
fix: rewrite projects/ and demos with new data api
Showing
{kind=link}
60.6 KB
{kind=link}
124 KB
{kind=link}
171 KB
{kind=link}
83.7 KB
{kind=link}
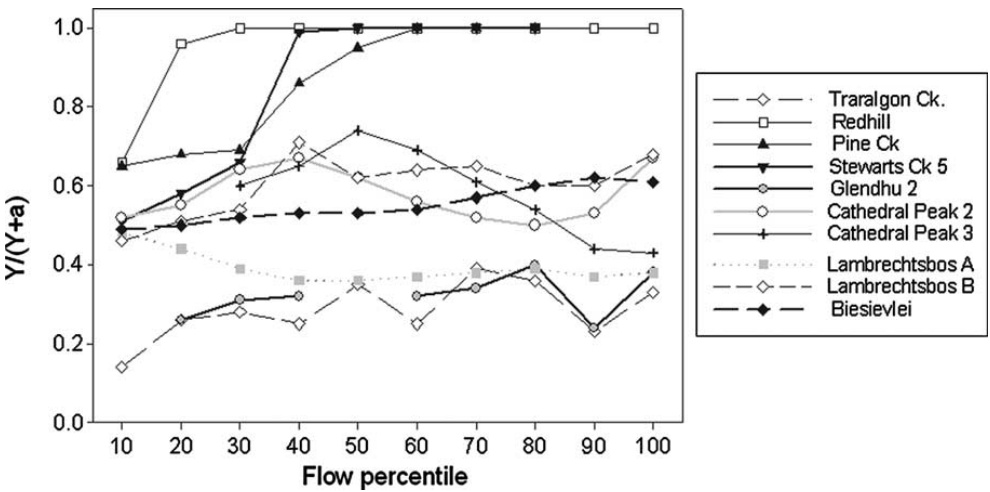
82.9 KB
{kind=link}
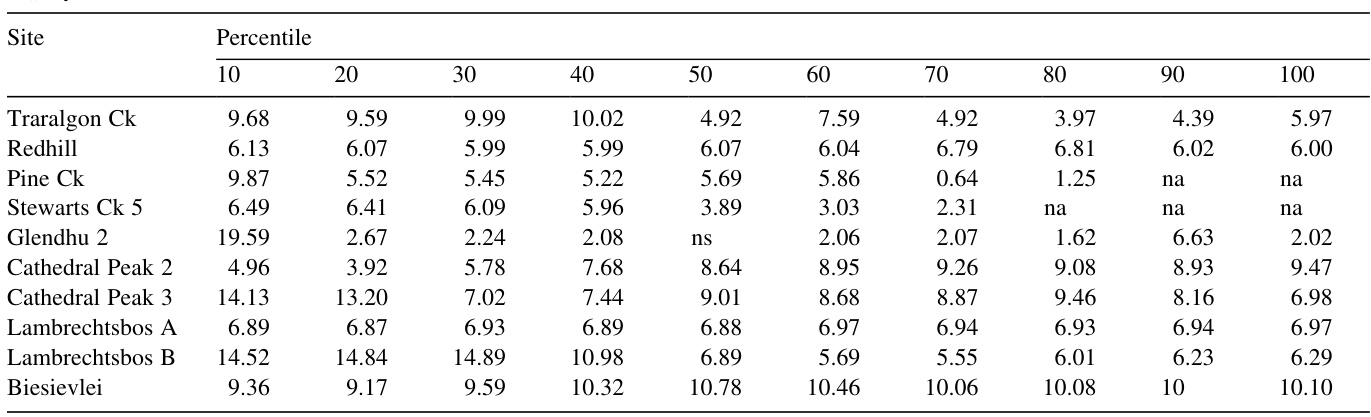
121 KB
{kind=link}
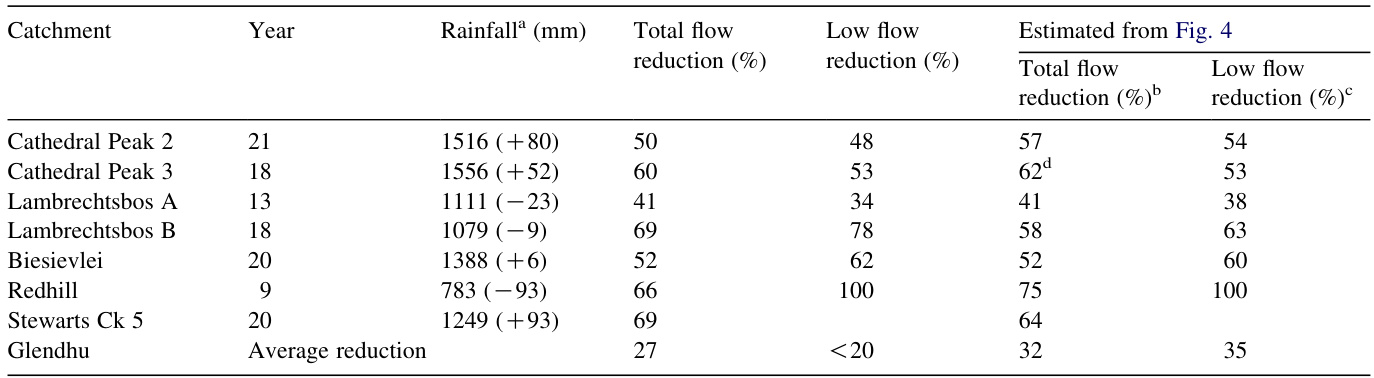
89.6 KB
magic_pdf/model/types.py
0 → 100644
60.6 KB
124 KB
171 KB
83.7 KB
82.9 KB
121 KB
89.6 KB