class CenterLoss(nn.Layer):
self
.
num_classes
=
num_classes
self
.
feat_dim
=
feat_dim
self
.
centers
=
paddle
.
randn
(
shape
=
[
self
.
num_classes
,
self
.
feat_dim
]).
astype
(
"float64"
)
#random center
shape
=
[
self
.
num_classes
,
self
.
feat_dim
]).
astype
(
"float64"
)
if
init_center
:
assert
os
.
path
.
exists
(
...
...
@@ -60,22 +58,23 @@ class CenterLoss(nn.Layer):
batch_size
=
feats_reshape
.
shape
[
0
]
#calc feat * feat
dist1
=
paddle
.
sum
(
paddle
.
square
(
feats_reshape
),
axis
=
1
,
keepdim
=
True
)
dist1
=
paddle
.
expand
(
dist1
,
[
batch_size
,
self
.
num_classes
])
#calc l2 distance between feats and centers
square_feat
=
paddle
.
sum
(
paddle
.
square
(
feats_reshape
),
axis
=
1
,
keepdim
=
True
)
square_feat
=
paddle
.
expand
(
square_feat
,
[
batch_size
,
self
.
num_classes
])
#dist2 of
centers
dist2
=
paddle
.
sum
(
paddle
.
square
(
self
.
centers
),
axis
=
1
,
keepdim
=
True
)
#num_classes
dist2
=
paddle
.
expand
(
dist2
,
[
self
.
num_classes
,
batch_size
]).
astype
(
"float64"
)
dist2
=
paddle
.
transpose
(
dist2
,
[
1
,
0
])
square_center
=
paddle
.
sum
(
paddle
.
square
(
self
.
centers
),
axis
=
1
,
keepdim
=
True
)
square_center
=
paddle
.
expand
(
square_center
,
[
self
.
num_classes
,
batch_size
]).
astype
(
"float64"
)
square_center
=
paddle
.
transpose
(
square_center
,
[
1
,
0
])
#first x * x + y * y
distmat
=
paddle
.
add
(
dist1
,
dist2
)
tmp
=
paddle
.
matmul
(
feats_reshape
,
paddle
.
transpose
(
self
.
centers
,
[
1
,
0
]))
distmat
=
distmat
-
2.0
*
tmp
distmat
=
paddle
.
add
(
square_feat
,
square_center
)
feat_dot_center
=
paddle
.
matmul
(
feats_reshape
,
paddle
.
transpose
(
self
.
centers
,
[
1
,
0
]))
distmat
=
distmat
-
2.0
*
feat_dot_center
#generate the mask
classes
=
paddle
.
arange
(
self
.
num_classes
).
astype
(
"int64"
)
...
...
@@ -83,7 +82,8 @@ class CenterLoss(nn.Layer):
paddle
.
unsqueeze
(
label
,
1
),
(
batch_size
,
self
.
num_classes
))
mask
=
paddle
.
equal
(
paddle
.
expand
(
classes
,
[
batch_size
,
self
.
num_classes
]),
label
).
astype
(
"float64"
)
#get mask
label
).
astype
(
"float64"
)
dist
=
paddle
.
multiply
(
distmat
,
mask
)
loss
=
paddle
.
sum
(
paddle
.
clip
(
dist
,
min
=
1e-12
,
max
=
1e+12
))
/
batch_size
return
{
'loss_center'
:
loss
}
tests/docs/test.png
deleted
100644 → 0
View file @
82f19a31
71.8 KB
Prev
1
2
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}