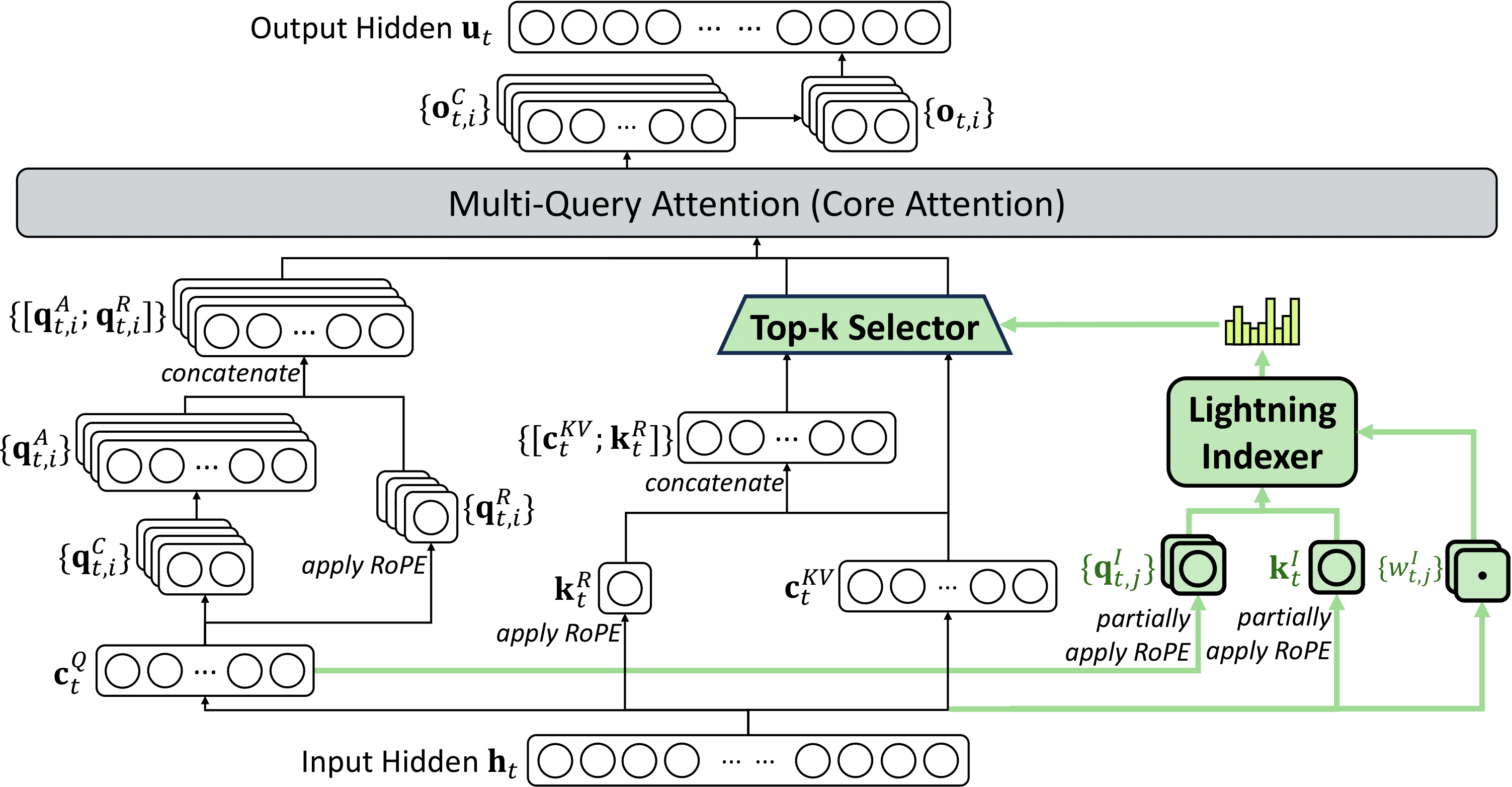
The architecture diagram above highlights three key components (shown in green) that correspond to our kernel implementations:
1.**Lightning Indexer** (`fp8_lighting_indexer.py`) - Efficiently indexes and processes sparse attention patterns using FP8 precision
2.**Top-k Selector** (`topk_selector.py`) - Selects the top-k most relevant tokens for sparse attention computation
3.**Multi-Query Attention** (`sparse_mla_fwd.py`, `sparse_mla_fwd_pipelined.py`, and `sparse_mla_bwd.py`) - Core attention mechanism implementation with sparse MLA (Multi-Latent Attention) forward and backward passes
### Lightning Indexer
Looking at the architecture diagram, the Lightning Indexer sits at the bottom right. It takes the input hidden states and produces compressed representations `{q^A_{t,i}}`, `{k^R_t}`, and `{w^I_{t,j}}`. These FP8-quantized index vectors are what feed into the top-k selector.
The main kernel `mqa_attn_return_logits_kernel` computes similarity scores between query and key indices:
```python
T.gemm(
index_k_shared,
index_q_shared,
s,
transpose_B=True,
clear_accum=True,
policy=T.GemmWarpPolicy.FullCol,
)
```
After the matmul, we apply ReLU and aggregate across heads with learned weights:
The result is a `[seq_len, seq_len_kv]` logits matrix. For long sequences, the kernel uses per-token bounds (`CuSeqLenKS`, `CuSeqLenKE`) to skip irrelevant KV positions:
The pipelined loop then only processes keys in the `[cu_k_s_min, cu_k_e_max)` range, which is crucial for handling variable-length sequences in distributed training.
### Top-k Selector
The Top-k Selector takes the logits matrix from the indexer and picks the top-k indices for each query. In the architecture diagram, this sits between the Lightning Indexer and the Multi-Query Attention block. The output indices tell the attention layer which KV tokens to actually load and process.
The implementation uses a radix-sort-based approach that processes floats as unsigned integers. Stage 1 does a quick 8-bit pass over the whole sequence:
The `convert_to_uint16` function maps floats to uint16 such that larger floats map to larger integers. After building a histogram and doing a cumulative sum, we find the threshold bin:
Stage 2 refines the threshold bin with up to 4 rounds of 8-bit radix sort, processing progressively higher bits. This gives exact top-k selection without sorting the entire sequence.
### Sparse MLA Forward
The Sparse MLA kernel is where the actual attention computation happens. In the architecture diagram, this is the large "Multi-Query Attention (Core Attention)" block at the top. It takes the selected top-k indices and computes attention only over those tokens.
Turning dense MLA into sparse MLA requires surprisingly few changes - essentially just modifying how we iterate and load KV tokens. The key difference from dense MLA (see `../deepseek_mla/example_mla_decode.py`) is the iteration pattern. Dense MLA iterates over all KV positions:
Beyond this sparse indexing, the rest of the attention computation (online softmax, output accumulation) follows the same pattern as dense MLA.
### Sparse MLA Forward (Pipelined)
The pipelined version (`sparse_mla_fwd_pipelined.py`) is a manual pipeline implementation designed to match the schedule of [FlashMLA](https://github.com/deepseek-ai/FlashMLA/blob/main/csrc/sm90/prefill/sparse/fwd.cu). It achieves close to 600 TFlops on H800 SXM by carefully orchestrating memory and compute pipelines.
The key difference is splitting the warp groups into specialized roles:
```python
iftx<128:
# Consumer 0: computes left half of output (D//2 dimensions)
# Handles QK matmul, softmax, and PV for left half
eliftx>=128andtx<256:
# Consumer 1: computes right half of output (D//2 dimensions)
# Only does PV matmul for right half
eliftx>=256:
# Producer: loads KV data from global memory
# Uses async copy with barriers to feed consumers
```
The producer thread group (tx >= 256) uses double buffering with barriers to keep consumers fed:
```python
# Producer alternates between two buffers
fori_iinT.serial(T.ceildiv(NI,2)):
# Buffer 0
T.barrier_wait(bar_k_0_free[0],((i_i&1)^1))
# ... load KV into buffer 0
T.cp_async_barrier_noinc(bar_k_0_ready[0])
# Buffer 1
T.barrier_wait(bar_k_1_free[0],((i_i&1)^1))
# ... load KV into buffer 1
T.cp_async_barrier_noinc(bar_k_1_ready[0])
```
Consumer threads wait on barriers and process buffers as they become ready. This manual orchestration hides memory latency behind compute, which is why it outperforms the simpler auto-pipelined version. The output dimension is also split in half so that the two consumer groups can work in parallel on different parts of the matmul.
### Sparse MLA Backward
The Sparse MLA backward kernel (`sparse_mla_bwd.py`) computes gradients with respect to queries (dQ) and key-values (dKV) for the sparse attention mechanism. Like the forward pass, it processes only the selected top-k indices, maintaining O(seq_len * topk) complexity.
The backward pass consists of three main stages:
**1. Preprocessing**: Computes delta values (row-wise dot products of output and output gradient):
**Performance**: The sparse MLA backward achieves excellent performance:
-**H800 SXM**: ~100 TFlops
-**H200 SXM**: ~115 TFlops
The implementation efficiently handles the irregular memory access patterns inherent in sparse attention while maintaining high compute utilization through careful memory management and atomic update strategies. Note that this is a relatively naive implementation that requires further optimization.
),"here we solve the H padding automatically, other wise you should handle Q copy and Output copy with your mask (when kv_group == 1, use g_i * padded_H:(g_i+1) * padded_H would be handled automatically)"
BI=block_I
NI=tilelang.cdiv(topk,block_I)
D=dim
D_tail=tail_dim
ifhead_kv>64:
asserthead_kv%64==0,"head_kv should be a multiple of 64"
assertkv_group==1,'here we solve the H padding automatically, other wise you should handle Q copy and Output copy with your mask (when kv_group == 1, use g_i * padded_H:(g_i+1) * padded_H would be handled automatically)'
BI=block_I
NI=tilelang.cdiv(topk,block_I)
assertNI%2==0,'NI should be a multiple of 2'
D=dim
D_tail=tail_dim
KV_stride=kv_stride
ifhead_kv>64:
asserthead_kv%64==0,'head_kv should be a multiple of 64'
assertq_start_index_s>kv_stride,"If it is because each cp has too short length, you should fix the logic involving CP0 (cp_rank == 0), to make sure q with pos < KV_Stride - 1 is masked (or you may just ignore how this is handled if nan in these q's Out would not effect others, which is reported to be likely to happen by wangding)"

{kind=link}