Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
wangkx1
tilelang
Commits
bc2d5632
Commit
bc2d5632
authored
Jan 15, 2026
by
root
Browse files
init
parents
Pipeline
#3222
failed with stages
in 0 seconds
Changes
257
Pipelines
1
Hide whitespace changes
Inline
Side-by-side
Showing
20 changed files
with
6015 additions
and
0 deletions
+6015
-0
examples/deepseek_mla/amd/benchmark_mla_decode_amd_torch.py
examples/deepseek_mla/amd/benchmark_mla_decode_amd_torch.py
+495
-0
examples/deepseek_mla/amd/benchmark_mla_decode_amd_triton.py
examples/deepseek_mla/amd/benchmark_mla_decode_amd_triton.py
+492
-0
examples/deepseek_mla/benchmark_mla.py
examples/deepseek_mla/benchmark_mla.py
+624
-0
examples/deepseek_mla/example_mla_decode.py
examples/deepseek_mla/example_mla_decode.py
+318
-0
examples/deepseek_mla/example_mla_decode_paged.py
examples/deepseek_mla/example_mla_decode_paged.py
+404
-0
examples/deepseek_mla/example_mla_decode_persistent.py
examples/deepseek_mla/example_mla_decode_persistent.py
+223
-0
examples/deepseek_mla/example_mla_decode_ws.py
examples/deepseek_mla/example_mla_decode_ws.py
+617
-0
examples/deepseek_mla/experimental/example_mla_decode_kv_fp8.py
...es/deepseek_mla/experimental/example_mla_decode_kv_fp8.py
+157
-0
examples/deepseek_mla/figures/bs128_float16.png
examples/deepseek_mla/figures/bs128_float16.png
+0
-0
examples/deepseek_mla/figures/bs64_float16.png
examples/deepseek_mla/figures/bs64_float16.png
+0
-0
examples/deepseek_mla/figures/flashmla-amd.png
examples/deepseek_mla/figures/flashmla-amd.png
+0
-0
examples/deepseek_mla/figures/pv_layout.jpg
examples/deepseek_mla/figures/pv_layout.jpg
+0
-0
examples/deepseek_mla/figures/qk_layout.jpg
examples/deepseek_mla/figures/qk_layout.jpg
+0
-0
examples/deepseek_mla/test_example_mla_decode.py
examples/deepseek_mla/test_example_mla_decode.py
+13
-0
examples/deepseek_mla/torch_refs.py
examples/deepseek_mla/torch_refs.py
+78
-0
examples/deepseek_nsa/benchmark/benchmark_nsa_fwd.py
examples/deepseek_nsa/benchmark/benchmark_nsa_fwd.py
+996
-0
examples/deepseek_nsa/example_tilelang_nsa_bwd.py
examples/deepseek_nsa/example_tilelang_nsa_bwd.py
+859
-0
examples/deepseek_nsa/example_tilelang_nsa_decode.py
examples/deepseek_nsa/example_tilelang_nsa_decode.py
+182
-0
examples/deepseek_nsa/example_tilelang_nsa_fwd.py
examples/deepseek_nsa/example_tilelang_nsa_fwd.py
+187
-0
examples/deepseek_nsa/example_tilelang_nsa_fwd_varlen.py
examples/deepseek_nsa/example_tilelang_nsa_fwd_varlen.py
+370
-0
No files found.
Too many changes to show.
To preserve performance only
257 of 257+
files are displayed.
Plain diff
Email patch
examples/deepseek_mla/amd/benchmark_mla_decode_amd_torch.py
0 → 100644
View file @
bc2d5632
# This benchmark script is modified based on: https://github.com/deepseek-ai/FlashMLA/blob/main/benchmark/bench_flash_mla.py
# ruff: noqa
import
argparse
import
math
import
random
import
torch
import
triton
import
triton.language
as
tl
import
tilelang
from
tilelang.profiler
import
do_bench
def
scaled_dot_product_attention
(
query
,
key
,
value
,
h_q
,
h_kv
,
is_causal
=
False
):
query
=
query
.
float
()
key
=
key
.
float
()
value
=
value
.
float
()
key
=
key
.
repeat_interleave
(
h_q
//
h_kv
,
dim
=
0
)
value
=
value
.
repeat_interleave
(
h_q
//
h_kv
,
dim
=
0
)
attn_weight
=
query
@
key
.
transpose
(
-
2
,
-
1
)
/
math
.
sqrt
(
query
.
size
(
-
1
))
if
is_causal
:
s_q
=
query
.
shape
[
-
2
]
s_k
=
key
.
shape
[
-
2
]
attn_bias
=
torch
.
zeros
(
s_q
,
s_k
,
dtype
=
query
.
dtype
)
temp_mask
=
torch
.
ones
(
s_q
,
s_k
,
dtype
=
torch
.
bool
).
tril
(
diagonal
=
s_k
-
s_q
)
attn_bias
.
masked_fill_
(
temp_mask
.
logical_not
(),
float
(
"-inf"
))
attn_bias
.
to
(
query
.
dtype
)
attn_weight
+=
attn_bias
lse
=
attn_weight
.
logsumexp
(
dim
=-
1
)
attn_weight
=
torch
.
softmax
(
attn_weight
,
dim
=-
1
,
dtype
=
torch
.
float32
)
return
attn_weight
@
value
,
lse
@
torch
.
inference_mode
()
def
run_torch_mla
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
):
blocked_v
=
blocked_k
[...,
:
dv
]
def
ref_mla
():
out
=
torch
.
empty
(
b
,
s_q
,
h_q
,
dv
,
dtype
=
torch
.
float32
)
lse
=
torch
.
empty
(
b
,
h_q
,
s_q
,
dtype
=
torch
.
float32
)
for
i
in
range
(
b
):
begin
=
i
*
max_seqlen_pad
end
=
begin
+
cache_seqlens
[
i
]
O
,
LSE
=
scaled_dot_product_attention
(
q
[
i
].
transpose
(
0
,
1
),
blocked_k
.
view
(
-
1
,
h_kv
,
d
)[
begin
:
end
].
transpose
(
0
,
1
),
blocked_v
.
view
(
-
1
,
h_kv
,
dv
)[
begin
:
end
].
transpose
(
0
,
1
),
h_q
,
h_kv
,
is_causal
=
causal
,
)
out
[
i
]
=
O
.
transpose
(
0
,
1
)
lse
[
i
]
=
LSE
return
out
,
lse
out_torch
,
lse_torch
=
ref_mla
()
t
=
triton
.
testing
.
do_bench
(
ref_mla
)
return
out_torch
,
lse_torch
,
t
@
triton
.
jit
def
_mla_attn_kernel
(
Q_nope
,
Q_pe
,
Kv_c_cache
,
K_pe_cache
,
Req_to_tokens
,
B_seq_len
,
O
,
sm_scale
,
stride_q_nope_bs
,
stride_q_nope_h
,
stride_q_pe_bs
,
stride_q_pe_h
,
stride_kv_c_bs
,
stride_k_pe_bs
,
stride_req_to_tokens_bs
,
stride_o_b
,
stride_o_h
,
stride_o_s
,
BLOCK_H
:
tl
.
constexpr
,
BLOCK_N
:
tl
.
constexpr
,
NUM_KV_SPLITS
:
tl
.
constexpr
,
PAGE_SIZE
:
tl
.
constexpr
,
HEAD_DIM_CKV
:
tl
.
constexpr
,
HEAD_DIM_KPE
:
tl
.
constexpr
,
):
cur_batch
=
tl
.
program_id
(
1
)
cur_head_id
=
tl
.
program_id
(
0
)
split_kv_id
=
tl
.
program_id
(
2
)
cur_batch_seq_len
=
tl
.
load
(
B_seq_len
+
cur_batch
)
offs_d_ckv
=
tl
.
arange
(
0
,
HEAD_DIM_CKV
)
cur_head
=
cur_head_id
*
BLOCK_H
+
tl
.
arange
(
0
,
BLOCK_H
)
offs_q_nope
=
cur_batch
*
stride_q_nope_bs
+
cur_head
[:,
None
]
*
stride_q_nope_h
+
offs_d_ckv
[
None
,
:]
q_nope
=
tl
.
load
(
Q_nope
+
offs_q_nope
)
offs_d_kpe
=
tl
.
arange
(
0
,
HEAD_DIM_KPE
)
offs_q_pe
=
cur_batch
*
stride_q_pe_bs
+
cur_head
[:,
None
]
*
stride_q_pe_h
+
offs_d_kpe
[
None
,
:]
q_pe
=
tl
.
load
(
Q_pe
+
offs_q_pe
)
e_max
=
tl
.
zeros
([
BLOCK_H
],
dtype
=
tl
.
float32
)
-
float
(
"inf"
)
e_sum
=
tl
.
zeros
([
BLOCK_H
],
dtype
=
tl
.
float32
)
acc
=
tl
.
zeros
([
BLOCK_H
,
HEAD_DIM_CKV
],
dtype
=
tl
.
float32
)
kv_len_per_split
=
tl
.
cdiv
(
cur_batch_seq_len
,
NUM_KV_SPLITS
)
split_kv_start
=
kv_len_per_split
*
split_kv_id
split_kv_end
=
tl
.
minimum
(
split_kv_start
+
kv_len_per_split
,
cur_batch_seq_len
)
for
start_n
in
range
(
split_kv_start
,
split_kv_end
,
BLOCK_N
):
offs_n
=
start_n
+
tl
.
arange
(
0
,
BLOCK_N
)
kv_page_number
=
tl
.
load
(
Req_to_tokens
+
stride_req_to_tokens_bs
*
cur_batch
+
offs_n
//
PAGE_SIZE
,
mask
=
offs_n
<
split_kv_end
,
other
=
0
,
)
kv_loc
=
kv_page_number
*
PAGE_SIZE
+
offs_n
%
PAGE_SIZE
offs_k_c
=
kv_loc
[
None
,
:]
*
stride_kv_c_bs
+
offs_d_ckv
[:,
None
]
k_c
=
tl
.
load
(
Kv_c_cache
+
offs_k_c
,
mask
=
offs_n
[
None
,
:]
<
split_kv_end
,
other
=
0.0
)
qk
=
tl
.
dot
(
q_nope
,
k_c
.
to
(
q_nope
.
dtype
))
offs_k_pe
=
kv_loc
[
None
,
:]
*
stride_k_pe_bs
+
offs_d_kpe
[:,
None
]
k_pe
=
tl
.
load
(
K_pe_cache
+
offs_k_pe
,
mask
=
offs_n
[
None
,
:]
<
split_kv_end
,
other
=
0.0
)
qk
+=
tl
.
dot
(
q_pe
,
k_pe
.
to
(
q_pe
.
dtype
))
qk
*=
sm_scale
qk
=
tl
.
where
(
offs_n
[
None
,
:]
<
split_kv_end
,
qk
,
float
(
"-inf"
))
v_c
=
tl
.
trans
(
k_c
)
n_e_max
=
tl
.
maximum
(
tl
.
max
(
qk
,
1
),
e_max
)
re_scale
=
tl
.
exp
(
e_max
-
n_e_max
)
p
=
tl
.
exp
(
qk
-
n_e_max
[:,
None
])
acc
*=
re_scale
[:,
None
]
acc
+=
tl
.
dot
(
p
.
to
(
v_c
.
dtype
),
v_c
)
e_sum
=
e_sum
*
re_scale
+
tl
.
sum
(
p
,
1
)
e_max
=
n_e_max
offs_o
=
cur_batch
*
stride_o_b
+
cur_head
[:,
None
]
*
stride_o_h
+
split_kv_id
*
stride_o_s
+
offs_d_ckv
[
None
,
:]
tl
.
store
(
O
+
offs_o
,
acc
/
e_sum
[:,
None
])
offs_o_1
=
cur_batch
*
stride_o_b
+
cur_head
*
stride_o_h
+
split_kv_id
*
stride_o_s
+
HEAD_DIM_CKV
tl
.
store
(
O
+
offs_o_1
,
e_max
+
tl
.
log
(
e_sum
))
def
_mla_attn
(
q_nope
,
q_pe
,
kv_c_cache
,
k_pe_cache
,
attn_logits
,
req_to_tokens
,
b_seq_len
,
num_kv_splits
,
sm_scale
,
page_size
,
):
batch_size
,
head_num
=
q_nope
.
shape
[
0
],
q_nope
.
shape
[
1
]
head_dim_ckv
=
q_nope
.
shape
[
-
1
]
head_dim_kpe
=
q_pe
.
shape
[
-
1
]
BLOCK_H
=
16
BLOCK_N
=
64
grid
=
(
triton
.
cdiv
(
head_num
,
BLOCK_H
),
batch_size
,
num_kv_splits
,
)
_mla_attn_kernel
[
grid
](
q_nope
,
q_pe
,
kv_c_cache
,
k_pe_cache
,
req_to_tokens
,
b_seq_len
,
attn_logits
,
sm_scale
,
# stride
q_nope
.
stride
(
0
),
q_nope
.
stride
(
1
),
q_pe
.
stride
(
0
),
q_pe
.
stride
(
1
),
kv_c_cache
.
stride
(
-
2
),
k_pe_cache
.
stride
(
-
2
),
req_to_tokens
.
stride
(
0
),
attn_logits
.
stride
(
0
),
attn_logits
.
stride
(
1
),
attn_logits
.
stride
(
2
),
BLOCK_H
=
BLOCK_H
,
BLOCK_N
=
BLOCK_N
,
NUM_KV_SPLITS
=
num_kv_splits
,
PAGE_SIZE
=
page_size
,
HEAD_DIM_CKV
=
head_dim_ckv
,
HEAD_DIM_KPE
=
head_dim_kpe
,
num_stages
=
1
,
# 2 will oom in amd
)
@
triton
.
jit
def
_mla_softmax_reducev_kernel
(
Logits
,
B_seq_len
,
O
,
stride_l_b
,
stride_l_h
,
stride_l_s
,
stride_o_b
,
stride_o_h
,
NUM_KV_SPLITS
:
tl
.
constexpr
,
HEAD_DIM_CKV
:
tl
.
constexpr
,
):
cur_batch
=
tl
.
program_id
(
0
)
cur_head
=
tl
.
program_id
(
1
)
cur_batch_seq_len
=
tl
.
load
(
B_seq_len
+
cur_batch
)
offs_d_ckv
=
tl
.
arange
(
0
,
HEAD_DIM_CKV
)
e_sum
=
0.0
e_max
=
-
float
(
"inf"
)
acc
=
tl
.
zeros
([
HEAD_DIM_CKV
],
dtype
=
tl
.
float32
)
offs_l
=
cur_batch
*
stride_l_b
+
cur_head
*
stride_l_h
+
offs_d_ckv
offs_l_1
=
cur_batch
*
stride_l_b
+
cur_head
*
stride_l_h
+
HEAD_DIM_CKV
for
split_kv_id
in
range
(
0
,
NUM_KV_SPLITS
):
kv_len_per_split
=
tl
.
cdiv
(
cur_batch_seq_len
,
NUM_KV_SPLITS
)
split_kv_start
=
kv_len_per_split
*
split_kv_id
split_kv_end
=
tl
.
minimum
(
split_kv_start
+
kv_len_per_split
,
cur_batch_seq_len
)
if
split_kv_end
>
split_kv_start
:
logits
=
tl
.
load
(
Logits
+
offs_l
+
split_kv_id
*
stride_l_s
)
logits_1
=
tl
.
load
(
Logits
+
offs_l_1
+
split_kv_id
*
stride_l_s
)
n_e_max
=
tl
.
maximum
(
logits_1
,
e_max
)
old_scale
=
tl
.
exp
(
e_max
-
n_e_max
)
acc
*=
old_scale
exp_logic
=
tl
.
exp
(
logits_1
-
n_e_max
)
acc
+=
exp_logic
*
logits
e_sum
=
e_sum
*
old_scale
+
exp_logic
e_max
=
n_e_max
tl
.
store
(
O
+
cur_batch
*
stride_o_b
+
cur_head
*
stride_o_h
+
offs_d_ckv
,
acc
/
e_sum
,
)
def
_mla_softmax_reducev
(
logits
,
o
,
b_seq_len
,
num_kv_splits
,
):
batch_size
,
head_num
,
head_dim_ckv
=
o
.
shape
[
0
],
o
.
shape
[
1
],
o
.
shape
[
2
]
grid
=
(
batch_size
,
head_num
)
_mla_softmax_reducev_kernel
[
grid
](
logits
,
b_seq_len
,
o
,
logits
.
stride
(
0
),
logits
.
stride
(
1
),
logits
.
stride
(
2
),
o
.
stride
(
0
),
o
.
stride
(
1
),
NUM_KV_SPLITS
=
num_kv_splits
,
HEAD_DIM_CKV
=
head_dim_ckv
,
)
def
mla_decode_triton
(
q_nope
,
q_pe
,
kv_c_cache
,
k_pe_cache
,
o
,
req_to_tokens
,
b_seq_len
,
attn_logits
,
num_kv_splits
,
sm_scale
,
page_size
,
):
assert
num_kv_splits
==
attn_logits
.
shape
[
2
]
_mla_attn
(
q_nope
,
q_pe
,
kv_c_cache
,
k_pe_cache
,
attn_logits
,
req_to_tokens
,
b_seq_len
,
num_kv_splits
,
sm_scale
,
page_size
,
)
_mla_softmax_reducev
(
attn_logits
,
o
,
b_seq_len
,
num_kv_splits
,
)
@
torch
.
inference_mode
()
def
run_flash_mla_triton
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
):
blocked_v
=
blocked_k
[...,
:
dv
]
assert
d
>
dv
,
"mla with rope dim should be larger than no rope dim"
q_nope
,
q_pe
=
q
[...,
:
dv
].
contiguous
(),
q
[...,
dv
:].
contiguous
()
blocked_k_nope
,
blocked_k_pe
=
blocked_k
[...,
:
dv
].
contiguous
(),
blocked_k
[...,
dv
:].
contiguous
()
def
flash_mla_triton
():
num_kv_splits
=
32
o
=
torch
.
empty
([
b
*
s_q
,
h_q
,
dv
])
attn_logits
=
torch
.
empty
([
b
*
s_q
,
h_q
,
num_kv_splits
,
dv
+
1
])
mla_decode_triton
(
q_nope
.
view
(
-
1
,
h_q
,
dv
),
q_pe
.
view
(
-
1
,
h_q
,
d
-
dv
),
blocked_k_nope
.
view
(
-
1
,
dv
),
blocked_k_pe
.
view
(
-
1
,
d
-
dv
),
o
,
block_table
,
cache_seqlens
,
attn_logits
,
num_kv_splits
,
1
/
math
.
sqrt
(
d
),
block_size
)
return
o
.
view
([
b
,
s_q
,
h_q
,
dv
])
out_flash
=
flash_mla_triton
()
t
=
triton
.
testing
.
do_bench
(
flash_mla_triton
)
return
out_flash
,
None
,
t
FUNC_TABLE
=
{
"torch"
:
run_torch_mla
,
"flash_mla_triton"
:
run_flash_mla_triton
,
}
def
compare_ab
(
baseline
,
target
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
):
print
(
f
"comparing
{
baseline
}
vs
{
target
}
:
{
b
=
}
,
{
s_q
=
}
, mean_seqlens=
{
cache_seqlens
.
float
().
mean
()
}
,
{
h_q
=
}
,
{
h_kv
=
}
,
{
d
=
}
,
{
dv
=
}
,
{
causal
=
}
,
{
dtype
=
}
"
)
device
=
torch
.
device
(
"cuda:0"
)
torch
.
set_default_dtype
(
dtype
)
torch
.
set_default_device
(
device
)
torch
.
cuda
.
set_device
(
device
)
torch
.
manual_seed
(
0
)
random
.
seed
(
0
)
assert
baseline
in
FUNC_TABLE
assert
target
in
FUNC_TABLE
baseline_func
=
FUNC_TABLE
[
baseline
]
target_func
=
FUNC_TABLE
[
target
]
total_seqlens
=
cache_seqlens
.
sum
().
item
()
max_seqlen
=
cache_seqlens
.
max
().
item
()
max_seqlen_pad
=
triton
.
cdiv
(
max_seqlen
,
256
)
*
256
# print(f"{total_seqlens=}, {mean_seqlens=}, {max_seqlen=}")
q
=
torch
.
randn
(
b
,
s_q
,
h_q
,
d
)
block_size
=
64
block_table
=
torch
.
arange
(
b
*
max_seqlen_pad
//
block_size
,
dtype
=
torch
.
int32
).
view
(
b
,
max_seqlen_pad
//
block_size
)
blocked_k
=
torch
.
randn
(
block_table
.
numel
(),
block_size
,
h_kv
,
d
)
out_a
,
lse_a
,
perf_a
=
baseline_func
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
)
out_b
,
lse_b
,
perf_b
=
target_func
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
)
torch
.
testing
.
assert_close
(
out_b
.
float
(),
out_a
.
float
(),
atol
=
1e-2
,
rtol
=
1e-2
),
"out"
if
target
not
in
[
"flash_mla_triton"
]:
# flash_mla_triton doesn't return lse
torch
.
testing
.
assert_close
(
lse_b
.
float
(),
lse_a
.
float
(),
atol
=
1e-2
,
rtol
=
1e-2
),
"lse"
FLOPS
=
s_q
*
total_seqlens
*
h_q
*
(
d
+
dv
)
*
2
bytes
=
(
total_seqlens
*
h_kv
*
d
+
b
*
s_q
*
h_q
*
d
+
b
*
s_q
*
h_q
*
dv
)
*
(
torch
.
finfo
(
dtype
).
bits
//
8
)
print
(
f
"perf
{
baseline
}
:
{
perf_a
:.
3
f
}
ms,
{
FLOPS
/
10
**
9
/
perf_a
:.
0
f
}
TFLOPS,
{
bytes
/
10
**
6
/
perf_a
:.
0
f
}
GB/s"
)
print
(
f
"perf
{
target
}
:
{
perf_b
:.
3
f
}
ms,
{
FLOPS
/
10
**
9
/
perf_b
:.
0
f
}
TFLOPS,
{
bytes
/
10
**
6
/
perf_b
:.
0
f
}
GB/s"
)
return
bytes
/
10
**
6
/
perf_a
,
bytes
/
10
**
6
/
perf_b
def
compare_a
(
target
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
):
print
(
f
"
{
target
}
:
{
b
=
}
,
{
s_q
=
}
, mean_seqlens=
{
cache_seqlens
.
float
().
mean
()
}
,
{
h_q
=
}
,
{
h_kv
=
}
,
{
d
=
}
,
{
dv
=
}
,
{
causal
=
}
,
{
dtype
=
}
"
)
torch
.
set_default_dtype
(
dtype
)
device
=
torch
.
device
(
"cuda:0"
)
torch
.
set_default_device
(
device
)
torch
.
cuda
.
set_device
(
device
)
torch
.
manual_seed
(
0
)
random
.
seed
(
0
)
assert
target
in
FUNC_TABLE
,
f
"target
{
target
}
not in
{
FUNC_TABLE
}
"
target_func
=
FUNC_TABLE
[
target
]
total_seqlens
=
cache_seqlens
.
sum
().
item
()
max_seqlen
=
cache_seqlens
.
max
().
item
()
max_seqlen_pad
=
triton
.
cdiv
(
max_seqlen
,
256
)
*
256
# print(f"{total_seqlens=}, {mean_seqlens=}, {max_seqlen=}")
q
=
torch
.
randn
(
b
,
s_q
,
h_q
,
d
)
block_size
=
64
block_table
=
torch
.
arange
(
b
*
max_seqlen_pad
//
block_size
,
dtype
=
torch
.
int32
).
view
(
b
,
max_seqlen_pad
//
block_size
)
blocked_k
=
torch
.
randn
(
block_table
.
numel
(),
block_size
,
h_kv
,
d
)
out_b
,
lse_b
,
perf_b
=
target_func
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
)
FLOPS
=
s_q
*
total_seqlens
*
h_q
*
(
d
+
dv
)
*
2
bytes
=
(
total_seqlens
*
h_kv
*
d
+
b
*
s_q
*
h_q
*
d
+
b
*
s_q
*
h_q
*
dv
)
*
(
torch
.
finfo
(
dtype
).
bits
//
8
)
print
(
f
"perf
{
target
}
:
{
perf_b
:.
3
f
}
ms,
{
FLOPS
/
10
**
9
/
perf_b
:.
0
f
}
TFLOPS,
{
bytes
/
10
**
6
/
perf_b
:.
0
f
}
GB/s"
)
return
bytes
/
10
**
6
/
perf_b
available_targets
=
[
"torch"
,
"flash_mla_triton"
,
]
shape_configs
=
[{
"b"
:
batch
,
"s_q"
:
1
,
"cache_seqlens"
:
torch
.
tensor
([
seqlen
+
2
*
i
for
i
in
range
(
batch
)],
dtype
=
torch
.
int32
,
device
=
"cuda"
),
"h_q"
:
head
,
"h_kv"
:
1
,
"d"
:
512
+
64
,
"dv"
:
512
,
"causal"
:
True
,
"dtype"
:
torch
.
float16
}
for
batch
in
[
128
]
for
seqlen
in
[
1024
,
2048
,
4096
,
8192
,
16384
]
for
head
in
[
128
]]
def
get_args
():
parser
=
argparse
.
ArgumentParser
()
parser
.
add_argument
(
"--baseline"
,
type
=
str
,
default
=
"torch"
)
parser
.
add_argument
(
"--target"
,
type
=
str
,
default
=
"torch"
)
parser
.
add_argument
(
"--all"
,
action
=
"store_true"
)
parser
.
add_argument
(
"--one"
,
action
=
"store_true"
)
parser
.
add_argument
(
"--compare"
,
action
=
"store_true"
)
args
=
parser
.
parse_args
()
return
args
if
__name__
==
"__main__"
:
args
=
get_args
()
benchmark_type
=
"all"
if
args
.
all
else
f
"
{
args
.
baseline
}
_vs_
{
args
.
target
}
"
if
args
.
compare
else
args
.
target
with
open
(
f
"
{
benchmark_type
}
_perf.csv"
,
"w"
)
as
fout
:
fout
.
write
(
"name,batch,seqlen,head,bw
\n
"
)
for
shape
in
shape_configs
:
if
args
.
all
:
for
target
in
available_targets
:
perf
=
compare_a
(
target
,
shape
[
"b"
],
shape
[
"s_q"
],
shape
[
"cache_seqlens"
],
shape
[
"h_q"
],
shape
[
"h_kv"
],
shape
[
"d"
],
shape
[
"dv"
],
shape
[
"causal"
],
shape
[
"dtype"
])
fout
.
write
(
f
'
{
target
}
,
{
shape
[
"b"
]
}
,
{
shape
[
"cache_seqlens"
].
float
().
mean
().
cpu
().
item
():.
0
f
}
,
{
shape
[
"h_q"
]
}
,
{
perf
:.
0
f
}
\n
'
)
elif
args
.
compare
:
perfa
,
prefb
=
compare_ab
(
args
.
baseline
,
args
.
target
,
shape
[
"b"
],
shape
[
"s_q"
],
shape
[
"cache_seqlens"
],
shape
[
"h_q"
],
shape
[
"h_kv"
],
shape
[
"d"
],
shape
[
"dv"
],
shape
[
"causal"
],
shape
[
"dtype"
])
fout
.
write
(
f
'
{
args
.
baseline
}
,
{
shape
[
"b"
]
}
,
{
shape
[
"cache_seqlens"
].
float
().
mean
().
cpu
().
item
():.
0
f
}
,
{
shape
[
"h_q"
]
}
,
{
perfa
:.
0
f
}
\n
'
)
fout
.
write
(
f
'
{
args
.
target
}
,
{
shape
[
"b"
]
}
,
{
shape
[
"cache_seqlens"
].
float
().
mean
().
cpu
().
item
():.
0
f
}
,
{
shape
[
"h_q"
]
}
,
{
prefb
:.
0
f
}
\n
'
)
elif
args
.
one
:
perf
=
compare_a
(
args
.
target
,
shape
[
"b"
],
shape
[
"s_q"
],
shape
[
"cache_seqlens"
],
shape
[
"h_q"
],
shape
[
"h_kv"
],
shape
[
"d"
],
shape
[
"dv"
],
shape
[
"causal"
],
shape
[
"dtype"
])
fout
.
write
(
f
'
{
args
.
target
}
,
{
shape
[
"b"
]
}
,
{
shape
[
"cache_seqlens"
].
float
().
mean
().
cpu
().
item
():.
0
f
}
,
{
shape
[
"h_q"
]
}
,
{
perf
:.
0
f
}
\n
'
)
examples/deepseek_mla/amd/benchmark_mla_decode_amd_triton.py
0 → 100644
View file @
bc2d5632
# This benchmark script is modified based on: https://github.com/deepseek-ai/FlashMLA/blob/main/benchmark/bench_flash_mla.py
# ruff: noqa
import
argparse
import
math
import
random
import
torch
import
triton
import
triton.language
as
tl
def
scaled_dot_product_attention
(
query
,
key
,
value
,
h_q
,
h_kv
,
is_causal
=
False
):
query
=
query
.
float
()
key
=
key
.
float
()
value
=
value
.
float
()
key
=
key
.
repeat_interleave
(
h_q
//
h_kv
,
dim
=
0
)
value
=
value
.
repeat_interleave
(
h_q
//
h_kv
,
dim
=
0
)
attn_weight
=
query
@
key
.
transpose
(
-
2
,
-
1
)
/
math
.
sqrt
(
query
.
size
(
-
1
))
if
is_causal
:
s_q
=
query
.
shape
[
-
2
]
s_k
=
key
.
shape
[
-
2
]
attn_bias
=
torch
.
zeros
(
s_q
,
s_k
,
dtype
=
query
.
dtype
)
temp_mask
=
torch
.
ones
(
s_q
,
s_k
,
dtype
=
torch
.
bool
).
tril
(
diagonal
=
s_k
-
s_q
)
attn_bias
.
masked_fill_
(
temp_mask
.
logical_not
(),
float
(
"-inf"
))
attn_bias
.
to
(
query
.
dtype
)
attn_weight
+=
attn_bias
lse
=
attn_weight
.
logsumexp
(
dim
=-
1
)
attn_weight
=
torch
.
softmax
(
attn_weight
,
dim
=-
1
,
dtype
=
torch
.
float32
)
return
attn_weight
@
value
,
lse
@
torch
.
inference_mode
()
def
run_torch_mla
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
):
blocked_v
=
blocked_k
[...,
:
dv
]
def
ref_mla
():
out
=
torch
.
empty
(
b
,
s_q
,
h_q
,
dv
,
dtype
=
torch
.
float32
)
lse
=
torch
.
empty
(
b
,
h_q
,
s_q
,
dtype
=
torch
.
float32
)
for
i
in
range
(
b
):
begin
=
i
*
max_seqlen_pad
end
=
begin
+
cache_seqlens
[
i
]
O
,
LSE
=
scaled_dot_product_attention
(
q
[
i
].
transpose
(
0
,
1
),
blocked_k
.
view
(
-
1
,
h_kv
,
d
)[
begin
:
end
].
transpose
(
0
,
1
),
blocked_v
.
view
(
-
1
,
h_kv
,
dv
)[
begin
:
end
].
transpose
(
0
,
1
),
h_q
,
h_kv
,
is_causal
=
causal
,
)
out
[
i
]
=
O
.
transpose
(
0
,
1
)
lse
[
i
]
=
LSE
return
out
,
lse
out_torch
,
lse_torch
=
ref_mla
()
t
=
triton
.
testing
.
do_bench
(
ref_mla
)
return
out_torch
,
lse_torch
,
t
@
triton
.
jit
def
_mla_attn_kernel
(
Q_nope
,
Q_pe
,
Kv_c_cache
,
K_pe_cache
,
Req_to_tokens
,
B_seq_len
,
O
,
sm_scale
,
stride_q_nope_bs
,
stride_q_nope_h
,
stride_q_pe_bs
,
stride_q_pe_h
,
stride_kv_c_bs
,
stride_k_pe_bs
,
stride_req_to_tokens_bs
,
stride_o_b
,
stride_o_h
,
stride_o_s
,
BLOCK_H
:
tl
.
constexpr
,
BLOCK_N
:
tl
.
constexpr
,
NUM_KV_SPLITS
:
tl
.
constexpr
,
PAGE_SIZE
:
tl
.
constexpr
,
HEAD_DIM_CKV
:
tl
.
constexpr
,
HEAD_DIM_KPE
:
tl
.
constexpr
,
):
cur_batch
=
tl
.
program_id
(
1
)
cur_head_id
=
tl
.
program_id
(
0
)
split_kv_id
=
tl
.
program_id
(
2
)
cur_batch_seq_len
=
tl
.
load
(
B_seq_len
+
cur_batch
)
offs_d_ckv
=
tl
.
arange
(
0
,
HEAD_DIM_CKV
)
cur_head
=
cur_head_id
*
BLOCK_H
+
tl
.
arange
(
0
,
BLOCK_H
)
offs_q_nope
=
cur_batch
*
stride_q_nope_bs
+
cur_head
[:,
None
]
*
stride_q_nope_h
+
offs_d_ckv
[
None
,
:]
q_nope
=
tl
.
load
(
Q_nope
+
offs_q_nope
)
offs_d_kpe
=
tl
.
arange
(
0
,
HEAD_DIM_KPE
)
offs_q_pe
=
cur_batch
*
stride_q_pe_bs
+
cur_head
[:,
None
]
*
stride_q_pe_h
+
offs_d_kpe
[
None
,
:]
q_pe
=
tl
.
load
(
Q_pe
+
offs_q_pe
)
e_max
=
tl
.
zeros
([
BLOCK_H
],
dtype
=
tl
.
float32
)
-
float
(
"inf"
)
e_sum
=
tl
.
zeros
([
BLOCK_H
],
dtype
=
tl
.
float32
)
acc
=
tl
.
zeros
([
BLOCK_H
,
HEAD_DIM_CKV
],
dtype
=
tl
.
float32
)
kv_len_per_split
=
tl
.
cdiv
(
cur_batch_seq_len
,
NUM_KV_SPLITS
)
split_kv_start
=
kv_len_per_split
*
split_kv_id
split_kv_end
=
tl
.
minimum
(
split_kv_start
+
kv_len_per_split
,
cur_batch_seq_len
)
for
start_n
in
range
(
split_kv_start
,
split_kv_end
,
BLOCK_N
):
offs_n
=
start_n
+
tl
.
arange
(
0
,
BLOCK_N
)
kv_page_number
=
tl
.
load
(
Req_to_tokens
+
stride_req_to_tokens_bs
*
cur_batch
+
offs_n
//
PAGE_SIZE
,
mask
=
offs_n
<
split_kv_end
,
other
=
0
,
)
kv_loc
=
kv_page_number
*
PAGE_SIZE
+
offs_n
%
PAGE_SIZE
offs_k_c
=
kv_loc
[
None
,
:]
*
stride_kv_c_bs
+
offs_d_ckv
[:,
None
]
k_c
=
tl
.
load
(
Kv_c_cache
+
offs_k_c
,
mask
=
offs_n
[
None
,
:]
<
split_kv_end
,
other
=
0.0
)
qk
=
tl
.
dot
(
q_nope
,
k_c
.
to
(
q_nope
.
dtype
))
offs_k_pe
=
kv_loc
[
None
,
:]
*
stride_k_pe_bs
+
offs_d_kpe
[:,
None
]
k_pe
=
tl
.
load
(
K_pe_cache
+
offs_k_pe
,
mask
=
offs_n
[
None
,
:]
<
split_kv_end
,
other
=
0.0
)
qk
+=
tl
.
dot
(
q_pe
,
k_pe
.
to
(
q_pe
.
dtype
))
qk
*=
sm_scale
qk
=
tl
.
where
(
offs_n
[
None
,
:]
<
split_kv_end
,
qk
,
float
(
"-inf"
))
v_c
=
tl
.
trans
(
k_c
)
n_e_max
=
tl
.
maximum
(
tl
.
max
(
qk
,
1
),
e_max
)
re_scale
=
tl
.
exp
(
e_max
-
n_e_max
)
p
=
tl
.
exp
(
qk
-
n_e_max
[:,
None
])
acc
*=
re_scale
[:,
None
]
acc
+=
tl
.
dot
(
p
.
to
(
v_c
.
dtype
),
v_c
)
e_sum
=
e_sum
*
re_scale
+
tl
.
sum
(
p
,
1
)
e_max
=
n_e_max
offs_o
=
cur_batch
*
stride_o_b
+
cur_head
[:,
None
]
*
stride_o_h
+
split_kv_id
*
stride_o_s
+
offs_d_ckv
[
None
,
:]
tl
.
store
(
O
+
offs_o
,
acc
/
e_sum
[:,
None
])
offs_o_1
=
cur_batch
*
stride_o_b
+
cur_head
*
stride_o_h
+
split_kv_id
*
stride_o_s
+
HEAD_DIM_CKV
tl
.
store
(
O
+
offs_o_1
,
e_max
+
tl
.
log
(
e_sum
))
def
_mla_attn
(
q_nope
,
q_pe
,
kv_c_cache
,
k_pe_cache
,
attn_logits
,
req_to_tokens
,
b_seq_len
,
num_kv_splits
,
sm_scale
,
page_size
,
):
batch_size
,
head_num
=
q_nope
.
shape
[
0
],
q_nope
.
shape
[
1
]
head_dim_ckv
=
q_nope
.
shape
[
-
1
]
head_dim_kpe
=
q_pe
.
shape
[
-
1
]
BLOCK_H
=
16
BLOCK_N
=
64
grid
=
(
triton
.
cdiv
(
head_num
,
BLOCK_H
),
batch_size
,
num_kv_splits
,
)
_mla_attn_kernel
[
grid
](
q_nope
,
q_pe
,
kv_c_cache
,
k_pe_cache
,
req_to_tokens
,
b_seq_len
,
attn_logits
,
sm_scale
,
# stride
q_nope
.
stride
(
0
),
q_nope
.
stride
(
1
),
q_pe
.
stride
(
0
),
q_pe
.
stride
(
1
),
kv_c_cache
.
stride
(
-
2
),
k_pe_cache
.
stride
(
-
2
),
req_to_tokens
.
stride
(
0
),
attn_logits
.
stride
(
0
),
attn_logits
.
stride
(
1
),
attn_logits
.
stride
(
2
),
BLOCK_H
=
BLOCK_H
,
BLOCK_N
=
BLOCK_N
,
NUM_KV_SPLITS
=
num_kv_splits
,
PAGE_SIZE
=
page_size
,
HEAD_DIM_CKV
=
head_dim_ckv
,
HEAD_DIM_KPE
=
head_dim_kpe
,
num_stages
=
1
,
# 2 will oom in amd
)
@
triton
.
jit
def
_mla_softmax_reducev_kernel
(
Logits
,
B_seq_len
,
O
,
stride_l_b
,
stride_l_h
,
stride_l_s
,
stride_o_b
,
stride_o_h
,
NUM_KV_SPLITS
:
tl
.
constexpr
,
HEAD_DIM_CKV
:
tl
.
constexpr
,
):
cur_batch
=
tl
.
program_id
(
0
)
cur_head
=
tl
.
program_id
(
1
)
cur_batch_seq_len
=
tl
.
load
(
B_seq_len
+
cur_batch
)
offs_d_ckv
=
tl
.
arange
(
0
,
HEAD_DIM_CKV
)
e_sum
=
0.0
e_max
=
-
float
(
"inf"
)
acc
=
tl
.
zeros
([
HEAD_DIM_CKV
],
dtype
=
tl
.
float32
)
offs_l
=
cur_batch
*
stride_l_b
+
cur_head
*
stride_l_h
+
offs_d_ckv
offs_l_1
=
cur_batch
*
stride_l_b
+
cur_head
*
stride_l_h
+
HEAD_DIM_CKV
for
split_kv_id
in
range
(
0
,
NUM_KV_SPLITS
):
kv_len_per_split
=
tl
.
cdiv
(
cur_batch_seq_len
,
NUM_KV_SPLITS
)
split_kv_start
=
kv_len_per_split
*
split_kv_id
split_kv_end
=
tl
.
minimum
(
split_kv_start
+
kv_len_per_split
,
cur_batch_seq_len
)
if
split_kv_end
>
split_kv_start
:
logits
=
tl
.
load
(
Logits
+
offs_l
+
split_kv_id
*
stride_l_s
)
logits_1
=
tl
.
load
(
Logits
+
offs_l_1
+
split_kv_id
*
stride_l_s
)
n_e_max
=
tl
.
maximum
(
logits_1
,
e_max
)
old_scale
=
tl
.
exp
(
e_max
-
n_e_max
)
acc
*=
old_scale
exp_logic
=
tl
.
exp
(
logits_1
-
n_e_max
)
acc
+=
exp_logic
*
logits
e_sum
=
e_sum
*
old_scale
+
exp_logic
e_max
=
n_e_max
tl
.
store
(
O
+
cur_batch
*
stride_o_b
+
cur_head
*
stride_o_h
+
offs_d_ckv
,
acc
/
e_sum
,
)
def
_mla_softmax_reducev
(
logits
,
o
,
b_seq_len
,
num_kv_splits
,
):
batch_size
,
head_num
,
head_dim_ckv
=
o
.
shape
[
0
],
o
.
shape
[
1
],
o
.
shape
[
2
]
grid
=
(
batch_size
,
head_num
)
_mla_softmax_reducev_kernel
[
grid
](
logits
,
b_seq_len
,
o
,
logits
.
stride
(
0
),
logits
.
stride
(
1
),
logits
.
stride
(
2
),
o
.
stride
(
0
),
o
.
stride
(
1
),
NUM_KV_SPLITS
=
num_kv_splits
,
HEAD_DIM_CKV
=
head_dim_ckv
,
)
def
mla_decode_triton
(
q_nope
,
q_pe
,
kv_c_cache
,
k_pe_cache
,
o
,
req_to_tokens
,
b_seq_len
,
attn_logits
,
num_kv_splits
,
sm_scale
,
page_size
,
):
assert
num_kv_splits
==
attn_logits
.
shape
[
2
]
_mla_attn
(
q_nope
,
q_pe
,
kv_c_cache
,
k_pe_cache
,
attn_logits
,
req_to_tokens
,
b_seq_len
,
num_kv_splits
,
sm_scale
,
page_size
,
)
_mla_softmax_reducev
(
attn_logits
,
o
,
b_seq_len
,
num_kv_splits
,
)
@
torch
.
inference_mode
()
def
run_flash_mla_triton
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
):
blocked_v
=
blocked_k
[...,
:
dv
]
assert
d
>
dv
,
"mla with rope dim should be larger than no rope dim"
q_nope
,
q_pe
=
q
[...,
:
dv
].
contiguous
(),
q
[...,
dv
:].
contiguous
()
blocked_k_nope
,
blocked_k_pe
=
blocked_k
[...,
:
dv
].
contiguous
(),
blocked_k
[...,
dv
:].
contiguous
()
def
flash_mla_triton
():
num_kv_splits
=
32
o
=
torch
.
empty
([
b
*
s_q
,
h_q
,
dv
])
attn_logits
=
torch
.
empty
([
b
*
s_q
,
h_q
,
num_kv_splits
,
dv
+
1
])
mla_decode_triton
(
q_nope
.
view
(
-
1
,
h_q
,
dv
),
q_pe
.
view
(
-
1
,
h_q
,
d
-
dv
),
blocked_k_nope
.
view
(
-
1
,
dv
),
blocked_k_pe
.
view
(
-
1
,
d
-
dv
),
o
,
block_table
,
cache_seqlens
,
attn_logits
,
num_kv_splits
,
1
/
math
.
sqrt
(
d
),
block_size
)
return
o
.
view
([
b
,
s_q
,
h_q
,
dv
])
out_flash
=
flash_mla_triton
()
t
=
triton
.
testing
.
do_bench
(
flash_mla_triton
)
return
out_flash
,
None
,
t
FUNC_TABLE
=
{
"torch"
:
run_torch_mla
,
"flash_mla_triton"
:
run_flash_mla_triton
,
}
def
compare_ab
(
baseline
,
target
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
):
print
(
f
"comparing
{
baseline
}
vs
{
target
}
:
{
b
=
}
,
{
s_q
=
}
, mean_seqlens=
{
cache_seqlens
.
float
().
mean
()
}
,
{
h_q
=
}
,
{
h_kv
=
}
,
{
d
=
}
,
{
dv
=
}
,
{
causal
=
}
,
{
dtype
=
}
"
)
device
=
torch
.
device
(
"cuda:0"
)
torch
.
set_default_dtype
(
dtype
)
torch
.
set_default_device
(
device
)
torch
.
cuda
.
set_device
(
device
)
torch
.
manual_seed
(
0
)
random
.
seed
(
0
)
assert
baseline
in
FUNC_TABLE
assert
target
in
FUNC_TABLE
baseline_func
=
FUNC_TABLE
[
baseline
]
target_func
=
FUNC_TABLE
[
target
]
total_seqlens
=
cache_seqlens
.
sum
().
item
()
max_seqlen
=
cache_seqlens
.
max
().
item
()
max_seqlen_pad
=
triton
.
cdiv
(
max_seqlen
,
256
)
*
256
# print(f"{total_seqlens=}, {mean_seqlens=}, {max_seqlen=}")
q
=
torch
.
randn
(
b
,
s_q
,
h_q
,
d
)
block_size
=
64
block_table
=
torch
.
arange
(
b
*
max_seqlen_pad
//
block_size
,
dtype
=
torch
.
int32
).
view
(
b
,
max_seqlen_pad
//
block_size
)
blocked_k
=
torch
.
randn
(
block_table
.
numel
(),
block_size
,
h_kv
,
d
)
out_a
,
lse_a
,
perf_a
=
baseline_func
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
)
out_b
,
lse_b
,
perf_b
=
target_func
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
)
torch
.
testing
.
assert_close
(
out_b
.
float
(),
out_a
.
float
(),
atol
=
1e-2
,
rtol
=
1e-2
),
"out"
if
target
not
in
[
"flash_mla_triton"
]:
# flash_mla_triton doesn't return lse
torch
.
testing
.
assert_close
(
lse_b
.
float
(),
lse_a
.
float
(),
atol
=
1e-2
,
rtol
=
1e-2
),
"lse"
FLOPS
=
s_q
*
total_seqlens
*
h_q
*
(
d
+
dv
)
*
2
bytes
=
(
total_seqlens
*
h_kv
*
d
+
b
*
s_q
*
h_q
*
d
+
b
*
s_q
*
h_q
*
dv
)
*
(
torch
.
finfo
(
dtype
).
bits
//
8
)
print
(
f
"perf
{
baseline
}
:
{
perf_a
:.
3
f
}
ms,
{
FLOPS
/
10
**
9
/
perf_a
:.
0
f
}
TFLOPS,
{
bytes
/
10
**
6
/
perf_a
:.
0
f
}
GB/s"
)
print
(
f
"perf
{
target
}
:
{
perf_b
:.
3
f
}
ms,
{
FLOPS
/
10
**
9
/
perf_b
:.
0
f
}
TFLOPS,
{
bytes
/
10
**
6
/
perf_b
:.
0
f
}
GB/s"
)
return
bytes
/
10
**
6
/
perf_a
,
bytes
/
10
**
6
/
perf_b
def
compare_a
(
target
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
):
print
(
f
"
{
target
}
:
{
b
=
}
,
{
s_q
=
}
, mean_seqlens=
{
cache_seqlens
.
float
().
mean
()
}
,
{
h_q
=
}
,
{
h_kv
=
}
,
{
d
=
}
,
{
dv
=
}
,
{
causal
=
}
,
{
dtype
=
}
"
)
torch
.
set_default_dtype
(
dtype
)
device
=
torch
.
device
(
"cuda:0"
)
torch
.
set_default_device
(
device
)
torch
.
cuda
.
set_device
(
device
)
torch
.
manual_seed
(
0
)
random
.
seed
(
0
)
assert
target
in
FUNC_TABLE
,
f
"target
{
target
}
not in
{
FUNC_TABLE
}
"
target_func
=
FUNC_TABLE
[
target
]
total_seqlens
=
cache_seqlens
.
sum
().
item
()
max_seqlen
=
cache_seqlens
.
max
().
item
()
max_seqlen_pad
=
triton
.
cdiv
(
max_seqlen
,
256
)
*
256
# print(f"{total_seqlens=}, {mean_seqlens=}, {max_seqlen=}")
q
=
torch
.
randn
(
b
,
s_q
,
h_q
,
d
)
block_size
=
64
block_table
=
torch
.
arange
(
b
*
max_seqlen_pad
//
block_size
,
dtype
=
torch
.
int32
).
view
(
b
,
max_seqlen_pad
//
block_size
)
blocked_k
=
torch
.
randn
(
block_table
.
numel
(),
block_size
,
h_kv
,
d
)
out_b
,
lse_b
,
perf_b
=
target_func
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
)
FLOPS
=
s_q
*
total_seqlens
*
h_q
*
(
d
+
dv
)
*
2
bytes
=
(
total_seqlens
*
h_kv
*
d
+
b
*
s_q
*
h_q
*
d
+
b
*
s_q
*
h_q
*
dv
)
*
(
torch
.
finfo
(
dtype
).
bits
//
8
)
print
(
f
"perf
{
target
}
:
{
perf_b
:.
3
f
}
ms,
{
FLOPS
/
10
**
9
/
perf_b
:.
0
f
}
TFLOPS,
{
bytes
/
10
**
6
/
perf_b
:.
0
f
}
GB/s"
)
return
bytes
/
10
**
6
/
perf_b
available_targets
=
[
"torch"
,
"flash_mla_triton"
,
]
shape_configs
=
[{
"b"
:
batch
,
"s_q"
:
1
,
"cache_seqlens"
:
torch
.
tensor
([
seqlen
+
2
*
i
for
i
in
range
(
batch
)],
dtype
=
torch
.
int32
,
device
=
"cuda"
),
"h_q"
:
head
,
"h_kv"
:
1
,
"d"
:
512
+
64
,
"dv"
:
512
,
"causal"
:
True
,
"dtype"
:
torch
.
float16
}
for
batch
in
[
64
,
128
]
for
seqlen
in
[
1024
,
2048
,
4096
,
8192
,
16384
]
for
head
in
[
128
]]
def
get_args
():
parser
=
argparse
.
ArgumentParser
()
parser
.
add_argument
(
"--baseline"
,
type
=
str
,
default
=
"torch"
)
parser
.
add_argument
(
"--target"
,
type
=
str
,
default
=
"flash_mla_triton"
)
parser
.
add_argument
(
"--all"
,
action
=
"store_true"
)
parser
.
add_argument
(
"--one"
,
action
=
"store_true"
)
parser
.
add_argument
(
"--compare"
,
action
=
"store_true"
)
args
=
parser
.
parse_args
()
return
args
if
__name__
==
"__main__"
:
args
=
get_args
()
benchmark_type
=
"all"
if
args
.
all
else
f
"
{
args
.
baseline
}
_vs_
{
args
.
target
}
"
if
args
.
compare
else
args
.
target
with
open
(
f
"
{
benchmark_type
}
_perf.csv"
,
"w"
)
as
fout
:
fout
.
write
(
"name,batch,seqlen,head,bw
\n
"
)
for
shape
in
shape_configs
:
if
args
.
all
:
for
target
in
available_targets
:
perf
=
compare_a
(
target
,
shape
[
"b"
],
shape
[
"s_q"
],
shape
[
"cache_seqlens"
],
shape
[
"h_q"
],
shape
[
"h_kv"
],
shape
[
"d"
],
shape
[
"dv"
],
shape
[
"causal"
],
shape
[
"dtype"
])
fout
.
write
(
f
'
{
target
}
,
{
shape
[
"b"
]
}
,
{
shape
[
"cache_seqlens"
].
float
().
mean
().
cpu
().
item
():.
0
f
}
,
{
shape
[
"h_q"
]
}
,
{
perf
:.
0
f
}
\n
'
)
elif
args
.
compare
:
perfa
,
prefb
=
compare_ab
(
args
.
baseline
,
args
.
target
,
shape
[
"b"
],
shape
[
"s_q"
],
shape
[
"cache_seqlens"
],
shape
[
"h_q"
],
shape
[
"h_kv"
],
shape
[
"d"
],
shape
[
"dv"
],
shape
[
"causal"
],
shape
[
"dtype"
])
fout
.
write
(
f
'
{
args
.
baseline
}
,
{
shape
[
"b"
]
}
,
{
shape
[
"cache_seqlens"
].
float
().
mean
().
cpu
().
item
():.
0
f
}
,
{
shape
[
"h_q"
]
}
,
{
perfa
:.
0
f
}
\n
'
)
fout
.
write
(
f
'
{
args
.
target
}
,
{
shape
[
"b"
]
}
,
{
shape
[
"cache_seqlens"
].
float
().
mean
().
cpu
().
item
():.
0
f
}
,
{
shape
[
"h_q"
]
}
,
{
prefb
:.
0
f
}
\n
'
)
elif
args
.
one
:
perf
=
compare_a
(
args
.
target
,
shape
[
"b"
],
shape
[
"s_q"
],
shape
[
"cache_seqlens"
],
shape
[
"h_q"
],
shape
[
"h_kv"
],
shape
[
"d"
],
shape
[
"dv"
],
shape
[
"causal"
],
shape
[
"dtype"
])
fout
.
write
(
f
'
{
args
.
target
}
,
{
shape
[
"b"
]
}
,
{
shape
[
"cache_seqlens"
].
float
().
mean
().
cpu
().
item
():.
0
f
}
,
{
shape
[
"h_q"
]
}
,
{
perf
:.
0
f
}
\n
'
)
examples/deepseek_mla/benchmark_mla.py
0 → 100644
View file @
bc2d5632
# This benchmark script is modified based on: https://github.com/deepseek-ai/FlashMLA/blob/main/benchmark/bench_flash_mla.py
# ruff: noqa
import
argparse
import
math
import
random
import
torch
import
triton
import
triton.language
as
tl
import
tilelang
from
tilelang.profiler
import
do_bench
from
example_mla_decode_paged
import
mla_decode_tilelang
def
scaled_dot_product_attention
(
query
,
key
,
value
,
h_q
,
h_kv
,
is_causal
=
False
):
query
=
query
.
float
()
key
=
key
.
float
()
value
=
value
.
float
()
key
=
key
.
repeat_interleave
(
h_q
//
h_kv
,
dim
=
0
)
value
=
value
.
repeat_interleave
(
h_q
//
h_kv
,
dim
=
0
)
attn_weight
=
query
@
key
.
transpose
(
-
2
,
-
1
)
/
math
.
sqrt
(
query
.
size
(
-
1
))
if
is_causal
:
s_q
=
query
.
shape
[
-
2
]
s_k
=
key
.
shape
[
-
2
]
attn_bias
=
torch
.
zeros
(
s_q
,
s_k
,
dtype
=
query
.
dtype
)
temp_mask
=
torch
.
ones
(
s_q
,
s_k
,
dtype
=
torch
.
bool
).
tril
(
diagonal
=
s_k
-
s_q
)
attn_bias
.
masked_fill_
(
temp_mask
.
logical_not
(),
float
(
"-inf"
))
attn_bias
.
to
(
query
.
dtype
)
attn_weight
+=
attn_bias
lse
=
attn_weight
.
logsumexp
(
dim
=-
1
)
attn_weight
=
torch
.
softmax
(
attn_weight
,
dim
=-
1
,
dtype
=
torch
.
float32
)
return
attn_weight
@
value
,
lse
@
torch
.
inference_mode
()
def
run_torch_mla
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
):
blocked_v
=
blocked_k
[...,
:
dv
]
def
ref_mla
():
out
=
torch
.
empty
(
b
,
s_q
,
h_q
,
dv
,
dtype
=
torch
.
float32
)
lse
=
torch
.
empty
(
b
,
h_q
,
s_q
,
dtype
=
torch
.
float32
)
for
i
in
range
(
b
):
begin
=
i
*
max_seqlen_pad
end
=
begin
+
cache_seqlens
[
i
]
O
,
LSE
=
scaled_dot_product_attention
(
q
[
i
].
transpose
(
0
,
1
),
blocked_k
.
view
(
-
1
,
h_kv
,
d
)[
begin
:
end
].
transpose
(
0
,
1
),
blocked_v
.
view
(
-
1
,
h_kv
,
dv
)[
begin
:
end
].
transpose
(
0
,
1
),
h_q
,
h_kv
,
is_causal
=
causal
,
)
out
[
i
]
=
O
.
transpose
(
0
,
1
)
lse
[
i
]
=
LSE
return
out
,
lse
out_torch
,
lse_torch
=
ref_mla
()
t
=
triton
.
testing
.
do_bench
(
ref_mla
)
return
out_torch
,
lse_torch
,
t
@
torch
.
inference_mode
()
def
run_flash_mla
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
):
from
flash_mla
import
flash_mla_with_kvcache
,
get_mla_metadata
blocked_v
=
blocked_k
[...,
:
dv
]
tile_scheduler_metadata
,
num_splits
=
get_mla_metadata
(
cache_seqlens
,
s_q
*
h_q
//
h_kv
,
h_kv
)
def
flash_mla
():
return
flash_mla_with_kvcache
(
q
,
blocked_k
,
block_table
,
cache_seqlens
,
dv
,
tile_scheduler_metadata
,
num_splits
,
causal
=
causal
,
)
out_flash
,
lse_flash
=
flash_mla
()
t
=
triton
.
testing
.
do_bench
(
flash_mla
)
return
out_flash
,
lse_flash
,
t
@
torch
.
inference_mode
()
def
run_flashinfer
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
):
# pip install flashinfer-python
import
flashinfer
assert
d
>
dv
,
"mla with rope dim should be larger than no rope dim"
q_nope
,
q_pe
=
q
[...,
:
dv
].
contiguous
(),
q
[...,
dv
:].
contiguous
()
blocked_k_nope
,
blocked_k_pe
=
blocked_k
[...,
:
dv
].
contiguous
(),
blocked_k
[...,
dv
:].
contiguous
()
kv_indptr
=
[
0
]
kv_indices
=
[]
for
i
in
range
(
b
):
seq_len
=
cache_seqlens
[
i
]
assert
seq_len
>
0
num_blocks
=
(
seq_len
+
block_size
-
1
)
//
block_size
kv_indices
.
extend
(
block_table
[
i
,
:
num_blocks
])
kv_indptr
.
append
(
kv_indptr
[
-
1
]
+
num_blocks
)
for
seq_len
in
cache_seqlens
[
1
:]:
kv_indptr
.
append
((
seq_len
+
block_size
-
1
)
//
block_size
+
kv_indptr
[
-
1
])
q_indptr
=
torch
.
arange
(
0
,
b
+
1
).
int
()
*
s_q
kv_indptr
=
torch
.
tensor
(
kv_indptr
,
dtype
=
torch
.
int32
)
kv_indices
=
torch
.
tensor
(
kv_indices
,
dtype
=
torch
.
int32
)
mla_wrapper
=
flashinfer
.
mla
.
BatchMLAPagedAttentionWrapper
(
torch
.
empty
(
128
*
1024
*
1024
,
dtype
=
torch
.
int8
),
backend
=
"fa3"
)
mla_wrapper
.
plan
(
q_indptr
,
kv_indptr
,
kv_indices
,
cache_seqlens
,
h_q
,
dv
,
d
-
dv
,
block_size
,
causal
,
1
/
math
.
sqrt
(
d
),
q
.
dtype
,
blocked_k
.
dtype
,
)
def
flashinfer
():
output
,
lse
=
mla_wrapper
.
run
(
q_nope
.
view
(
-
1
,
h_q
,
dv
),
q_pe
.
view
(
-
1
,
h_q
,
d
-
dv
),
blocked_k_nope
,
blocked_k_pe
,
return_lse
=
True
)
return
output
.
view
(
b
,
-
1
,
h_q
,
dv
),
lse
.
view
(
b
,
h_q
,
1
)
out_flash
,
lse_flash
=
flashinfer
()
t
=
triton
.
testing
.
do_bench
(
flashinfer
)
return
out_flash
,
lse_flash
,
t
@
triton
.
jit
def
_mla_attn_kernel
(
Q_nope
,
Q_pe
,
Kv_c_cache
,
K_pe_cache
,
Req_to_tokens
,
B_seq_len
,
O
,
sm_scale
,
stride_q_nope_bs
,
stride_q_nope_h
,
stride_q_pe_bs
,
stride_q_pe_h
,
stride_kv_c_bs
,
stride_k_pe_bs
,
stride_req_to_tokens_bs
,
stride_o_b
,
stride_o_h
,
stride_o_s
,
BLOCK_H
:
tl
.
constexpr
,
BLOCK_N
:
tl
.
constexpr
,
NUM_KV_SPLITS
:
tl
.
constexpr
,
PAGE_SIZE
:
tl
.
constexpr
,
HEAD_DIM_CKV
:
tl
.
constexpr
,
HEAD_DIM_KPE
:
tl
.
constexpr
,
):
cur_batch
=
tl
.
program_id
(
1
)
cur_head_id
=
tl
.
program_id
(
0
)
split_kv_id
=
tl
.
program_id
(
2
)
cur_batch_seq_len
=
tl
.
load
(
B_seq_len
+
cur_batch
)
offs_d_ckv
=
tl
.
arange
(
0
,
HEAD_DIM_CKV
)
cur_head
=
cur_head_id
*
BLOCK_H
+
tl
.
arange
(
0
,
BLOCK_H
)
offs_q_nope
=
cur_batch
*
stride_q_nope_bs
+
cur_head
[:,
None
]
*
stride_q_nope_h
+
offs_d_ckv
[
None
,
:]
q_nope
=
tl
.
load
(
Q_nope
+
offs_q_nope
)
offs_d_kpe
=
tl
.
arange
(
0
,
HEAD_DIM_KPE
)
offs_q_pe
=
cur_batch
*
stride_q_pe_bs
+
cur_head
[:,
None
]
*
stride_q_pe_h
+
offs_d_kpe
[
None
,
:]
q_pe
=
tl
.
load
(
Q_pe
+
offs_q_pe
)
e_max
=
tl
.
zeros
([
BLOCK_H
],
dtype
=
tl
.
float32
)
-
float
(
"inf"
)
e_sum
=
tl
.
zeros
([
BLOCK_H
],
dtype
=
tl
.
float32
)
acc
=
tl
.
zeros
([
BLOCK_H
,
HEAD_DIM_CKV
],
dtype
=
tl
.
float32
)
kv_len_per_split
=
tl
.
cdiv
(
cur_batch_seq_len
,
NUM_KV_SPLITS
)
split_kv_start
=
kv_len_per_split
*
split_kv_id
split_kv_end
=
tl
.
minimum
(
split_kv_start
+
kv_len_per_split
,
cur_batch_seq_len
)
for
start_n
in
range
(
split_kv_start
,
split_kv_end
,
BLOCK_N
):
offs_n
=
start_n
+
tl
.
arange
(
0
,
BLOCK_N
)
kv_page_number
=
tl
.
load
(
Req_to_tokens
+
stride_req_to_tokens_bs
*
cur_batch
+
offs_n
//
PAGE_SIZE
,
mask
=
offs_n
<
split_kv_end
,
other
=
0
,
)
kv_loc
=
kv_page_number
*
PAGE_SIZE
+
offs_n
%
PAGE_SIZE
offs_k_c
=
kv_loc
[
None
,
:]
*
stride_kv_c_bs
+
offs_d_ckv
[:,
None
]
k_c
=
tl
.
load
(
Kv_c_cache
+
offs_k_c
,
mask
=
offs_n
[
None
,
:]
<
split_kv_end
,
other
=
0.0
)
qk
=
tl
.
dot
(
q_nope
,
k_c
.
to
(
q_nope
.
dtype
))
offs_k_pe
=
kv_loc
[
None
,
:]
*
stride_k_pe_bs
+
offs_d_kpe
[:,
None
]
k_pe
=
tl
.
load
(
K_pe_cache
+
offs_k_pe
,
mask
=
offs_n
[
None
,
:]
<
split_kv_end
,
other
=
0.0
)
qk
+=
tl
.
dot
(
q_pe
,
k_pe
.
to
(
q_pe
.
dtype
))
qk
*=
sm_scale
qk
=
tl
.
where
(
offs_n
[
None
,
:]
<
split_kv_end
,
qk
,
float
(
"-inf"
))
v_c
=
tl
.
trans
(
k_c
)
n_e_max
=
tl
.
maximum
(
tl
.
max
(
qk
,
1
),
e_max
)
re_scale
=
tl
.
exp
(
e_max
-
n_e_max
)
p
=
tl
.
exp
(
qk
-
n_e_max
[:,
None
])
acc
*=
re_scale
[:,
None
]
acc
+=
tl
.
dot
(
p
.
to
(
v_c
.
dtype
),
v_c
)
e_sum
=
e_sum
*
re_scale
+
tl
.
sum
(
p
,
1
)
e_max
=
n_e_max
offs_o
=
cur_batch
*
stride_o_b
+
cur_head
[:,
None
]
*
stride_o_h
+
split_kv_id
*
stride_o_s
+
offs_d_ckv
[
None
,
:]
tl
.
store
(
O
+
offs_o
,
acc
/
e_sum
[:,
None
])
offs_o_1
=
cur_batch
*
stride_o_b
+
cur_head
*
stride_o_h
+
split_kv_id
*
stride_o_s
+
HEAD_DIM_CKV
tl
.
store
(
O
+
offs_o_1
,
e_max
+
tl
.
log
(
e_sum
))
def
_mla_attn
(
q_nope
,
q_pe
,
kv_c_cache
,
k_pe_cache
,
attn_logits
,
req_to_tokens
,
b_seq_len
,
num_kv_splits
,
sm_scale
,
page_size
,
):
batch_size
,
head_num
=
q_nope
.
shape
[
0
],
q_nope
.
shape
[
1
]
head_dim_ckv
=
q_nope
.
shape
[
-
1
]
head_dim_kpe
=
q_pe
.
shape
[
-
1
]
BLOCK_H
=
16
BLOCK_N
=
64
grid
=
(
triton
.
cdiv
(
head_num
,
BLOCK_H
),
batch_size
,
num_kv_splits
,
)
_mla_attn_kernel
[
grid
](
q_nope
,
q_pe
,
kv_c_cache
,
k_pe_cache
,
req_to_tokens
,
b_seq_len
,
attn_logits
,
sm_scale
,
# stride
q_nope
.
stride
(
0
),
q_nope
.
stride
(
1
),
q_pe
.
stride
(
0
),
q_pe
.
stride
(
1
),
kv_c_cache
.
stride
(
-
2
),
k_pe_cache
.
stride
(
-
2
),
req_to_tokens
.
stride
(
0
),
attn_logits
.
stride
(
0
),
attn_logits
.
stride
(
1
),
attn_logits
.
stride
(
2
),
BLOCK_H
=
BLOCK_H
,
BLOCK_N
=
BLOCK_N
,
NUM_KV_SPLITS
=
num_kv_splits
,
PAGE_SIZE
=
page_size
,
HEAD_DIM_CKV
=
head_dim_ckv
,
HEAD_DIM_KPE
=
head_dim_kpe
,
)
@
triton
.
jit
def
_mla_softmax_reducev_kernel
(
Logits
,
B_seq_len
,
O
,
stride_l_b
,
stride_l_h
,
stride_l_s
,
stride_o_b
,
stride_o_h
,
NUM_KV_SPLITS
:
tl
.
constexpr
,
HEAD_DIM_CKV
:
tl
.
constexpr
,
):
cur_batch
=
tl
.
program_id
(
0
)
cur_head
=
tl
.
program_id
(
1
)
cur_batch_seq_len
=
tl
.
load
(
B_seq_len
+
cur_batch
)
offs_d_ckv
=
tl
.
arange
(
0
,
HEAD_DIM_CKV
)
e_sum
=
0.0
e_max
=
-
float
(
"inf"
)
acc
=
tl
.
zeros
([
HEAD_DIM_CKV
],
dtype
=
tl
.
float32
)
offs_l
=
cur_batch
*
stride_l_b
+
cur_head
*
stride_l_h
+
offs_d_ckv
offs_l_1
=
cur_batch
*
stride_l_b
+
cur_head
*
stride_l_h
+
HEAD_DIM_CKV
for
split_kv_id
in
range
(
0
,
NUM_KV_SPLITS
):
kv_len_per_split
=
tl
.
cdiv
(
cur_batch_seq_len
,
NUM_KV_SPLITS
)
split_kv_start
=
kv_len_per_split
*
split_kv_id
split_kv_end
=
tl
.
minimum
(
split_kv_start
+
kv_len_per_split
,
cur_batch_seq_len
)
if
split_kv_end
>
split_kv_start
:
logits
=
tl
.
load
(
Logits
+
offs_l
+
split_kv_id
*
stride_l_s
)
logits_1
=
tl
.
load
(
Logits
+
offs_l_1
+
split_kv_id
*
stride_l_s
)
n_e_max
=
tl
.
maximum
(
logits_1
,
e_max
)
old_scale
=
tl
.
exp
(
e_max
-
n_e_max
)
acc
*=
old_scale
exp_logic
=
tl
.
exp
(
logits_1
-
n_e_max
)
acc
+=
exp_logic
*
logits
e_sum
=
e_sum
*
old_scale
+
exp_logic
e_max
=
n_e_max
tl
.
store
(
O
+
cur_batch
*
stride_o_b
+
cur_head
*
stride_o_h
+
offs_d_ckv
,
acc
/
e_sum
,
)
def
_mla_softmax_reducev
(
logits
,
o
,
b_seq_len
,
num_kv_splits
,
):
batch_size
,
head_num
,
head_dim_ckv
=
o
.
shape
[
0
],
o
.
shape
[
1
],
o
.
shape
[
2
]
grid
=
(
batch_size
,
head_num
)
_mla_softmax_reducev_kernel
[
grid
](
logits
,
b_seq_len
,
o
,
logits
.
stride
(
0
),
logits
.
stride
(
1
),
logits
.
stride
(
2
),
o
.
stride
(
0
),
o
.
stride
(
1
),
NUM_KV_SPLITS
=
num_kv_splits
,
HEAD_DIM_CKV
=
head_dim_ckv
,
num_warps
=
4
,
num_stages
=
2
,
)
def
mla_decode_triton
(
q_nope
,
q_pe
,
kv_c_cache
,
k_pe_cache
,
o
,
req_to_tokens
,
b_seq_len
,
attn_logits
,
num_kv_splits
,
sm_scale
,
page_size
,
):
assert
num_kv_splits
==
attn_logits
.
shape
[
2
]
_mla_attn
(
q_nope
,
q_pe
,
kv_c_cache
,
k_pe_cache
,
attn_logits
,
req_to_tokens
,
b_seq_len
,
num_kv_splits
,
sm_scale
,
page_size
,
)
_mla_softmax_reducev
(
attn_logits
,
o
,
b_seq_len
,
num_kv_splits
,
)
@
torch
.
inference_mode
()
def
run_flash_mla_triton
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
):
blocked_v
=
blocked_k
[...,
:
dv
]
assert
d
>
dv
,
"mla with rope dim should be larger than no rope dim"
q_nope
,
q_pe
=
q
[...,
:
dv
].
contiguous
(),
q
[...,
dv
:].
contiguous
()
blocked_k_nope
,
blocked_k_pe
=
blocked_k
[...,
:
dv
].
contiguous
(),
blocked_k
[...,
dv
:].
contiguous
()
def
flash_mla_triton
():
num_kv_splits
=
32
o
=
torch
.
empty
([
b
*
s_q
,
h_q
,
dv
])
attn_logits
=
torch
.
empty
([
b
*
s_q
,
h_q
,
num_kv_splits
,
dv
+
1
])
mla_decode_triton
(
q_nope
.
view
(
-
1
,
h_q
,
dv
),
q_pe
.
view
(
-
1
,
h_q
,
d
-
dv
),
blocked_k_nope
.
view
(
-
1
,
dv
),
blocked_k_pe
.
view
(
-
1
,
d
-
dv
),
o
,
block_table
,
cache_seqlens
,
attn_logits
,
num_kv_splits
,
1
/
math
.
sqrt
(
d
),
block_size
)
return
o
.
view
([
b
,
s_q
,
h_q
,
dv
])
out_flash
=
flash_mla_triton
()
t
=
triton
.
testing
.
do_bench
(
flash_mla_triton
)
return
out_flash
,
None
,
t
@
torch
.
inference_mode
()
def
run_flash_mla_tilelang
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
):
assert
d
>
dv
,
"mla with rope dim should be larger than no rope dim"
q_nope
,
q_pe
=
q
[...,
:
dv
].
contiguous
(),
q
[...,
dv
:].
contiguous
()
blocked_k_nope
,
blocked_k_pe
=
blocked_k
[...,
:
dv
].
contiguous
(),
blocked_k
[...,
dv
:].
contiguous
()
dpe
=
d
-
dv
num_kv_splits
=
1
BLOCK_N
=
64
BLOCK_H
=
64
out_partial
=
torch
.
empty
(
b
,
h_q
,
num_kv_splits
,
dv
,
dtype
=
dtype
,
device
=
q
.
device
)
glse
=
torch
.
empty
(
b
,
h_q
,
num_kv_splits
,
dtype
=
dtype
,
device
=
q
.
device
)
kernel
=
mla_decode_tilelang
(
b
,
h_q
,
h_kv
,
max_seqlen_pad
,
dv
,
dpe
,
BLOCK_N
,
BLOCK_H
,
num_kv_splits
,
block_size
)
def
flash_mla_tilelang
():
out
=
kernel
(
q_nope
.
view
(
-
1
,
h_q
,
dv
),
q_pe
.
view
(
-
1
,
h_q
,
dpe
),
blocked_k_nope
.
view
(
-
1
,
h_kv
,
dv
),
blocked_k_pe
.
view
(
-
1
,
h_kv
,
dpe
),
block_table
,
cache_seqlens
,
glse
,
out_partial
,
)
return
out
.
view
([
b
,
s_q
,
h_q
,
dv
])
out_flash
=
flash_mla_tilelang
()
t
=
do_bench
(
flash_mla_tilelang
)
return
out_flash
,
None
,
t
FUNC_TABLE
=
{
"torch"
:
run_torch_mla
,
"tilelang"
:
run_flash_mla_tilelang
,
"flash_mla"
:
run_flash_mla
,
"flashinfer"
:
run_flashinfer
,
"flash_mla_triton"
:
run_flash_mla_triton
,
}
def
compare_ab
(
baseline
,
target
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
):
print
(
f
"comparing
{
baseline
}
vs
{
target
}
:
{
b
=
}
,
{
s_q
=
}
, mean_seqlens=
{
cache_seqlens
.
float
().
mean
()
}
,
{
h_q
=
}
,
{
h_kv
=
}
,
{
d
=
}
,
{
dv
=
}
,
{
causal
=
}
,
{
dtype
=
}
"
)
device
=
torch
.
device
(
"cuda:0"
)
torch
.
set_default_dtype
(
dtype
)
torch
.
set_default_device
(
device
)
torch
.
cuda
.
set_device
(
device
)
torch
.
manual_seed
(
0
)
random
.
seed
(
0
)
assert
baseline
in
FUNC_TABLE
assert
target
in
FUNC_TABLE
baseline_func
=
FUNC_TABLE
[
baseline
]
target_func
=
FUNC_TABLE
[
target
]
total_seqlens
=
cache_seqlens
.
sum
().
item
()
max_seqlen
=
cache_seqlens
.
max
().
item
()
max_seqlen_pad
=
triton
.
cdiv
(
max_seqlen
,
256
)
*
256
# print(f"{total_seqlens=}, {mean_seqlens=}, {max_seqlen=}")
q
=
torch
.
randn
(
b
,
s_q
,
h_q
,
d
)
block_size
=
64
block_table
=
torch
.
arange
(
b
*
max_seqlen_pad
//
block_size
,
dtype
=
torch
.
int32
).
view
(
b
,
max_seqlen_pad
//
block_size
)
blocked_k
=
torch
.
randn
(
block_table
.
numel
(),
block_size
,
h_kv
,
d
)
out_a
,
lse_a
,
perf_a
=
baseline_func
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
)
out_b
,
lse_b
,
perf_b
=
target_func
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
)
torch
.
testing
.
assert_close
(
out_b
.
float
(),
out_a
.
float
(),
atol
=
1e-2
,
rtol
=
1e-2
),
"out"
if
target
not
in
[
"flashinfer"
,
"flash_mla_triton"
,
"tilelang"
]
and
baseline
not
in
[
"flashinfer"
,
"flash_mla_triton"
,
"tilelang"
]:
# flashinfer has a different lse return value
# flash_mla_triton and flash_mla_tilelang doesn't return lse
torch
.
testing
.
assert_close
(
lse_b
.
float
(),
lse_a
.
float
(),
atol
=
1e-2
,
rtol
=
1e-2
),
"lse"
FLOPS
=
s_q
*
total_seqlens
*
h_q
*
(
d
+
dv
)
*
2
bytes
=
(
total_seqlens
*
h_kv
*
d
+
b
*
s_q
*
h_q
*
d
+
b
*
s_q
*
h_q
*
dv
)
*
(
torch
.
finfo
(
dtype
).
bits
//
8
)
print
(
f
"perf
{
baseline
}
:
{
perf_a
:.
3
f
}
ms,
{
FLOPS
/
10
**
9
/
perf_a
:.
0
f
}
TFLOPS,
{
bytes
/
10
**
6
/
perf_a
:.
0
f
}
GB/s"
)
print
(
f
"perf
{
target
}
:
{
perf_b
:.
3
f
}
ms,
{
FLOPS
/
10
**
9
/
perf_b
:.
0
f
}
TFLOPS,
{
bytes
/
10
**
6
/
perf_b
:.
0
f
}
GB/s"
)
return
bytes
/
10
**
6
/
perf_a
,
bytes
/
10
**
6
/
perf_b
def
compare_a
(
target
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
):
print
(
f
"
{
target
}
:
{
b
=
}
,
{
s_q
=
}
, mean_seqlens=
{
cache_seqlens
.
float
().
mean
()
}
,
{
h_q
=
}
,
{
h_kv
=
}
,
{
d
=
}
,
{
dv
=
}
,
{
causal
=
}
,
{
dtype
=
}
"
)
torch
.
set_default_dtype
(
dtype
)
device
=
torch
.
device
(
"cuda:0"
)
torch
.
set_default_device
(
device
)
torch
.
cuda
.
set_device
(
device
)
torch
.
manual_seed
(
0
)
random
.
seed
(
0
)
assert
target
in
FUNC_TABLE
target_func
=
FUNC_TABLE
[
target
]
total_seqlens
=
cache_seqlens
.
sum
().
item
()
max_seqlen
=
cache_seqlens
.
max
().
item
()
max_seqlen_pad
=
triton
.
cdiv
(
max_seqlen
,
256
)
*
256
# print(f"{total_seqlens=}, {mean_seqlens=}, {max_seqlen=}")
q
=
torch
.
randn
(
b
,
s_q
,
h_q
,
d
)
block_size
=
64
block_table
=
torch
.
arange
(
b
*
max_seqlen_pad
//
block_size
,
dtype
=
torch
.
int32
).
view
(
b
,
max_seqlen_pad
//
block_size
)
blocked_k
=
torch
.
randn
(
block_table
.
numel
(),
block_size
,
h_kv
,
d
)
out_b
,
lse_b
,
perf_b
=
target_func
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
)
FLOPS
=
s_q
*
total_seqlens
*
h_q
*
(
d
+
dv
)
*
2
bytes
=
(
total_seqlens
*
h_kv
*
d
+
b
*
s_q
*
h_q
*
d
+
b
*
s_q
*
h_q
*
dv
)
*
(
torch
.
finfo
(
dtype
).
bits
//
8
)
print
(
f
"perf
{
target
}
:
{
perf_b
:.
3
f
}
ms,
{
FLOPS
/
10
**
9
/
perf_b
:.
0
f
}
TFLOPS,
{
bytes
/
10
**
6
/
perf_b
:.
0
f
}
GB/s"
)
return
bytes
/
10
**
6
/
perf_b
available_targets
=
[
"torch"
,
"tilelang"
,
"flash_mla"
,
"flashinfer"
,
"flash_mla_triton"
,
]
shape_configs
=
[{
"b"
:
batch
,
"s_q"
:
1
,
"cache_seqlens"
:
torch
.
tensor
([
seqlen
+
2
*
i
for
i
in
range
(
batch
)],
dtype
=
torch
.
int32
,
device
=
"cuda"
),
"h_q"
:
head
,
"h_kv"
:
1
,
"d"
:
512
+
64
,
"dv"
:
512
,
"causal"
:
True
,
"dtype"
:
torch
.
float16
}
for
batch
in
[
128
]
for
seqlen
in
[
1024
,
2048
,
4096
,
8192
,
16384
,
32768
]
for
head
in
[
128
]]
def
get_args
():
parser
=
argparse
.
ArgumentParser
()
parser
.
add_argument
(
"--baseline"
,
type
=
str
,
default
=
"torch"
)
parser
.
add_argument
(
"--target"
,
type
=
str
,
default
=
"tilelang"
)
parser
.
add_argument
(
"--all"
,
action
=
"store_true"
)
parser
.
add_argument
(
"--one"
,
action
=
"store_true"
)
parser
.
add_argument
(
"--compare"
,
action
=
"store_true"
)
args
=
parser
.
parse_args
()
return
args
if
__name__
==
"__main__"
:
args
=
get_args
()
benchmark_type
=
"all"
if
args
.
all
else
f
"
{
args
.
baseline
}
_vs_
{
args
.
target
}
"
if
args
.
compare
else
args
.
target
with
open
(
f
"
{
benchmark_type
}
_perf.csv"
,
"w"
)
as
fout
:
fout
.
write
(
"name,batch,seqlen,head,bw
\n
"
)
for
shape
in
shape_configs
:
if
args
.
all
:
for
target
in
available_targets
:
perf
=
compare_a
(
target
,
shape
[
"b"
],
shape
[
"s_q"
],
shape
[
"cache_seqlens"
],
shape
[
"h_q"
],
shape
[
"h_kv"
],
shape
[
"d"
],
shape
[
"dv"
],
shape
[
"causal"
],
shape
[
"dtype"
])
fout
.
write
(
f
'
{
target
}
,
{
shape
[
"b"
]
}
,
{
shape
[
"cache_seqlens"
].
float
().
mean
().
cpu
().
item
():.
0
f
}
,
{
shape
[
"h_q"
]
}
,
{
perf
:.
0
f
}
\n
'
)
elif
args
.
compare
:
perfa
,
prefb
=
compare_ab
(
args
.
baseline
,
args
.
target
,
shape
[
"b"
],
shape
[
"s_q"
],
shape
[
"cache_seqlens"
],
shape
[
"h_q"
],
shape
[
"h_kv"
],
shape
[
"d"
],
shape
[
"dv"
],
shape
[
"causal"
],
shape
[
"dtype"
])
fout
.
write
(
f
'
{
args
.
baseline
}
,
{
shape
[
"b"
]
}
,
{
shape
[
"cache_seqlens"
].
float
().
mean
().
cpu
().
item
():.
0
f
}
,
{
shape
[
"h_q"
]
}
,
{
perfa
:.
0
f
}
\n
'
)
fout
.
write
(
f
'
{
args
.
target
}
,
{
shape
[
"b"
]
}
,
{
shape
[
"cache_seqlens"
].
float
().
mean
().
cpu
().
item
():.
0
f
}
,
{
shape
[
"h_q"
]
}
,
{
prefb
:.
0
f
}
\n
'
)
elif
args
.
one
:
perf
=
compare_a
(
args
.
target
,
shape
[
"b"
],
shape
[
"s_q"
],
shape
[
"cache_seqlens"
],
shape
[
"h_q"
],
shape
[
"h_kv"
],
shape
[
"d"
],
shape
[
"dv"
],
shape
[
"causal"
],
shape
[
"dtype"
])
fout
.
write
(
f
'
{
args
.
target
}
,
{
shape
[
"b"
]
}
,
{
shape
[
"cache_seqlens"
].
float
().
mean
().
cpu
().
item
():.
0
f
}
,
{
shape
[
"h_q"
]
}
,
{
perf
:.
0
f
}
\n
'
)
examples/deepseek_mla/example_mla_decode.py
0 → 100644
View file @
bc2d5632
import
torch
import
torch.nn.functional
as
F
import
tilelang
from
tilelang.autotuner
import
*
import
tilelang.language
as
T
from
einops
import
rearrange
,
einsum
import
argparse
@
tilelang
.
jit
(
out_idx
=
[
6
],
pass_configs
=
{
tilelang
.
PassConfigKey
.
TL_ENABLE_FAST_MATH
:
True
,
})
def
flashattn
(
batch
,
heads
,
kv_head_num
,
seqlen_kv
,
dim
,
pe_dim
,
block_N
,
block_H
,
num_split
,
softmax_scale
):
scale
=
float
(
softmax_scale
*
1.44269504
)
# log2(e)
dtype
=
"float16"
accum_dtype
=
"float"
kv_group_num
=
heads
//
kv_head_num
VALID_BLOCK_H
=
min
(
block_H
,
kv_group_num
)
assert
kv_head_num
==
1
,
"kv_head_num must be 1"
@
T
.
macro
def
flash_attn
(
Q
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
Q_pe
:
T
.
Tensor
([
batch
,
heads
,
pe_dim
],
dtype
),
KV
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
dim
],
dtype
),
K_pe
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
pe_dim
],
dtype
),
Output
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
):
with
T
.
Kernel
(
heads
//
min
(
block_H
,
kv_group_num
),
batch
,
threads
=
256
)
as
(
hid
,
bid
):
Q_shared
=
T
.
alloc_shared
([
block_H
,
dim
],
dtype
)
S_shared
=
T
.
alloc_shared
([
block_H
,
block_N
],
dtype
)
Q_pe_shared
=
T
.
alloc_shared
([
block_H
,
pe_dim
],
dtype
)
KV_shared
=
T
.
alloc_shared
([
block_N
,
dim
],
dtype
)
K_pe_shared
=
T
.
alloc_shared
([
block_N
,
pe_dim
],
dtype
)
O_shared
=
T
.
alloc_shared
([
block_H
,
dim
],
dtype
)
acc_s
=
T
.
alloc_fragment
([
block_H
,
block_N
],
accum_dtype
)
acc_o
=
T
.
alloc_fragment
([
block_H
,
dim
],
accum_dtype
)
scores_max
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_max_prev
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_scale
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_sum
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
logsum
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
cur_kv_head
=
hid
//
(
kv_group_num
//
block_H
)
T
.
annotate_layout
({
O_shared
:
tilelang
.
layout
.
make_swizzled_layout
(
O_shared
),
})
T
.
copy
(
Q
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
:],
Q_shared
)
T
.
copy
(
Q_pe
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
:],
Q_pe_shared
)
T
.
fill
(
acc_o
,
0
)
T
.
fill
(
logsum
,
0
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
loop_range
=
T
.
ceildiv
(
seqlen_kv
,
block_N
)
for
k
in
T
.
Pipelined
(
loop_range
,
num_stages
=
2
):
T
.
copy
(
KV
[
bid
,
k
*
block_N
:(
k
+
1
)
*
block_N
,
cur_kv_head
,
:],
KV_shared
)
T
.
copy
(
K_pe
[
bid
,
k
*
block_N
:(
k
+
1
)
*
block_N
,
cur_kv_head
,
:],
K_pe_shared
)
T
.
gemm
(
Q_shared
,
KV_shared
,
acc_s
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
,
clear_accum
=
True
)
T
.
gemm
(
Q_pe_shared
,
K_pe_shared
,
acc_s
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
)
T
.
copy
(
scores_max
,
scores_max_prev
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
T
.
reduce_max
(
acc_s
,
scores_max
,
dim
=
1
,
clear
=
False
)
for
i
in
T
.
Parallel
(
block_H
):
scores_scale
[
i
]
=
T
.
exp2
(
scores_max_prev
[
i
]
*
scale
-
scores_max
[
i
]
*
scale
)
for
i
,
j
in
T
.
Parallel
(
block_H
,
block_N
):
acc_s
[
i
,
j
]
=
T
.
exp2
(
acc_s
[
i
,
j
]
*
scale
-
scores_max
[
i
]
*
scale
)
T
.
reduce_sum
(
acc_s
,
scores_sum
,
dim
=
1
)
T
.
copy
(
acc_s
,
S_shared
)
for
i
in
T
.
Parallel
(
block_H
):
logsum
[
i
]
=
logsum
[
i
]
*
scores_scale
[
i
]
+
scores_sum
[
i
]
for
i
,
j
in
T
.
Parallel
(
block_H
,
dim
):
acc_o
[
i
,
j
]
*=
scores_scale
[
i
]
T
.
gemm
(
S_shared
,
KV_shared
,
acc_o
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
)
for
i
,
j
in
T
.
Parallel
(
block_H
,
dim
):
acc_o
[
i
,
j
]
/=
logsum
[
i
]
T
.
copy
(
acc_o
,
O_shared
)
T
.
copy
(
O_shared
,
Output
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
:])
@
T
.
macro
def
flash_attn_split
(
Q
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
Q_pe
:
T
.
Tensor
([
batch
,
heads
,
pe_dim
],
dtype
),
KV
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
dim
],
dtype
),
K_pe
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
pe_dim
],
dtype
),
glse
:
T
.
Tensor
([
batch
,
heads
,
num_split
],
dtype
),
Output_partial
:
T
.
Tensor
([
batch
,
heads
,
num_split
,
dim
],
dtype
),
):
with
T
.
Kernel
(
batch
,
heads
//
min
(
block_H
,
kv_group_num
),
num_split
,
threads
=
256
)
as
(
bid
,
hid
,
bz
):
Q_shared
=
T
.
alloc_shared
([
block_H
,
dim
],
dtype
)
S_shared
=
T
.
alloc_shared
([
block_H
,
block_N
],
dtype
)
Q_pe_shared
=
T
.
alloc_shared
([
block_H
,
pe_dim
],
dtype
)
KV_shared
=
T
.
alloc_shared
([
block_N
,
dim
],
dtype
)
K_pe_shared
=
T
.
alloc_shared
([
block_N
,
pe_dim
],
dtype
)
O_shared
=
T
.
alloc_shared
([
block_H
,
dim
],
dtype
)
acc_s
=
T
.
alloc_fragment
([
block_H
,
block_N
],
accum_dtype
)
acc_s_cast
=
T
.
alloc_fragment
([
block_H
,
block_N
],
dtype
)
acc_o
=
T
.
alloc_fragment
([
block_H
,
dim
],
accum_dtype
)
scores_max
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_max_prev
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_scale
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_sum
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
logsum
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
cur_kv_head
=
hid
//
(
kv_group_num
//
block_H
)
T
.
use_swizzle
(
10
)
T
.
annotate_layout
({
O_shared
:
tilelang
.
layout
.
make_swizzled_layout
(
O_shared
),
S_shared
:
tilelang
.
layout
.
make_swizzled_layout
(
S_shared
),
})
T
.
copy
(
Q
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
:],
Q_shared
)
T
.
copy
(
Q_pe
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
:],
Q_pe_shared
)
T
.
fill
(
acc_o
,
0
)
T
.
fill
(
logsum
,
0
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
loop_range
=
T
.
ceildiv
((
seqlen_kv
//
num_split
),
block_N
)
for
k
in
T
.
Pipelined
(
loop_range
,
num_stages
=
2
):
kv_start
=
(
seqlen_kv
//
num_split
)
*
bz
+
k
*
block_N
kv_end
=
(
seqlen_kv
//
num_split
)
*
bz
+
(
k
+
1
)
*
block_N
T
.
copy
(
KV
[
bid
,
kv_start
:
kv_end
,
cur_kv_head
,
:],
KV_shared
)
T
.
copy
(
K_pe
[
bid
,
kv_start
:
kv_end
,
cur_kv_head
,
:],
K_pe_shared
)
T
.
clear
(
acc_s
)
T
.
gemm
(
Q_shared
,
KV_shared
,
acc_s
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
)
T
.
gemm
(
Q_pe_shared
,
K_pe_shared
,
acc_s
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
)
T
.
copy
(
scores_max
,
scores_max_prev
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
T
.
reduce_max
(
acc_s
,
scores_max
,
dim
=
1
,
clear
=
False
)
for
i
in
T
.
Parallel
(
block_H
):
scores_scale
[
i
]
=
T
.
exp2
(
scores_max_prev
[
i
]
*
scale
-
scores_max
[
i
]
*
scale
)
for
i
,
j
in
T
.
Parallel
(
block_H
,
block_N
):
acc_s
[
i
,
j
]
=
T
.
exp2
(
acc_s
[
i
,
j
]
*
scale
-
scores_max
[
i
]
*
scale
)
T
.
reduce_sum
(
acc_s
,
scores_sum
,
dim
=
1
)
T
.
copy
(
acc_s
,
S_shared
)
T
.
copy
(
S_shared
,
acc_s_cast
)
for
i
in
T
.
Parallel
(
block_H
):
logsum
[
i
]
=
logsum
[
i
]
*
scores_scale
[
i
]
+
scores_sum
[
i
]
for
i
,
j
in
T
.
Parallel
(
block_H
,
dim
):
acc_o
[
i
,
j
]
*=
scores_scale
[
i
]
T
.
gemm
(
acc_s_cast
,
KV_shared
,
acc_o
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
)
for
i
,
j
in
T
.
Parallel
(
block_H
,
dim
):
acc_o
[
i
,
j
]
/=
logsum
[
i
]
for
i
in
T
.
Parallel
(
block_H
):
logsum
[
i
]
=
T
.
log2
(
logsum
[
i
])
+
scores_max
[
i
]
*
scale
T
.
copy
(
logsum
,
glse
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
bz
])
T
.
copy
(
acc_o
,
O_shared
)
T
.
copy
(
O_shared
,
Output_partial
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
bz
,
:])
@
T
.
macro
def
combine
(
glse
:
T
.
Tensor
([
batch
,
heads
,
num_split
],
dtype
),
Output_partial
:
T
.
Tensor
([
batch
,
heads
,
num_split
,
dim
],
dtype
),
Output
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
):
with
T
.
Kernel
(
heads
,
batch
,
threads
=
128
)
as
(
hid
,
bz
):
po_local
=
T
.
alloc_fragment
([
dim
],
dtype
)
o_accum_local
=
T
.
alloc_fragment
([
dim
],
accum_dtype
)
lse_local_split
=
T
.
alloc_local
([
1
],
accum_dtype
)
lse_logsum_local
=
T
.
alloc_local
([
1
],
accum_dtype
)
lse_max_local
=
T
.
alloc_local
([
1
],
accum_dtype
)
scale_local
=
T
.
alloc_local
([
1
],
accum_dtype
)
T
.
annotate_layout
({
lse_logsum_local
:
T
.
Fragment
(
lse_logsum_local
.
shape
,
forward_thread_fn
=
lambda
i
:
i
),
})
T
.
clear
(
lse_logsum_local
)
T
.
clear
(
o_accum_local
)
lse_max_local
[
0
]
=
-
T
.
infinity
(
accum_dtype
)
for
k
in
T
.
serial
(
num_split
):
lse_max_local
[
0
]
=
T
.
max
(
lse_max_local
[
0
],
glse
[
bz
,
hid
,
k
])
for
k
in
T
.
Pipelined
(
num_split
,
num_stages
=
1
):
lse_local_split
[
0
]
=
glse
[
bz
,
hid
,
k
]
lse_logsum_local
[
0
]
+=
T
.
exp2
(
lse_local_split
[
0
]
-
lse_max_local
[
0
])
lse_logsum_local
[
0
]
=
T
.
log2
(
lse_logsum_local
[
0
])
+
lse_max_local
[
0
]
for
k
in
T
.
serial
(
num_split
):
for
i
in
T
.
Parallel
(
dim
):
po_local
[
i
]
=
Output_partial
[
bz
,
hid
,
k
,
i
]
lse_local_split
[
0
]
=
glse
[
bz
,
hid
,
k
]
scale_local
[
0
]
=
T
.
exp2
(
lse_local_split
[
0
]
-
lse_logsum_local
[
0
])
for
i
in
T
.
Parallel
(
dim
):
o_accum_local
[
i
]
+=
po_local
[
i
]
*
scale_local
[
0
]
for
i
in
T
.
Parallel
(
dim
):
Output
[
bz
,
hid
,
i
]
=
o_accum_local
[
i
]
@
T
.
prim_func
def
main_split
(
Q
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
Q_pe
:
T
.
Tensor
([
batch
,
heads
,
pe_dim
],
dtype
),
KV
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
dim
],
dtype
),
K_pe
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
pe_dim
],
dtype
),
glse
:
T
.
Tensor
([
batch
,
heads
,
num_split
],
dtype
),
Output_partial
:
T
.
Tensor
([
batch
,
heads
,
num_split
,
dim
],
dtype
),
Output
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
):
flash_attn_split
(
Q
,
Q_pe
,
KV
,
K_pe
,
glse
,
Output_partial
)
combine
(
glse
,
Output_partial
,
Output
)
@
T
.
prim_func
def
main_no_split
(
Q
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
Q_pe
:
T
.
Tensor
([
batch
,
heads
,
pe_dim
],
dtype
),
KV
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
dim
],
dtype
),
K_pe
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
pe_dim
],
dtype
),
glse
:
T
.
Tensor
([
batch
,
heads
,
num_split
],
dtype
),
Output_partial
:
T
.
Tensor
([
batch
,
heads
,
num_split
,
dim
],
dtype
),
Output
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
):
flash_attn
(
Q
,
Q_pe
,
KV
,
K_pe
,
Output
)
if
num_split
>
1
:
return
main_split
else
:
return
main_no_split
def
ref_program
(
q
,
q_pe
,
kv
,
k_pe
,
glse
,
Output_partial
):
# """
# Inputs:
# - q (Tensor): [batch, heads, dim]
# - q_pe (Tensor): [batch, heads, pe_dim]
# - kv (Tensor): [batch, seqlen_kv, kv_head_num, dim]
# - k_pe (Tensor): [batch, seqlen_kv, kv_head_num, pe_dim]
# - glse (Tensor): [batch, heads, num_split]
# - Output_partial (Tensor): [batch, heads, num_split, dim]
# Outputs:
# - output (Tensor): [batch, heads, dim]
# """
dim
=
q
.
shape
[
-
1
]
pe_dim
=
q_pe
.
shape
[
-
1
]
num_head_groups
=
q
.
shape
[
1
]
//
kv
.
shape
[
2
]
scale
=
(
dim
+
pe_dim
)
**
0.5
q
=
rearrange
(
q
,
'b (h g) d -> b g h d'
,
g
=
num_head_groups
)
# [batch_size, num_head_groups, groups, dim]
q_pe
=
rearrange
(
q_pe
,
'b (h g) d -> b g h d'
,
g
=
num_head_groups
)
# [batch_size, num_head_groups, groups, pe_dim]
kv
=
rearrange
(
kv
,
'b n h d -> b h n d'
)
# [batch_size, groups, seqlen_kv, dim]
k_pe
=
rearrange
(
k_pe
,
'b n h d -> b h n d'
)
# [batch_size, num_head_groups, groups, pe_dim]
query
=
torch
.
concat
([
q
,
q_pe
],
dim
=-
1
)
key
=
torch
.
concat
([
kv
,
k_pe
],
dim
=-
1
)
scores
=
einsum
(
query
,
key
,
'b g h d, b h s d -> b g h s'
)
# [batch_size, num_head_groups, groups, seqlen_kv]
attention
=
F
.
softmax
(
scores
/
scale
,
dim
=-
1
)
# [batch_size, num_head_groups, groups, seqlen_kv]
out
=
einsum
(
attention
,
kv
,
'b g h s, b h s d -> b g h d'
)
# [batch_size, num_head_groups, groups, dim]
out
=
rearrange
(
out
,
'b g h d -> b (h g) d'
)
# [batch_size, heads, dim]
return
out
def
main
(
batch
=
1
,
heads
=
128
,
kv_heads
=
1
,
kv_ctx
=
8192
,
dim
=
512
,
pe_dim
=
64
,
):
qk_flops
=
2
*
batch
*
heads
*
kv_ctx
*
(
dim
+
pe_dim
)
pv_flops
=
2
*
batch
*
heads
*
kv_ctx
*
dim
total_flops
=
qk_flops
+
pv_flops
BLOCK_N
=
64
BLOCK_H
=
min
(
64
,
heads
//
kv_heads
)
num_split
=
1
softmax_scale
=
(
dim
+
pe_dim
)
**-
0.5
kernel
=
flashattn
(
batch
,
heads
,
kv_heads
,
kv_ctx
,
dim
,
pe_dim
,
BLOCK_N
,
BLOCK_H
,
num_split
,
softmax_scale
)
profiler
=
kernel
.
get_profiler
(
tensor_supply_type
=
tilelang
.
TensorSupplyType
.
Randn
)
profiler
.
assert_allclose
(
ref_program
,
rtol
=
1e-4
,
atol
=
1e-4
)
latency
=
profiler
.
do_bench
(
warmup
=
500
)
print
(
f
"Latency:
{
latency
}
ms"
)
print
(
f
"TFlops:
{
total_flops
/
latency
*
1e-9
}
TFlops"
)
if
__name__
==
"__main__"
:
parser
=
argparse
.
ArgumentParser
()
parser
.
add_argument
(
'--batch'
,
type
=
int
,
default
=
132
,
help
=
'batch size'
)
parser
.
add_argument
(
'--heads'
,
type
=
int
,
default
=
128
,
help
=
'q heads number'
)
parser
.
add_argument
(
'--kv_heads'
,
type
=
int
,
default
=
1
,
help
=
'kv heads number'
)
parser
.
add_argument
(
'--kv_ctx'
,
type
=
int
,
default
=
8192
,
help
=
'kv context length'
)
parser
.
add_argument
(
'--dim'
,
type
=
int
,
default
=
512
,
help
=
'head dim'
)
parser
.
add_argument
(
'--pe_dim'
,
type
=
int
,
default
=
64
,
help
=
'pe head dim'
)
args
=
parser
.
parse_args
()
batch
,
heads
,
kv_heads
,
kv_ctx
,
dim
,
pe_dim
=
args
.
batch
,
args
.
heads
,
args
.
kv_heads
,
args
.
kv_ctx
,
args
.
dim
,
args
.
pe_dim
main
(
batch
,
heads
,
kv_heads
,
kv_ctx
,
dim
,
pe_dim
)
examples/deepseek_mla/example_mla_decode_paged.py
0 → 100644
View file @
bc2d5632
import
torch
import
tilelang
from
tilelang.autotuner
import
*
import
tilelang.language
as
T
import
argparse
from
tilelang.profiler
import
do_bench
import
math
@
tilelang
.
jit
(
out_idx
=
[
8
],
pass_configs
=
{
tilelang
.
PassConfigKey
.
TL_ENABLE_FAST_MATH
:
True
,
})
def
mla_decode_tilelang
(
batch
,
h_q
,
h_kv
,
max_seqlen_pad
,
dv
,
dpe
,
block_N
,
block_H
,
num_split
,
block_size
,
softmax_scale
=
None
):
if
softmax_scale
is
None
:
softmax_scale
=
(
dv
+
dpe
)
**-
0.5
scale
=
float
(
softmax_scale
*
1.44269504
)
# log2(e)
dtype
=
"float16"
accum_dtype
=
"float"
kv_group_num
=
h_q
//
h_kv
VALID_BLOCK_H
=
min
(
block_H
,
kv_group_num
)
assert
h_kv
==
1
,
"h_kv must be 1"
assert
block_size
>=
block_N
and
block_size
%
block_N
==
0
,
"block_size must be larger than block_N and a multiple of block_N"
@
T
.
macro
def
flash_mla_kernel
(
Q
:
T
.
Tensor
([
batch
,
h_q
,
dv
],
dtype
),
Q_pe
:
T
.
Tensor
([
batch
,
h_q
,
dpe
],
dtype
),
KV
:
T
.
Tensor
([
batch
*
max_seqlen_pad
,
h_kv
,
dv
],
dtype
),
K_pe
:
T
.
Tensor
([
batch
*
max_seqlen_pad
,
h_kv
,
dpe
],
dtype
),
BLOCK_TABLE
:
T
.
Tensor
([
batch
,
max_seqlen_pad
//
block_size
],
"int32"
),
CACHE_SEQLENS
:
T
.
Tensor
([
batch
],
"int32"
),
Output
:
T
.
Tensor
([
batch
,
h_q
,
dv
],
dtype
),
):
with
T
.
Kernel
(
batch
,
h_q
//
min
(
block_H
,
kv_group_num
),
threads
=
256
)
as
(
bx
,
by
):
Q_shared
=
T
.
alloc_shared
([
block_H
,
dv
],
dtype
)
S_shared
=
T
.
alloc_shared
([
block_H
,
block_N
],
dtype
)
Q_pe_shared
=
T
.
alloc_shared
([
block_H
,
dpe
],
dtype
)
KV_shared
=
T
.
alloc_shared
([
block_N
,
dv
],
dtype
)
K_pe_shared
=
T
.
alloc_shared
([
block_N
,
dpe
],
dtype
)
O_shared
=
T
.
alloc_shared
([
block_H
,
dv
],
dtype
)
acc_s
=
T
.
alloc_fragment
([
block_H
,
block_N
],
accum_dtype
)
acc_o
=
T
.
alloc_fragment
([
block_H
,
dv
],
accum_dtype
)
scores_max
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_max_prev
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_scale
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_sum
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
logsum
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
cur_kv_head
=
by
//
(
kv_group_num
//
block_H
)
T
.
use_swizzle
(
10
)
T
.
annotate_layout
({
O_shared
:
tilelang
.
layout
.
make_swizzled_layout
(
O_shared
),
S_shared
:
tilelang
.
layout
.
make_swizzled_layout
(
S_shared
),
})
T
.
copy
(
Q
[
bx
,
by
*
VALID_BLOCK_H
:(
by
+
1
)
*
VALID_BLOCK_H
,
:],
Q_shared
)
T
.
copy
(
Q_pe
[
bx
,
by
*
VALID_BLOCK_H
:(
by
+
1
)
*
VALID_BLOCK_H
,
:],
Q_pe_shared
)
T
.
fill
(
acc_o
,
0
)
T
.
fill
(
logsum
,
0
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
loop_range
=
T
.
ceildiv
(
CACHE_SEQLENS
[
bx
],
block_N
)
for
kr
in
T
.
Pipelined
(
loop_range
,
num_stages
=
2
):
k
=
loop_range
-
1
-
kr
kv_start
=
BLOCK_TABLE
[
bx
,
(
k
*
block_N
)
//
block_size
]
*
block_size
+
(
k
*
block_N
)
%
block_size
T
.
copy
(
KV
[
kv_start
:
kv_start
+
block_N
,
cur_kv_head
,
:],
KV_shared
)
T
.
copy
(
K_pe
[
kv_start
:
kv_start
+
block_N
,
cur_kv_head
,
:],
K_pe_shared
)
T
.
clear
(
acc_s
)
T
.
gemm
(
Q_shared
,
KV_shared
,
acc_s
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
)
T
.
gemm
(
Q_pe_shared
,
K_pe_shared
,
acc_s
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
)
T
.
copy
(
scores_max
,
scores_max_prev
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
if
kr
==
0
:
for
i
,
j
in
T
.
Parallel
(
block_H
,
block_N
):
acc_s
[
i
,
j
]
=
T
.
if_then_else
(
k
*
block_N
+
j
>=
CACHE_SEQLENS
[
bx
],
-
T
.
infinity
(
accum_dtype
),
acc_s
[
i
,
j
])
T
.
reduce_max
(
acc_s
,
scores_max
,
dim
=
1
,
clear
=
False
)
for
i
in
T
.
Parallel
(
block_H
):
scores_scale
[
i
]
=
T
.
exp2
(
scores_max_prev
[
i
]
*
scale
-
scores_max
[
i
]
*
scale
)
for
i
,
j
in
T
.
Parallel
(
block_H
,
block_N
):
acc_s
[
i
,
j
]
=
T
.
exp2
(
acc_s
[
i
,
j
]
*
scale
-
scores_max
[
i
]
*
scale
)
T
.
reduce_sum
(
acc_s
,
scores_sum
,
dim
=
1
)
T
.
copy
(
acc_s
,
S_shared
)
for
i
in
T
.
Parallel
(
block_H
):
logsum
[
i
]
=
logsum
[
i
]
*
scores_scale
[
i
]
+
scores_sum
[
i
]
for
i
,
j
in
T
.
Parallel
(
block_H
,
dv
):
acc_o
[
i
,
j
]
*=
scores_scale
[
i
]
T
.
gemm
(
S_shared
,
KV_shared
,
acc_o
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
)
for
i
,
j
in
T
.
Parallel
(
block_H
,
dv
):
acc_o
[
i
,
j
]
/=
logsum
[
i
]
T
.
copy
(
acc_o
,
O_shared
)
T
.
copy
(
O_shared
,
Output
[
bx
,
by
*
VALID_BLOCK_H
:(
by
+
1
)
*
VALID_BLOCK_H
,
:])
@
T
.
macro
def
flash_mla_split_kv_kernel
(
Q
:
T
.
Tensor
([
batch
,
h_q
,
dv
],
dtype
),
Q_pe
:
T
.
Tensor
([
batch
,
h_q
,
dpe
],
dtype
),
KV
:
T
.
Tensor
([
batch
*
max_seqlen_pad
,
h_kv
,
dv
],
dtype
),
K_pe
:
T
.
Tensor
([
batch
*
max_seqlen_pad
,
h_kv
,
dpe
],
dtype
),
BLOCK_TABLE
:
T
.
Tensor
([
batch
,
max_seqlen_pad
//
block_size
],
"int32"
),
CACHE_SEQLENS
:
T
.
Tensor
([
batch
],
"int32"
),
glse
:
T
.
Tensor
([
batch
,
h_q
,
num_split
],
dtype
),
Output_partial
:
T
.
Tensor
([
batch
,
h_q
,
num_split
,
dv
],
dtype
),
):
with
T
.
Kernel
(
batch
,
h_q
//
min
(
block_H
,
kv_group_num
),
num_split
,
threads
=
256
)
as
(
bx
,
by
,
bz
):
Q_shared
=
T
.
alloc_shared
([
block_H
,
dv
],
dtype
)
S_shared
=
T
.
alloc_shared
([
block_H
,
block_N
],
dtype
)
Q_pe_shared
=
T
.
alloc_shared
([
block_H
,
dpe
],
dtype
)
KV_shared
=
T
.
alloc_shared
([
block_N
,
dv
],
dtype
)
K_pe_shared
=
T
.
alloc_shared
([
block_N
,
dpe
],
dtype
)
O_shared
=
T
.
alloc_shared
([
block_H
,
dv
],
dtype
)
acc_s
=
T
.
alloc_fragment
([
block_H
,
block_N
],
accum_dtype
)
acc_s_cast
=
T
.
alloc_fragment
([
block_H
,
block_N
],
dtype
)
acc_o
=
T
.
alloc_fragment
([
block_H
,
dv
],
accum_dtype
)
scores_max
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_max_prev
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_scale
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_sum
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
logsum
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
cur_kv_head
=
by
//
(
kv_group_num
//
block_H
)
T
.
use_swizzle
(
10
)
T
.
annotate_layout
({
O_shared
:
tilelang
.
layout
.
make_swizzled_layout
(
O_shared
),
S_shared
:
tilelang
.
layout
.
make_swizzled_layout
(
S_shared
),
})
T
.
copy
(
Q
[
bx
,
by
*
VALID_BLOCK_H
:(
by
+
1
)
*
VALID_BLOCK_H
,
:],
Q_shared
)
T
.
copy
(
Q_pe
[
bx
,
by
*
VALID_BLOCK_H
:(
by
+
1
)
*
VALID_BLOCK_H
,
:],
Q_pe_shared
)
T
.
fill
(
acc_o
,
0
)
T
.
fill
(
logsum
,
0
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
total_blocks
=
T
.
ceildiv
(
CACHE_SEQLENS
[
bx
],
block_N
)
blocks_per_split
=
T
.
floordiv
(
total_blocks
,
num_split
)
remaining_blocks
=
T
.
floormod
(
total_blocks
,
num_split
)
loop_range
=
(
blocks_per_split
+
T
.
if_then_else
(
bz
<
remaining_blocks
,
1
,
0
))
start
=
(
blocks_per_split
*
bz
+
T
.
min
(
bz
,
remaining_blocks
))
*
block_N
for
k
in
T
.
Pipelined
(
loop_range
,
num_stages
=
2
):
kv_start
=
BLOCK_TABLE
[
bx
,
(
start
+
k
*
block_N
)
//
block_size
]
*
block_size
+
(
k
*
block_N
)
%
block_size
T
.
copy
(
KV
[
kv_start
:
kv_start
+
block_N
,
cur_kv_head
,
:],
KV_shared
)
T
.
copy
(
K_pe
[
kv_start
:
kv_start
+
block_N
,
cur_kv_head
,
:],
K_pe_shared
)
T
.
clear
(
acc_s
)
T
.
gemm
(
Q_shared
,
KV_shared
,
acc_s
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
)
T
.
gemm
(
Q_pe_shared
,
K_pe_shared
,
acc_s
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
)
T
.
copy
(
scores_max
,
scores_max_prev
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
for
i
,
j
in
T
.
Parallel
(
block_H
,
block_N
):
acc_s
[
i
,
j
]
=
T
.
if_then_else
(
start
+
k
*
block_N
+
j
>=
CACHE_SEQLENS
[
bx
],
-
T
.
infinity
(
accum_dtype
),
acc_s
[
i
,
j
])
T
.
reduce_max
(
acc_s
,
scores_max
,
dim
=
1
,
clear
=
False
)
for
i
in
T
.
Parallel
(
block_H
):
scores_scale
[
i
]
=
T
.
exp2
(
scores_max_prev
[
i
]
*
scale
-
scores_max
[
i
]
*
scale
)
for
i
,
j
in
T
.
Parallel
(
block_H
,
block_N
):
acc_s
[
i
,
j
]
=
T
.
exp2
(
acc_s
[
i
,
j
]
*
scale
-
scores_max
[
i
]
*
scale
)
T
.
reduce_sum
(
acc_s
,
scores_sum
,
dim
=
1
)
T
.
copy
(
acc_s
,
S_shared
)
T
.
copy
(
S_shared
,
acc_s_cast
)
for
i
in
T
.
Parallel
(
block_H
):
logsum
[
i
]
=
logsum
[
i
]
*
scores_scale
[
i
]
+
scores_sum
[
i
]
for
i
,
j
in
T
.
Parallel
(
block_H
,
dv
):
acc_o
[
i
,
j
]
*=
scores_scale
[
i
]
T
.
gemm
(
acc_s_cast
,
KV_shared
,
acc_o
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
)
for
i
,
j
in
T
.
Parallel
(
block_H
,
dv
):
acc_o
[
i
,
j
]
/=
logsum
[
i
]
for
i
in
T
.
Parallel
(
block_H
):
logsum
[
i
]
=
T
.
log2
(
logsum
[
i
])
+
scores_max
[
i
]
*
scale
T
.
copy
(
logsum
,
glse
[
bx
,
by
*
VALID_BLOCK_H
:(
by
+
1
)
*
VALID_BLOCK_H
,
bz
])
T
.
copy
(
acc_o
,
O_shared
)
T
.
copy
(
O_shared
,
Output_partial
[
bx
,
by
*
VALID_BLOCK_H
:(
by
+
1
)
*
VALID_BLOCK_H
,
bz
,
:])
@
T
.
macro
def
combine
(
glse
:
T
.
Tensor
([
batch
,
h_q
,
num_split
],
dtype
),
Output_partial
:
T
.
Tensor
([
batch
,
h_q
,
num_split
,
dv
],
dtype
),
Output
:
T
.
Tensor
([
batch
,
h_q
,
dv
],
dtype
),
):
with
T
.
Kernel
(
h_q
,
batch
,
threads
=
128
)
as
(
by
,
bz
):
po_local
=
T
.
alloc_fragment
([
dv
],
dtype
)
o_accum_local
=
T
.
alloc_fragment
([
dv
],
accum_dtype
)
lse_local_split
=
T
.
alloc_local
([
1
],
accum_dtype
)
lse_logsum_local
=
T
.
alloc_local
([
1
],
accum_dtype
)
lse_max_local
=
T
.
alloc_local
([
1
],
accum_dtype
)
scale_local
=
T
.
alloc_local
([
1
],
accum_dtype
)
T
.
annotate_layout
({
lse_logsum_local
:
T
.
Fragment
(
lse_logsum_local
.
shape
,
forward_thread_fn
=
lambda
i
:
i
),
})
T
.
clear
(
lse_logsum_local
)
T
.
clear
(
o_accum_local
)
lse_max_local
[
0
]
=
-
T
.
infinity
(
accum_dtype
)
for
k
in
T
.
serial
(
num_split
):
lse_max_local
[
0
]
=
T
.
max
(
lse_max_local
[
0
],
glse
[
bz
,
by
,
k
])
for
k
in
T
.
Pipelined
(
num_split
,
num_stages
=
1
):
lse_local_split
[
0
]
=
glse
[
bz
,
by
,
k
]
lse_logsum_local
[
0
]
+=
T
.
exp2
(
lse_local_split
[
0
]
-
lse_max_local
[
0
])
lse_logsum_local
[
0
]
=
T
.
log2
(
lse_logsum_local
[
0
])
+
lse_max_local
[
0
]
for
k
in
T
.
serial
(
num_split
):
for
i
in
T
.
Parallel
(
dv
):
po_local
[
i
]
=
Output_partial
[
bz
,
by
,
k
,
i
]
lse_local_split
[
0
]
=
glse
[
bz
,
by
,
k
]
scale_local
[
0
]
=
T
.
exp2
(
lse_local_split
[
0
]
-
lse_logsum_local
[
0
])
for
i
in
T
.
Parallel
(
dv
):
o_accum_local
[
i
]
+=
po_local
[
i
]
*
scale_local
[
0
]
for
i
in
T
.
Parallel
(
dv
):
Output
[
bz
,
by
,
i
]
=
o_accum_local
[
i
]
@
T
.
prim_func
def
main_split
(
Q
:
T
.
Tensor
([
batch
,
h_q
,
dv
],
dtype
),
Q_pe
:
T
.
Tensor
([
batch
,
h_q
,
dpe
],
dtype
),
KV
:
T
.
Tensor
([
batch
*
max_seqlen_pad
,
h_kv
,
dv
],
dtype
),
K_pe
:
T
.
Tensor
([
batch
*
max_seqlen_pad
,
h_kv
,
dpe
],
dtype
),
block_table
:
T
.
Tensor
([
batch
,
max_seqlen_pad
//
block_size
],
"int32"
),
cache_seqlens
:
T
.
Tensor
([
batch
],
"int32"
),
glse
:
T
.
Tensor
([
batch
,
h_q
,
num_split
],
dtype
),
Output_partial
:
T
.
Tensor
([
batch
,
h_q
,
num_split
,
dv
],
dtype
),
Output
:
T
.
Tensor
([
batch
,
h_q
,
dv
],
dtype
),
):
flash_mla_split_kv_kernel
(
Q
,
Q_pe
,
KV
,
K_pe
,
block_table
,
cache_seqlens
,
glse
,
Output_partial
)
combine
(
glse
,
Output_partial
,
Output
)
@
T
.
prim_func
def
main_no_split
(
Q
:
T
.
Tensor
([
batch
,
h_q
,
dv
],
dtype
),
Q_pe
:
T
.
Tensor
([
batch
,
h_q
,
dpe
],
dtype
),
KV
:
T
.
Tensor
([
batch
*
max_seqlen_pad
,
h_kv
,
dv
],
dtype
),
K_pe
:
T
.
Tensor
([
batch
*
max_seqlen_pad
,
h_kv
,
dpe
],
dtype
),
block_table
:
T
.
Tensor
([
batch
,
max_seqlen_pad
//
block_size
],
"int32"
),
cache_seqlens
:
T
.
Tensor
([
batch
],
"int32"
),
glse
:
T
.
Tensor
([
batch
,
h_q
,
num_split
],
dtype
),
Output_partial
:
T
.
Tensor
([
batch
,
h_q
,
num_split
,
dv
],
dtype
),
Output
:
T
.
Tensor
([
batch
,
h_q
,
dv
],
dtype
),
):
flash_mla_kernel
(
Q
,
Q_pe
,
KV
,
K_pe
,
block_table
,
cache_seqlens
,
Output
)
if
num_split
>
1
:
return
main_split
else
:
return
main_no_split
def
scaled_dot_product_attention
(
query
,
key
,
value
,
h_q
,
h_kv
,
is_causal
=
False
):
query
=
query
.
float
()
key
=
key
.
float
()
value
=
value
.
float
()
key
=
key
.
repeat_interleave
(
h_q
//
h_kv
,
dim
=
0
)
value
=
value
.
repeat_interleave
(
h_q
//
h_kv
,
dim
=
0
)
attn_weight
=
query
@
key
.
transpose
(
-
2
,
-
1
)
/
math
.
sqrt
(
query
.
size
(
-
1
))
if
is_causal
:
s_q
=
query
.
shape
[
-
2
]
s_k
=
key
.
shape
[
-
2
]
attn_bias
=
torch
.
zeros
(
s_q
,
s_k
,
dtype
=
query
.
dtype
,
device
=
query
.
device
)
temp_mask
=
torch
.
ones
(
s_q
,
s_k
,
dtype
=
torch
.
bool
,
device
=
query
.
device
).
tril
(
diagonal
=
s_k
-
s_q
)
attn_bias
.
masked_fill_
(
temp_mask
.
logical_not
(),
float
(
"-inf"
))
attn_bias
.
to
(
query
.
dtype
)
attn_weight
+=
attn_bias
lse
=
attn_weight
.
logsumexp
(
dim
=-
1
)
attn_weight
=
torch
.
softmax
(
attn_weight
,
dim
=-
1
,
dtype
=
torch
.
float32
)
return
attn_weight
@
value
,
lse
@
torch
.
inference_mode
()
def
run_torch_mla
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
):
# q: [b, s_q, h_q, d]
# block_table: [b, max_seqlen_pad // block_size]
# blocked_k: [b * max_seqlen_pad // block_size, block_size, h_kv, d]
# cache_seqlens: [b]
blocked_v
=
blocked_k
[...,
:
dv
]
def
ref_mla
():
out
=
torch
.
empty
(
b
,
s_q
,
h_q
,
dv
,
dtype
=
torch
.
float32
,
device
=
q
.
device
)
lse
=
torch
.
empty
(
b
,
h_q
,
s_q
,
dtype
=
torch
.
float32
,
device
=
q
.
device
)
for
i
in
range
(
b
):
begin
=
i
*
max_seqlen_pad
end
=
begin
+
cache_seqlens
[
i
]
O
,
LSE
=
scaled_dot_product_attention
(
q
[
i
].
transpose
(
0
,
1
),
blocked_k
.
view
(
-
1
,
h_kv
,
d
)[
begin
:
end
].
transpose
(
0
,
1
),
blocked_v
.
view
(
-
1
,
h_kv
,
dv
)[
begin
:
end
].
transpose
(
0
,
1
),
h_q
,
h_kv
,
is_causal
=
causal
,
)
out
[
i
]
=
O
.
transpose
(
0
,
1
)
lse
[
i
]
=
LSE
return
out
.
to
(
dtype
),
lse
.
to
(
dtype
)
out_torch
,
_
=
ref_mla
()
return
out_torch
def
run_tilelang_mla
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
):
assert
d
>
dv
,
"mla with rope dim should be larger than no rope dim"
q_nope
,
q_pe
=
q
[...,
:
dv
].
contiguous
(),
q
[...,
dv
:].
contiguous
()
blocked_k_nope
,
blocked_k_pe
=
blocked_k
[...,
:
dv
].
contiguous
(),
blocked_k
[...,
dv
:].
contiguous
()
dpe
=
d
-
dv
num_kv_splits
=
1
BLOCK_N
=
64
BLOCK_H
=
min
(
64
,
h_q
//
h_kv
)
softmax_scale
=
d
**-
0.5
out_partial
=
torch
.
empty
(
b
,
h_q
,
num_kv_splits
,
dv
,
dtype
=
dtype
,
device
=
q
.
device
)
glse
=
torch
.
empty
(
b
,
h_q
,
num_kv_splits
,
dtype
=
dtype
,
device
=
q
.
device
)
kernel
=
mla_decode_tilelang
(
b
,
h_q
,
h_kv
,
max_seqlen_pad
,
dv
,
dpe
,
BLOCK_N
,
BLOCK_H
,
num_kv_splits
,
block_size
,
softmax_scale
)
profiler
=
kernel
.
get_profiler
(
tensor_supply_type
=
tilelang
.
TensorSupplyType
.
Randn
)
def
flash_mla_tilelang
():
out
=
profiler
.
func
(
q_nope
.
view
(
-
1
,
h_q
,
dv
),
q_pe
.
view
(
-
1
,
h_q
,
dpe
),
blocked_k_nope
.
view
(
-
1
,
h_kv
,
dv
),
blocked_k_pe
.
view
(
-
1
,
h_kv
,
dpe
),
block_table
,
cache_seqlens
,
glse
,
out_partial
,
)
return
out
.
view
([
b
,
s_q
,
h_q
,
dv
])
out_flash
=
flash_mla_tilelang
()
t
=
do_bench
(
flash_mla_tilelang
)
out_ref
=
run_torch_mla
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
)
torch
.
testing
.
assert_close
(
out_flash
,
out_ref
,
rtol
=
0.01
,
atol
=
0.01
)
print
(
"All close"
)
return
out_flash
,
t
if
__name__
==
"__main__"
:
parser
=
argparse
.
ArgumentParser
()
parser
.
add_argument
(
'--batch'
,
type
=
int
,
default
=
128
,
help
=
'batch size'
)
parser
.
add_argument
(
'--h_q'
,
type
=
int
,
default
=
128
,
help
=
'q heads number'
)
parser
.
add_argument
(
'--h_kv'
,
type
=
int
,
default
=
1
,
help
=
'kv heads number'
)
parser
.
add_argument
(
'--cache_seqlen'
,
type
=
int
,
default
=
8192
,
help
=
'kv cache context length'
)
parser
.
add_argument
(
'--d'
,
type
=
int
,
default
=
576
,
help
=
'query/key head dim, d = dv + dpe'
)
parser
.
add_argument
(
'--dv'
,
type
=
int
,
default
=
512
,
help
=
'value head dim'
)
args
=
parser
.
parse_args
()
b
,
h_q
,
h_kv
,
cache_seqlen
,
d
,
dv
=
args
.
batch
,
args
.
h_q
,
args
.
h_kv
,
args
.
cache_seqlen
,
args
.
d
,
args
.
dv
device
=
"cuda"
dtype
=
torch
.
float16
s_q
=
1
# for decode, s_q = 1
block_size
=
64
cache_seqlens
=
torch
.
tensor
([
cache_seqlen
+
2
*
i
for
i
in
range
(
b
)],
dtype
=
torch
.
int32
,
device
=
device
)
dpe
=
d
-
dv
causal
=
True
total_seqlens
=
cache_seqlens
.
sum
().
item
()
mean_seqlens
=
cache_seqlens
.
float
().
mean
().
int
().
item
()
max_seqlen
=
cache_seqlens
.
max
().
item
()
max_seqlen_pad
=
math
.
ceil
(
max_seqlen
/
256
)
*
256
total_flops
=
s_q
*
total_seqlens
*
h_q
*
d
*
2
q
=
torch
.
randn
(
b
,
s_q
,
h_q
,
d
,
dtype
=
dtype
,
device
=
device
)
block_table
=
torch
.
arange
(
b
*
max_seqlen_pad
//
block_size
,
dtype
=
torch
.
int32
,
device
=
device
).
view
(
b
,
max_seqlen_pad
//
block_size
)
blocked_k
=
torch
.
randn
(
block_table
.
numel
(),
block_size
,
h_kv
,
d
,
dtype
=
dtype
,
device
=
device
)
out_flash
,
latency
=
run_tilelang_mla
(
q
,
block_table
,
blocked_k
,
max_seqlen_pad
,
block_size
,
b
,
s_q
,
cache_seqlens
,
h_q
,
h_kv
,
d
,
dv
,
causal
,
dtype
)
print
(
"Tile-lang: {:.2f} ms"
.
format
(
latency
))
print
(
"Tile-lang: {:.2f} TFlops"
.
format
(
total_flops
/
latency
*
1e-9
))
examples/deepseek_mla/example_mla_decode_persistent.py
0 → 100644
View file @
bc2d5632
import
torch
import
torch.nn.functional
as
F
import
tilelang
from
tilelang.autotuner
import
*
import
tilelang.language
as
T
from
tilelang.carver.arch
import
driver
from
einops
import
rearrange
,
einsum
import
argparse
@
tilelang
.
jit
(
out_idx
=
[
6
],
pass_configs
=
{
tilelang
.
PassConfigKey
.
TL_ENABLE_FAST_MATH
:
True
,
})
def
flashattn
(
batch
,
heads
,
kv_head_num
,
seqlen_kv
,
dim
,
pe_dim
,
block_N
,
block_H
,
num_split
):
scale
=
(
1.0
/
(
dim
+
pe_dim
))
**
0.5
*
1.44269504
# log2(e)
dtype
=
"float16"
accum_dtype
=
"float"
kv_group_num
=
heads
//
kv_head_num
VALID_BLOCK_H
=
min
(
block_H
,
kv_group_num
)
assert
kv_head_num
==
1
,
"kv_head_num must be 1"
sm_num
=
driver
.
get_num_sms
()
@
T
.
prim_func
def
main_split_persistent
(
Q
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
Q_pe
:
T
.
Tensor
([
batch
,
heads
,
pe_dim
],
dtype
),
KV
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
dim
],
dtype
),
K_pe
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
pe_dim
],
dtype
),
glse
:
T
.
Tensor
([
batch
,
heads
,
num_split
],
dtype
),
Output_partial
:
T
.
Tensor
([
batch
,
heads
,
num_split
,
dim
],
dtype
),
Output
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
):
with
T
.
Kernel
(
sm_num
,
threads
=
256
)
as
(
block_id
):
Q_shared
=
T
.
alloc_shared
([
block_H
,
dim
],
dtype
)
S_shared
=
T
.
alloc_shared
([
block_H
,
block_N
],
dtype
)
Q_pe_shared
=
T
.
alloc_shared
([
block_H
,
pe_dim
],
dtype
)
KV_shared
=
T
.
alloc_shared
([
block_N
,
dim
],
dtype
)
K_pe_shared
=
T
.
alloc_shared
([
block_N
,
pe_dim
],
dtype
)
# O_shared = T.alloc_shared([block_H, dim], dtype)
acc_s
=
T
.
alloc_fragment
([
block_H
,
block_N
],
accum_dtype
)
acc_s_cast
=
T
.
alloc_fragment
([
block_H
,
block_N
],
dtype
)
acc_o
=
T
.
alloc_fragment
([
block_H
,
dim
],
accum_dtype
)
scores_max
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_max_prev
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_scale
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_sum
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
logsum
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
po_local
=
T
.
alloc_fragment
([
dim
],
dtype
)
o_accum_local
=
T
.
alloc_fragment
([
dim
],
accum_dtype
)
lse_local_split
=
T
.
alloc_local
([
1
],
accum_dtype
)
lse_logsum_local
=
T
.
alloc_local
([
1
],
accum_dtype
)
lse_max_local
=
T
.
alloc_local
([
1
],
accum_dtype
)
scale_local
=
T
.
alloc_local
([
1
],
accum_dtype
)
T
.
annotate_layout
({
# O_shared: tilelang.layout.make_swizzled_layout(O_shared),
S_shared
:
tilelang
.
layout
.
make_swizzled_layout
(
S_shared
),
lse_logsum_local
:
T
.
Fragment
(
lse_logsum_local
.
shape
,
forward_thread_fn
=
lambda
i
:
i
),
})
T
.
use_swizzle
(
10
)
total_tiles
=
batch
*
(
heads
//
min
(
block_H
,
kv_group_num
))
*
num_split
waves
=
T
.
ceildiv
(
total_tiles
,
sm_num
)
for
w
in
T
.
serial
(
waves
):
tile_id
=
sm_num
*
w
+
block_id
bid
=
tile_id
//
((
heads
//
min
(
block_H
,
kv_group_num
))
*
num_split
)
hid
=
tile_id
//
num_split
%
(
heads
//
min
(
block_H
,
kv_group_num
))
sid
=
tile_id
%
num_split
cur_kv_head
=
hid
//
(
kv_group_num
//
block_H
)
if
bid
<
batch
and
hid
*
VALID_BLOCK_H
<
heads
and
sid
<
num_split
:
T
.
copy
(
Q
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
:],
Q_shared
)
T
.
copy
(
Q_pe
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
:],
Q_pe_shared
)
T
.
fill
(
acc_o
,
0
)
T
.
fill
(
logsum
,
0
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
loop_range
=
T
.
ceildiv
((
seqlen_kv
//
num_split
),
block_N
)
for
k
in
T
.
Pipelined
(
loop_range
,
num_stages
=
2
):
kv_start
=
(
seqlen_kv
//
num_split
)
*
sid
+
k
*
block_N
kv_end
=
(
seqlen_kv
//
num_split
)
*
sid
+
(
k
+
1
)
*
block_N
T
.
copy
(
KV
[
bid
,
kv_start
:
kv_end
,
cur_kv_head
,
:],
KV_shared
)
T
.
copy
(
K_pe
[
bid
,
kv_start
:
kv_end
,
cur_kv_head
,
:],
K_pe_shared
)
T
.
clear
(
acc_s
)
T
.
gemm
(
Q_shared
,
KV_shared
,
acc_s
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
)
T
.
gemm
(
Q_pe_shared
,
K_pe_shared
,
acc_s
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
)
T
.
copy
(
scores_max
,
scores_max_prev
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
T
.
reduce_max
(
acc_s
,
scores_max
,
dim
=
1
,
clear
=
False
)
for
i
in
T
.
Parallel
(
block_H
):
scores_scale
[
i
]
=
T
.
exp2
(
scores_max_prev
[
i
]
*
scale
-
scores_max
[
i
]
*
scale
)
for
i
,
j
in
T
.
Parallel
(
block_H
,
block_N
):
acc_s
[
i
,
j
]
=
T
.
exp2
(
acc_s
[
i
,
j
]
*
scale
-
scores_max
[
i
]
*
scale
)
T
.
reduce_sum
(
acc_s
,
scores_sum
,
dim
=
1
)
T
.
copy
(
acc_s
,
S_shared
)
T
.
copy
(
S_shared
,
acc_s_cast
)
for
i
in
T
.
Parallel
(
block_H
):
logsum
[
i
]
=
logsum
[
i
]
*
scores_scale
[
i
]
+
scores_sum
[
i
]
for
i
,
j
in
T
.
Parallel
(
block_H
,
dim
):
acc_o
[
i
,
j
]
*=
scores_scale
[
i
]
T
.
gemm
(
acc_s_cast
,
KV_shared
,
acc_o
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
)
for
i
,
j
in
T
.
Parallel
(
block_H
,
dim
):
acc_o
[
i
,
j
]
/=
logsum
[
i
]
for
i
in
T
.
Parallel
(
block_H
):
logsum
[
i
]
=
T
.
log2
(
logsum
[
i
])
+
scores_max
[
i
]
*
scale
T
.
copy
(
logsum
,
glse
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
sid
])
# T.copy(acc_o, O_shared)
T
.
copy
(
acc_o
,
Output_partial
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
sid
,
:])
T
.
sync_grid
()
waves
=
T
.
ceildiv
(
heads
*
batch
,
sm_num
)
for
w
in
T
.
serial
(
waves
):
tile_id
=
sm_num
*
w
+
block_id
hid
=
tile_id
//
batch
bid
=
tile_id
%
batch
if
bid
<
batch
and
hid
<
heads
:
T
.
clear
(
lse_logsum_local
)
T
.
clear
(
o_accum_local
)
lse_max_local
[
0
]
=
-
T
.
infinity
(
accum_dtype
)
for
k
in
T
.
serial
(
num_split
):
lse_max_local
[
0
]
=
T
.
max
(
lse_max_local
[
0
],
glse
[
bid
,
hid
,
k
])
for
k
in
T
.
Pipelined
(
num_split
,
num_stages
=
1
):
lse_local_split
[
0
]
=
glse
[
bid
,
hid
,
k
]
lse_logsum_local
[
0
]
+=
T
.
exp2
(
lse_local_split
[
0
]
-
lse_max_local
[
0
])
lse_logsum_local
[
0
]
=
T
.
log2
(
lse_logsum_local
[
0
])
+
lse_max_local
[
0
]
for
k
in
T
.
serial
(
num_split
):
for
i
in
T
.
Parallel
(
dim
):
po_local
[
i
]
=
Output_partial
[
bid
,
hid
,
k
,
i
]
lse_local_split
[
0
]
=
glse
[
bid
,
hid
,
k
]
scale_local
[
0
]
=
T
.
exp2
(
lse_local_split
[
0
]
-
lse_logsum_local
[
0
])
for
i
in
T
.
Parallel
(
dim
):
o_accum_local
[
i
]
+=
po_local
[
i
]
*
scale_local
[
0
]
for
i
in
T
.
Parallel
(
dim
):
Output
[
bid
,
hid
,
i
]
=
o_accum_local
[
i
]
return
main_split_persistent
def
ref_program
(
q
,
q_pe
,
kv
,
k_pe
,
glse
,
Output_partial
):
# """
# Inputs:
# - q (Tensor): [batch, heads, dim]
# - q_pe (Tensor): [batch, heads, pe_dim]
# - kv (Tensor): [batch, seqlen_kv, kv_head_num, dim]
# - k_pe (Tensor): [batch, seqlen_kv, kv_head_num, pe_dim]
# - glse (Tensor): [batch, heads, num_split]
# - Output_partial (Tensor): [batch, heads, num_split, dim]
# Outputs:
# - output (Tensor): [batch, heads, dim]
# """
dim
=
q
.
shape
[
-
1
]
pe_dim
=
q_pe
.
shape
[
-
1
]
num_head_groups
=
q
.
shape
[
1
]
//
kv
.
shape
[
2
]
scale
=
(
dim
+
pe_dim
)
**
0.5
q
=
rearrange
(
q
,
'b (h g) d -> b g h d'
,
g
=
num_head_groups
)
# [batch_size, num_head_groups, groups, dim]
q_pe
=
rearrange
(
q_pe
,
'b (h g) d -> b g h d'
,
g
=
num_head_groups
)
# [batch_size, num_head_groups, groups, pe_dim]
kv
=
rearrange
(
kv
,
'b n h d -> b h n d'
)
# [batch_size, groups, seqlen_kv, dim]
k_pe
=
rearrange
(
k_pe
,
'b n h d -> b h n d'
)
# [batch_size, num_head_groups, groups, pe_dim]
query
=
torch
.
concat
([
q
,
q_pe
],
dim
=-
1
)
key
=
torch
.
concat
([
kv
,
k_pe
],
dim
=-
1
)
scores
=
einsum
(
query
,
key
,
'b g h d, b h s d -> b g h s'
)
# [batch_size, num_head_groups, groups, seqlen_kv]
attention
=
F
.
softmax
(
scores
/
scale
,
dim
=-
1
)
# [batch_size, num_head_groups, groups, seqlen_kv]
out
=
einsum
(
attention
,
kv
,
'b g h s, b h s d -> b g h d'
)
# [batch_size, num_head_groups, groups, dim]
out
=
rearrange
(
out
,
'b g h d -> b (h g) d'
)
# [batch_size, heads, dim]
return
out
def
main
():
parser
=
argparse
.
ArgumentParser
()
parser
.
add_argument
(
'--batch'
,
type
=
int
,
default
=
128
,
help
=
'batch size'
)
parser
.
add_argument
(
'--heads'
,
type
=
int
,
default
=
128
,
help
=
'q heads number'
)
parser
.
add_argument
(
'--kv_heads'
,
type
=
int
,
default
=
1
,
help
=
'kv heads number'
)
parser
.
add_argument
(
'--kv_ctx'
,
type
=
int
,
default
=
8192
,
help
=
'kv context length'
)
parser
.
add_argument
(
'--dim'
,
type
=
int
,
default
=
512
,
help
=
'head dim'
)
parser
.
add_argument
(
'--pe_dim'
,
type
=
int
,
default
=
64
,
help
=
'pe head dim'
)
args
=
parser
.
parse_args
()
batch
,
heads
,
kv_heads
,
kv_ctx
,
dim
,
pe_dim
=
args
.
batch
,
args
.
heads
,
args
.
kv_heads
,
args
.
kv_ctx
,
args
.
dim
,
args
.
pe_dim
qk_flops
=
2
*
batch
*
heads
*
kv_ctx
*
(
dim
+
pe_dim
)
pv_flops
=
2
*
batch
*
heads
*
kv_ctx
*
dim
total_flops
=
qk_flops
+
pv_flops
BLOCK_N
=
64
BLOCK_H
=
64
num_split
=
2
kernel
=
flashattn
(
batch
,
heads
,
kv_heads
,
kv_ctx
,
dim
,
pe_dim
,
BLOCK_N
,
BLOCK_H
,
num_split
)
print
(
kernel
.
get_kernel_source
())
profiler
=
kernel
.
get_profiler
(
tensor_supply_type
=
tilelang
.
TensorSupplyType
.
Randn
)
profiler
.
assert_allclose
(
ref_program
,
rtol
=
0.01
,
atol
=
0.01
)
latency
=
profiler
.
do_bench
(
warmup
=
500
)
print
(
f
"Latency:
{
latency
}
ms"
)
print
(
f
"TFlops:
{
total_flops
/
latency
*
1e-9
}
TFlops"
)
if
__name__
==
"__main__"
:
main
()
examples/deepseek_mla/example_mla_decode_ws.py
0 → 100644
View file @
bc2d5632
import
torch
import
torch.nn.functional
as
F
import
tilelang
from
tilelang.autotuner
import
*
import
tilelang.language
as
T
from
einops
import
rearrange
,
einsum
import
argparse
@
tilelang
.
jit
(
out_idx
=
[
6
],
pass_configs
=
{
tilelang
.
PassConfigKey
.
TL_ENABLE_FAST_MATH
:
True
,
},
compile_flags
=
[
"-O3"
,
"-Wno-deprecated-declarations"
,
"-U__CUDA_NO_HALF_OPERATORS__"
,
"-U__CUDA_NO_HALF_CONVERSIONS__"
,
"-U__CUDA_NO_HALF2_OPERATORS__"
,
"-U__CUDA_NO_BFLOAT16_CONVERSIONS__"
,
"--expt-relaxed-constexpr"
,
"--expt-extended-lambda"
,
"--ptxas-options=-v,--register-usage-level=10"
,
"-DNDEBUG"
],
)
def
flashattn
(
batch
,
heads
,
kv_head_num
,
seqlen_kv
,
dim
,
pe_dim
,
block_N
,
block_H
,
num_split
,
softmax_scale
):
sm_scale
=
float
(
softmax_scale
*
1.44269504
)
# log2(e)
dtype
=
"float16"
accum_dtype
=
"float"
kv_group_num
=
heads
//
kv_head_num
VALID_BLOCK_H
=
min
(
block_H
,
kv_group_num
)
assert
kv_head_num
==
1
,
"kv_head_num must be 1"
@
T
.
macro
def
flash_attn
(
Q
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
Q_pe
:
T
.
Tensor
([
batch
,
heads
,
pe_dim
],
dtype
),
KV
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
dim
],
dtype
),
K_pe
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
pe_dim
],
dtype
),
Output
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
):
with
T
.
Kernel
(
heads
//
min
(
block_H
,
kv_group_num
),
batch
,
threads
=
384
)
as
(
hid
,
bid
):
Q_shared_l
=
T
.
alloc_shared
([
block_H
,
dim
//
2
],
dtype
)
Q_shared_r
=
T
.
alloc_shared
([
block_H
,
dim
//
2
],
dtype
)
Q_tail_shared
=
T
.
alloc_shared
([
block_H
,
pe_dim
],
dtype
)
KV_shared_0_l
=
T
.
alloc_shared
([
block_N
,
dim
//
2
],
dtype
)
KV_shared_0_r
=
T
.
alloc_shared
([
block_N
,
dim
//
2
],
dtype
)
KV_shared_1_l
=
T
.
alloc_shared
([
block_N
,
dim
//
2
],
dtype
)
KV_shared_1_r
=
T
.
alloc_shared
([
block_N
,
dim
//
2
],
dtype
)
K_tail_shared_0
=
T
.
alloc_shared
([
block_N
,
pe_dim
],
dtype
)
K_tail_shared_1
=
T
.
alloc_shared
([
block_N
,
pe_dim
],
dtype
)
O_shared_l
=
Q_shared_l
O_shared_r
=
Q_shared_r
acc_o_l
=
T
.
alloc_fragment
([
block_H
,
dim
//
2
],
accum_dtype
)
acc_o_r
=
T
.
alloc_fragment
([
block_H
,
dim
//
2
],
accum_dtype
)
acc_s
=
T
.
alloc_fragment
([
block_H
,
block_N
],
accum_dtype
)
S_shared
=
T
.
alloc_shared
([
block_H
,
block_N
],
dtype
)
sumexp
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
sum_exp_shared
=
T
.
alloc_shared
([
block_H
],
accum_dtype
)
sumexp_i
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
alpha_shared
=
T
.
alloc_shared
([
block_H
],
accum_dtype
,
scope
=
"shared"
)
alpha_local
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
m_i
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
m_i_prev
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
# TODO: Multi buffer
bar_q
=
T
.
alloc_barrier
(
arrive_count
=
384
)
bar_k_0_ready
=
T
.
alloc_barrier
(
arrive_count
=
128
)
bar_k_1_ready
=
T
.
alloc_barrier
(
arrive_count
=
128
)
bar_k_0_free
=
T
.
alloc_barrier
(
arrive_count
=
256
)
bar_k_1_free
=
T
.
alloc_barrier
(
arrive_count
=
256
)
bar_sScale_and_sS_ready
=
T
.
alloc_barrier
(
arrive_count
=
256
)
bar_sScale_and_sS_free
=
T
.
alloc_barrier
(
arrive_count
=
256
)
cur_kv_head
=
hid
//
(
kv_group_num
//
block_H
)
NI
=
T
.
ceildiv
((
seqlen_kv
//
num_split
),
block_N
)
tx
=
T
.
get_thread_binding
()
T
.
copy
(
Q
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
0
:
dim
//
2
],
Q_shared_l
)
T
.
copy
(
Q
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
dim
//
2
:
dim
],
Q_shared_r
)
T
.
copy
(
Q_pe
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
:],
Q_tail_shared
)
T
.
barrier_arrive
(
bar_q
)
if
tx
<
128
:
T
.
set_max_nreg
(
240
,
1
)
T
.
fill
(
sumexp
,
0
)
T
.
fill
(
m_i
,
-
2
**
30
)
# avoid -inf - inf to cause nan
T
.
fill
(
acc_o_l
,
0
)
T
.
barrier_wait
(
bar_q
,
0
)
for
i_i
in
T
.
serial
(
T
.
ceildiv
(
NI
,
2
)):
# Buffer 0
T
.
barrier_wait
(
bar_k_0_ready
[
0
],
(
i_i
&
1
))
T
.
clear
(
acc_s
)
T
.
gemm
(
Q_shared_l
,
KV_shared_0_l
,
acc_s
,
transpose_B
=
True
,
wg_wait
=-
1
)
T
.
gemm
(
Q_shared_r
,
KV_shared_0_r
,
acc_s
,
transpose_B
=
True
,
wg_wait
=-
1
)
T
.
gemm
(
Q_tail_shared
,
K_tail_shared_0
,
acc_s
,
transpose_B
=
True
,
wg_wait
=-
1
)
T
.
wait_wgmma
(
0
)
if
i_i
!=
0
:
T
.
barrier_arrive
(
bar_sScale_and_sS_free
)
T
.
barrier_wait
(
bar_sScale_and_sS_free
,
((
i_i
*
2
)
&
1
)
^
1
)
T
.
copy
(
m_i
,
m_i_prev
)
T
.
reduce_max
(
acc_s
,
m_i
,
dim
=
1
,
clear
=
False
)
for
h_i
in
T
.
Parallel
(
block_H
):
alpha_local
[
h_i
]
=
T
.
exp2
((
m_i_prev
[
h_i
]
-
m_i
[
h_i
])
*
sm_scale
)
for
h_i
,
bi_i
in
T
.
Parallel
(
block_H
,
block_N
):
acc_s
[
h_i
,
bi_i
]
=
T
.
exp2
(
acc_s
[
h_i
,
bi_i
]
*
sm_scale
-
m_i
[
h_i
]
*
sm_scale
)
T
.
reduce_sum
(
acc_s
,
sumexp_i
,
dim
=
1
)
# is this a accumulate operator?
for
h_i
in
T
.
Parallel
(
block_H
):
sumexp
[
h_i
]
=
sumexp
[
h_i
]
*
alpha_local
[
h_i
]
+
sumexp_i
[
h_i
]
for
h_i
,
d_i
in
T
.
Parallel
(
block_H
,
dim
//
2
):
acc_o_l
[
h_i
,
d_i
]
*=
alpha_local
[
h_i
]
T
.
copy
(
alpha_local
,
alpha_shared
)
T
.
copy
(
acc_s
,
S_shared
)
T
.
gemm
(
S_shared
,
KV_shared_0_l
,
acc_o_l
)
T
.
barrier_arrive
(
bar_sScale_and_sS_ready
)
T
.
barrier_arrive
(
bar_k_0_free
[
0
])
# Buffer 1
T
.
barrier_wait
(
bar_k_1_ready
[
0
],
(
i_i
&
1
))
T
.
clear
(
acc_s
)
T
.
gemm
(
Q_shared_l
,
KV_shared_1_l
,
acc_s
,
transpose_B
=
True
,
wg_wait
=-
1
)
T
.
gemm
(
Q_shared_r
,
KV_shared_1_r
,
acc_s
,
transpose_B
=
True
,
wg_wait
=-
1
)
T
.
gemm
(
Q_tail_shared
,
K_tail_shared_1
,
acc_s
,
transpose_B
=
True
,
wg_wait
=-
1
)
T
.
wait_wgmma
(
0
)
T
.
barrier_arrive
(
bar_sScale_and_sS_free
)
T
.
barrier_wait
(
bar_sScale_and_sS_free
,
((
i_i
*
2
+
1
)
&
1
)
^
1
)
T
.
copy
(
m_i
,
m_i_prev
)
T
.
reduce_max
(
acc_s
,
m_i
,
dim
=
1
,
clear
=
False
)
for
h_i
in
T
.
Parallel
(
block_H
):
alpha_local
[
h_i
]
=
T
.
exp2
((
m_i_prev
[
h_i
]
-
m_i
[
h_i
])
*
sm_scale
)
for
h_i
,
bi_i
in
T
.
Parallel
(
block_H
,
block_N
):
acc_s
[
h_i
,
bi_i
]
=
T
.
exp2
(
acc_s
[
h_i
,
bi_i
]
*
sm_scale
-
m_i
[
h_i
]
*
sm_scale
)
T
.
reduce_sum
(
acc_s
,
sumexp_i
,
dim
=
1
)
# is this a accumulate operator?
for
h_i
in
T
.
Parallel
(
block_H
):
sumexp
[
h_i
]
=
sumexp
[
h_i
]
*
alpha_local
[
h_i
]
+
sumexp_i
[
h_i
]
for
h_i
,
d_i
in
T
.
Parallel
(
block_H
,
dim
//
2
):
acc_o_l
[
h_i
,
d_i
]
*=
alpha_local
[
h_i
]
T
.
copy
(
alpha_local
,
alpha_shared
)
T
.
copy
(
acc_s
,
S_shared
)
T
.
gemm
(
S_shared
,
KV_shared_1_l
,
acc_o_l
)
T
.
barrier_arrive
(
bar_sScale_and_sS_ready
)
T
.
barrier_arrive
(
bar_k_1_free
[
0
])
# Rescale
for
h_i
in
T
.
Parallel
(
block_H
):
sum_exp_shared
[
h_i
]
=
sumexp
[
h_i
]
for
h_i
,
d_i
in
T
.
Parallel
(
block_H
,
dim
//
2
):
acc_o_l
[
h_i
,
d_i
]
/=
sumexp
[
h_i
]
for
h_i
in
T
.
Parallel
(
block_H
):
sumexp
[
h_i
]
=
T
.
log2
(
sumexp
[
h_i
])
+
m_i
[
h_i
]
*
sm_scale
T
.
copy
(
acc_o_l
,
O_shared_l
)
T
.
copy
(
O_shared_l
,
Output
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
0
:
dim
//
2
])
elif
tx
>=
128
and
tx
<
256
:
T
.
set_max_nreg
(
168
,
1
)
T
.
fill
(
acc_o_r
,
0
)
for
i_i
in
T
.
serial
(
T
.
ceildiv
(
NI
,
2
)):
# Buffer 0
T
.
barrier_arrive
(
bar_sScale_and_sS_ready
)
T
.
barrier_wait
(
bar_sScale_and_sS_ready
,
((
i_i
*
2
)
&
1
))
for
h_i
,
d_i
in
T
.
Parallel
(
block_H
,
dim
//
2
):
acc_o_r
[
h_i
,
d_i
]
*=
alpha_shared
[
h_i
]
T
.
gemm
(
S_shared
,
KV_shared_0_r
,
acc_o_r
)
T
.
barrier_arrive
(
bar_k_0_free
[
0
])
T
.
barrier_arrive
(
bar_sScale_and_sS_free
)
# Buffer 1
T
.
barrier_arrive
(
bar_sScale_and_sS_ready
)
T
.
barrier_wait
(
bar_sScale_and_sS_ready
,
((
i_i
*
2
+
1
)
&
1
))
for
h_i
,
d_i
in
T
.
Parallel
(
block_H
,
dim
//
2
):
acc_o_r
[
h_i
,
d_i
]
*=
alpha_shared
[
h_i
]
T
.
gemm
(
S_shared
,
KV_shared_1_r
,
acc_o_r
)
T
.
barrier_arrive
(
bar_k_1_free
[
0
])
if
i_i
!=
T
.
ceildiv
(
NI
,
2
)
-
1
:
T
.
barrier_arrive
(
bar_sScale_and_sS_free
)
# Rescale
for
h_i
,
d_i
in
T
.
Parallel
(
block_H
,
dim
//
2
):
acc_o_r
[
h_i
,
d_i
]
/=
sum_exp_shared
[
h_i
]
T
.
copy
(
acc_o_r
,
O_shared_r
)
T
.
copy
(
O_shared_r
,
Output
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
dim
//
2
:
dim
])
elif
tx
>=
256
:
# producer
T
.
set_max_nreg
(
80
,
0
)
for
i_i
in
T
.
serial
(
T
.
ceildiv
(
NI
,
2
)):
# Buffer 0
T
.
barrier_wait
(
bar_k_0_free
[
0
],
((
i_i
&
1
)
^
1
))
for
r
in
T
.
serial
(
4
):
kv_indices
=
(
i_i
*
2
)
*
block_N
+
r
*
16
+
(
tx
-
256
)
//
8
with
T
.
attr
(
"default"
,
"async_scope"
,
1
):
for
u
in
T
.
serial
(
4
):
for
v
in
T
.
vectorized
(
8
):
KV_shared_0_l
[
r
*
16
+
(
tx
-
256
)
//
8
,
64
*
u
+
(
tx
-
256
)
%
8
*
8
+
v
]
=
KV
[
bid
,
kv_indices
,
cur_kv_head
,
64
*
u
+
(
tx
-
256
)
%
8
*
8
+
v
]
KV_shared_0_r
[
r
*
16
+
(
tx
-
256
)
//
8
,
64
*
u
+
(
tx
-
256
)
%
8
*
8
+
v
]
=
KV
[
bid
,
kv_indices
,
cur_kv_head
,
dim
//
2
+
64
*
u
+
(
tx
-
256
)
%
8
*
8
+
v
]
with
T
.
attr
(
"default"
,
"async_scope"
,
1
):
for
v
in
T
.
vectorized
(
8
):
K_tail_shared_0
[
r
*
16
+
(
tx
-
256
)
//
8
,
(
tx
-
256
)
%
8
*
8
+
v
]
=
K_pe
[
bid
,
kv_indices
,
cur_kv_head
,
(
tx
-
256
)
%
8
*
8
+
v
]
T
.
cp_async_barrier_noinc
(
bar_k_0_ready
[
0
])
# Buffer 1
T
.
barrier_wait
(
bar_k_1_free
[
0
],
((
i_i
&
1
)
^
1
))
for
r
in
T
.
serial
(
4
):
kv_indices
=
(
i_i
*
2
+
1
)
*
block_N
+
r
*
16
+
(
tx
-
256
)
//
8
with
T
.
attr
(
"default"
,
"async_scope"
,
1
):
for
u
in
T
.
serial
(
4
):
for
v
in
T
.
vectorized
(
8
):
KV_shared_1_l
[
r
*
16
+
(
tx
-
256
)
//
8
,
64
*
u
+
(
tx
-
256
)
%
8
*
8
+
v
]
=
KV
[
bid
,
kv_indices
,
cur_kv_head
,
64
*
u
+
(
tx
-
256
)
%
8
*
8
+
v
]
KV_shared_1_r
[
r
*
16
+
(
tx
-
256
)
//
8
,
64
*
u
+
(
tx
-
256
)
%
8
*
8
+
v
]
=
KV
[
bid
,
kv_indices
,
cur_kv_head
,
dim
//
2
+
64
*
u
+
(
tx
-
256
)
%
8
*
8
+
v
]
with
T
.
attr
(
"default"
,
"async_scope"
,
1
):
for
v
in
T
.
vectorized
(
8
):
K_tail_shared_1
[
r
*
16
+
(
tx
-
256
)
//
8
,
(
tx
-
256
)
%
8
*
8
+
v
]
=
K_pe
[
bid
,
kv_indices
,
cur_kv_head
,
(
tx
-
256
)
%
8
*
8
+
v
]
T
.
cp_async_barrier_noinc
(
bar_k_1_ready
[
0
])
@
T
.
macro
def
flash_attn_split
(
Q
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
Q_pe
:
T
.
Tensor
([
batch
,
heads
,
pe_dim
],
dtype
),
KV
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
dim
],
dtype
),
K_pe
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
pe_dim
],
dtype
),
glse
:
T
.
Tensor
([
batch
,
heads
,
num_split
],
dtype
),
Output_partial
:
T
.
Tensor
([
batch
,
heads
,
num_split
,
dim
],
dtype
),
):
with
T
.
Kernel
(
batch
,
heads
//
min
(
block_H
,
kv_group_num
),
num_split
,
threads
=
384
)
as
(
bid
,
hid
,
bz
):
Q_shared_l
=
T
.
alloc_shared
([
block_H
,
dim
//
2
],
dtype
)
Q_shared_r
=
T
.
alloc_shared
([
block_H
,
dim
//
2
],
dtype
)
Q_tail_shared
=
T
.
alloc_shared
([
block_H
,
pe_dim
],
dtype
)
KV_shared_0_l
=
T
.
alloc_shared
([
block_N
,
dim
//
2
],
dtype
)
KV_shared_0_r
=
T
.
alloc_shared
([
block_N
,
dim
//
2
],
dtype
)
KV_shared_1_l
=
T
.
alloc_shared
([
block_N
,
dim
//
2
],
dtype
)
KV_shared_1_r
=
T
.
alloc_shared
([
block_N
,
dim
//
2
],
dtype
)
K_tail_shared_0
=
T
.
alloc_shared
([
block_N
,
pe_dim
],
dtype
)
K_tail_shared_1
=
T
.
alloc_shared
([
block_N
,
pe_dim
],
dtype
)
O_shared_l
=
Q_shared_l
O_shared_r
=
Q_shared_r
acc_o_l
=
T
.
alloc_fragment
([
block_H
,
dim
//
2
],
accum_dtype
)
acc_o_r
=
T
.
alloc_fragment
([
block_H
,
dim
//
2
],
accum_dtype
)
acc_s
=
T
.
alloc_fragment
([
block_H
,
block_N
],
accum_dtype
)
S_shared
=
T
.
alloc_shared
([
block_H
,
block_N
],
dtype
)
sumexp
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
sum_exp_shared
=
T
.
alloc_shared
([
block_H
],
accum_dtype
)
sumexp_i
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
alpha_shared
=
T
.
alloc_shared
([
block_H
],
accum_dtype
,
scope
=
"shared"
)
alpha_local
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
m_i
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
m_i_prev
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
# TODO: Multi buffer
bar_q
=
T
.
alloc_barrier
(
arrive_count
=
384
)
bar_k_0_ready
=
T
.
alloc_barrier
(
arrive_count
=
128
)
bar_k_1_ready
=
T
.
alloc_barrier
(
arrive_count
=
128
)
bar_k_0_free
=
T
.
alloc_barrier
(
arrive_count
=
256
)
bar_k_1_free
=
T
.
alloc_barrier
(
arrive_count
=
256
)
bar_sScale_and_sS_ready
=
T
.
alloc_barrier
(
arrive_count
=
256
)
bar_sScale_and_sS_free
=
T
.
alloc_barrier
(
arrive_count
=
256
)
cur_kv_head
=
hid
//
(
kv_group_num
//
block_H
)
NI
=
T
.
ceildiv
((
seqlen_kv
//
num_split
),
block_N
)
tx
=
T
.
get_thread_binding
()
T
.
copy
(
Q
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
0
:
dim
//
2
],
Q_shared_l
)
T
.
copy
(
Q
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
dim
//
2
:
dim
],
Q_shared_r
)
T
.
copy
(
Q_pe
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
:],
Q_tail_shared
)
T
.
barrier_arrive
(
bar_q
)
if
tx
<
128
:
T
.
set_max_nreg
(
240
,
1
)
T
.
fill
(
sumexp
,
0
)
T
.
fill
(
m_i
,
-
2
**
30
)
# avoid -inf - inf to cause nan
T
.
fill
(
acc_o_l
,
0
)
T
.
barrier_wait
(
bar_q
,
0
)
for
i_i
in
T
.
serial
(
T
.
ceildiv
(
NI
,
2
)):
# Buffer 0
T
.
barrier_wait
(
bar_k_0_ready
[
0
],
(
i_i
&
1
))
T
.
clear
(
acc_s
)
T
.
gemm
(
Q_shared_l
,
KV_shared_0_l
,
acc_s
,
transpose_B
=
True
,
wg_wait
=-
1
)
T
.
gemm
(
Q_shared_r
,
KV_shared_0_r
,
acc_s
,
transpose_B
=
True
,
wg_wait
=-
1
)
T
.
gemm
(
Q_tail_shared
,
K_tail_shared_0
,
acc_s
,
transpose_B
=
True
,
wg_wait
=-
1
)
T
.
wait_wgmma
(
0
)
if
i_i
!=
0
:
T
.
barrier_arrive
(
bar_sScale_and_sS_free
)
T
.
barrier_wait
(
bar_sScale_and_sS_free
,
((
i_i
*
2
)
&
1
)
^
1
)
T
.
copy
(
m_i
,
m_i_prev
)
T
.
reduce_max
(
acc_s
,
m_i
,
dim
=
1
,
clear
=
False
)
for
h_i
in
T
.
Parallel
(
block_H
):
alpha_local
[
h_i
]
=
T
.
exp2
((
m_i_prev
[
h_i
]
-
m_i
[
h_i
])
*
sm_scale
)
for
h_i
,
bi_i
in
T
.
Parallel
(
block_H
,
block_N
):
acc_s
[
h_i
,
bi_i
]
=
T
.
exp2
(
acc_s
[
h_i
,
bi_i
]
*
sm_scale
-
m_i
[
h_i
]
*
sm_scale
)
T
.
reduce_sum
(
acc_s
,
sumexp_i
,
dim
=
1
)
# is this a accumulate operator?
for
h_i
in
T
.
Parallel
(
block_H
):
sumexp
[
h_i
]
=
sumexp
[
h_i
]
*
alpha_local
[
h_i
]
+
sumexp_i
[
h_i
]
for
h_i
,
d_i
in
T
.
Parallel
(
block_H
,
dim
//
2
):
acc_o_l
[
h_i
,
d_i
]
*=
alpha_local
[
h_i
]
T
.
copy
(
alpha_local
,
alpha_shared
)
T
.
copy
(
acc_s
,
S_shared
)
T
.
gemm
(
S_shared
,
KV_shared_0_l
,
acc_o_l
)
T
.
barrier_arrive
(
bar_sScale_and_sS_ready
)
T
.
barrier_arrive
(
bar_k_0_free
[
0
])
# Buffer 1
T
.
barrier_wait
(
bar_k_1_ready
[
0
],
(
i_i
&
1
))
T
.
clear
(
acc_s
)
T
.
gemm
(
Q_shared_l
,
KV_shared_1_l
,
acc_s
,
transpose_B
=
True
,
wg_wait
=-
1
)
T
.
gemm
(
Q_shared_r
,
KV_shared_1_r
,
acc_s
,
transpose_B
=
True
,
wg_wait
=-
1
)
T
.
gemm
(
Q_tail_shared
,
K_tail_shared_1
,
acc_s
,
transpose_B
=
True
,
wg_wait
=-
1
)
T
.
wait_wgmma
(
0
)
T
.
barrier_arrive
(
bar_sScale_and_sS_free
)
T
.
barrier_wait
(
bar_sScale_and_sS_free
,
((
i_i
*
2
+
1
)
&
1
)
^
1
)
T
.
copy
(
m_i
,
m_i_prev
)
T
.
reduce_max
(
acc_s
,
m_i
,
dim
=
1
,
clear
=
False
)
for
h_i
in
T
.
Parallel
(
block_H
):
alpha_local
[
h_i
]
=
T
.
exp2
((
m_i_prev
[
h_i
]
-
m_i
[
h_i
])
*
sm_scale
)
for
h_i
,
bi_i
in
T
.
Parallel
(
block_H
,
block_N
):
acc_s
[
h_i
,
bi_i
]
=
T
.
exp2
(
acc_s
[
h_i
,
bi_i
]
*
sm_scale
-
m_i
[
h_i
]
*
sm_scale
)
T
.
reduce_sum
(
acc_s
,
sumexp_i
,
dim
=
1
)
# is this a accumulate operator?
for
h_i
in
T
.
Parallel
(
block_H
):
sumexp
[
h_i
]
=
sumexp
[
h_i
]
*
alpha_local
[
h_i
]
+
sumexp_i
[
h_i
]
for
h_i
,
d_i
in
T
.
Parallel
(
block_H
,
dim
//
2
):
acc_o_l
[
h_i
,
d_i
]
*=
alpha_local
[
h_i
]
T
.
copy
(
alpha_local
,
alpha_shared
)
T
.
copy
(
acc_s
,
S_shared
)
T
.
gemm
(
S_shared
,
KV_shared_1_l
,
acc_o_l
)
T
.
barrier_arrive
(
bar_sScale_and_sS_ready
)
T
.
barrier_arrive
(
bar_k_1_free
[
0
])
# Rescale
for
h_i
in
T
.
Parallel
(
block_H
):
sum_exp_shared
[
h_i
]
=
sumexp
[
h_i
]
for
h_i
,
d_i
in
T
.
Parallel
(
block_H
,
dim
//
2
):
acc_o_l
[
h_i
,
d_i
]
/=
sumexp
[
h_i
]
for
h_i
in
T
.
Parallel
(
block_H
):
sumexp
[
h_i
]
=
T
.
log2
(
sumexp
[
h_i
])
+
m_i
[
h_i
]
*
sm_scale
T
.
copy
(
acc_o_l
,
O_shared_l
)
T
.
copy
(
O_shared_l
,
Output_partial
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
bz
,
0
:
dim
//
2
])
T
.
copy
(
sumexp
,
glse
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
bz
])
elif
tx
>=
128
and
tx
<
256
:
T
.
set_max_nreg
(
168
,
1
)
T
.
fill
(
acc_o_r
,
0
)
for
i_i
in
T
.
serial
(
T
.
ceildiv
(
NI
,
2
)):
# Buffer 0
T
.
barrier_arrive
(
bar_sScale_and_sS_ready
)
T
.
barrier_wait
(
bar_sScale_and_sS_ready
,
((
i_i
*
2
)
&
1
))
for
h_i
,
d_i
in
T
.
Parallel
(
block_H
,
dim
//
2
):
acc_o_r
[
h_i
,
d_i
]
*=
alpha_shared
[
h_i
]
T
.
gemm
(
S_shared
,
KV_shared_0_r
,
acc_o_r
)
T
.
barrier_arrive
(
bar_k_0_free
[
0
])
T
.
barrier_arrive
(
bar_sScale_and_sS_free
)
# Buffer 1
T
.
barrier_arrive
(
bar_sScale_and_sS_ready
)
T
.
barrier_wait
(
bar_sScale_and_sS_ready
,
((
i_i
*
2
+
1
)
&
1
))
for
h_i
,
d_i
in
T
.
Parallel
(
block_H
,
dim
//
2
):
acc_o_r
[
h_i
,
d_i
]
*=
alpha_shared
[
h_i
]
T
.
gemm
(
S_shared
,
KV_shared_1_r
,
acc_o_r
)
T
.
barrier_arrive
(
bar_k_1_free
[
0
])
if
i_i
!=
T
.
ceildiv
(
NI
,
2
)
-
1
:
T
.
barrier_arrive
(
bar_sScale_and_sS_free
)
# Rescale
for
h_i
,
d_i
in
T
.
Parallel
(
block_H
,
dim
//
2
):
acc_o_r
[
h_i
,
d_i
]
/=
sum_exp_shared
[
h_i
]
T
.
copy
(
acc_o_r
,
O_shared_r
)
T
.
copy
(
O_shared_r
,
Output_partial
[
bid
,
hid
*
VALID_BLOCK_H
:(
hid
+
1
)
*
VALID_BLOCK_H
,
bz
,
dim
//
2
:
dim
])
elif
tx
>=
256
:
# producer
T
.
set_max_nreg
(
80
,
0
)
for
i_i
in
T
.
serial
(
T
.
ceildiv
(
NI
,
2
)):
# Buffer 0
T
.
barrier_wait
(
bar_k_0_free
[
0
],
((
i_i
&
1
)
^
1
))
for
r
in
T
.
serial
(
4
):
kv_indices
=
(
seqlen_kv
//
num_split
)
*
bz
+
(
i_i
*
2
)
*
block_N
+
r
*
16
+
(
tx
-
256
)
//
8
with
T
.
attr
(
"default"
,
"async_scope"
,
1
):
for
u
in
T
.
serial
(
4
):
for
v
in
T
.
vectorized
(
8
):
KV_shared_0_l
[
r
*
16
+
(
tx
-
256
)
//
8
,
64
*
u
+
(
tx
-
256
)
%
8
*
8
+
v
]
=
KV
[
bid
,
kv_indices
,
cur_kv_head
,
64
*
u
+
(
tx
-
256
)
%
8
*
8
+
v
]
KV_shared_0_r
[
r
*
16
+
(
tx
-
256
)
//
8
,
64
*
u
+
(
tx
-
256
)
%
8
*
8
+
v
]
=
KV
[
bid
,
kv_indices
,
cur_kv_head
,
dim
//
2
+
64
*
u
+
(
tx
-
256
)
%
8
*
8
+
v
]
with
T
.
attr
(
"default"
,
"async_scope"
,
1
):
for
v
in
T
.
vectorized
(
8
):
K_tail_shared_0
[
r
*
16
+
(
tx
-
256
)
//
8
,
(
tx
-
256
)
%
8
*
8
+
v
]
=
K_pe
[
bid
,
kv_indices
,
cur_kv_head
,
(
tx
-
256
)
%
8
*
8
+
v
]
T
.
cp_async_barrier_noinc
(
bar_k_0_ready
[
0
])
# Buffer 1
T
.
barrier_wait
(
bar_k_1_free
[
0
],
((
i_i
&
1
)
^
1
))
for
r
in
T
.
serial
(
4
):
kv_indices
=
(
seqlen_kv
//
num_split
)
*
bz
+
(
i_i
*
2
+
1
)
*
block_N
+
r
*
16
+
(
tx
-
256
)
//
8
with
T
.
attr
(
"default"
,
"async_scope"
,
1
):
for
u
in
T
.
serial
(
4
):
for
v
in
T
.
vectorized
(
8
):
KV_shared_1_l
[
r
*
16
+
(
tx
-
256
)
//
8
,
64
*
u
+
(
tx
-
256
)
%
8
*
8
+
v
]
=
KV
[
bid
,
kv_indices
,
cur_kv_head
,
64
*
u
+
(
tx
-
256
)
%
8
*
8
+
v
]
KV_shared_1_r
[
r
*
16
+
(
tx
-
256
)
//
8
,
64
*
u
+
(
tx
-
256
)
%
8
*
8
+
v
]
=
KV
[
bid
,
kv_indices
,
cur_kv_head
,
dim
//
2
+
64
*
u
+
(
tx
-
256
)
%
8
*
8
+
v
]
with
T
.
attr
(
"default"
,
"async_scope"
,
1
):
for
v
in
T
.
vectorized
(
8
):
K_tail_shared_1
[
r
*
16
+
(
tx
-
256
)
//
8
,
(
tx
-
256
)
%
8
*
8
+
v
]
=
K_pe
[
bid
,
kv_indices
,
cur_kv_head
,
(
tx
-
256
)
%
8
*
8
+
v
]
T
.
cp_async_barrier_noinc
(
bar_k_1_ready
[
0
])
@
T
.
macro
def
combine
(
glse
:
T
.
Tensor
([
batch
,
heads
,
num_split
],
dtype
),
Output_partial
:
T
.
Tensor
([
batch
,
heads
,
num_split
,
dim
],
dtype
),
Output
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
):
with
T
.
Kernel
(
heads
,
batch
,
threads
=
128
)
as
(
hid
,
bz
):
po_local
=
T
.
alloc_fragment
([
dim
],
dtype
)
o_accum_local
=
T
.
alloc_fragment
([
dim
],
accum_dtype
)
lse_local_split
=
T
.
alloc_local
([
1
],
accum_dtype
)
lse_logsum_local
=
T
.
alloc_local
([
1
],
accum_dtype
)
lse_max_local
=
T
.
alloc_local
([
1
],
accum_dtype
)
scale_local
=
T
.
alloc_local
([
1
],
accum_dtype
)
T
.
annotate_layout
({
lse_logsum_local
:
T
.
Fragment
(
lse_logsum_local
.
shape
,
forward_thread_fn
=
lambda
i
:
i
),
})
T
.
clear
(
lse_logsum_local
)
T
.
clear
(
o_accum_local
)
lse_max_local
[
0
]
=
-
T
.
infinity
(
accum_dtype
)
for
k
in
T
.
serial
(
num_split
):
lse_max_local
[
0
]
=
T
.
max
(
lse_max_local
[
0
],
glse
[
bz
,
hid
,
k
])
for
k
in
T
.
Pipelined
(
num_split
,
num_stages
=
1
):
lse_local_split
[
0
]
=
glse
[
bz
,
hid
,
k
]
lse_logsum_local
[
0
]
+=
T
.
exp2
(
lse_local_split
[
0
]
-
lse_max_local
[
0
])
lse_logsum_local
[
0
]
=
T
.
log2
(
lse_logsum_local
[
0
])
+
lse_max_local
[
0
]
for
k
in
T
.
serial
(
num_split
):
for
i
in
T
.
Parallel
(
dim
):
po_local
[
i
]
=
Output_partial
[
bz
,
hid
,
k
,
i
]
lse_local_split
[
0
]
=
glse
[
bz
,
hid
,
k
]
scale_local
[
0
]
=
T
.
exp2
(
lse_local_split
[
0
]
-
lse_logsum_local
[
0
])
for
i
in
T
.
Parallel
(
dim
):
o_accum_local
[
i
]
+=
po_local
[
i
]
*
scale_local
[
0
]
for
i
in
T
.
Parallel
(
dim
):
Output
[
bz
,
hid
,
i
]
=
o_accum_local
[
i
]
@
T
.
prim_func
def
main_split
(
Q
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
Q_pe
:
T
.
Tensor
([
batch
,
heads
,
pe_dim
],
dtype
),
KV
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
dim
],
dtype
),
K_pe
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
pe_dim
],
dtype
),
glse
:
T
.
Tensor
([
batch
,
heads
,
num_split
],
dtype
),
Output_partial
:
T
.
Tensor
([
batch
,
heads
,
num_split
,
dim
],
dtype
),
Output
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
):
flash_attn_split
(
Q
,
Q_pe
,
KV
,
K_pe
,
glse
,
Output_partial
)
combine
(
glse
,
Output_partial
,
Output
)
@
T
.
prim_func
def
main_no_split
(
Q
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
Q_pe
:
T
.
Tensor
([
batch
,
heads
,
pe_dim
],
dtype
),
KV
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
dim
],
dtype
),
K_pe
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
pe_dim
],
dtype
),
glse
:
T
.
Tensor
([
batch
,
heads
,
num_split
],
dtype
),
Output_partial
:
T
.
Tensor
([
batch
,
heads
,
num_split
,
dim
],
dtype
),
Output
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
):
flash_attn
(
Q
,
Q_pe
,
KV
,
K_pe
,
Output
)
if
num_split
>
1
:
return
main_split
else
:
return
main_no_split
def
ref_program
(
q
,
q_pe
,
kv
,
k_pe
,
glse
,
Output_partial
):
# """
# Inputs:
# - q (Tensor): [batch, heads, dim]
# - q_pe (Tensor): [batch, heads, pe_dim]
# - kv (Tensor): [batch, seqlen_kv, kv_head_num, dim]
# - k_pe (Tensor): [batch, seqlen_kv, kv_head_num, pe_dim]
# - glse (Tensor): [batch, heads, num_split]
# - Output_partial (Tensor): [batch, heads, num_split, dim]
# Outputs:
# - output (Tensor): [batch, heads, dim]
# """
dim
=
q
.
shape
[
-
1
]
pe_dim
=
q_pe
.
shape
[
-
1
]
num_head_groups
=
q
.
shape
[
1
]
//
kv
.
shape
[
2
]
scale
=
(
dim
+
pe_dim
)
**
0.5
q
=
rearrange
(
q
,
'b (h g) d -> b g h d'
,
g
=
num_head_groups
)
# [batch_size, num_head_groups, groups, dim]
q_pe
=
rearrange
(
q_pe
,
'b (h g) d -> b g h d'
,
g
=
num_head_groups
)
# [batch_size, num_head_groups, groups, pe_dim]
kv
=
rearrange
(
kv
,
'b n h d -> b h n d'
)
# [batch_size, groups, seqlen_kv, dim]
k_pe
=
rearrange
(
k_pe
,
'b n h d -> b h n d'
)
# [batch_size, num_head_groups, groups, pe_dim]
query
=
torch
.
concat
([
q
,
q_pe
],
dim
=-
1
)
key
=
torch
.
concat
([
kv
,
k_pe
],
dim
=-
1
)
scores
=
einsum
(
query
,
key
,
'b g h d, b h s d -> b g h s'
)
# [batch_size, num_head_groups, groups, seqlen_kv]
attention
=
F
.
softmax
(
scores
/
scale
,
dim
=-
1
)
# [batch_size, num_head_groups, groups, seqlen_kv]
out
=
einsum
(
attention
,
kv
,
'b g h s, b h s d -> b g h d'
)
# [batch_size, num_head_groups, groups, dim]
out
=
rearrange
(
out
,
'b g h d -> b (h g) d'
)
# [batch_size, heads, dim]
return
out
def
main
(
batch
=
1
,
heads
=
128
,
kv_heads
=
1
,
kv_ctx
=
8192
,
dim
=
512
,
pe_dim
=
64
,
):
qk_flops
=
2
*
batch
*
heads
*
kv_ctx
*
(
dim
+
pe_dim
)
pv_flops
=
2
*
batch
*
heads
*
kv_ctx
*
dim
total_flops
=
qk_flops
+
pv_flops
BLOCK_N
=
64
BLOCK_H
=
min
(
64
,
heads
//
kv_heads
)
num_split
=
1
softmax_scale
=
(
dim
+
pe_dim
)
**-
0.5
kernel
=
flashattn
(
batch
,
heads
,
kv_heads
,
kv_ctx
,
dim
,
pe_dim
,
BLOCK_N
,
BLOCK_H
,
num_split
,
softmax_scale
)
profiler
=
kernel
.
get_profiler
(
tensor_supply_type
=
tilelang
.
TensorSupplyType
.
Randn
)
profiler
.
assert_allclose
(
ref_program
,
rtol
=
1e-4
,
atol
=
1e-4
)
latency
=
profiler
.
do_bench
(
warmup
=
500
)
print
(
f
"Latency:
{
latency
}
ms"
)
print
(
f
"TFlops:
{
total_flops
/
latency
*
1e-9
}
TFlops"
)
if
__name__
==
"__main__"
:
parser
=
argparse
.
ArgumentParser
()
parser
.
add_argument
(
'--batch'
,
type
=
int
,
default
=
132
,
help
=
'batch size'
)
parser
.
add_argument
(
'--heads'
,
type
=
int
,
default
=
128
,
help
=
'q heads number'
)
parser
.
add_argument
(
'--kv_heads'
,
type
=
int
,
default
=
1
,
help
=
'kv heads number'
)
parser
.
add_argument
(
'--kv_ctx'
,
type
=
int
,
default
=
8192
,
help
=
'kv context length'
)
parser
.
add_argument
(
'--dim'
,
type
=
int
,
default
=
512
,
help
=
'head dim'
)
parser
.
add_argument
(
'--pe_dim'
,
type
=
int
,
default
=
64
,
help
=
'pe head dim'
)
args
=
parser
.
parse_args
()
batch
,
heads
,
kv_heads
,
kv_ctx
,
dim
,
pe_dim
=
args
.
batch
,
args
.
heads
,
args
.
kv_heads
,
args
.
kv_ctx
,
args
.
dim
,
args
.
pe_dim
main
(
batch
,
heads
,
kv_heads
,
kv_ctx
,
dim
,
pe_dim
)
examples/deepseek_mla/experimental/example_mla_decode_kv_fp8.py
0 → 100644
View file @
bc2d5632
import
torch
import
torch.nn.functional
as
F
import
tilelang
from
tilelang.autotuner
import
*
import
tilelang.language
as
T
from
einops
import
rearrange
,
einsum
import
argparse
@
tilelang
.
jit
(
out_idx
=
[
-
1
],
pass_configs
=
{
tilelang
.
PassConfigKey
.
TL_ENABLE_FAST_MATH
:
True
,
})
def
flashattn
(
batch
,
heads
,
kv_head_num
,
seqlen_kv
,
dim
,
pe_dim
,
block_N
,
block_H
):
scale
=
(
1.0
/
(
dim
+
pe_dim
))
**
0.5
*
1.44269504
# log2(e)
dtype
=
"float16"
q_dtype
=
"float8_e4m3"
accum_dtype
=
"float"
kv_group_num
=
heads
//
kv_head_num
VALID_BLOCK_H
=
min
(
block_H
,
kv_group_num
)
assert
kv_head_num
==
1
,
"kv_head_num must be 1"
@
T
.
prim_func
def
main_no_split
(
Q
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
Q_pe
:
T
.
Tensor
([
batch
,
heads
,
pe_dim
],
dtype
),
KV
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
dim
],
q_dtype
),
K_pe
:
T
.
Tensor
([
batch
,
seqlen_kv
,
kv_head_num
,
pe_dim
],
dtype
),
Output
:
T
.
Tensor
([
batch
,
heads
,
dim
],
dtype
),
):
with
T
.
Kernel
(
batch
,
heads
//
min
(
block_H
,
kv_group_num
),
threads
=
256
)
as
(
bx
,
by
):
Q_shared
=
T
.
alloc_shared
([
block_H
,
dim
],
dtype
)
S_shared
=
T
.
alloc_shared
([
block_H
,
block_N
],
dtype
)
Q_pe_shared
=
T
.
alloc_shared
([
block_H
,
pe_dim
],
dtype
)
qKV_shared
=
T
.
alloc_shared
([
block_N
,
dim
],
q_dtype
)
KV_shared
=
T
.
alloc_shared
([
block_N
,
dim
],
dtype
)
K_pe_shared
=
T
.
alloc_shared
([
block_N
,
pe_dim
],
dtype
)
O_shared
=
T
.
alloc_shared
([
block_H
,
dim
],
dtype
)
acc_s
=
T
.
alloc_fragment
([
block_H
,
block_N
],
accum_dtype
)
acc_o
=
T
.
alloc_fragment
([
block_H
,
dim
],
accum_dtype
)
scores_max
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_max_prev
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_scale
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
scores_sum
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
logsum
=
T
.
alloc_fragment
([
block_H
],
accum_dtype
)
cur_kv_head
=
by
//
(
kv_group_num
//
block_H
)
T
.
use_swizzle
(
10
)
T
.
annotate_layout
({
O_shared
:
tilelang
.
layout
.
make_swizzled_layout
(
O_shared
),
})
T
.
copy
(
Q
[
bx
,
by
*
VALID_BLOCK_H
:(
by
+
1
)
*
VALID_BLOCK_H
,
:],
Q_shared
)
T
.
copy
(
Q_pe
[
bx
,
by
*
VALID_BLOCK_H
:(
by
+
1
)
*
VALID_BLOCK_H
,
:],
Q_pe_shared
)
T
.
fill
(
acc_o
,
0
)
T
.
fill
(
logsum
,
0
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
T
.
disable_warp_group_reg_alloc
()
loop_range
=
T
.
ceildiv
(
seqlen_kv
,
block_N
)
for
k
in
T
.
Pipelined
(
loop_range
,
num_stages
=
2
):
T
.
copy
(
KV
[
bx
,
k
*
block_N
:(
k
+
1
)
*
block_N
,
cur_kv_head
,
:],
qKV_shared
)
T
.
copy
(
K_pe
[
bx
,
k
*
block_N
:(
k
+
1
)
*
block_N
,
cur_kv_head
,
:],
K_pe_shared
)
T
.
copy
(
qKV_shared
,
KV_shared
)
T
.
clear
(
acc_s
)
T
.
gemm
(
Q_shared
,
KV_shared
,
acc_s
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
)
T
.
gemm
(
Q_pe_shared
,
K_pe_shared
,
acc_s
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
)
T
.
copy
(
scores_max
,
scores_max_prev
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
T
.
reduce_max
(
acc_s
,
scores_max
,
dim
=
1
,
clear
=
False
)
for
i
in
T
.
Parallel
(
block_H
):
scores_scale
[
i
]
=
T
.
exp2
(
scores_max_prev
[
i
]
*
scale
-
scores_max
[
i
]
*
scale
)
for
i
,
j
in
T
.
Parallel
(
block_H
,
block_N
):
acc_s
[
i
,
j
]
=
T
.
exp2
(
acc_s
[
i
,
j
]
*
scale
-
scores_max
[
i
]
*
scale
)
T
.
reduce_sum
(
acc_s
,
scores_sum
,
dim
=
1
)
T
.
copy
(
acc_s
,
S_shared
)
for
i
in
T
.
Parallel
(
block_H
):
logsum
[
i
]
=
logsum
[
i
]
*
scores_scale
[
i
]
+
scores_sum
[
i
]
for
i
,
j
in
T
.
Parallel
(
block_H
,
dim
):
acc_o
[
i
,
j
]
*=
scores_scale
[
i
]
T
.
gemm
(
S_shared
,
KV_shared
,
acc_o
,
policy
=
T
.
GemmWarpPolicy
.
FullCol
)
for
i
,
j
in
T
.
Parallel
(
block_H
,
dim
):
acc_o
[
i
,
j
]
/=
logsum
[
i
]
T
.
copy
(
acc_o
,
O_shared
)
T
.
copy
(
O_shared
,
Output
[
bx
,
by
*
VALID_BLOCK_H
:(
by
+
1
)
*
VALID_BLOCK_H
,
:])
return
main_no_split
def
ref_program
(
q
,
q_pe
,
kv
,
k_pe
):
# """
# Inputs:
# - q (Tensor): [batch, heads, dim]
# - q_pe (Tensor): [batch, heads, pe_dim]
# - kv (Tensor): [batch, seqlen_kv, kv_head_num, dim]
# - k_pe (Tensor): [batch, seqlen_kv, kv_head_num, pe_dim]
# Outputs:
# - output (Tensor): [batch, heads, dim]
# """
dim
=
q
.
shape
[
-
1
]
pe_dim
=
q_pe
.
shape
[
-
1
]
num_head_groups
=
q
.
shape
[
1
]
//
kv
.
shape
[
2
]
scale
=
(
dim
+
pe_dim
)
**
0.5
q
=
rearrange
(
q
,
'b (h g) d -> b g h d'
,
g
=
num_head_groups
)
# [batch_size, num_head_groups, groups, dim]
q_pe
=
rearrange
(
q_pe
,
'b (h g) d -> b g h d'
,
g
=
num_head_groups
)
# [batch_size, num_head_groups, groups, pe_dim]
kv
=
rearrange
(
kv
,
'b n h d -> b h n d'
)
# [batch_size, groups, seqlen_kv, dim]
k_pe
=
rearrange
(
k_pe
,
'b n h d -> b h n d'
)
# [batch_size, num_head_groups, groups, pe_dim]
query
=
torch
.
concat
([
q
,
q_pe
],
dim
=-
1
)
key
=
torch
.
concat
([
kv
,
k_pe
],
dim
=-
1
)
scores
=
einsum
(
query
,
key
,
'b g h d, b h s d -> b g h s'
)
# [batch_size, num_head_groups, groups, seqlen_kv]
attention
=
F
.
softmax
(
scores
/
scale
,
dim
=-
1
)
# [batch_size, num_head_groups, groups, seqlen_kv]
out
=
einsum
(
attention
,
kv
,
'b g h s, b h s d -> b g h d'
)
# [batch_size, num_head_groups, groups, dim]
out
=
rearrange
(
out
,
'b g h d -> b (h g) d'
)
# [batch_size, heads, dim]
return
out
if
__name__
==
"__main__"
:
parser
=
argparse
.
ArgumentParser
()
parser
.
add_argument
(
'--batch'
,
type
=
int
,
default
=
128
,
help
=
'batch size'
)
parser
.
add_argument
(
'--heads'
,
type
=
int
,
default
=
128
,
help
=
'q heads number'
)
parser
.
add_argument
(
'--kv_heads'
,
type
=
int
,
default
=
1
,
help
=
'kv heads number'
)
parser
.
add_argument
(
'--kv_ctx'
,
type
=
int
,
default
=
8192
,
help
=
'kv context length'
)
parser
.
add_argument
(
'--dim'
,
type
=
int
,
default
=
512
,
help
=
'head dim'
)
parser
.
add_argument
(
'--pe_dim'
,
type
=
int
,
default
=
64
,
help
=
'pe head dim'
)
args
=
parser
.
parse_args
()
batch
,
heads
,
kv_heads
,
kv_ctx
,
dim
,
pe_dim
=
args
.
batch
,
args
.
heads
,
args
.
kv_heads
,
args
.
kv_ctx
,
args
.
dim
,
args
.
pe_dim
qk_flops
=
2
*
batch
*
heads
*
kv_ctx
*
(
dim
+
pe_dim
)
pv_flops
=
2
*
batch
*
heads
*
kv_ctx
*
dim
total_flops
=
qk_flops
+
pv_flops
BLOCK_N
=
64
BLOCK_H
=
64
kernel
=
flashattn
(
batch
,
heads
,
kv_heads
,
kv_ctx
,
dim
,
pe_dim
,
BLOCK_N
,
BLOCK_H
)
profiler
=
kernel
.
get_profiler
(
tensor_supply_type
=
tilelang
.
TensorSupplyType
.
Randn
)
latency
=
profiler
.
do_bench
(
warmup
=
500
)
print
(
f
"Latency:
{
latency
}
ms"
)
print
(
f
"TFlops:
{
total_flops
/
latency
*
1e-9
}
TFlops"
)
examples/deepseek_mla/figures/bs128_float16.png
0 → 100644
View file @
bc2d5632
153 KB
examples/deepseek_mla/figures/bs64_float16.png
0 → 100644
View file @
bc2d5632
154 KB
examples/deepseek_mla/figures/flashmla-amd.png
0 → 100644
View file @
bc2d5632
368 KB
examples/deepseek_mla/figures/pv_layout.jpg
0 → 100644
View file @
bc2d5632
394 KB
examples/deepseek_mla/figures/qk_layout.jpg
0 → 100644
View file @
bc2d5632
496 KB
examples/deepseek_mla/test_example_mla_decode.py
0 → 100644
View file @
bc2d5632
import
tilelang.testing
import
example_mla_decode
@
tilelang
.
testing
.
requires_cuda
@
tilelang
.
testing
.
requires_cuda_compute_version_ge
(
9
,
0
)
def
test_example_mla_decode
():
example_mla_decode
.
main
()
if
__name__
==
"__main__"
:
tilelang
.
testing
.
main
()
examples/deepseek_mla/torch_refs.py
0 → 100644
View file @
bc2d5632
import
torch
num_split
=
1
def
flash_split_ref
(
Q
,
Q_pe
,
KV
,
K_pe
):
dim
=
Q
.
shape
[
-
1
]
pe_dim
=
Q_pe
.
shape
[
-
1
]
batch
=
Q
.
size
(
0
)
nheads
=
Q
.
size
(
1
)
block_N
=
64
seqlen_kv
=
KV
.
size
(
1
)
scale
=
(
1.0
/
(
dim
+
pe_dim
))
**
0.5
*
1.44269504
# log2(e)
acc_s
=
torch
.
empty
((
batch
,
nheads
,
block_N
),
device
=
"cuda"
,
dtype
=
torch
.
float
)
acc_s_cast
=
torch
.
empty
((
batch
,
nheads
,
block_N
),
device
=
"cuda"
,
dtype
=
torch
.
float16
)
acc_o
=
torch
.
empty
((
batch
,
nheads
,
dim
),
device
=
"cuda"
,
dtype
=
torch
.
float
)
scores_max
=
torch
.
empty
((
batch
,
nheads
),
device
=
"cuda"
,
dtype
=
torch
.
float
)
scores_max_prev
=
torch
.
empty
((
batch
,
nheads
),
device
=
"cuda"
,
dtype
=
torch
.
float
)
scores_scale
=
torch
.
empty
((
batch
,
nheads
),
device
=
"cuda"
,
dtype
=
torch
.
float
)
scores_sum
=
torch
.
empty
((
batch
,
nheads
),
device
=
"cuda"
,
dtype
=
torch
.
float
)
logsum
=
torch
.
empty
((
batch
,
nheads
),
device
=
"cuda"
,
dtype
=
torch
.
float
)
gacc_o
=
torch
.
empty
((
num_split
,
batch
,
nheads
,
dim
),
device
=
"cuda"
,
dtype
=
torch
.
float
)
glogsum
=
torch
.
empty
((
num_split
,
batch
,
nheads
),
device
=
"cuda"
,
dtype
=
torch
.
float
)
Q_
=
Q
*
scale
Q_pe_
=
Q_pe
*
scale
KV_
=
KV
.
expand
(
-
1
,
-
1
,
nheads
,
-
1
)
K_pe_
=
K_pe
.
expand
(
-
1
,
-
1
,
nheads
,
-
1
)
for
ks
in
range
(
num_split
):
acc_o
.
fill_
(
0
)
logsum
.
fill_
(
0
)
scores_max
.
fill_
(
float
(
'-inf'
))
scores_max_prev
.
fill_
(
float
(
'-inf'
))
for
i
in
range
(
int
((
seqlen_kv
//
num_split
)
/
block_N
)):
acc_s
.
fill_
(
0
)
acc_s
=
torch
.
einsum
(
'bhd,bkhd->bhk'
,
Q_
,
KV_
[:,
(
seqlen_kv
//
num_split
)
*
ks
+
i
*
block_N
:(
seqlen_kv
//
num_split
)
*
ks
+
(
i
+
1
)
*
block_N
,
:,
:])
# [batch, nheads, block_N]
acc_s
+=
torch
.
einsum
(
'bhd,bkhd->bhk'
,
Q_pe_
,
K_pe_
[:,
(
seqlen_kv
//
num_split
)
*
ks
+
i
*
block_N
:(
seqlen_kv
//
num_split
)
*
ks
+
(
i
+
1
)
*
block_N
,
:,
:])
scores_max_prev
=
scores_max
scores_max
=
acc_s
.
max
(
dim
=-
1
,
keepdim
=
False
).
values
# [batch, nheads]
scores_scale
=
torch
.
exp2
(
scores_max_prev
-
scores_max
)
# [batch, nheads]
acc_o
*=
scores_scale
[:,
:,
None
]
acc_s
=
torch
.
exp2
(
acc_s
-
scores_max
[:,
:,
None
])
acc_s_cast
=
acc_s
.
to
(
torch
.
float16
)
# [batch, nheads, block_N]
acc_o
+=
torch
.
einsum
(
'bhk,bkhd->bhd'
,
acc_s_cast
,
KV_
[:,
(
seqlen_kv
//
num_split
)
*
ks
+
i
*
block_N
:(
seqlen_kv
//
num_split
)
*
ks
+
(
i
+
1
)
*
block_N
,
:,
:])
scores_sum
=
acc_s
.
sum
(
dim
=-
1
,
keepdim
=
False
)
logsum
=
logsum
*
scores_scale
+
scores_sum
acc_o
/=
logsum
[:,
:,
None
]
logsum
=
torch
.
log2
(
logsum
)
+
scores_max
gacc_o
[
ks
,
:,
:,
:]
=
acc_o
glogsum
[
ks
,
:,
:]
=
logsum
return
glogsum
.
to
(
torch
.
float16
).
permute
(
1
,
2
,
0
),
gacc_o
.
to
(
torch
.
float16
).
permute
(
1
,
2
,
0
,
3
)
def
reduce_ref
(
Q
,
Q_pe
,
KV
,
K_pe
,
glse
,
Output_partial
):
o
=
torch
.
empty_like
(
Output_partial
[:,
:,
0
,
:]).
fill_
(
0
)
lse_logsum
=
torch
.
empty_like
(
glse
[:,
:,
0
]).
fill_
(
0
)
lse_max
=
glse
.
max
(
dim
=
2
,
keepdim
=
False
).
values
for
ks
in
range
(
num_split
):
lse
=
glse
[:,
:,
ks
]
lse_logsum
+=
torch
.
exp2
(
lse
-
lse_max
)
lse_logsum
=
torch
.
log2
(
lse_logsum
)
+
lse_max
for
ks
in
range
(
num_split
):
lse
=
glse
[:,
:,
ks
]
scale
=
torch
.
exp2
(
lse
-
lse_logsum
)
o
+=
Output_partial
[:,
:,
ks
,
:]
*
scale
[:,
:,
None
]
return
o
.
to
(
torch
.
float16
)
examples/deepseek_nsa/benchmark/benchmark_nsa_fwd.py
0 → 100644
View file @
bc2d5632
# ruff: noqa
import
torch
import
time
import
argparse
import
tilelang
from
tilelang
import
language
as
T
import
tilelang.testing
from
typing
import
Optional
,
Union
from
einops
import
rearrange
,
repeat
import
triton
import
triton.language
as
tl
from
fla.ops.utils
import
prepare_token_indices
from
fla.utils
import
autocast_custom_fwd
,
contiguous
@
triton
.
heuristics
({
'USE_OFFSETS'
:
lambda
args
:
args
[
'offsets'
]
is
not
None
,
'USE_BLOCK_COUNTS'
:
lambda
args
:
isinstance
(
args
[
'block_counts'
],
torch
.
Tensor
),
})
@
triton
.
autotune
(
configs
=
[
triton
.
Config
({},
num_warps
=
num_warps
)
for
num_warps
in
[
1
]],
key
=
[
'BS'
,
'BK'
,
'BV'
],
)
@
triton
.
jit
def
parallel_nsa_fwd_kernel
(
q
,
k
,
v
,
o_slc
,
o_swa
,
lse_slc
,
lse_swa
,
scale
,
block_indices
,
block_counts
,
offsets
,
token_indices
,
T
,
H
:
tl
.
constexpr
,
HQ
:
tl
.
constexpr
,
G
:
tl
.
constexpr
,
K
:
tl
.
constexpr
,
V
:
tl
.
constexpr
,
S
:
tl
.
constexpr
,
BS
:
tl
.
constexpr
,
WS
:
tl
.
constexpr
,
BK
:
tl
.
constexpr
,
BV
:
tl
.
constexpr
,
USE_OFFSETS
:
tl
.
constexpr
,
USE_BLOCK_COUNTS
:
tl
.
constexpr
):
i_t
,
i_v
,
i_bh
=
tl
.
program_id
(
0
),
tl
.
program_id
(
1
),
tl
.
program_id
(
2
)
i_b
,
i_h
=
i_bh
//
H
,
i_bh
%
H
bos
,
eos
=
i_b
*
T
,
i_b
*
T
+
T
k
+=
(
bos
*
H
+
i_h
)
*
K
v
+=
(
bos
*
H
+
i_h
)
*
V
block_indices
+=
(
bos
+
i_t
)
*
H
*
S
+
i_h
*
S
NS
=
S
p_q
=
tl
.
make_block_ptr
(
q
+
(
bos
+
i_t
)
*
HQ
*
K
,
(
HQ
,
K
),
(
K
,
1
),
(
i_h
*
G
,
0
),
(
G
,
BK
),
(
1
,
0
))
# the Q block is kept in the shared memory throughout the whole kernel
# [G, BK]
b_q
=
tl
.
load
(
p_q
,
boundary_check
=
(
0
,
1
))
b_q
=
(
b_q
*
scale
).
to
(
b_q
.
dtype
)
p_o_slc
=
tl
.
make_block_ptr
(
o_slc
+
(
bos
+
i_t
)
*
HQ
*
V
,
(
HQ
,
V
),
(
V
,
1
),
(
i_h
*
G
,
i_v
*
BV
),
(
G
,
BV
),
(
1
,
0
))
p_lse_slc
=
lse_slc
+
(
bos
+
i_t
)
*
HQ
+
i_h
*
G
+
tl
.
arange
(
0
,
G
)
# [G, BV]
b_o_slc
=
tl
.
zeros
([
G
,
BV
],
dtype
=
tl
.
float32
)
b_m_slc
=
tl
.
full
([
G
],
float
(
'-inf'
),
dtype
=
tl
.
float32
)
b_acc_slc
=
tl
.
zeros
([
G
],
dtype
=
tl
.
float32
)
for
i
in
range
(
NS
):
i_s
=
tl
.
load
(
block_indices
+
i
).
to
(
tl
.
int32
)
*
BS
if
i_s
<=
i_t
and
i_s
>=
0
:
p_k_slc
=
tl
.
make_block_ptr
(
k
,
(
K
,
T
),
(
1
,
H
*
K
),
(
0
,
i_s
),
(
BK
,
BS
),
(
0
,
1
))
p_v_slc
=
tl
.
make_block_ptr
(
v
,
(
T
,
V
),
(
H
*
V
,
1
),
(
i_s
,
i_v
*
BV
),
(
BS
,
BV
),
(
1
,
0
))
# [BK, BS]
b_k_slc
=
tl
.
load
(
p_k_slc
,
boundary_check
=
(
0
,
1
))
# [BS, BV]
b_v_slc
=
tl
.
load
(
p_v_slc
,
boundary_check
=
(
0
,
1
))
# [G, BS]
b_s_slc
=
tl
.
dot
(
b_q
,
b_k_slc
)
b_s_slc
=
tl
.
where
((
i_t
>=
(
i_s
+
tl
.
arange
(
0
,
BS
)))[
None
,
:],
b_s_slc
,
float
(
'-inf'
))
# [G]
b_m_slc
,
b_mp_slc
=
tl
.
maximum
(
b_m_slc
,
tl
.
max
(
b_s_slc
,
1
)),
b_m_slc
b_r_slc
=
tl
.
exp
(
b_mp_slc
-
b_m_slc
)
# [G, BS]
b_p_slc
=
tl
.
exp
(
b_s_slc
-
b_m_slc
[:,
None
])
# [G]
b_acc_slc
=
b_acc_slc
*
b_r_slc
+
tl
.
sum
(
b_p_slc
,
1
)
# [G, BV]
b_o_slc
=
b_o_slc
*
b_r_slc
[:,
None
]
+
tl
.
dot
(
b_p_slc
.
to
(
b_q
.
dtype
),
b_v_slc
)
b_mp_slc
=
b_m_slc
b_o_slc
=
b_o_slc
/
b_acc_slc
[:,
None
]
b_m_slc
+=
tl
.
log
(
b_acc_slc
)
tl
.
store
(
p_o_slc
,
b_o_slc
.
to
(
p_o_slc
.
dtype
.
element_ty
),
boundary_check
=
(
0
,
1
))
tl
.
store
(
p_lse_slc
,
b_m_slc
.
to
(
p_lse_slc
.
dtype
.
element_ty
))
class
ParallelNSAFunction
(
torch
.
autograd
.
Function
):
@
staticmethod
@
contiguous
@
autocast_custom_fwd
def
forward
(
ctx
,
q
,
k
,
v
,
block_indices
,
block_size
,
scale
,
offsets
):
ctx
.
dtype
=
q
.
dtype
# 2-d sequence indices denoting the offsets of tokens in each sequence
# for example, if the passed `offsets` is [0, 2, 6],
# then there are 2 and 4 tokens in the 1st and 2nd sequences respectively, and `token_indices` will be
# [[0, 0], [0, 1], [1, 0], [1, 1], [1, 2], [1, 3]]
token_indices
=
prepare_token_indices
(
offsets
)
if
offsets
is
not
None
else
None
o
,
lse
=
parallel_nsa_fwd
(
q
=
q
,
k
=
k
,
v
=
v
,
block_indices
=
block_indices
,
block_size
=
block_size
,
scale
=
scale
)
ctx
.
save_for_backward
(
q
,
k
,
v
,
o
,
lse
)
ctx
.
block_indices
=
block_indices
ctx
.
block_size
=
block_size
ctx
.
scale
=
scale
return
o
.
to
(
q
.
dtype
)
def
parallel_nsa_fwd
(
q
:
torch
.
Tensor
,
k
:
torch
.
Tensor
,
v
:
torch
.
Tensor
,
o_slc
:
torch
.
Tensor
,
o_swa
:
Optional
[
torch
.
Tensor
],
lse_slc
:
torch
.
Tensor
,
lse_swa
:
Optional
[
torch
.
Tensor
],
block_indices
:
torch
.
LongTensor
,
block_counts
:
Union
[
torch
.
LongTensor
,
int
],
block_size
:
int
,
window_size
:
int
,
scale
:
float
,
offsets
:
Optional
[
torch
.
LongTensor
]
=
None
,
token_indices
:
Optional
[
torch
.
LongTensor
]
=
None
,
):
B
,
T
,
H
,
K
,
V
,
S
=
*
k
.
shape
,
v
.
shape
[
-
1
],
block_indices
.
shape
[
-
1
]
HQ
=
q
.
shape
[
2
]
G
=
HQ
//
H
BS
=
block_size
WS
=
window_size
if
torch
.
cuda
.
get_device_capability
()[
0
]
>=
9
:
BK
=
min
(
256
,
triton
.
next_power_of_2
(
K
))
BV
=
min
(
256
,
triton
.
next_power_of_2
(
V
))
else
:
BK
=
min
(
128
,
triton
.
next_power_of_2
(
K
))
BV
=
min
(
128
,
triton
.
next_power_of_2
(
V
))
NK
=
triton
.
cdiv
(
K
,
BK
)
NV
=
triton
.
cdiv
(
V
,
BV
)
assert
NK
==
1
,
"The key dimension can not be larger than 256"
grid
=
(
T
,
NV
,
B
*
H
)
parallel_nsa_fwd_kernel
[
grid
](
q
=
q
,
k
=
k
,
v
=
v
,
o_slc
=
o_slc
,
o_swa
=
o_swa
,
lse_slc
=
lse_slc
,
lse_swa
=
lse_swa
,
scale
=
scale
,
block_indices
=
block_indices
,
block_counts
=
block_counts
,
offsets
=
offsets
,
token_indices
=
token_indices
,
T
=
T
,
H
=
H
,
HQ
=
HQ
,
G
=
G
,
K
=
K
,
V
=
V
,
S
=
S
,
BS
=
BS
,
WS
=
WS
,
BK
=
BK
,
BV
=
BV
,
)
return
o_slc
,
lse_slc
,
o_swa
,
lse_swa
@
torch
.
compile
class
ParallelNSAFunction
(
torch
.
autograd
.
Function
):
@
staticmethod
@
contiguous
@
autocast_custom_fwd
def
forward
(
ctx
,
q
,
k
,
v
,
block_indices
,
block_counts
,
block_size
,
window_size
,
scale
,
offsets
):
ctx
.
dtype
=
q
.
dtype
# 2-d sequence indices denoting the offsets of tokens in each sequence
# for example, if the passed `offsets` is [0, 2, 6],
# then there are 2 and 4 tokens in the 1st and 2nd sequences respectively, and `token_indices` will be
# [[0, 0], [0, 1], [1, 0], [1, 1], [1, 2], [1, 3]]
token_indices
=
prepare_token_indices
(
offsets
)
if
offsets
is
not
None
else
None
o_slc
,
lse_slc
,
o_swa
,
lse_swa
=
parallel_nsa_fwd
(
q
=
q
,
k
=
k
,
v
=
v
,
block_indices
=
block_indices
,
block_counts
=
block_counts
,
block_size
=
block_size
,
window_size
=
window_size
,
scale
=
scale
,
offsets
=
offsets
,
token_indices
=
token_indices
)
ctx
.
save_for_backward
(
q
,
k
,
v
,
o_slc
,
lse_slc
,
o_swa
,
lse_swa
)
ctx
.
block_indices
=
block_indices
ctx
.
block_counts
=
block_counts
ctx
.
offsets
=
offsets
ctx
.
token_indices
=
token_indices
ctx
.
block_size
=
block_size
ctx
.
window_size
=
window_size
ctx
.
scale
=
scale
return
o_slc
.
to
(
q
.
dtype
),
o_swa
.
to
(
q
.
dtype
)
if
o_swa
is
not
None
else
o_swa
def
parallel_nsa
(
q
:
torch
.
Tensor
,
k
:
torch
.
Tensor
,
v
:
torch
.
Tensor
,
g_slc
:
torch
.
Tensor
,
g_swa
:
torch
.
Tensor
,
block_indices
:
torch
.
LongTensor
,
block_counts
:
Optional
[
Union
[
torch
.
LongTensor
,
int
]]
=
None
,
block_size
:
int
=
64
,
window_size
:
int
=
0
,
scale
:
Optional
[
float
]
=
None
,
cu_seqlens
:
Optional
[
torch
.
LongTensor
]
=
None
,
head_first
:
bool
=
False
)
->
torch
.
Tensor
:
r
"""
Args:
q (torch.Tensor):
queries of shape `[B, T, HQ, K]` if `head_first=False` else `[B, HQ, T, K]`.
k (torch.Tensor):
keys of shape `[B, T, H, K]` if `head_first=False` else `[B, H, T, K]`.
GQA is enforced here. The ratio of query heads (HQ) to key/value heads (H) must be a power of 2 and >=16.
v (torch.Tensor):
values of shape `[B, T, H, V]` if `head_first=False` else `[B, H, T, V]`.
g_slc (torch.Tensor):
Gate score for selected attention of shape `[B, T, HQ]` if `head_first=False` else `[B, HQ, T]`.
g_swa (torch.Tensor):
Gate score for sliding attentionof shape `[B, T, HQ]` if `head_first=False` else `[B, HQ, T]`.
block_indices (torch.LongTensor):
Block indices of shape `[B, T, H, S]` if `head_first=False` else `[B, H, T, S]`.
`S` is the number of selected blocks for each query token, which is set to 16 in the paper.
block_counts (Union[torch.LongTensor, int]):
Number of selected blocks for each token.
If a tensor is provided, with shape `[B, T, H]` if `head_first=True` else `[B, T, H]`,
each token can select the same number of blocks.
If not provided, it will default to `S`, Default: `None`
block_size (int):
Selected block size. Default: 64.
window_size (int):
Sliding window size. Default: 0.
scale (Optional[int]):
Scale factor for attention scores.
If not provided, it will default to `1 / sqrt(K)`. Default: `None`.
head_first (Optional[bool]):
Whether the inputs are in the head-first format. Default: `False`.
cu_seqlens (torch.LongTensor):
Cumulative sequence lengths of shape `[N+1]` used for variable-length training,
consistent with the FlashAttention API.
Returns:
o (torch.Tensor):
Outputs of shape `[B, T, HQ, V]` if `head_first=False` else `[B, HQ, T, V]`.
"""
if
scale
is
None
:
scale
=
k
.
shape
[
-
1
]
**-
0.5
if
cu_seqlens
is
not
None
:
assert
q
.
shape
[
0
]
==
1
,
"batch size must be 1 when cu_seqlens are provided"
if
head_first
:
q
,
k
,
v
,
block_indices
=
map
(
lambda
x
:
rearrange
(
x
,
'b h t d -> b t h d'
),
(
q
,
k
,
v
,
block_indices
))
g_slc
,
g_swa
=
map
(
lambda
x
:
rearrange
(
x
,
'b h t -> b t h'
),
(
g_slc
,
g_swa
))
if
isinstance
(
block_counts
,
torch
.
Tensor
):
block_counts
=
rearrange
(
block_counts
,
'b h t -> b t h'
)
assert
q
.
shape
[
2
]
%
(
k
.
shape
[
2
]
*
16
)
==
0
,
"Group size must be a multiple of 16 in NSA"
if
isinstance
(
block_counts
,
int
):
block_indices
=
block_indices
[:,
:,
:,
:
block_counts
]
block_counts
=
None
o_slc
,
o_swa
=
ParallelNSAFunction
.
apply
(
q
,
k
,
v
,
block_indices
,
block_counts
,
block_size
,
window_size
,
scale
,
cu_seqlens
)
if
window_size
>
0
:
o
=
torch
.
addcmul
(
o_slc
*
g_slc
.
unsqueeze
(
-
1
),
o_swa
,
g_swa
.
unsqueeze
(
-
1
))
else
:
o
=
o_slc
*
g_slc
.
unsqueeze
(
-
1
)
if
head_first
:
o
=
rearrange
(
o
,
'b t h d -> b h t d'
)
return
o
def
naive_nsa
(
q
:
torch
.
Tensor
,
k
:
torch
.
Tensor
,
v
:
torch
.
Tensor
,
g_slc
:
torch
.
Tensor
,
g_swa
:
torch
.
Tensor
,
block_indices
:
torch
.
LongTensor
,
block_counts
:
Optional
[
Union
[
torch
.
LongTensor
,
int
]]
=
None
,
block_size
:
int
=
64
,
window_size
:
int
=
0
,
scale
:
Optional
[
float
]
=
None
,
cu_seqlens
:
Optional
[
torch
.
LongTensor
]
=
None
,
head_first
:
bool
=
False
)
->
torch
.
Tensor
:
r
"""
Args:
q (torch.Tensor):
Queries of shape `[B, T, HQ, K]` if `head_first=False` else `[B, HQ, T, K]`.
k (torch.Tensor):
Keys of shape `[B, T, H, K]` if `head_first=False` else `[B, H, T, K]`.
GQA is enforced here. The ratio of query heads (HQ) to key/value heads (H) must be a power of 2 and >=16.
v (torch.Tensor):
Values of shape `[B, T, H, V]` if `head_first=False` else `[B, H, T, V]`.
g_slc (torch.Tensor):
Gate score for selected attention of shape `[B, T, HQ]` if `head_first=False` else `[B, HQ, T]`.
g_swa (torch.Tensor):
Gate score for sliding attentionof shape `[B, T, HQ]` if `head_first=False` else `[B, HQ, T]`.
block_indices (torch.LongTensor):
Block indices of shape `[B, T, H, S]` if `head_first=False` else `[B, H, T, S]`.
`S` is the maximum number of selected blocks for each query token, which is set to 16 in the paper.
block_counts (Union[torch.LongTensor, int]):
Number of selected blocks for each token.
If a tensor is provided, with shape `[B, T, H]` if `head_first=True` else `[B, T, H]`,
each token can select the same number of blocks.
If not provided, it will default to `S`, Default: `None`.
block_size (int):
Selected block size. Default: 64.
window_size (int):
Sliding window size. Default: 0.
scale (Optional[int]):
Scale factor for attention scores.
If not provided, it will default to `1 / sqrt(K)`. Default: `None`.
cu_seqlens (torch.LongTensor):
Cumulative sequence lengths of shape `[N+1]` used for variable-length training,
consistent with the FlashAttention API.
head_first (Optional[bool]):
Whether the inputs are in the head-first format. Default: `False`.
Returns:
o (torch.Tensor):
Outputs of shape `[B, T, HQ, V]` if `head_first=False` else `[B, HQ, T, V]`.
"""
if
scale
is
None
:
scale
=
k
.
shape
[
-
1
]
**-
0.5
if
cu_seqlens
is
not
None
:
assert
q
.
shape
[
0
]
==
1
,
"batch size must be 1 when cu_seqlens are provided"
if
head_first
:
raise
RuntimeError
(
"Sequences with variable lengths are not supported for head-first mode"
)
if
head_first
:
q
,
k
,
v
,
block_indices
=
map
(
lambda
x
:
rearrange
(
x
,
'b h t d -> b t h d'
),
(
q
,
k
,
v
,
block_indices
))
g_slc
,
g_swa
=
map
(
lambda
x
:
rearrange
(
x
,
'b h t -> b t h'
),
(
g_slc
,
g_swa
))
if
isinstance
(
block_counts
,
torch
.
Tensor
):
block_counts
=
rearrange
(
block_counts
,
'b h t -> b t h'
)
dtype
=
q
.
dtype
G
=
q
.
shape
[
2
]
//
k
.
shape
[
2
]
BS
=
block_size
S
=
block_indices
.
shape
[
-
1
]
k
,
v
,
block_indices
=
(
repeat
(
x
,
'b t h d -> b t (h g) d'
,
g
=
G
)
for
x
in
(
k
,
v
,
block_indices
))
if
isinstance
(
block_counts
,
torch
.
Tensor
):
block_counts
=
repeat
(
block_counts
,
'b t h -> b t (h g)'
,
g
=
G
)
c
=
torch
.
arange
(
S
).
repeat_interleave
(
BS
).
unsqueeze
(
1
).
expand
(
-
1
,
q
.
shape
[
2
]).
to
(
q
.
device
)
q
,
k
,
v
=
map
(
lambda
x
:
x
.
float
(),
(
q
,
k
,
v
))
o_slc
=
torch
.
zeros_like
(
v
)
o_swa
=
torch
.
zeros_like
(
v
)
if
window_size
>
0
else
None
varlen
=
True
if
cu_seqlens
is
None
:
varlen
=
False
B
,
T
=
q
.
shape
[:
2
]
cu_seqlens
=
torch
.
cat
(
[
block_indices
.
new_tensor
(
range
(
0
,
B
*
T
,
T
)),
block_indices
.
new_tensor
([
B
*
T
])])
for
i
in
range
(
len
(
cu_seqlens
)
-
1
):
if
not
varlen
:
q_b
,
k_b
,
v_b
,
g_slc_b
,
g_swa_b
,
i_b
=
q
[
i
],
k
[
i
],
v
[
i
],
g_slc
[
i
],
g_swa
[
i
],
block_indices
[
i
]
if
isinstance
(
block_counts
,
torch
.
Tensor
):
s_b
=
block_counts
[
i
]
else
:
s_b
=
block_counts
else
:
T
=
cu_seqlens
[
i
+
1
]
-
cu_seqlens
[
i
]
q_b
,
k_b
,
v_b
,
g_slc_b
,
g_swa_b
,
i_b
=
map
(
lambda
x
:
x
[
0
][
cu_seqlens
[
i
]:
cu_seqlens
[
i
+
1
]],
(
q
,
k
,
v
,
g_slc
,
g_swa
,
block_indices
))
if
isinstance
(
block_counts
,
torch
.
Tensor
):
s_b
=
block_counts
[
0
][
cu_seqlens
[
i
]:
cu_seqlens
[
i
+
1
]]
else
:
s_b
=
block_counts
i_b
=
i_b
.
unsqueeze
(
-
1
)
*
BS
+
i_b
.
new_tensor
(
range
(
BS
))
# [T, S*BS, HQ]
i_b
=
i_b
.
view
(
T
,
block_indices
.
shape
[
2
],
-
1
).
transpose
(
1
,
2
)
for
i_q
in
range
(
T
):
# [HQ, D]
q_i
=
q_b
[
i_q
]
*
scale
# [HQ]
g_slc_i
=
g_slc_b
[
i_q
]
# [HQ]
g_swa_i
=
g_swa_b
[
i_q
]
# [S*BS, HQ]
i_i
=
i_b
[
i_q
]
# [HQ]
if
isinstance
(
block_counts
,
torch
.
Tensor
):
s_i
=
s_b
[
i_q
]
else
:
s_i
=
s_b
# [S*BS, HQ, -1]
k_i_slc
,
v_i_slc
=
map
(
lambda
x
:
x
.
gather
(
0
,
i_i
.
clamp
(
0
,
T
-
1
).
unsqueeze
(
-
1
).
expand
(
*
i_i
.
shape
,
x
.
shape
[
-
1
])),
(
k_b
,
v_b
))
# [S*BS, HQ]
attn_slc
=
torch
.
einsum
(
'h d, n h d -> n h'
,
q_i
,
k_i_slc
).
masked_fill
(
torch
.
logical_or
(
i_i
<
0
,
i_i
>
i_q
)
|
(
c
>=
s_i
if
block_counts
is
not
None
else
False
),
float
(
'-inf'
)).
softmax
(
0
)
if
not
varlen
:
o_slc
[
i
,
i_q
]
=
torch
.
einsum
(
'n h, n h v -> h v'
,
attn_slc
,
v_i_slc
)
*
g_slc_i
.
unsqueeze
(
-
1
)
else
:
o_slc
[
0
][
cu_seqlens
[
i
]
+
i_q
]
=
torch
.
einsum
(
'n h, n h v -> h v'
,
attn_slc
,
v_i_slc
)
*
g_slc_i
.
unsqueeze
(
-
1
)
if
window_size
>
0
:
k_i_swa
,
v_i_swa
=
map
(
lambda
x
:
x
[
max
(
0
,
i_q
-
window_size
+
1
):
i_q
+
1
],
(
k_b
,
v_b
))
attn_swa
=
torch
.
einsum
(
'h d, n h d -> n h'
,
q_i
,
k_i_swa
).
softmax
(
0
)
if
not
varlen
:
o_swa
[
i
,
i_q
]
=
torch
.
einsum
(
'n h, n h v -> h v'
,
attn_swa
,
v_i_swa
)
*
g_swa_i
.
unsqueeze
(
-
1
)
else
:
o_swa
[
0
][
cu_seqlens
[
i
]
+
i_q
]
=
torch
.
einsum
(
'n h, n h v -> h v'
,
attn_swa
,
v_i_swa
)
*
g_swa_i
.
unsqueeze
(
-
1
)
if
head_first
:
o_slc
=
rearrange
(
o_slc
,
'b t h d -> b h t d'
)
o_swa
=
rearrange
(
o_swa
,
'b t h d -> b h t d'
)
return
o_slc
.
to
(
dtype
)
+
o_swa
.
to
(
dtype
)
if
o_swa
is
not
None
else
o_slc
.
to
(
dtype
)
def
get_configs
():
import
itertools
iter_params
=
dict
(
block_T
=
[
128
,
256
,
512
],
num_stages
=
[
0
,
1
,
2
,
4
,
5
],
threads
=
[
32
,
64
,
128
,
256
,
512
],
)
return
[{
k
:
v
for
k
,
v
in
zip
(
iter_params
,
values
)
}
for
values
in
itertools
.
product
(
*
iter_params
.
values
())]
@
tilelang
.
autotune
(
configs
=
get_configs
(),)
@
tilelang
.
jit
(
pass_configs
=
{
tilelang
.
PassConfigKey
.
TL_ENABLE_FAST_MATH
:
True
,
tilelang
.
PassConfigKey
.
TL_DISABLE_TMA_LOWER
:
True
,
tilelang
.
PassConfigKey
.
TL_DISABLE_WARP_SPECIALIZED
:
True
,
})
def
tilelang_sparse_attention
(
batch
,
heads
,
seq_len
,
dim
,
is_causal
,
scale
=
None
,
block_size
=
64
,
groups
=
1
,
selected_blocks
=
16
,
block_T
=
128
,
num_stages
=
2
,
threads
=
32
):
if
scale
is
None
:
scale
=
(
1.0
/
dim
)
**
0.5
*
1.44269504
# log2(e)
else
:
scale
=
scale
*
1.44269504
# log2(e)
head_kv
=
heads
//
groups
q_shape
=
[
batch
,
seq_len
,
heads
,
dim
]
kv_shape
=
[
batch
,
seq_len
,
head_kv
,
dim
]
block_indices_shape
=
[
batch
,
seq_len
,
head_kv
,
selected_blocks
]
block_indices_dtype
=
"int32"
dtype
=
"float16"
accum_dtype
=
"float"
block_S
=
block_size
block_T
=
min
(
block_T
,
tilelang
.
math
.
next_power_of_2
(
dim
))
NK
=
tilelang
.
cdiv
(
dim
,
block_T
)
NV
=
tilelang
.
cdiv
(
dim
,
block_T
)
assert
NK
==
1
,
"The key dimension can not be larger than 256"
S
=
selected_blocks
G
=
groups
BS
=
block_S
BK
=
BV
=
block_T
@
T
.
prim_func
def
tilelang_sparse_attention
(
Q
:
T
.
Tensor
(
q_shape
,
dtype
),
K
:
T
.
Tensor
(
kv_shape
,
dtype
),
V
:
T
.
Tensor
(
kv_shape
,
dtype
),
BlockIndices
:
T
.
Tensor
(
block_indices_shape
,
block_indices_dtype
),
Output
:
T
.
Tensor
(
q_shape
,
dtype
),
):
with
T
.
Kernel
(
seq_len
,
NV
,
batch
*
head_kv
,
threads
=
threads
)
as
(
bx
,
by
,
bz
):
Q_shared
=
T
.
alloc_shared
([
G
,
BK
],
dtype
)
K_shared
=
T
.
alloc_shared
([
BS
,
BK
],
dtype
)
V_shared
=
T
.
alloc_shared
([
BS
,
BV
],
dtype
)
O_shared
=
T
.
alloc_shared
([
G
,
BV
],
dtype
)
acc_s
=
T
.
alloc_fragment
([
G
,
BS
],
accum_dtype
)
acc_s_cast
=
T
.
alloc_shared
([
G
,
BS
],
dtype
)
acc_o
=
T
.
alloc_fragment
([
G
,
BV
],
accum_dtype
)
scores_max
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
scores_max_prev
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
scores_scale
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
scores_sum
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
logsum
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
T
.
annotate_layout
({
O_shared
:
tilelang
.
layout
.
make_swizzled_layout
(
O_shared
)})
i_t
,
i_v
,
i_bh
=
bx
,
by
,
bz
i_b
,
i_h
=
i_bh
//
head_kv
,
i_bh
%
head_kv
NS
=
S
T
.
copy
(
Q
[
i_b
,
i_t
,
i_h
*
G
:(
i_h
+
1
)
*
G
,
:],
Q_shared
)
T
.
fill
(
acc_o
,
0
)
T
.
fill
(
logsum
,
0
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
for
i
in
T
.
Pipelined
(
NS
,
num_stages
=
num_stages
):
i_s
=
BlockIndices
[
i_b
,
i_t
,
i_h
,
i
]
*
BS
if
i_s
<=
i_t
and
i_s
>=
0
:
# [BS, BK]
T
.
copy
(
K
[
i_b
,
i_s
:
i_s
+
BS
,
i_h
,
:],
K_shared
)
if
is_causal
:
for
i
,
j
in
T
.
Parallel
(
G
,
BS
):
acc_s
[
i
,
j
]
=
T
.
if_then_else
(
i_t
>=
(
i_s
+
j
),
0
,
-
T
.
infinity
(
acc_s
.
dtype
))
else
:
T
.
clear
(
acc_s
)
T
.
gemm
(
Q_shared
,
K_shared
,
acc_s
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
)
# Softmax
T
.
copy
(
scores_max
,
scores_max_prev
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
T
.
reduce_max
(
acc_s
,
scores_max
,
dim
=
1
,
clear
=
True
)
for
i
in
T
.
Parallel
(
G
):
scores_scale
[
i
]
=
T
.
exp2
(
scores_max_prev
[
i
]
*
scale
-
scores_max
[
i
]
*
scale
)
for
i
,
j
in
T
.
Parallel
(
G
,
BS
):
acc_s
[
i
,
j
]
=
T
.
exp2
(
acc_s
[
i
,
j
]
*
scale
-
scores_max
[
i
]
*
scale
)
T
.
reduce_sum
(
acc_s
,
scores_sum
,
dim
=
1
)
for
i
in
T
.
Parallel
(
G
):
logsum
[
i
]
=
logsum
[
i
]
*
scores_scale
[
i
]
+
scores_sum
[
i
]
T
.
copy
(
acc_s
,
acc_s_cast
)
# Rescale
for
i
,
j
in
T
.
Parallel
(
G
,
BV
):
acc_o
[
i
,
j
]
*=
scores_scale
[
i
]
# V * softmax(Q * K)
T
.
copy
(
V
[
i_b
,
i_s
:
i_s
+
BS
,
i_h
,
i_v
*
BV
:(
i_v
+
1
)
*
BV
],
V_shared
)
T
.
gemm
(
acc_s_cast
,
V_shared
,
acc_o
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
)
for
i
,
j
in
T
.
Parallel
(
G
,
BV
):
acc_o
[
i
,
j
]
/=
logsum
[
i
]
T
.
copy
(
acc_o
,
O_shared
)
T
.
copy
(
O_shared
,
Output
[
i_b
,
i_t
,
i_h
*
G
:(
i_h
+
1
)
*
G
,
i_v
*
BV
:(
i_v
+
1
)
*
BV
])
return
tilelang_sparse_attention
def
generate_block_indices
(
batch
,
seq_len
,
heads
,
selected_blocks
,
block_size
):
"""Generate random block indices for the benchmark."""
block_indices
=
torch
.
full
((
batch
,
seq_len
,
heads
,
selected_blocks
),
seq_len
,
dtype
=
torch
.
long
,
device
=
'cuda'
)
for
b
in
range
(
batch
):
for
t
in
range
(
seq_len
):
for
h
in
range
(
heads
):
i_i
=
torch
.
randperm
(
max
(
1
,
(
t
//
block_size
)))[:
selected_blocks
]
block_indices
[
b
,
t
,
h
,
:
len
(
i_i
)]
=
i_i
return
block_indices
.
sort
(
-
1
)[
0
]
def
benchmark_nsa
(
batch_size
,
seq_len
,
heads
,
head_query
,
dim
,
selected_blocks
,
block_size
,
dtype
,
scale
,
warmup
=
10
,
iterations
=
100
,
validate
=
False
):
"""Benchmark the TileLang Sparse Attention implementation."""
# Set random seed for reproducibility
tilelang
.
testing
.
set_random_seed
(
0
)
torch
.
random
.
manual_seed
(
0
)
# Compile the NSA kernel
kernel
=
tilelang_sparse_attention
(
batch
=
batch_size
,
heads
=
head_query
,
seq_len
=
seq_len
,
dim
=
dim
,
is_causal
=
True
,
block_size
=
block_size
,
groups
=
head_query
//
heads
,
selected_blocks
=
selected_blocks
,
scale
=
scale
,
)
profiler
=
kernel
.
get_profiler
()
profiler_latency
=
profiler
.
do_bench
()
print
(
f
"Profiler latency:
{
profiler_latency
}
ms"
)
# Create input tensors
Q
=
torch
.
randn
((
batch_size
,
seq_len
,
head_query
,
dim
),
dtype
=
dtype
,
device
=
'cuda'
)
K
=
torch
.
randn
((
batch_size
,
seq_len
,
heads
,
dim
),
dtype
=
dtype
,
device
=
'cuda'
)
V
=
torch
.
randn
((
batch_size
,
seq_len
,
heads
,
dim
),
dtype
=
dtype
,
device
=
'cuda'
)
out
=
torch
.
empty
((
batch_size
,
seq_len
,
head_query
,
dim
),
dtype
=
dtype
,
device
=
'cuda'
)
# Generate block indices
block_indices
=
generate_block_indices
(
batch_size
,
seq_len
,
heads
,
selected_blocks
,
block_size
).
to
(
torch
.
int32
)
# Warmup
for
_
in
range
(
warmup
):
kernel
(
Q
,
K
,
V
,
block_indices
,
out
)
# Synchronize before timing
torch
.
cuda
.
synchronize
()
# Benchmark
start_time
=
time
.
time
()
for
_
in
range
(
iterations
):
kernel
(
Q
,
K
,
V
,
block_indices
,
out
)
torch
.
cuda
.
synchronize
()
end_time
=
time
.
time
()
# Calculate metrics
elapsed_time
=
end_time
-
start_time
avg_time
=
elapsed_time
/
iterations
*
1000
# ms
# Calculate FLOPs (approximate for NSA)
# Each token attends to selected_blocks * block_size tokens
# Each attention calculation involves 2*dim FLOPs for QK
# And another 2*dim FLOPs for attention * V
flops_per_token
=
4
*
dim
*
selected_blocks
*
block_size
total_flops
=
batch_size
*
seq_len
*
head_query
*
flops_per_token
flops_per_sec
=
total_flops
/
(
elapsed_time
/
iterations
)
tflops
=
flops_per_sec
/
1e12
# Validate result against reference if requested
if
validate
:
g_slc
=
torch
.
ones
((
batch_size
,
seq_len
,
head_query
),
dtype
=
dtype
,
device
=
'cuda'
)
g_swa
=
torch
.
ones
((
batch_size
,
seq_len
,
head_query
),
dtype
=
dtype
,
device
=
'cuda'
)
block_counts
=
torch
.
randint
(
1
,
selected_blocks
+
1
,
(
batch_size
,
seq_len
,
heads
),
device
=
'cuda'
)
ref
=
naive_nsa
(
q
=
Q
,
k
=
K
,
v
=
V
,
g_slc
=
g_slc
,
g_swa
=
g_swa
,
block_indices
=
block_indices
,
block_counts
=
block_counts
,
block_size
=
block_size
,
scale
=
scale
,
)
is_valid
=
torch
.
allclose
(
ref
,
out
,
atol
=
1e-2
,
rtol
=
1e-2
)
if
is_valid
:
print
(
"Validation: PASSED"
)
else
:
print
(
"Validation: FAILED"
)
print
(
f
"Max difference:
{
(
ref
-
out
).
abs
().
max
().
item
()
}
"
)
# Return benchmark results
return
{
"avg_time_ms"
:
avg_time
,
"tflops"
:
tflops
,
"batch_size"
:
batch_size
,
"seq_len"
:
seq_len
,
"heads"
:
heads
,
"head_query"
:
head_query
,
"dim"
:
dim
,
"selected_blocks"
:
selected_blocks
,
"block_size"
:
block_size
}
def
benchmark_triton_nsa
(
batch_size
,
seq_len
,
heads
,
head_query
,
dim
,
selected_blocks
,
block_size
,
dtype
,
scale
,
warmup
=
10
,
iterations
=
100
,
validate
=
False
):
"""Benchmark the Triton-based TileLang Sparse Attention implementation."""
# Set random seed for reproducibility
tilelang
.
testing
.
set_random_seed
(
0
)
torch
.
random
.
manual_seed
(
0
)
# Create input tensors
Q
=
torch
.
randn
((
batch_size
,
seq_len
,
head_query
,
dim
),
dtype
=
dtype
,
device
=
'cuda'
)
K
=
torch
.
randn
((
batch_size
,
seq_len
,
heads
,
dim
),
dtype
=
dtype
,
device
=
'cuda'
)
V
=
torch
.
randn
((
batch_size
,
seq_len
,
heads
,
dim
),
dtype
=
dtype
,
device
=
'cuda'
)
g_slc
=
torch
.
ones
((
batch_size
,
seq_len
,
head_query
),
dtype
=
dtype
,
device
=
'cuda'
)
g_swa
=
torch
.
ones
((
batch_size
,
seq_len
,
head_query
),
dtype
=
dtype
,
device
=
'cuda'
)
# Generate block indices
block_indices
=
generate_block_indices
(
batch_size
,
seq_len
,
heads
,
selected_blocks
,
block_size
)
block_counts
=
torch
.
randint
(
1
,
selected_blocks
+
1
,
(
batch_size
,
seq_len
,
heads
),
device
=
'cuda'
)
o_slc
=
torch
.
empty
((
batch_size
,
seq_len
,
head_query
,
dim
),
dtype
=
dtype
,
device
=
'cuda'
)
lse_slc
=
torch
.
empty
((
batch_size
,
seq_len
,
head_query
),
dtype
=
torch
.
float
,
device
=
'cuda'
)
# Warmup
for
_
in
range
(
warmup
):
out
=
parallel_nsa_fwd
(
q
=
Q
,
k
=
K
,
v
=
V
,
o_slc
=
o_slc
,
o_swa
=
None
,
lse_slc
=
lse_slc
,
lse_swa
=
None
,
block_indices
=
block_indices
,
block_counts
=
block_counts
,
block_size
=
block_size
,
window_size
=
0
,
scale
=
scale
)
# Synchronize before timing
torch
.
cuda
.
synchronize
()
# Benchmark
start_time
=
time
.
time
()
for
_
in
range
(
iterations
):
out
=
parallel_nsa_fwd
(
q
=
Q
,
k
=
K
,
v
=
V
,
o_slc
=
o_slc
,
o_swa
=
None
,
lse_slc
=
lse_slc
,
lse_swa
=
None
,
block_indices
=
block_indices
,
block_counts
=
block_counts
,
block_size
=
block_size
,
window_size
=
0
,
scale
=
scale
)
torch
.
cuda
.
synchronize
()
end_time
=
time
.
time
()
# Calculate metrics
elapsed_time
=
end_time
-
start_time
avg_time
=
elapsed_time
/
iterations
*
1000
# ms
# Calculate FLOPs (approximate for NSA)
flops_per_token
=
4
*
dim
*
selected_blocks
*
block_size
total_flops
=
batch_size
*
seq_len
*
head_query
*
flops_per_token
flops_per_sec
=
total_flops
/
(
elapsed_time
/
iterations
)
tflops
=
flops_per_sec
/
1e12
# Validate result against reference if requested
if
validate
:
ref
=
naive_nsa
(
q
=
Q
,
k
=
K
,
v
=
V
,
g_slc
=
g_slc
,
g_swa
=
g_swa
,
block_indices
=
block_indices
,
block_counts
=
block_counts
,
block_size
=
block_size
,
scale
=
scale
,
)
is_valid
=
torch
.
allclose
(
ref
,
out
,
atol
=
1e-2
,
rtol
=
1e-2
)
if
is_valid
:
print
(
"Validation: PASSED"
)
else
:
print
(
"Validation: FAILED"
)
print
(
f
"Max difference:
{
(
ref
-
out
).
abs
().
max
().
item
()
}
"
)
# Return benchmark results
return
{
"avg_time_ms"
:
avg_time
,
"tflops"
:
tflops
,
"batch_size"
:
batch_size
,
"seq_len"
:
seq_len
,
"heads"
:
heads
,
"head_query"
:
head_query
,
"dim"
:
dim
,
"selected_blocks"
:
selected_blocks
,
"block_size"
:
block_size
}
def
run_benchmark_suite
(
impl
=
'all'
):
"""Run a suite of benchmarks with different configurations."""
# Define configurations to benchmark
configs
=
[
# Small model config - Note: head_query must be a multiple of heads*16 for Triton
{
"batch_size"
:
2
,
"seq_len"
:
1024
,
"heads"
:
8
,
"head_query"
:
8
*
16
,
"dim"
:
64
,
"selected_blocks"
:
8
,
"block_size"
:
32
},
# Medium model config
{
"batch_size"
:
2
,
"seq_len"
:
2048
,
"heads"
:
16
,
"head_query"
:
16
*
16
,
"dim"
:
64
,
"selected_blocks"
:
16
,
"block_size"
:
64
},
# Large model config
{
"batch_size"
:
1
,
"seq_len"
:
4096
,
"heads"
:
32
,
"head_query"
:
32
*
16
,
"dim"
:
128
,
"selected_blocks"
:
32
,
"block_size"
:
128
},
]
results
=
[]
for
config
in
configs
:
print
(
f
"Running benchmark with config:
{
config
}
"
)
if
impl
in
[
'all'
,
'tilelang'
]:
print
(
"Benchmarking TileLang implementation:"
)
result
=
benchmark_nsa
(
batch_size
=
config
[
"batch_size"
],
seq_len
=
config
[
"seq_len"
],
heads
=
config
[
"heads"
],
head_query
=
config
[
"head_query"
],
dim
=
config
[
"dim"
],
selected_blocks
=
config
[
"selected_blocks"
],
block_size
=
config
[
"block_size"
],
dtype
=
torch
.
float16
,
scale
=
0.1
,
validate
=
False
)
results
.
append
({
"impl"
:
"tilelang"
,
**
result
})
print
(
f
"Average time:
{
result
[
'avg_time_ms'
]:.
2
f
}
ms"
)
print
(
f
"Performance:
{
result
[
'tflops'
]:.
2
f
}
TFLOPs"
)
if
impl
in
[
'all'
,
'triton'
]:
print
(
"Benchmarking Triton implementation:"
)
result
=
benchmark_triton_nsa
(
batch_size
=
config
[
"batch_size"
],
seq_len
=
config
[
"seq_len"
],
heads
=
config
[
"heads"
],
head_query
=
config
[
"head_query"
],
dim
=
config
[
"dim"
],
selected_blocks
=
config
[
"selected_blocks"
],
block_size
=
config
[
"block_size"
],
dtype
=
torch
.
float16
,
scale
=
0.1
,
validate
=
False
)
results
.
append
({
"impl"
:
"triton"
,
**
result
})
print
(
f
"Average time:
{
result
[
'avg_time_ms'
]:.
2
f
}
ms"
)
print
(
f
"Performance:
{
result
[
'tflops'
]:.
2
f
}
TFLOPs"
)
if
impl
in
[
'all'
]:
# Print comparison if both implementations were run
tilelang_result
=
next
(
r
for
r
in
results
if
r
[
"impl"
]
==
"tilelang"
and
r
[
"batch_size"
]
==
config
[
"batch_size"
]
and
r
[
"seq_len"
]
==
config
[
"seq_len"
])
triton_result
=
next
(
r
for
r
in
results
if
r
[
"impl"
]
==
"triton"
and
r
[
"batch_size"
]
==
config
[
"batch_size"
]
and
r
[
"seq_len"
]
==
config
[
"seq_len"
])
speedup
=
tilelang_result
[
"avg_time_ms"
]
/
triton_result
[
"avg_time_ms"
]
print
(
f
"Speedup (Triton vs TileLang):
{
speedup
:.
2
f
}
x"
)
print
(
"-"
*
50
)
return
results
if
__name__
==
"__main__"
:
parser
=
argparse
.
ArgumentParser
(
description
=
"Benchmark TileLang Sparse Attention"
)
parser
.
add_argument
(
"--batch"
,
type
=
int
,
default
=
32
,
help
=
"Batch size"
)
parser
.
add_argument
(
"--seq_len"
,
type
=
int
,
default
=
1024
,
help
=
"Sequence length"
)
parser
.
add_argument
(
"--heads"
,
type
=
int
,
default
=
1
,
help
=
"Number of heads"
)
parser
.
add_argument
(
"--head_query"
,
type
=
int
,
default
=
16
,
help
=
"Number of query heads"
)
parser
.
add_argument
(
"--dim"
,
type
=
int
,
default
=
128
,
help
=
"Head dimension"
)
parser
.
add_argument
(
"--selected_blocks"
,
type
=
int
,
default
=
16
,
help
=
"Number of selected blocks"
)
parser
.
add_argument
(
"--block_size"
,
type
=
int
,
default
=
32
,
help
=
"Block size"
)
parser
.
add_argument
(
"--dtype"
,
type
=
str
,
default
=
"float16"
,
help
=
"Data type (float16 or float32)"
)
parser
.
add_argument
(
"--scale"
,
type
=
float
,
default
=
0.1
,
help
=
"Attention scale factor"
)
parser
.
add_argument
(
"--iterations"
,
type
=
int
,
default
=
100
,
help
=
"Number of iterations"
)
parser
.
add_argument
(
"--warmup"
,
type
=
int
,
default
=
10
,
help
=
"Warmup iterations"
)
parser
.
add_argument
(
"--validate"
,
action
=
"store_true"
,
help
=
"Validate against reference"
)
parser
.
add_argument
(
"--suite"
,
action
=
"store_true"
,
help
=
"Run benchmark suite"
)
parser
.
add_argument
(
"--impl"
,
type
=
str
,
default
=
"all"
,
choices
=
[
"tilelang"
,
"triton"
,
"all"
],
help
=
"Implementation to benchmark (tilelang, triton, or all)"
)
args
=
parser
.
parse_args
()
# For Triton impl, ensure head_query is a multiple of heads*16
if
args
.
impl
in
[
"triton"
,
"all"
]
and
args
.
head_query
%
(
args
.
heads
*
16
)
!=
0
:
# Adjust head_query to nearest valid value
args
.
head_query
=
((
args
.
head_query
//
(
args
.
heads
*
16
))
+
1
)
*
(
args
.
heads
*
16
)
print
(
f
"Adjusted head_query to
{
args
.
head_query
}
to be compatible with Triton implementation"
)
if
args
.
suite
:
run_benchmark_suite
(
impl
=
args
.
impl
)
else
:
dtype
=
torch
.
float16
if
args
.
dtype
==
"float16"
else
torch
.
float32
if
args
.
impl
in
[
"tilelang"
,
"all"
]:
print
(
"Benchmarking TileLang implementation:"
)
result
=
benchmark_nsa
(
batch_size
=
args
.
batch
,
seq_len
=
args
.
seq_len
,
heads
=
args
.
heads
,
head_query
=
args
.
head_query
,
dim
=
args
.
dim
,
selected_blocks
=
args
.
selected_blocks
,
block_size
=
args
.
block_size
,
dtype
=
dtype
,
scale
=
args
.
scale
,
warmup
=
args
.
warmup
,
iterations
=
args
.
iterations
,
validate
=
args
.
validate
)
print
(
"
\n
Benchmark Results (TileLang):"
)
print
(
f
"Configuration: batch=
{
args
.
batch
}
, seq_len=
{
args
.
seq_len
}
, heads=
{
args
.
heads
}
, "
+
f
"head_query=
{
args
.
head_query
}
, dim=
{
args
.
dim
}
, blocks=
{
args
.
selected_blocks
}
, "
+
f
"block_size=
{
args
.
block_size
}
"
)
print
(
f
"Average time:
{
result
[
'avg_time_ms'
]:.
2
f
}
ms"
)
print
(
f
"Performance:
{
result
[
'tflops'
]:.
2
f
}
TFLOPs"
)
if
args
.
impl
in
[
"triton"
,
"all"
]:
print
(
"Benchmarking Triton implementation:"
)
result
=
benchmark_triton_nsa
(
batch_size
=
args
.
batch
,
seq_len
=
args
.
seq_len
,
heads
=
args
.
heads
,
head_query
=
args
.
head_query
,
dim
=
args
.
dim
,
selected_blocks
=
args
.
selected_blocks
,
block_size
=
args
.
block_size
,
dtype
=
dtype
,
scale
=
args
.
scale
,
warmup
=
args
.
warmup
,
iterations
=
args
.
iterations
,
validate
=
args
.
validate
)
print
(
"
\n
Benchmark Results (Triton):"
)
print
(
f
"Configuration: batch=
{
args
.
batch
}
, seq_len=
{
args
.
seq_len
}
, heads=
{
args
.
heads
}
, "
+
f
"head_query=
{
args
.
head_query
}
, dim=
{
args
.
dim
}
, blocks=
{
args
.
selected_blocks
}
, "
+
f
"block_size=
{
args
.
block_size
}
"
)
print
(
f
"Average time:
{
result
[
'avg_time_ms'
]:.
2
f
}
ms"
)
print
(
f
"Performance:
{
result
[
'tflops'
]:.
2
f
}
TFLOPs"
)
examples/deepseek_nsa/example_tilelang_nsa_bwd.py
0 → 100644
View file @
bc2d5632
# ruff: noqa
import
torch
from
typing
import
Optional
,
Union
from
packaging.version
import
parse
import
torch
import
triton
import
fla
if
parse
(
fla
.
__version__
)
<
parse
(
"0.2.1"
):
from
fla.ops.common.utils
import
prepare_token_indices
else
:
from
fla.ops.utils
import
prepare_token_indices
from
fla.utils
import
autocast_custom_bwd
,
autocast_custom_fwd
,
contiguous
from
reference
import
naive_nsa
from
einops
import
rearrange
import
tilelang
@
tilelang
.
jit
(
pass_configs
=
{
tilelang
.
PassConfigKey
.
TL_ENABLE_FAST_MATH
:
True
,
tilelang
.
PassConfigKey
.
TL_DISABLE_TMA_LOWER
:
True
,
tilelang
.
PassConfigKey
.
TL_DISABLE_WARP_SPECIALIZED
:
True
,
})
def
tilelang_kernel_fwd
(
batch
,
heads
,
seq_len
,
dim
,
is_causal
,
scale
=
None
,
block_size
=
64
,
groups
=
1
,
selected_blocks
=
16
,
):
from
tilelang
import
language
as
T
if
scale
is
None
:
scale
=
(
1.0
/
dim
)
**
0.5
*
1.44269504
# log2(e)
else
:
scale
=
scale
*
1.44269504
# log2(e)
head_kv
=
heads
//
groups
q_shape
=
[
batch
,
seq_len
,
heads
,
dim
]
kv_shape
=
[
batch
,
seq_len
,
head_kv
,
dim
]
o_slc_shape
=
[
batch
,
seq_len
,
heads
,
dim
]
lse_slc_shape
=
[
batch
,
seq_len
,
heads
]
block_indices_shape
=
[
batch
,
seq_len
,
head_kv
,
selected_blocks
]
block_indices_dtype
=
"int32"
dtype
=
"float16"
accum_dtype
=
"float"
block_S
=
block_size
block_T
=
min
(
128
,
tilelang
.
math
.
next_power_of_2
(
dim
))
NK
=
tilelang
.
cdiv
(
dim
,
block_T
)
NV
=
tilelang
.
cdiv
(
dim
,
block_T
)
assert
NK
==
1
,
"The key dimension can not be larger than 256"
S
=
selected_blocks
G
=
groups
BS
=
block_S
BK
=
BV
=
block_T
num_stages
=
0
threads
=
32
@
T
.
prim_func
def
native_sparse_attention
(
Q
:
T
.
Tensor
(
q_shape
,
dtype
),
K
:
T
.
Tensor
(
kv_shape
,
dtype
),
V
:
T
.
Tensor
(
kv_shape
,
dtype
),
BlockIndices
:
T
.
Tensor
(
block_indices_shape
,
block_indices_dtype
),
O_slc
:
T
.
Tensor
(
o_slc_shape
,
dtype
),
LSE_slc
:
T
.
Tensor
(
lse_slc_shape
,
accum_dtype
),
):
with
T
.
Kernel
(
seq_len
,
NV
,
batch
*
head_kv
,
threads
=
threads
)
as
(
bx
,
by
,
bz
):
Q_shared
=
T
.
alloc_shared
([
G
,
BK
],
dtype
)
K_shared
=
T
.
alloc_shared
([
BS
,
BK
],
dtype
)
V_shared
=
T
.
alloc_shared
([
BS
,
BV
],
dtype
)
O_shared
=
T
.
alloc_shared
([
G
,
BV
],
dtype
)
acc_s
=
T
.
alloc_fragment
([
G
,
BS
],
accum_dtype
)
acc_s_cast
=
T
.
alloc_fragment
([
G
,
BS
],
dtype
)
acc_o
=
T
.
alloc_fragment
([
G
,
BV
],
accum_dtype
)
scores_max
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
scores_max_prev
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
scores_scale
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
scores_sum
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
logsum
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
i_t
,
i_v
,
i_bh
=
bx
,
by
,
bz
i_b
,
i_h
=
i_bh
//
head_kv
,
i_bh
%
head_kv
NS
=
S
T
.
copy
(
Q
[
i_b
,
i_t
,
i_h
*
G
:(
i_h
+
1
)
*
G
,
:],
Q_shared
)
T
.
fill
(
acc_o
,
0
)
T
.
fill
(
logsum
,
0
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
for
i
in
T
.
Pipelined
(
NS
,
num_stages
=
num_stages
):
i_s
=
BlockIndices
[
i_b
,
i_t
,
i_h
,
i
]
*
BS
if
i_s
<=
i_t
and
i_s
>=
0
:
# [BS, BK]
T
.
copy
(
K
[
i_b
,
i_s
:
i_s
+
BS
,
i_h
,
:],
K_shared
)
if
is_causal
:
for
i
,
j
in
T
.
Parallel
(
G
,
BS
):
acc_s
[
i
,
j
]
=
T
.
if_then_else
(
i_t
>=
(
i_s
+
j
),
0
,
-
T
.
infinity
(
acc_s
.
dtype
))
else
:
T
.
clear
(
acc_s
)
T
.
gemm
(
Q_shared
,
K_shared
,
acc_s
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
,
)
# Softmax
T
.
copy
(
scores_max
,
scores_max_prev
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
T
.
reduce_max
(
acc_s
,
scores_max
,
dim
=
1
,
clear
=
True
)
for
i
in
T
.
Parallel
(
G
):
scores_scale
[
i
]
=
T
.
exp2
(
scores_max_prev
[
i
]
*
scale
-
scores_max
[
i
]
*
scale
)
for
i
,
j
in
T
.
Parallel
(
G
,
BS
):
acc_s
[
i
,
j
]
=
T
.
exp2
(
acc_s
[
i
,
j
]
*
scale
-
scores_max
[
i
]
*
scale
)
T
.
reduce_sum
(
acc_s
,
scores_sum
,
dim
=
1
)
for
i
in
T
.
Parallel
(
G
):
logsum
[
i
]
=
logsum
[
i
]
*
scores_scale
[
i
]
+
scores_sum
[
i
]
T
.
copy
(
acc_s
,
acc_s_cast
)
# Rescale
for
i
,
j
in
T
.
Parallel
(
G
,
BV
):
acc_o
[
i
,
j
]
*=
scores_scale
[
i
]
# V * softmax(Q * K)
T
.
copy
(
V
[
i_b
,
i_s
:
i_s
+
BS
,
i_h
,
i_v
*
BV
:(
i_v
+
1
)
*
BV
],
V_shared
)
T
.
gemm
(
acc_s_cast
,
V_shared
,
acc_o
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
)
for
i
,
j
in
T
.
Parallel
(
G
,
BV
):
acc_o
[
i
,
j
]
/=
logsum
[
i
]
T
.
copy
(
acc_o
,
O_shared
)
T
.
copy
(
O_shared
,
O_slc
[
i_b
,
i_t
,
i_h
*
G
:(
i_h
+
1
)
*
G
,
i_v
*
BV
:(
i_v
+
1
)
*
BV
],
)
for
i
in
T
.
Parallel
(
G
):
logsum
[
i
]
=
T
.
log2
(
logsum
[
i
])
+
scores_max
[
i
]
*
scale
T
.
copy
(
logsum
,
LSE_slc
[
i_b
,
i_t
,
i_h
*
G
:(
i_h
+
1
)
*
G
])
return
native_sparse_attention
@
tilelang
.
jit
(
pass_configs
=
{
tilelang
.
PassConfigKey
.
TL_ENABLE_FAST_MATH
:
True
,
})
def
tilelang_kernel_bwd_dkv
(
batch
,
heads
,
seq_len
,
dim
,
is_causal
,
scale
=
None
,
block_size
=
64
,
groups
=
1
,
selected_blocks
=
16
,
dtype
=
"float16"
,
accum_dtype
=
"float"
,
):
if
scale
is
None
:
sm_scale
=
(
1.0
/
dim
)
**
0.5
else
:
sm_scale
=
scale
scale
=
sm_scale
*
1.44269504
from
tilelang
import
language
as
T
B
=
batch
BS
=
block_size
G
=
groups
V
=
dim
K
=
dim
BK
=
tilelang
.
next_power_of_2
(
K
)
BV
=
min
(
128
,
tilelang
.
next_power_of_2
(
dim
))
NS
=
tilelang
.
cdiv
(
seq_len
,
BS
)
NV
=
tilelang
.
cdiv
(
V
,
BV
)
heads_kv
=
heads
//
groups
q_shape
=
[
batch
,
seq_len
,
heads
,
dim
]
k_shape
=
[
batch
,
seq_len
,
heads_kv
,
dim
]
v_shape
=
[
batch
,
seq_len
,
heads_kv
,
dim
]
lse_slc_shape
=
[
batch
,
seq_len
,
heads
]
delta_slc_shape
=
[
batch
,
seq_len
,
heads
]
o_shape
=
[
batch
,
heads
,
seq_len
,
dim
]
do_slc_shape
=
[
batch
,
seq_len
,
heads
,
dim
]
dk_shape
=
[
NV
,
batch
,
seq_len
,
heads_kv
,
dim
]
dv_shape
=
[
batch
,
seq_len
,
heads_kv
,
dim
]
block_mask_shape
=
[
batch
,
seq_len
,
heads_kv
,
NS
]
num_threads
=
32
print
(
"NV"
,
NV
,
"NS"
,
NS
,
"B"
,
B
,
"H"
,
H
)
@
T
.
prim_func
def
flash_bwd_dkv
(
Q
:
T
.
Tensor
(
q_shape
,
dtype
),
K
:
T
.
Tensor
(
k_shape
,
dtype
),
V
:
T
.
Tensor
(
v_shape
,
dtype
),
LSE_slc
:
T
.
Tensor
(
lse_slc_shape
,
accum_dtype
),
Delta_slc
:
T
.
Tensor
(
delta_slc_shape
,
accum_dtype
),
DO_slc
:
T
.
Tensor
(
do_slc_shape
,
dtype
),
DK
:
T
.
Tensor
(
dk_shape
,
dtype
),
DV
:
T
.
Tensor
(
dv_shape
,
dtype
),
BlockMask
:
T
.
Tensor
(
block_mask_shape
,
"int32"
),
):
with
T
.
Kernel
(
NV
,
NS
,
B
*
H
,
threads
=
num_threads
)
as
(
i_v
,
i_s
,
i_bh
):
K_shared
=
T
.
alloc_shared
([
BS
,
BK
],
dtype
)
V_shared
=
T
.
alloc_shared
([
BS
,
BV
],
dtype
)
Q_shared
=
T
.
alloc_shared
([
G
,
BK
],
dtype
)
qkT
=
T
.
alloc_fragment
([
BS
,
G
],
accum_dtype
)
qkT_cast
=
T
.
alloc_fragment
([
BS
,
G
],
dtype
)
dsT
=
T
.
alloc_fragment
([
BS
,
G
],
accum_dtype
)
dsT_cast
=
T
.
alloc_fragment
([
BS
,
G
],
dtype
)
lse_shared
=
T
.
alloc_shared
([
G
],
accum_dtype
)
delta
=
T
.
alloc_shared
([
G
],
accum_dtype
)
do
=
T
.
alloc_shared
([
G
,
BV
],
dtype
)
dv
=
T
.
alloc_fragment
([
BS
,
BV
],
accum_dtype
)
dk
=
T
.
alloc_fragment
([
BS
,
BK
],
accum_dtype
)
dq
=
T
.
alloc_fragment
([
BS
,
G
],
accum_dtype
)
dv_shared
=
T
.
alloc_shared
([
BS
,
BV
],
dtype
)
dk_shared
=
T
.
alloc_shared
([
BS
,
BK
],
dtype
)
i_b
,
i_h
=
i_bh
//
H
,
i_bh
%
H
T
.
copy
(
K
[
i_b
,
i_s
*
BS
:(
i_s
+
1
)
*
BS
,
i_h
,
:
BK
],
K_shared
)
T
.
copy
(
V
[
i_b
,
i_s
*
BS
:(
i_s
+
1
)
*
BS
,
i_h
,
:
BV
],
V_shared
)
# [BS, BK]
T
.
clear
(
dk
)
# [BS, BV]
T
.
clear
(
dv
)
T
.
annotate_layout
({
K_shared
:
tilelang
.
layout
.
make_swizzled_layout
(
K_shared
),
dv_shared
:
tilelang
.
layout
.
make_swizzled_layout
(
dv_shared
),
dk_shared
:
tilelang
.
layout
.
make_swizzled_layout
(
dk_shared
),
})
loop_st
=
i_s
*
BS
loop_ed
=
seq_len
for
i
in
T
.
Pipelined
(
start
=
loop_st
,
stop
=
loop_ed
,
num_stages
=
0
,
):
b_m_slc
=
BlockMask
[
i_b
,
i
,
i_h
,
i_s
]
if
b_m_slc
!=
0
:
# [G, BK]
T
.
copy
(
Q
[
i_b
,
i
,
i_h
*
G
:(
i_h
+
1
)
*
G
,
:
BK
],
Q_shared
)
T
.
clear
(
qkT
)
# [BS, BK] @ [G, BK] -> [BS, G]
T
.
gemm
(
K_shared
,
Q_shared
,
qkT
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
,
)
# [G]
T
.
copy
(
LSE_slc
[
i_b
,
i
,
i_h
*
G
:(
i_h
+
1
)
*
G
],
lse_shared
)
for
_i
,
_j
in
T
.
Parallel
(
BS
,
G
):
qkT
[
_i
,
_j
]
=
T
.
exp2
(
qkT
[
_i
,
_j
]
*
scale
-
lse_shared
[
_j
])
for
_i
,
_j
in
T
.
Parallel
(
BS
,
G
):
qkT
[
_i
,
_j
]
=
T
.
if_then_else
(
i
>=
(
i_s
*
BS
+
_i
),
qkT
[
_i
,
_j
],
0
)
# [G, BV]
T
.
copy
(
DO_slc
[
i_b
,
i
,
i_h
*
G
:(
i_h
+
1
)
*
G
,
:
BV
],
do
)
T
.
clear
(
dsT
)
# [BS, BV] @ [G, BV] -> [BS, G]
T
.
gemm
(
V_shared
,
do
,
dsT
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
,
)
T
.
copy
(
qkT
,
qkT_cast
)
# [BS, G] @ [G, BV] -> [BS, BV]
T
.
gemm
(
qkT_cast
,
do
,
dv
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
)
# [G]
T
.
copy
(
Delta_slc
[
i_b
,
i
,
i_h
*
G
:(
i_h
+
1
)
*
G
],
delta
)
for
i
,
j
in
T
.
Parallel
(
BS
,
G
):
dsT_cast
[
i
,
j
]
=
qkT
[
i
,
j
]
*
(
dsT
[
i
,
j
]
-
delta
[
j
])
*
sm_scale
# [BS, G] @ [G, BK] -> [BS, BK]
T
.
gemm
(
dsT_cast
,
Q_shared
,
dk
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
)
T
.
copy
(
dv
,
dv_shared
)
T
.
copy
(
dk
,
dk_shared
)
T
.
copy
(
dv_shared
,
DV
[
i_b
,
i_s
*
BS
:(
i_s
+
1
)
*
BS
,
i_h
,
:
BV
])
T
.
copy
(
dk_shared
,
DK
[
i_v
,
i_b
,
i_s
*
BS
:(
i_s
+
1
)
*
BS
,
i_h
,
:
BK
])
return
flash_bwd_dkv
def
make_dq_layout
(
dQ
):
from
tilelang
import
language
as
T
# atomicAdd can not be vectorized, so we need to reorder dq to match the 8x8 gemm fragment
return
T
.
Layout
(
dQ
.
shape
,
lambda
b
,
l
,
h
,
d
:
[
b
,
l
//
8
,
h
,
d
//
8
,
(
d
%
2
),
4
*
(
l
%
8
)
+
(
d
%
8
)
//
2
],
)
@
tilelang
.
jit
(
pass_configs
=
{
tilelang
.
PassConfigKey
.
TL_ENABLE_FAST_MATH
:
True
,
})
def
tilelang_kernel_bwd_dqkv
(
batch
,
heads
,
seq_len
,
dim
,
is_causal
,
scale
=
None
,
block_size
=
64
,
groups
=
1
,
selected_blocks
=
16
,
dtype
=
"float16"
,
accum_dtype
=
"float"
,
):
if
scale
is
None
:
sm_scale
=
(
1.0
/
dim
)
**
0.5
else
:
sm_scale
=
scale
scale
=
sm_scale
*
1.44269504
from
tilelang
import
language
as
T
B
=
batch
BS
=
block_size
G
=
groups
V
=
dim
K
=
dim
BK
=
tilelang
.
next_power_of_2
(
K
)
BV
=
min
(
128
,
tilelang
.
next_power_of_2
(
dim
))
NS
=
tilelang
.
cdiv
(
seq_len
,
BS
)
NV
=
tilelang
.
cdiv
(
V
,
BV
)
heads_kv
=
heads
//
groups
q_shape
=
[
batch
,
seq_len
,
heads
,
dim
]
k_shape
=
[
batch
,
seq_len
,
heads_kv
,
dim
]
v_shape
=
[
batch
,
seq_len
,
heads_kv
,
dim
]
lse_slc_shape
=
[
batch
,
seq_len
,
heads
]
delta_slc_shape
=
[
batch
,
seq_len
,
heads
]
o_shape
=
[
batch
,
heads
,
seq_len
,
dim
]
do_slc_shape
=
[
batch
,
seq_len
,
heads
,
dim
]
dq_shape
=
[
NV
,
batch
,
seq_len
,
heads
,
dim
]
dk_shape
=
[
NV
,
batch
,
seq_len
,
heads_kv
,
dim
]
dv_shape
=
[
batch
,
seq_len
,
heads_kv
,
dim
]
block_mask_shape
=
[
batch
,
seq_len
,
heads_kv
,
NS
]
num_threads
=
32
@
T
.
prim_func
def
flash_bwd_dqkv
(
Q
:
T
.
Tensor
(
q_shape
,
dtype
),
K
:
T
.
Tensor
(
k_shape
,
dtype
),
V
:
T
.
Tensor
(
v_shape
,
dtype
),
LSE_slc
:
T
.
Tensor
(
lse_slc_shape
,
accum_dtype
),
Delta_slc
:
T
.
Tensor
(
delta_slc_shape
,
accum_dtype
),
DO_slc
:
T
.
Tensor
(
do_slc_shape
,
dtype
),
DQ
:
T
.
Tensor
(
dq_shape
,
dtype
),
DK
:
T
.
Tensor
(
dk_shape
,
dtype
),
DV
:
T
.
Tensor
(
dv_shape
,
dtype
),
BlockMask
:
T
.
Tensor
(
block_mask_shape
,
"int32"
),
):
with
T
.
Kernel
(
NV
,
NS
,
B
*
H
,
threads
=
num_threads
)
as
(
i_v
,
i_s
,
i_bh
):
K_shared
=
T
.
alloc_shared
([
BS
,
BK
],
dtype
)
dsT_shared
=
T
.
alloc_shared
([
BS
,
G
],
dtype
)
V_shared
=
T
.
alloc_shared
([
BS
,
BV
],
dtype
)
Q_shared
=
T
.
alloc_shared
([
G
,
BK
],
dtype
)
qkT
=
T
.
alloc_fragment
([
BS
,
G
],
accum_dtype
)
qkT_cast
=
T
.
alloc_fragment
([
BS
,
G
],
dtype
)
dsT
=
T
.
alloc_fragment
([
BS
,
G
],
accum_dtype
)
dsT_cast
=
T
.
alloc_fragment
([
BS
,
G
],
dtype
)
lse_shared
=
T
.
alloc_shared
([
G
],
accum_dtype
)
delta
=
T
.
alloc_shared
([
G
],
accum_dtype
)
do
=
T
.
alloc_shared
([
G
,
BV
],
dtype
)
dv
=
T
.
alloc_fragment
([
BS
,
BV
],
accum_dtype
)
dk
=
T
.
alloc_fragment
([
BS
,
BK
],
accum_dtype
)
dq
=
T
.
alloc_fragment
([
G
,
BK
],
accum_dtype
)
dv_shared
=
T
.
alloc_shared
([
BS
,
BV
],
dtype
)
dk_shared
=
T
.
alloc_shared
([
BS
,
BK
],
dtype
)
i_b
,
i_h
=
i_bh
//
H
,
i_bh
%
H
T
.
copy
(
K
[
i_b
,
i_s
*
BS
:(
i_s
+
1
)
*
BS
,
i_h
,
:
BK
],
K_shared
)
T
.
copy
(
V
[
i_b
,
i_s
*
BS
:(
i_s
+
1
)
*
BS
,
i_h
,
:
BV
],
V_shared
)
# [BS, BK]
T
.
clear
(
dk
)
# [BS, BV]
T
.
clear
(
dv
)
T
.
annotate_layout
({
K_shared
:
tilelang
.
layout
.
make_swizzled_layout
(
K_shared
),
dv_shared
:
tilelang
.
layout
.
make_swizzled_layout
(
dv_shared
),
dk_shared
:
tilelang
.
layout
.
make_swizzled_layout
(
dk_shared
),
})
loop_st
=
i_s
*
BS
loop_ed
=
seq_len
for
i
in
T
.
Pipelined
(
start
=
loop_st
,
stop
=
loop_ed
,
num_stages
=
0
,
):
b_m_slc
=
BlockMask
[
i_b
,
i
,
i_h
,
i_s
]
if
b_m_slc
!=
0
:
# [G, BK]
T
.
copy
(
Q
[
i_b
,
i
,
i_h
*
G
:(
i_h
+
1
)
*
G
,
:
BK
],
Q_shared
)
T
.
clear
(
qkT
)
# [BS, BK] @ [G, BK] -> [BS, G]
T
.
gemm
(
K_shared
,
Q_shared
,
qkT
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
,
)
# [G]
T
.
copy
(
LSE_slc
[
i_b
,
i
,
i_h
*
G
:(
i_h
+
1
)
*
G
],
lse_shared
)
for
_i
,
_j
in
T
.
Parallel
(
BS
,
G
):
qkT
[
_i
,
_j
]
=
T
.
exp2
(
qkT
[
_i
,
_j
]
*
scale
-
lse_shared
[
_j
])
for
_i
,
_j
in
T
.
Parallel
(
BS
,
G
):
qkT
[
_i
,
_j
]
=
T
.
if_then_else
(
i
>=
(
i_s
*
BS
+
_i
),
qkT
[
_i
,
_j
],
0
)
# [G, BV]
T
.
copy
(
DO_slc
[
i_b
,
i
,
i_h
*
G
:(
i_h
+
1
)
*
G
,
:
BV
],
do
)
T
.
clear
(
dsT
)
# [BS, BV] @ [G, BV] -> [BS, G]
T
.
gemm
(
V_shared
,
do
,
dsT
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
,
)
T
.
copy
(
qkT
,
qkT_cast
)
# [BS, G] @ [G, BV] -> [BS, BV]
T
.
gemm
(
qkT_cast
,
do
,
dv
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
)
# [G]
T
.
copy
(
Delta_slc
[
i_b
,
i
,
i_h
*
G
:(
i_h
+
1
)
*
G
],
delta
)
for
i
,
j
in
T
.
Parallel
(
BS
,
G
):
dsT_cast
[
i
,
j
]
=
qkT
[
i
,
j
]
*
(
dsT
[
i
,
j
]
-
delta
[
j
])
*
sm_scale
# [BS, G] @ [G, BK] -> [BS, BK]
T
.
gemm
(
dsT_cast
,
Q_shared
,
dk
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
)
T
.
copy
(
dsT_cast
,
dsT_shared
)
T
.
clear
(
dq
)
# [BS, G] * [BS, BK] -> [G, BK]
T
.
gemm
(
dsT_shared
,
K_shared
,
dq
,
transpose_A
=
True
)
for
_i
,
_j
in
T
.
Parallel
(
G
,
BK
):
T
.
atomic_add
(
DQ
[
i_v
,
i_b
,
i
,
i_h
*
G
+
_i
,
_j
],
dq
[
_i
,
_j
])
T
.
copy
(
dv
,
dv_shared
)
T
.
copy
(
dk
,
dk_shared
)
T
.
copy
(
dv_shared
,
DV
[
i_b
,
i_s
*
BS
:(
i_s
+
1
)
*
BS
,
i_h
,
:
BV
])
T
.
copy
(
dk_shared
,
DK
[
i_v
,
i_b
,
i_s
*
BS
:(
i_s
+
1
)
*
BS
,
i_h
,
:
BK
])
return
flash_bwd_dqkv
@
tilelang
.
jit
(
out_idx
=
[
2
],
pass_configs
=
{
tilelang
.
PassConfigKey
.
TL_ENABLE_FAST_MATH
:
True
,
})
def
tilelang_kernel_preprocess
(
batch
,
heads
,
seq_len
,
dim
,
dtype
=
"float16"
,
accum_dtype
=
"float"
,
blk
=
32
,
):
from
tilelang
import
language
as
T
shape
=
[
batch
,
seq_len
,
heads
,
dim
]
@
T
.
prim_func
def
flash_bwd_prep
(
O
:
T
.
Tensor
(
shape
,
dtype
),
# type: ignore
dO
:
T
.
Tensor
(
shape
,
dtype
),
# type: ignore
Delta
:
T
.
Tensor
([
batch
,
seq_len
,
heads
],
accum_dtype
),
# type: ignore
):
with
T
.
Kernel
(
heads
,
T
.
ceildiv
(
seq_len
,
blk
),
batch
)
as
(
bx
,
by
,
bz
):
o
=
T
.
alloc_fragment
([
blk
,
blk
],
dtype
)
do
=
T
.
alloc_fragment
([
blk
,
blk
],
dtype
)
acc
=
T
.
alloc_fragment
([
blk
,
blk
],
accum_dtype
)
delta
=
T
.
alloc_fragment
([
blk
],
accum_dtype
)
T
.
clear
(
acc
)
for
k
in
range
(
T
.
ceildiv
(
dim
,
blk
)):
T
.
copy
(
O
[
bz
,
by
*
blk
:(
by
+
1
)
*
blk
,
bx
,
k
*
blk
:(
k
+
1
)
*
blk
],
o
)
T
.
copy
(
dO
[
bz
,
by
*
blk
:(
by
+
1
)
*
blk
,
bx
,
k
*
blk
:(
k
+
1
)
*
blk
],
do
)
for
i
,
j
in
T
.
Parallel
(
blk
,
blk
):
acc
[
i
,
j
]
+=
o
[
i
,
j
]
*
do
[
i
,
j
]
T
.
reduce_sum
(
acc
,
delta
,
1
)
T
.
copy
(
delta
,
Delta
[
bz
,
by
*
blk
:(
by
+
1
)
*
blk
,
bx
])
return
flash_bwd_prep
@
tilelang
.
jit
(
out_idx
=
[
2
],
pass_configs
=
{
tilelang
.
PassConfigKey
.
TL_ENABLE_FAST_MATH
:
True
,
})
def
tilelang_kernel_block_mask
(
batch
,
heads
,
seq_len
,
selected_blocks
,
block_size
,
dtype
=
"int32"
,
):
from
tilelang
import
language
as
T
block_indices_shape
=
[
batch
,
seq_len
,
heads
,
selected_blocks
]
block_counts_shape
=
[
batch
,
seq_len
,
heads
]
S
=
selected_blocks
BS
=
block_size
NS
=
tilelang
.
cdiv
(
seq_len
,
BS
)
block_mask_shape
=
[
batch
,
seq_len
,
heads
,
NS
]
USE_BLOCK_COUNTS
=
block_counts
is
not
None
@
T
.
prim_func
def
flash_bwd_block_mask
(
BlockIndices
:
T
.
Tensor
(
block_indices_shape
,
dtype
),
# type: ignore
BlockCounts
:
T
.
Tensor
(
block_counts_shape
,
dtype
),
# type: ignore
BlockMask
:
T
.
Tensor
(
block_mask_shape
,
dtype
),
# type: ignore
):
with
T
.
Kernel
(
seq_len
,
batch
,
heads
*
S
)
as
(
bx
,
by
,
bz
):
i_t
,
i_b
,
i_hs
=
bx
,
by
,
bz
i_h
,
i_s
=
i_hs
//
S
,
i_hs
%
S
b_i
=
BlockIndices
[
i_b
,
i_t
,
i_h
,
i_s
]
if
USE_BLOCK_COUNTS
:
b_m
=
b_i
*
BS
<=
i_t
and
i_s
<
BlockCounts
[
i_b
,
i_t
,
i_h
].
astype
(
i_s
.
dtype
)
BlockMask
[
i_b
,
i_t
,
i_h
,
i_s
]
=
b_m
else
:
b_m
=
b_i
*
BS
<=
i_t
BlockMask
[
i_b
,
i_t
,
i_h
,
i_s
]
=
b_m
return
flash_bwd_block_mask
def
parallel_nsa_bwd
(
q
:
torch
.
Tensor
,
k
:
torch
.
Tensor
,
v
:
torch
.
Tensor
,
o_slc
:
torch
.
Tensor
,
lse_slc
:
torch
.
Tensor
,
do_slc
:
torch
.
Tensor
,
o_swa
:
torch
.
Tensor
,
lse_swa
:
torch
.
Tensor
,
do_swa
:
torch
.
Tensor
,
block_indices
:
torch
.
Tensor
,
block_counts
:
Union
[
torch
.
LongTensor
,
int
],
block_size
:
int
=
64
,
window_size
:
int
=
0
,
scale
:
float
=
None
,
offsets
:
Optional
[
torch
.
LongTensor
]
=
None
,
token_indices
:
Optional
[
torch
.
LongTensor
]
=
None
,
):
B
,
T
,
H
,
K
,
V
,
S
=
*
k
.
shape
,
v
.
shape
[
-
1
],
block_indices
.
shape
[
-
1
]
HQ
=
q
.
shape
[
2
]
G
=
HQ
//
H
BS
=
block_size
WS
=
window_size
BK
=
triton
.
next_power_of_2
(
K
)
BV
=
min
(
128
,
triton
.
next_power_of_2
(
v
.
shape
[
-
1
]))
NV
=
triton
.
cdiv
(
V
,
BV
)
assert
window_size
==
0
,
"Window size is not supported yet"
delta_slc
=
tilelang_kernel_preprocess
(
B
,
HQ
,
T
,
K
)(
o_slc
,
do_slc
)
dq
=
torch
.
zeros
(
NV
,
*
q
.
shape
,
dtype
=
q
.
dtype
if
NV
==
1
else
torch
.
float
,
device
=
q
.
device
)
dk
=
torch
.
empty
(
NV
,
*
k
.
shape
,
dtype
=
k
.
dtype
,
device
=
q
.
device
)
dv
=
torch
.
empty
(
v
.
shape
,
dtype
=
v
.
dtype
,
device
=
q
.
device
)
block_mask
=
tilelang_kernel_block_mask
(
B
,
H
,
T
,
S
,
BS
)(
block_indices
.
to
(
torch
.
int32
),
block_counts
.
to
(
torch
.
int32
)).
to
(
torch
.
bool
)
fused_qkv_bwd_kernel
=
tilelang_kernel_bwd_dqkv
(
batch
=
B
,
heads
=
HQ
,
seq_len
=
T
,
dim
=
K
,
is_causal
=
True
,
block_size
=
BS
,
groups
=
G
,
selected_blocks
=
S
,
scale
=
scale
,
)
fused_qkv_bwd_kernel
(
q
,
k
,
v
,
lse_slc
,
delta_slc
,
do_slc
,
dq
,
dk
,
dv
,
block_mask
.
to
(
torch
.
int32
))
dq
=
dq
.
sum
(
0
)
dk
=
dk
.
sum
(
0
)
return
dq
,
dk
,
dv
@
torch
.
compile
class
ParallelNSAFunction
(
torch
.
autograd
.
Function
):
@
staticmethod
@
contiguous
@
autocast_custom_fwd
def
forward
(
ctx
,
q
,
k
,
v
,
block_indices
,
block_counts
,
block_size
,
window_size
,
scale
,
offsets
,
):
ctx
.
dtype
=
q
.
dtype
assert
offsets
is
None
,
"Offsets are not supported yet"
# 2-d sequence indices denoting the offsets of tokens in each sequence
# for example, if the passed `offsets` is [0, 2, 6],
# then there are 2 and 4 tokens in the 1st and 2nd sequences respectively, and `token_indices` will be
# [[0, 0], [0, 1], [1, 0], [1, 1], [1, 2], [1, 3]]
token_indices
=
prepare_token_indices
(
offsets
)
if
offsets
is
not
None
else
None
B
,
SEQLEN
,
HQ
,
D
=
q
.
shape
H
=
k
.
shape
[
2
]
G
=
HQ
//
H
S
=
block_indices
.
shape
[
-
1
]
V
=
v
.
shape
[
-
1
]
kernel
=
tilelang_kernel_fwd
(
batch
=
B
,
heads
=
HQ
,
seq_len
=
SEQLEN
,
dim
=
D
,
is_causal
=
True
,
scale
=
scale
,
block_size
=
block_size
,
groups
=
G
,
selected_blocks
=
S
,
)
o_slc
=
torch
.
empty
(
B
,
SEQLEN
,
HQ
,
D
,
dtype
=
v
.
dtype
,
device
=
q
.
device
)
lse_slc
=
torch
.
empty
(
B
,
SEQLEN
,
HQ
,
dtype
=
torch
.
float
,
device
=
q
.
device
)
kernel
(
q
,
k
,
v
,
block_indices
.
to
(
torch
.
int32
),
o_slc
,
lse_slc
)
ctx
.
save_for_backward
(
q
,
k
,
v
,
o_slc
,
lse_slc
)
ctx
.
block_indices
=
block_indices
ctx
.
block_counts
=
block_counts
ctx
.
offsets
=
offsets
ctx
.
token_indices
=
token_indices
ctx
.
block_size
=
block_size
ctx
.
window_size
=
window_size
ctx
.
scale
=
scale
return
o_slc
.
to
(
q
.
dtype
),
lse_slc
.
to
(
torch
.
float
)
@
staticmethod
@
contiguous
@
autocast_custom_bwd
def
backward
(
ctx
,
do_slc
,
do_swa
):
q
,
k
,
v
,
o_slc
,
lse_slc
=
ctx
.
saved_tensors
dq
,
dk
,
dv
=
parallel_nsa_bwd
(
q
=
q
,
k
=
k
,
v
=
v
,
o_slc
=
o_slc
,
o_swa
=
None
,
lse_slc
=
lse_slc
,
lse_swa
=
None
,
do_slc
=
do_slc
,
do_swa
=
do_swa
,
block_indices
=
ctx
.
block_indices
,
block_counts
=
ctx
.
block_counts
,
block_size
=
ctx
.
block_size
,
window_size
=
ctx
.
window_size
,
scale
=
ctx
.
scale
,
offsets
=
ctx
.
offsets
,
token_indices
=
ctx
.
token_indices
,
)
return
(
dq
.
to
(
q
),
dk
.
to
(
k
),
dv
.
to
(
v
),
None
,
None
,
None
,
None
,
None
,
None
,
None
,
None
,
)
def
parallel_nsa
(
q
:
torch
.
Tensor
,
k
:
torch
.
Tensor
,
v
:
torch
.
Tensor
,
g_slc
:
torch
.
Tensor
,
g_swa
:
torch
.
Tensor
,
block_indices
:
torch
.
LongTensor
,
block_counts
:
Optional
[
Union
[
torch
.
LongTensor
,
int
]]
=
None
,
block_size
:
int
=
64
,
window_size
:
int
=
0
,
scale
:
Optional
[
float
]
=
None
,
cu_seqlens
:
Optional
[
torch
.
LongTensor
]
=
None
,
head_first
:
bool
=
False
,
)
->
torch
.
Tensor
:
r
"""
Args:
q (torch.Tensor):
queries of shape `[B, SEQLEN, HQ, K]` if `head_first=False` else `[B, HQ, SEQLEN, K]`.
k (torch.Tensor):
keys of shape `[B, SEQLEN, H, K]` if `head_first=False` else `[B, H, SEQLEN, K]`.
GQA is enforced here. The ratio of query heads (HQ) to key/value heads (H) must be a power of 2 and >=16.
v (torch.Tensor):
values of shape `[B, SEQLEN, H, V]` if `head_first=False` else `[B, H, SEQLEN, V]`.
g_slc (torch.Tensor):
Gate score for selected attention of shape `[B, SEQLEN, HQ]` if `head_first=False` else `[B, HQ, SEQLEN]`.
g_swa (torch.Tensor):
Gate score for sliding attention of shape `[B, SEQLEN, HQ]` if `head_first=False` else `[B, HQ, SEQLEN]`.
block_indices (torch.LongTensor):
Block indices of shape `[B, SEQLEN, H, S]` if `head_first=False` else `[B, H, SEQLEN, S]`.
`S` is the number of selected blocks for each query token, which is set to 16 in the paper.
block_counts (Union[torch.LongTensor, int]):
Number of selected blocks for each token.
If a tensor is provided, with shape `[B, SEQLEN, H]` if `head_first=True` else `[B, SEQLEN, H]`,
each token can select the same number of blocks.
If not provided, it will default to `S`, Default: `None`
block_size (int):
Selected block size. Default: 64.
window_size (int):
Sliding window size. Default: 0.
scale (Optional[int]):
Scale factor for attention scores.
If not provided, it will default to `1 / sqrt(K)`. Default: `None`.
head_first (Optional[bool]):
Whether the inputs are in the head-first format. Default: `False`.
cu_seqlens (torch.LongTensor):
Cumulative sequence lengths of shape `[N+1]` used for variable-length training,
consistent with the FlashAttention API.
Returns:
o (torch.Tensor):
Outputs of shape `[B, SEQLEN, HQ, V]` if `head_first=False` else `[B, HQ, SEQLEN, V]`.
"""
if
scale
is
None
:
scale
=
k
.
shape
[
-
1
]
**-
0.5
if
cu_seqlens
is
not
None
:
assert
q
.
shape
[
0
]
==
1
,
"batch size must be 1 when cu_seqlens are provided"
if
head_first
:
q
,
k
,
v
,
block_indices
=
map
(
lambda
x
:
rearrange
(
x
,
"b h t d -> b t h d"
),
(
q
,
k
,
v
,
block_indices
))
g_slc
,
g_swa
=
map
(
lambda
x
:
rearrange
(
x
,
"b h t -> b t h"
),
(
g_slc
,
g_swa
))
if
isinstance
(
block_counts
,
torch
.
Tensor
):
block_counts
=
rearrange
(
block_counts
,
"b h t -> b t h"
)
assert
(
q
.
shape
[
2
]
%
(
k
.
shape
[
2
]
*
16
)
==
0
),
"Group size must be a multiple of 16 in NSA"
if
isinstance
(
block_counts
,
int
):
block_indices
=
block_indices
[:,
:,
:,
:
block_counts
]
block_counts
=
None
o_slc
,
o_swa
=
ParallelNSAFunction
.
apply
(
q
,
k
,
v
,
block_indices
,
block_counts
,
block_size
,
window_size
,
scale
,
cu_seqlens
)
if
window_size
>
0
:
o
=
torch
.
addcmul
(
o_slc
*
g_slc
.
unsqueeze
(
-
1
),
o_swa
,
g_swa
.
unsqueeze
(
-
1
))
else
:
o
=
o_slc
*
g_slc
.
unsqueeze
(
-
1
)
if
head_first
:
o
=
rearrange
(
o
,
"b t h d -> b h t d"
)
return
o
if
__name__
==
"__main__"
:
B
,
T
,
H
,
HQ
,
D
,
S
,
block_size
,
dtype
=
1
,
32
,
1
,
16
,
32
,
1
,
32
,
torch
.
float16
torch
.
random
.
manual_seed
(
0
)
q
=
torch
.
randn
((
B
,
T
,
HQ
,
D
),
dtype
=
dtype
,
device
=
"cuda"
).
requires_grad_
(
True
)
k
=
torch
.
randn
((
B
,
T
,
H
,
D
),
dtype
=
dtype
,
device
=
"cuda"
).
requires_grad_
(
True
)
v
=
torch
.
randn
((
B
,
T
,
H
,
D
),
dtype
=
dtype
,
device
=
"cuda"
).
requires_grad_
(
True
)
g_slc
=
torch
.
ones
((
B
,
T
,
HQ
),
dtype
=
dtype
,
device
=
"cuda"
).
requires_grad_
(
True
)
g_swa
=
torch
.
ones
((
B
,
T
,
HQ
),
dtype
=
dtype
,
device
=
"cuda"
).
requires_grad_
(
True
)
do
=
torch
.
randn
((
B
,
T
,
HQ
,
D
),
dtype
=
dtype
,
device
=
"cuda"
)
block_indices
=
torch
.
full
((
B
,
T
,
H
,
S
),
T
,
dtype
=
torch
.
long
,
device
=
"cuda"
)
for
b
in
range
(
B
):
for
t
in
range
(
T
):
for
h
in
range
(
H
):
i_i
=
torch
.
randperm
(
max
(
1
,
(
t
//
block_size
)))[:
S
]
block_indices
[
b
,
t
,
h
,
:
len
(
i_i
)]
=
i_i
block_indices
=
block_indices
.
sort
(
-
1
)[
0
]
block_counts
=
torch
.
randint
(
1
,
S
+
1
,
(
B
,
T
,
H
),
device
=
"cuda"
)
ref
=
naive_nsa
(
q
=
q
,
k
=
k
,
v
=
v
,
g_slc
=
g_slc
,
g_swa
=
g_swa
,
block_indices
=
block_indices
,
block_counts
=
block_counts
,
block_size
=
block_size
,
)
ref
.
backward
(
do
)
ref_dq
,
q
.
grad
=
q
.
grad
.
clone
(),
None
ref_dk
,
k
.
grad
=
k
.
grad
.
clone
(),
None
ref_dv
,
v
.
grad
=
v
.
grad
.
clone
(),
None
ref_dg_slc
,
g_slc
.
grad
=
g_slc
.
grad
.
clone
(),
None
tri
=
parallel_nsa
(
q
=
q
,
k
=
k
,
v
=
v
,
g_slc
=
g_slc
,
g_swa
=
g_swa
,
block_indices
=
block_indices
,
block_size
=
block_size
,
block_counts
=
block_counts
,
)
tri
.
backward
(
do
)
tri_dq
,
q
.
grad
=
q
.
grad
.
clone
(),
None
tri_dk
,
k
.
grad
=
k
.
grad
.
clone
(),
None
tri_dv
,
v
.
grad
=
v
.
grad
.
clone
(),
None
tri_dg_slc
,
g_slc
.
grad
=
g_slc
.
grad
.
clone
(),
None
# assert_close(" o", ref, tri, 0.004)
torch
.
testing
.
assert_close
(
ref
,
tri
,
atol
=
1e-2
,
rtol
=
1e-2
)
torch
.
testing
.
assert_close
(
ref_dq
,
tri_dq
,
atol
=
1e-2
,
rtol
=
1e-2
)
torch
.
testing
.
assert_close
(
ref_dk
,
tri_dk
,
atol
=
1e-2
,
rtol
=
1e-2
)
torch
.
testing
.
assert_close
(
ref_dv
,
tri_dv
,
atol
=
1e-2
,
rtol
=
1e-2
)
torch
.
testing
.
assert_close
(
ref_dg_slc
,
tri_dg_slc
,
atol
=
1e-2
,
rtol
=
1e-2
)
examples/deepseek_nsa/example_tilelang_nsa_decode.py
0 → 100644
View file @
bc2d5632
# ruff: noqa
import
torch
from
reference
import
naive_nsa_simple_inference
import
tilelang
from
tilelang
import
language
as
T
import
tilelang.testing
tilelang
.
testing
.
set_random_seed
(
42
)
# TODO(lei): workaround, as threads is not divisible by warp group size,
# auto warp specialization may have some bugs.
@
tilelang
.
jit
(
out_idx
=
[
-
1
],
pass_configs
=
{
tilelang
.
PassConfigKey
.
TL_DISABLE_TMA_LOWER
:
True
,
tilelang
.
PassConfigKey
.
TL_DISABLE_WARP_SPECIALIZED
:
True
,
tilelang
.
PassConfigKey
.
TL_ENABLE_FAST_MATH
:
True
,
})
def
native_sparse_attention
(
batch
,
heads
,
seq_len
,
# Length of K/V sequences (context window size)
dim
,
# Embedding dimension per head
scale
=
None
,
block_size
=
64
,
# Tile size for attention computation
groups
=
1
,
# Grouped query attention (GQA) groups
selected_blocks
=
16
# Number of blocks to select per attention head
):
if
scale
is
None
:
scale
=
(
1.0
/
dim
)
**
0.5
*
1.44269504
# log2(e)
head_kv
=
heads
//
groups
# Modified shapes for inference (q has seq_len=1)a
q_shape
=
[
batch
,
1
,
heads
,
dim
]
# Changed seq_len to 1
kv_shape
=
[
batch
,
seq_len
,
head_kv
,
dim
]
block_indices_shape
=
[
batch
,
1
,
head_kv
,
selected_blocks
]
# Changed seq_len to 1
block_indices_dtype
=
"int32"
dtype
=
"float16"
accum_dtype
=
"float"
block_S
=
block_size
block_T
=
min
(
128
,
tilelang
.
math
.
next_power_of_2
(
dim
))
NK
=
tilelang
.
cdiv
(
dim
,
block_T
)
NV
=
tilelang
.
cdiv
(
dim
,
block_T
)
assert
NK
==
1
,
"The key dimension can not be larger than 256"
S
=
selected_blocks
G
=
groups
BS
=
block_S
BK
=
BV
=
block_T
num_stages
=
0
threads
=
32
@
T
.
prim_func
def
native_sparse_attention
(
Q
:
T
.
Tensor
(
q_shape
,
dtype
),
# [batch, 1, heads, dim]
K
:
T
.
Tensor
(
kv_shape
,
dtype
),
# [batch, seq_len, head_kv, dim]
V
:
T
.
Tensor
(
kv_shape
,
dtype
),
# Same shape as K
BlockIndices
:
T
.
Tensor
(
block_indices_shape
,
block_indices_dtype
),
# Selected block indices
Output
:
T
.
Tensor
(
q_shape
,
dtype
),
# Output attention tensor
):
with
T
.
Kernel
(
1
,
NV
,
batch
*
head_kv
,
threads
=
threads
)
as
(
bx
,
by
,
bz
):
# Shared memory allocations for tile storage
Q_shared
=
T
.
alloc_shared
([
G
,
BK
],
dtype
)
# Current query block
K_shared
=
T
.
alloc_shared
([
BS
,
BK
],
dtype
)
# Current key block
V_shared
=
T
.
alloc_shared
([
BS
,
BV
],
dtype
)
# Current value block
O_shared
=
T
.
alloc_shared
([
G
,
BV
],
dtype
)
# Output accumulator
# Attention computation buffers
acc_s
=
T
.
alloc_fragment
([
G
,
BS
],
accum_dtype
)
# QK^T scores
acc_s_cast
=
T
.
alloc_fragment
([
G
,
BS
],
dtype
)
# Casted scores for softmax
acc_o
=
T
.
alloc_fragment
([
G
,
BV
],
accum_dtype
)
# Output accumulator
scores_max
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
scores_max_prev
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
scores_scale
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
scores_sum
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
logsum
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
i_v
,
i_bh
=
by
,
bz
i_b
,
i_h
=
i_bh
//
head_kv
,
i_bh
%
head_kv
NS
=
S
# Copy Q for the single position
T
.
copy
(
Q
[
i_b
,
0
,
i_h
*
G
:(
i_h
+
1
)
*
G
,
:],
Q_shared
)
# Changed i_t to 0
T
.
fill
(
acc_o
,
0
)
T
.
fill
(
logsum
,
0
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
# Main attention computation loop over selected blocks
for
i
in
T
.
Pipelined
(
NS
,
num_stages
=
num_stages
):
i_s
=
BlockIndices
[
i_b
,
0
,
i_h
,
i
]
*
BS
# Get block offset
if
i_s
>=
0
:
# Skip invalid/padding blocks
# Load current key block to shared memory
T
.
copy
(
K
[
i_b
,
i_s
:
i_s
+
BS
,
i_h
,
:],
K_shared
)
# Compute QK^T attention scores
T
.
clear
(
acc_s
)
T
.
gemm
(
Q_shared
,
K_shared
,
acc_s
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
)
# Online softmax with numerical stability
# 1. Compute max for scaling
# 2. Compute exponentials and sum
# 3. Maintain running logsum for normalization
T
.
copy
(
scores_max
,
scores_max_prev
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
T
.
reduce_max
(
acc_s
,
scores_max
,
dim
=
1
,
clear
=
True
)
for
i
in
T
.
Parallel
(
G
):
scores_scale
[
i
]
=
T
.
exp2
(
scores_max_prev
[
i
]
*
scale
-
scores_max
[
i
]
*
scale
)
for
i
,
j
in
T
.
Parallel
(
G
,
BS
):
acc_s
[
i
,
j
]
=
T
.
exp2
(
acc_s
[
i
,
j
]
*
scale
-
scores_max
[
i
]
*
scale
)
T
.
reduce_sum
(
acc_s
,
scores_sum
,
dim
=
1
)
for
i
in
T
.
Parallel
(
G
):
logsum
[
i
]
=
logsum
[
i
]
*
scores_scale
[
i
]
+
scores_sum
[
i
]
T
.
copy
(
acc_s
,
acc_s_cast
)
# Accumulate attention-weighted values
T
.
copy
(
V
[
i_b
,
i_s
:
i_s
+
BS
,
i_h
,
i_v
*
BV
:(
i_v
+
1
)
*
BV
],
V_shared
)
T
.
gemm
(
acc_s_cast
,
V_shared
,
acc_o
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
)
# Final normalization and output
for
i
,
j
in
T
.
Parallel
(
G
,
BV
):
acc_o
[
i
,
j
]
/=
logsum
[
i
]
# Normalize by logsum
T
.
copy
(
acc_o
,
O_shared
)
T
.
copy
(
O_shared
,
Output
[
i_b
,
0
,
i_h
*
G
:(
i_h
+
1
)
*
G
,
i_v
*
BV
:(
i_v
+
1
)
*
BV
])
# Changed i_t to 0
return
native_sparse_attention
def
main
():
B
,
SEQ_LEN
,
H
,
HQ
,
D
,
S
,
block_size
,
dtype
=
2
,
64
,
1
,
16
,
16
,
1
,
32
,
torch
.
float16
groups
=
HQ
//
H
SEQ_LEN_Q
=
1
kernel
=
native_sparse_attention
(
batch
=
B
,
heads
=
HQ
,
seq_len
=
SEQ_LEN
,
dim
=
D
,
block_size
=
block_size
,
groups
=
HQ
//
H
,
selected_blocks
=
S
,
)
Q
=
torch
.
randn
((
B
,
SEQ_LEN_Q
,
HQ
,
D
),
dtype
=
dtype
,
device
=
'cuda'
).
requires_grad_
(
True
)
K
=
torch
.
randn
((
B
,
SEQ_LEN
,
H
,
D
),
dtype
=
dtype
,
device
=
'cuda'
).
requires_grad_
(
True
)
V
=
torch
.
randn
((
B
,
SEQ_LEN
,
H
,
D
),
dtype
=
dtype
,
device
=
'cuda'
).
requires_grad_
(
True
)
mask
=
torch
.
randint
(
0
,
2
,
(
B
,
SEQ_LEN
,
groups
),
device
=
'cuda'
)
DO
=
torch
.
randn
((
B
,
SEQ_LEN_Q
,
HQ
,
D
),
dtype
=
dtype
,
device
=
'cuda'
)
block_indices
=
torch
.
full
((
B
,
SEQ_LEN_Q
,
H
,
S
),
SEQ_LEN
,
dtype
=
torch
.
long
,
device
=
'cuda'
)
for
b
in
range
(
B
):
for
t
in
range
(
SEQ_LEN_Q
):
for
h
in
range
(
H
):
i_i
=
torch
.
randperm
(
max
(
1
,
(
t
//
block_size
)))[:
S
]
block_indices
[
b
,
t
,
h
,
:
len
(
i_i
)]
=
i_i
block_indices
=
block_indices
.
sort
(
-
1
)[
0
]
block_counts
=
torch
.
randint
(
1
,
S
+
1
,
(
B
,
SEQ_LEN_Q
,
H
),
device
=
'cuda'
)
out
=
kernel
(
Q
,
K
,
V
,
block_indices
.
to
(
torch
.
int32
))
ref
=
naive_nsa_simple_inference
(
q
=
Q
,
k
=
K
,
v
=
V
,
block_indices
=
block_indices
,
block_counts
=
block_counts
,
block_size
=
block_size
,
)
torch
.
testing
.
assert_close
(
ref
,
out
,
atol
=
1e-2
,
rtol
=
1e-2
)
if
__name__
==
"__main__"
:
main
()
examples/deepseek_nsa/example_tilelang_nsa_fwd.py
0 → 100644
View file @
bc2d5632
# ruff: noqa
import
torch
from
reference
import
naive_nsa
import
tilelang
from
tilelang
import
language
as
T
import
tilelang.testing
tilelang
.
testing
.
set_random_seed
(
0
)
@
tilelang
.
jit
(
out_idx
=
[
-
1
],
pass_configs
=
{
tilelang
.
PassConfigKey
.
TL_ENABLE_FAST_MATH
:
True
,
tilelang
.
PassConfigKey
.
TL_DISABLE_TMA_LOWER
:
True
,
tilelang
.
PassConfigKey
.
TL_DISABLE_WARP_SPECIALIZED
:
True
,
})
def
native_sparse_attention
(
batch
,
heads
,
seq_len
,
dim
,
is_causal
,
scale
=
None
,
block_size
=
64
,
groups
=
1
,
selected_blocks
=
16
):
if
scale
is
None
:
scale
=
(
1.0
/
dim
)
**
0.5
*
1.44269504
# log2(e)
else
:
scale
=
scale
*
1.44269504
# log2(e)
head_kv
=
heads
//
groups
q_shape
=
[
batch
,
seq_len
,
heads
,
dim
]
kv_shape
=
[
batch
,
seq_len
,
head_kv
,
dim
]
block_indices_shape
=
[
batch
,
seq_len
,
head_kv
,
selected_blocks
]
block_indices_dtype
=
"int32"
dtype
=
"float16"
accum_dtype
=
"float"
block_S
=
block_size
block_T
=
min
(
128
,
tilelang
.
math
.
next_power_of_2
(
dim
))
NK
=
tilelang
.
cdiv
(
dim
,
block_T
)
NV
=
tilelang
.
cdiv
(
dim
,
block_T
)
assert
NK
==
1
,
"The key dimension can not be larger than 256"
S
=
selected_blocks
G
=
groups
BS
=
block_S
BK
=
BV
=
block_T
num_stages
=
2
threads
=
32
@
T
.
prim_func
def
native_sparse_attention
(
Q
:
T
.
Tensor
(
q_shape
,
dtype
),
K
:
T
.
Tensor
(
kv_shape
,
dtype
),
V
:
T
.
Tensor
(
kv_shape
,
dtype
),
BlockIndices
:
T
.
Tensor
(
block_indices_shape
,
block_indices_dtype
),
Output
:
T
.
Tensor
(
q_shape
,
dtype
),
):
with
T
.
Kernel
(
seq_len
,
NV
,
batch
*
head_kv
,
threads
=
threads
)
as
(
bx
,
by
,
bz
):
Q_shared
=
T
.
alloc_shared
([
G
,
BK
],
dtype
)
K_shared
=
T
.
alloc_shared
([
BS
,
BK
],
dtype
)
V_shared
=
T
.
alloc_shared
([
BS
,
BV
],
dtype
)
O_shared
=
T
.
alloc_shared
([
G
,
BV
],
dtype
)
acc_s
=
T
.
alloc_fragment
([
G
,
BS
],
accum_dtype
)
acc_s_cast
=
T
.
alloc_fragment
([
G
,
BS
],
dtype
)
acc_o
=
T
.
alloc_fragment
([
G
,
BV
],
accum_dtype
)
scores_max
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
scores_max_prev
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
scores_scale
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
scores_sum
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
logsum
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
i_t
,
i_v
,
i_bh
=
bx
,
by
,
bz
i_b
,
i_h
=
i_bh
//
head_kv
,
i_bh
%
head_kv
NS
=
S
T
.
copy
(
Q
[
i_b
,
i_t
,
i_h
*
G
:(
i_h
+
1
)
*
G
,
:],
Q_shared
)
T
.
fill
(
acc_o
,
0
)
T
.
fill
(
logsum
,
0
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
for
i
in
T
.
Pipelined
(
NS
,
num_stages
=
num_stages
):
i_s
=
BlockIndices
[
i_b
,
i_t
,
i_h
,
i
]
*
BS
if
i_s
<=
i_t
and
i_s
>=
0
:
# [BS, BK]
T
.
copy
(
K
[
i_b
,
i_s
:
i_s
+
BS
,
i_h
,
:],
K_shared
)
if
is_causal
:
for
i
,
j
in
T
.
Parallel
(
G
,
BS
):
acc_s
[
i
,
j
]
=
T
.
if_then_else
(
i_t
>=
(
i_s
+
j
),
0
,
-
T
.
infinity
(
acc_s
.
dtype
))
else
:
T
.
clear
(
acc_s
)
T
.
gemm
(
Q_shared
,
K_shared
,
acc_s
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
)
# Softmax
T
.
copy
(
scores_max
,
scores_max_prev
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
T
.
reduce_max
(
acc_s
,
scores_max
,
dim
=
1
,
clear
=
True
)
for
i
in
T
.
Parallel
(
G
):
scores_scale
[
i
]
=
T
.
exp2
(
scores_max_prev
[
i
]
*
scale
-
scores_max
[
i
]
*
scale
)
for
i
,
j
in
T
.
Parallel
(
G
,
BS
):
acc_s
[
i
,
j
]
=
T
.
exp2
(
acc_s
[
i
,
j
]
*
scale
-
scores_max
[
i
]
*
scale
)
T
.
reduce_sum
(
acc_s
,
scores_sum
,
dim
=
1
)
for
i
in
T
.
Parallel
(
G
):
logsum
[
i
]
=
logsum
[
i
]
*
scores_scale
[
i
]
+
scores_sum
[
i
]
T
.
copy
(
acc_s
,
acc_s_cast
)
# Rescale
for
i
,
j
in
T
.
Parallel
(
G
,
BV
):
acc_o
[
i
,
j
]
*=
scores_scale
[
i
]
# V * softmax(Q * K)
T
.
copy
(
V
[
i_b
,
i_s
:
i_s
+
BS
,
i_h
,
i_v
*
BV
:(
i_v
+
1
)
*
BV
],
V_shared
)
T
.
gemm
(
acc_s_cast
,
V_shared
,
acc_o
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
)
for
i
,
j
in
T
.
Parallel
(
G
,
BV
):
acc_o
[
i
,
j
]
/=
logsum
[
i
]
T
.
copy
(
acc_o
,
O_shared
)
T
.
copy
(
O_shared
,
Output
[
i_b
,
i_t
,
i_h
*
G
:(
i_h
+
1
)
*
G
,
i_v
*
BV
:(
i_v
+
1
)
*
BV
])
return
native_sparse_attention
def
main
():
B
,
SEQ_LEN
,
H
,
HQ
,
D
,
S
,
block_size
,
dtype
,
scale
=
2
,
64
,
1
,
16
,
32
,
1
,
32
,
torch
.
float16
,
0.1
kernel
=
native_sparse_attention
(
batch
=
B
,
heads
=
HQ
,
seq_len
=
SEQ_LEN
,
dim
=
D
,
is_causal
=
True
,
block_size
=
block_size
,
groups
=
HQ
//
H
,
selected_blocks
=
S
,
scale
=
scale
,
)
print
(
kernel
.
get_kernel_source
())
torch
.
random
.
manual_seed
(
0
)
Q
=
torch
.
randn
((
B
,
SEQ_LEN
,
HQ
,
D
),
dtype
=
dtype
,
device
=
'cuda'
).
requires_grad_
(
True
)
K
=
torch
.
randn
((
B
,
SEQ_LEN
,
H
,
D
),
dtype
=
dtype
,
device
=
'cuda'
).
requires_grad_
(
True
)
V
=
torch
.
randn
((
B
,
SEQ_LEN
,
H
,
D
),
dtype
=
dtype
,
device
=
'cuda'
).
requires_grad_
(
True
)
g_slc
=
torch
.
ones
((
B
,
SEQ_LEN
,
HQ
),
dtype
=
dtype
,
device
=
'cuda'
).
requires_grad_
(
True
)
g_swa
=
torch
.
ones
((
B
,
SEQ_LEN
,
HQ
),
dtype
=
dtype
,
device
=
'cuda'
).
requires_grad_
(
True
)
DO
=
torch
.
randn
((
B
,
SEQ_LEN
,
HQ
,
D
),
dtype
=
dtype
,
device
=
'cuda'
)
block_indices
=
torch
.
full
((
B
,
SEQ_LEN
,
H
,
S
),
SEQ_LEN
,
dtype
=
torch
.
long
,
device
=
'cuda'
)
for
b
in
range
(
B
):
for
t
in
range
(
SEQ_LEN
):
for
h
in
range
(
H
):
i_i
=
torch
.
randperm
(
max
(
1
,
(
t
//
block_size
)))[:
S
]
block_indices
[
b
,
t
,
h
,
:
len
(
i_i
)]
=
i_i
block_indices
=
block_indices
.
sort
(
-
1
)[
0
]
block_counts
=
torch
.
randint
(
1
,
S
+
1
,
(
B
,
SEQ_LEN
,
H
),
device
=
'cuda'
)
out
=
kernel
(
Q
,
K
,
V
,
block_indices
.
to
(
torch
.
int32
))
ref
=
naive_nsa
(
q
=
Q
,
k
=
K
,
v
=
V
,
g_slc
=
g_slc
,
g_swa
=
g_swa
,
block_indices
=
block_indices
,
block_counts
=
block_counts
,
block_size
=
block_size
,
scale
=
scale
,
)
print
(
"out"
,
out
)
print
(
"ref"
,
ref
)
torch
.
testing
.
assert_close
(
ref
,
out
,
atol
=
1e-2
,
rtol
=
1e-2
)
if
__name__
==
"__main__"
:
main
()
examples/deepseek_nsa/example_tilelang_nsa_fwd_varlen.py
0 → 100644
View file @
bc2d5632
# ruff: noqa
import
torch
from
typing
import
Optional
,
Union
from
packaging.version
import
parse
import
tilelang
from
tilelang
import
language
as
T
import
tilelang.testing
import
fla
if
parse
(
fla
.
__version__
)
<
parse
(
"0.2.1"
):
from
fla.ops.common.utils
import
prepare_token_indices
else
:
from
fla.ops.utils
import
prepare_token_indices
from
reference
import
naive_nsa
from
einops
import
rearrange
@
tilelang
.
jit
(
pass_configs
=
{
tilelang
.
PassConfigKey
.
TL_ENABLE_FAST_MATH
:
True
,
tilelang
.
PassConfigKey
.
TL_DISABLE_TMA_LOWER
:
True
,
tilelang
.
PassConfigKey
.
TL_DISABLE_WARP_SPECIALIZED
:
True
,
})
def
native_sparse_attention_varlen
(
batch
,
heads
,
c_seq_len
,
dim
,
is_causal
,
scale
=
None
,
block_size
=
64
,
groups
=
1
,
selected_blocks
=
16
):
if
scale
is
None
:
scale
=
(
1.0
/
dim
)
**
0.5
*
1.44269504
# log2(e)
head_kv
=
heads
//
groups
q_shape
=
[
c_seq_len
,
heads
,
dim
]
kv_shape
=
[
c_seq_len
,
head_kv
,
dim
]
o_slc_shape
=
[
c_seq_len
,
heads
,
dim
]
o_swa_shape
=
[
c_seq_len
,
heads
,
dim
]
lse_slc_shape
=
[
c_seq_len
,
heads
]
lse_swa_shape
=
[
c_seq_len
,
heads
]
block_indices_shape
=
[
c_seq_len
,
head_kv
,
selected_blocks
]
block_counts_shape
=
[
c_seq_len
,
head_kv
]
offsets_shape
=
[
batch
+
1
]
token_indices_shape
=
[
c_seq_len
,
2
]
block_indices_dtype
=
"int32"
block_counts_dtype
=
"int32"
offsets_dtype
=
"int32"
token_indices_dtype
=
"int32"
dtype
=
"float16"
accum_dtype
=
"float"
block_S
=
block_size
block_T
=
min
(
128
,
tilelang
.
math
.
next_power_of_2
(
dim
))
NK
=
tilelang
.
cdiv
(
dim
,
block_T
)
NV
=
tilelang
.
cdiv
(
dim
,
block_T
)
assert
NK
==
1
,
"The key dimension can not be larger than 256"
S
=
selected_blocks
G
=
groups
BS
=
block_S
BK
=
BV
=
block_T
num_stages
=
0
threads
=
32
@
T
.
prim_func
def
native_sparse_attention_varlen
(
Q
:
T
.
Tensor
(
q_shape
,
dtype
),
K
:
T
.
Tensor
(
kv_shape
,
dtype
),
V
:
T
.
Tensor
(
kv_shape
,
dtype
),
O_slc
:
T
.
Tensor
(
o_slc_shape
,
dtype
),
BlockIndices
:
T
.
Tensor
(
block_indices_shape
,
block_indices_dtype
),
BlockCounts
:
T
.
Tensor
(
block_counts_shape
,
block_counts_dtype
),
Offsets
:
T
.
Tensor
(
offsets_shape
,
offsets_dtype
),
TokenIndices
:
T
.
Tensor
(
token_indices_shape
,
token_indices_dtype
),
):
with
T
.
Kernel
(
c_seq_len
,
NV
,
batch
*
head_kv
,
threads
=
threads
)
as
(
bx
,
by
,
bz
):
Q_shared
=
T
.
alloc_shared
([
G
,
BK
],
dtype
)
K_shared
=
T
.
alloc_shared
([
BS
,
BK
],
dtype
)
V_shared
=
T
.
alloc_shared
([
BS
,
BV
],
dtype
)
O_shared
=
T
.
alloc_shared
([
G
,
BV
],
dtype
)
acc_s
=
T
.
alloc_fragment
([
G
,
BS
],
accum_dtype
)
acc_s_cast
=
T
.
alloc_fragment
([
G
,
BS
],
dtype
)
acc_o
=
T
.
alloc_fragment
([
G
,
BV
],
accum_dtype
)
scores_max
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
scores_max_prev
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
scores_scale
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
scores_sum
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
logsum
=
T
.
alloc_fragment
([
G
],
accum_dtype
)
i_c
,
i_v
,
i_bh
=
bx
,
by
,
bz
i_b
,
i_h
=
i_bh
//
head_kv
,
i_bh
%
head_kv
i_n
,
i_t
=
TokenIndices
[
i_c
,
0
],
TokenIndices
[
i_c
,
1
]
bos
=
Offsets
[
i_n
]
eos
=
Offsets
[
i_n
+
1
]
current_seq_len
=
eos
-
bos
NS
=
BlockCounts
[
i_t
,
i_h
]
T
.
copy
(
Q
[
bos
+
i_t
,
i_h
*
G
:(
i_h
+
1
)
*
G
,
:
BK
],
Q_shared
)
T
.
fill
(
acc_o
,
0
)
T
.
fill
(
logsum
,
0
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
for
i
in
T
.
Pipelined
(
NS
,
num_stages
=
num_stages
):
i_s
=
BlockIndices
[
bos
+
i_t
,
i_h
,
i
]
*
BS
if
i_s
<=
i_t
and
i_s
>=
0
:
# [BS, BK]
# Lei: may have some padding issues
# we should learn from mha varlen templates to handle this
T
.
copy
(
K
[
bos
+
i_s
:
bos
+
i_s
+
BS
,
i_h
,
:
BK
],
K_shared
)
if
is_causal
:
for
i
,
j
in
T
.
Parallel
(
G
,
BS
):
acc_s
[
i
,
j
]
=
T
.
if_then_else
(
i_t
>=
(
i_s
+
j
),
0
,
-
T
.
infinity
(
acc_s
.
dtype
))
else
:
T
.
clear
(
acc_s
)
T
.
gemm
(
Q_shared
,
K_shared
,
acc_s
,
transpose_B
=
True
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
)
# Softmax
T
.
copy
(
scores_max
,
scores_max_prev
)
T
.
fill
(
scores_max
,
-
T
.
infinity
(
accum_dtype
))
T
.
reduce_max
(
acc_s
,
scores_max
,
dim
=
1
,
clear
=
True
)
for
i
in
T
.
Parallel
(
G
):
scores_scale
[
i
]
=
T
.
exp2
(
scores_max_prev
[
i
]
*
scale
-
scores_max
[
i
]
*
scale
)
for
i
,
j
in
T
.
Parallel
(
G
,
BS
):
acc_s
[
i
,
j
]
=
T
.
exp2
(
acc_s
[
i
,
j
]
*
scale
-
scores_max
[
i
]
*
scale
)
T
.
reduce_sum
(
acc_s
,
scores_sum
,
dim
=
1
)
for
i
in
T
.
Parallel
(
G
):
logsum
[
i
]
=
logsum
[
i
]
*
scores_scale
[
i
]
+
scores_sum
[
i
]
T
.
copy
(
acc_s
,
acc_s_cast
)
# Rescale
for
i
,
j
in
T
.
Parallel
(
G
,
BV
):
acc_o
[
i
,
j
]
*=
scores_scale
[
i
]
# V * softmax(Q * K)
T
.
copy
(
V
[
bos
+
i_s
:
bos
+
i_s
+
BS
,
i_h
,
i_v
*
BV
:(
i_v
+
1
)
*
BV
],
V_shared
)
T
.
gemm
(
acc_s_cast
,
V_shared
,
acc_o
,
policy
=
T
.
GemmWarpPolicy
.
FullRow
)
for
i
,
j
in
T
.
Parallel
(
G
,
BV
):
acc_o
[
i
,
j
]
/=
logsum
[
i
]
T
.
copy
(
acc_o
,
O_shared
)
T
.
copy
(
O_shared
,
O_slc
[
bos
+
i_t
,
i_h
*
G
:(
i_h
+
1
)
*
G
,
i_v
*
BV
:(
i_v
+
1
)
*
BV
])
return
native_sparse_attention_varlen
def
parallel_nsa_fwd
(
q
:
torch
.
Tensor
,
k
:
torch
.
Tensor
,
v
:
torch
.
Tensor
,
block_indices
:
torch
.
LongTensor
,
block_counts
:
Union
[
torch
.
LongTensor
,
int
],
block_size
:
int
,
window_size
:
int
,
scale
:
float
,
offsets
:
Optional
[
torch
.
LongTensor
]
=
None
,
token_indices
:
Optional
[
torch
.
LongTensor
]
=
None
,
):
B
,
C_SEQ_LEN
,
H
,
K
,
V
,
S
=
*
k
.
shape
,
v
.
shape
[
-
1
],
block_indices
.
shape
[
-
1
]
batch
=
len
(
offsets
)
-
1
HQ
=
q
.
shape
[
2
]
G
=
HQ
//
H
BS
=
block_size
WS
=
window_size
kernel
=
native_sparse_attention_varlen
(
batch
=
batch
,
heads
=
HQ
,
c_seq_len
=
C_SEQ_LEN
,
dim
=
K
,
is_causal
=
True
,
block_size
=
block_size
,
groups
=
G
,
selected_blocks
=
S
,
)
o_slc
=
torch
.
empty
(
B
,
C_SEQ_LEN
,
HQ
,
V
,
dtype
=
v
.
dtype
,
device
=
q
.
device
)
kernel
(
q
.
view
(
C_SEQ_LEN
,
HQ
,
D
),
k
.
view
(
C_SEQ_LEN
,
H
,
D
),
v
.
view
(
C_SEQ_LEN
,
H
,
D
),
o_slc
.
view
(
C_SEQ_LEN
,
HQ
,
V
),
block_indices
.
to
(
torch
.
int32
).
view
(
C_SEQ_LEN
,
H
,
S
),
block_counts
.
to
(
torch
.
int32
).
view
(
C_SEQ_LEN
,
H
),
offsets
.
to
(
torch
.
int32
),
token_indices
.
to
(
torch
.
int32
))
return
o_slc
@
torch
.
compile
class
ParallelNSAFunction
(
torch
.
autograd
.
Function
):
@
staticmethod
def
forward
(
ctx
,
q
,
k
,
v
,
block_indices
,
block_counts
,
block_size
,
window_size
,
scale
,
offsets
):
ctx
.
dtype
=
q
.
dtype
# 2-d sequence indices denoting the offsets of tokens in each sequence
# for example, if the passed `offsets` is [0, 2, 6],
# then there are 2 and 4 tokens in the 1st and 2nd sequences respectively, and `token_indices` will be
# [[0, 0], [0, 1], [1, 0], [1, 1], [1, 2], [1, 3]]
token_indices
=
prepare_token_indices
(
offsets
)
if
offsets
is
not
None
else
None
o_slc
=
parallel_nsa_fwd
(
q
=
q
,
k
=
k
,
v
=
v
,
block_indices
=
block_indices
,
block_counts
=
block_counts
,
block_size
=
block_size
,
window_size
=
window_size
,
scale
=
scale
,
offsets
=
offsets
,
token_indices
=
token_indices
)
return
o_slc
.
to
(
q
.
dtype
)
def
parallel_nsa
(
q
:
torch
.
Tensor
,
k
:
torch
.
Tensor
,
v
:
torch
.
Tensor
,
g_slc
:
torch
.
Tensor
,
g_swa
:
torch
.
Tensor
,
block_indices
:
torch
.
LongTensor
,
block_counts
:
Optional
[
Union
[
torch
.
LongTensor
,
int
]]
=
None
,
block_size
:
int
=
64
,
window_size
:
int
=
0
,
scale
:
Optional
[
float
]
=
None
,
cu_seqlens
:
Optional
[
torch
.
LongTensor
]
=
None
,
head_first
:
bool
=
False
)
->
torch
.
Tensor
:
r
"""
Args:
q (torch.Tensor):
queries of shape `[B, T, HQ, K]` if `head_first=False` else `[B, HQ, T, K]`.
k (torch.Tensor):
keys of shape `[B, T, H, K]` if `head_first=False` else `[B, H, T, K]`.
GQA is enforced here. The ratio of query heads (HQ) to key/value heads (H) must be a power of 2 and >=16.
v (torch.Tensor):
values of shape `[B, T, H, V]` if `head_first=False` else `[B, H, T, V]`.
g_slc (torch.Tensor):
Gate score for selected attention of shape `[B, T, HQ]` if `head_first=False` else `[B, HQ, T]`.
g_swa (torch.Tensor):
Gate score for sliding attentionof shape `[B, T, HQ]` if `head_first=False` else `[B, HQ, T]`.
block_indices (torch.LongTensor):
Block indices of shape `[B, T, H, S]` if `head_first=False` else `[B, H, T, S]`.
`S` is the number of selected blocks for each query token, which is set to 16 in the paper.
block_counts (Union[torch.LongTensor, int]):
Number of selected blocks for each token.
If a tensor is provided, with shape `[B, T, H]` if `head_first=True` else `[B, T, H]`,
each token can select the same number of blocks.
If not provided, it will default to `S`, Default: `None`
block_size (int):
Selected block size. Default: 64.
window_size (int):
Sliding window size. Default: 0.
scale (Optional[int]):
Scale factor for attention scores.
If not provided, it will default to `1 / sqrt(K)`. Default: `None`.
head_first (Optional[bool]):
Whether the inputs are in the head-first format. Default: `False`.
cu_seqlens (torch.LongTensor):
Cumulative sequence lengths of shape `[N+1]` used for variable-length training,
consistent with the FlashAttention API.
Returns:
o (torch.Tensor):
Outputs of shape `[B, T, HQ, V]` if `head_first=False` else `[B, HQ, T, V]`.
"""
if
scale
is
None
:
scale
=
k
.
shape
[
-
1
]
**-
0.5
if
cu_seqlens
is
not
None
:
assert
q
.
shape
[
0
]
==
1
,
"batch size must be 1 when cu_seqlens are provided"
if
head_first
:
q
,
k
,
v
,
block_indices
=
map
(
lambda
x
:
rearrange
(
x
,
'b h t d -> b t h d'
),
(
q
,
k
,
v
,
block_indices
))
g_slc
,
g_swa
=
map
(
lambda
x
:
rearrange
(
x
,
'b h t -> b t h'
),
(
g_slc
,
g_swa
))
if
isinstance
(
block_counts
,
torch
.
Tensor
):
block_counts
=
rearrange
(
block_counts
,
'b h t -> b t h'
)
assert
q
.
shape
[
2
]
%
(
k
.
shape
[
2
]
*
16
)
==
0
,
"Group size must be a multiple of 16 in NSA"
if
isinstance
(
block_counts
,
int
):
block_indices
=
block_indices
[:,
:,
:,
:
block_counts
]
block_counts
=
None
o_slc
=
ParallelNSAFunction
.
apply
(
q
,
k
,
v
,
block_indices
,
block_counts
,
block_size
,
window_size
,
scale
,
cu_seqlens
)
if
window_size
>
0
:
assert
False
,
"Window size is not supported yet"
else
:
o
=
o_slc
*
g_slc
.
unsqueeze
(
-
1
)
if
head_first
:
o
=
rearrange
(
o
,
'b t h d -> b h t d'
)
return
o
if
__name__
==
"__main__"
:
N
,
C_SEQ_LEN
,
H
,
HQ
,
D
,
S
,
block_size
,
dtype
=
2
,
64
,
1
,
16
,
64
,
1
,
32
,
torch
.
float16
torch
.
manual_seed
(
42
)
# randomly split the sequence into N segments
offsets
=
torch
.
cat
([
torch
.
tensor
([
0
],
dtype
=
torch
.
long
),
torch
.
arange
(
16
,
C_SEQ_LEN
)[
torch
.
randperm
(
C_SEQ_LEN
-
1
)[:
N
-
1
]],
torch
.
tensor
([
C_SEQ_LEN
],
dtype
=
torch
.
long
)
],
0
).
cuda
().
sort
()[
0
]
# seq-first required for inputs with variable lengths
perm_q
=
torch
.
randperm
(
C_SEQ_LEN
,
device
=
'cuda'
)
perm_k
=
torch
.
randperm
(
C_SEQ_LEN
,
device
=
'cuda'
)
perm_v
=
torch
.
randperm
(
C_SEQ_LEN
,
device
=
'cuda'
)
q
=
torch
.
linspace
(
0
,
1
,
steps
=
C_SEQ_LEN
,
dtype
=
dtype
,
device
=
'cuda'
)[
perm_q
].
view
(
1
,
C_SEQ_LEN
,
1
,
1
).
expand
(
1
,
C_SEQ_LEN
,
HQ
,
D
).
clone
().
requires_grad_
(
True
)
k
=
torch
.
linspace
(
0
,
1
,
steps
=
C_SEQ_LEN
,
dtype
=
dtype
,
device
=
'cuda'
)[
perm_k
].
view
(
1
,
C_SEQ_LEN
,
1
,
1
).
expand
(
1
,
C_SEQ_LEN
,
H
,
D
).
clone
().
requires_grad_
(
True
)
v
=
torch
.
linspace
(
0
,
1
,
steps
=
C_SEQ_LEN
,
dtype
=
dtype
,
device
=
'cuda'
)[
perm_v
].
view
(
1
,
C_SEQ_LEN
,
1
,
1
).
expand
(
1
,
C_SEQ_LEN
,
H
,
D
).
clone
().
requires_grad_
(
True
)
g_slc
=
torch
.
rand
((
1
,
C_SEQ_LEN
,
HQ
),
dtype
=
dtype
,
device
=
'cuda'
).
requires_grad_
(
True
)
g_swa
=
torch
.
rand
((
1
,
C_SEQ_LEN
,
HQ
),
dtype
=
dtype
,
device
=
'cuda'
).
requires_grad_
(
True
)
do
=
torch
.
randn
((
1
,
C_SEQ_LEN
,
HQ
,
D
),
dtype
=
dtype
,
device
=
'cuda'
)
token_indices
=
prepare_token_indices
(
offsets
).
tolist
()
block_indices
=
torch
.
full
((
1
,
C_SEQ_LEN
,
H
,
S
),
C_SEQ_LEN
,
dtype
=
torch
.
long
,
device
=
'cuda'
)
for
i
in
range
(
C_SEQ_LEN
):
_
,
t
=
token_indices
[
i
]
for
h
in
range
(
H
):
i_i
=
torch
.
randperm
(
max
(
1
,
tilelang
.
cdiv
(
t
,
block_size
)))[:
S
]
block_indices
[
0
,
i
,
h
,
:
len
(
i_i
)]
=
i_i
block_indices
=
block_indices
.
sort
(
-
1
)[
0
]
block_counts
=
torch
.
randint
(
1
,
S
+
1
,
(
1
,
C_SEQ_LEN
,
H
),
device
=
'cuda'
)
ref
=
naive_nsa
(
q
=
q
,
k
=
k
,
v
=
v
,
g_slc
=
g_slc
,
g_swa
=
g_swa
,
block_indices
=
block_indices
,
block_counts
=
block_counts
,
block_size
=
block_size
,
cu_seqlens
=
offsets
)
tri
=
parallel_nsa
(
q
=
q
,
k
=
k
,
v
=
v
,
g_slc
=
g_slc
,
g_swa
=
g_swa
,
block_indices
=
block_indices
,
block_counts
=
block_counts
,
block_size
=
block_size
,
cu_seqlens
=
offsets
)
print
(
"tri"
,
tri
)
print
(
"ref"
,
ref
)
torch
.
testing
.
assert_close
(
ref
,
tri
,
atol
=
1e-2
,
rtol
=
1e-2
)
Prev
1
…
4
5
6
7
8
9
10
11
12
13
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}

{kind=link}

{kind=link}
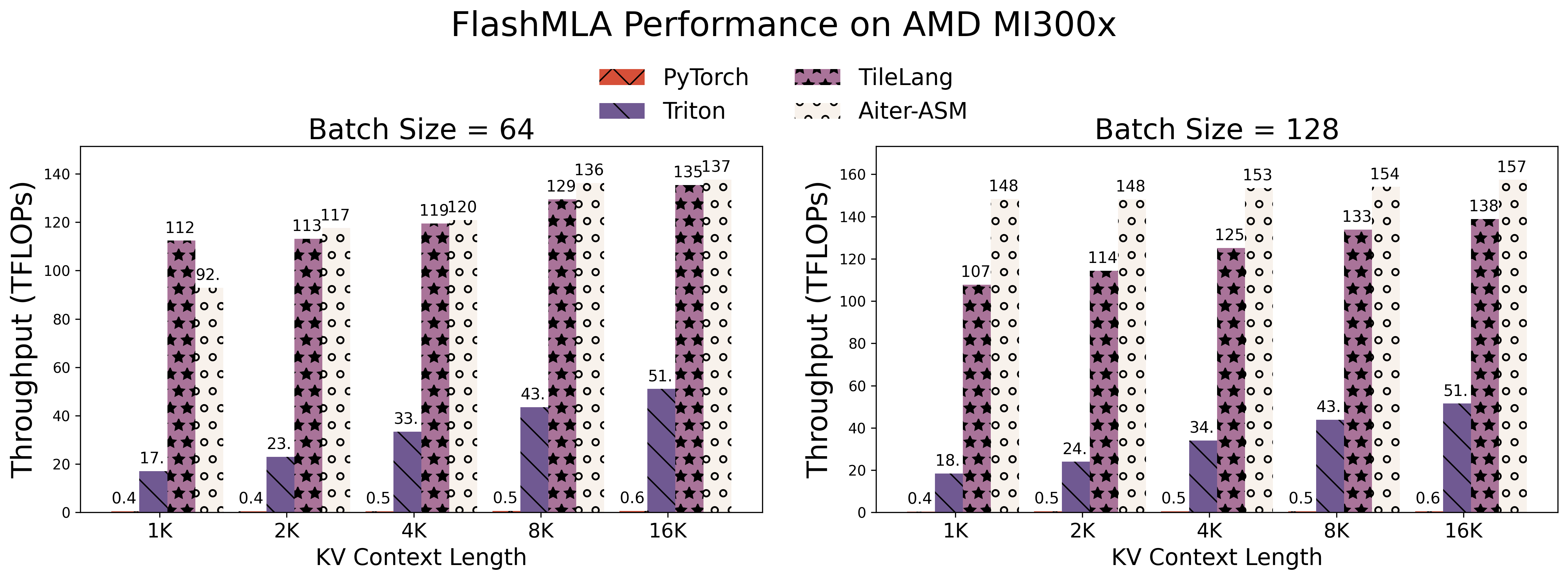
{kind=link}
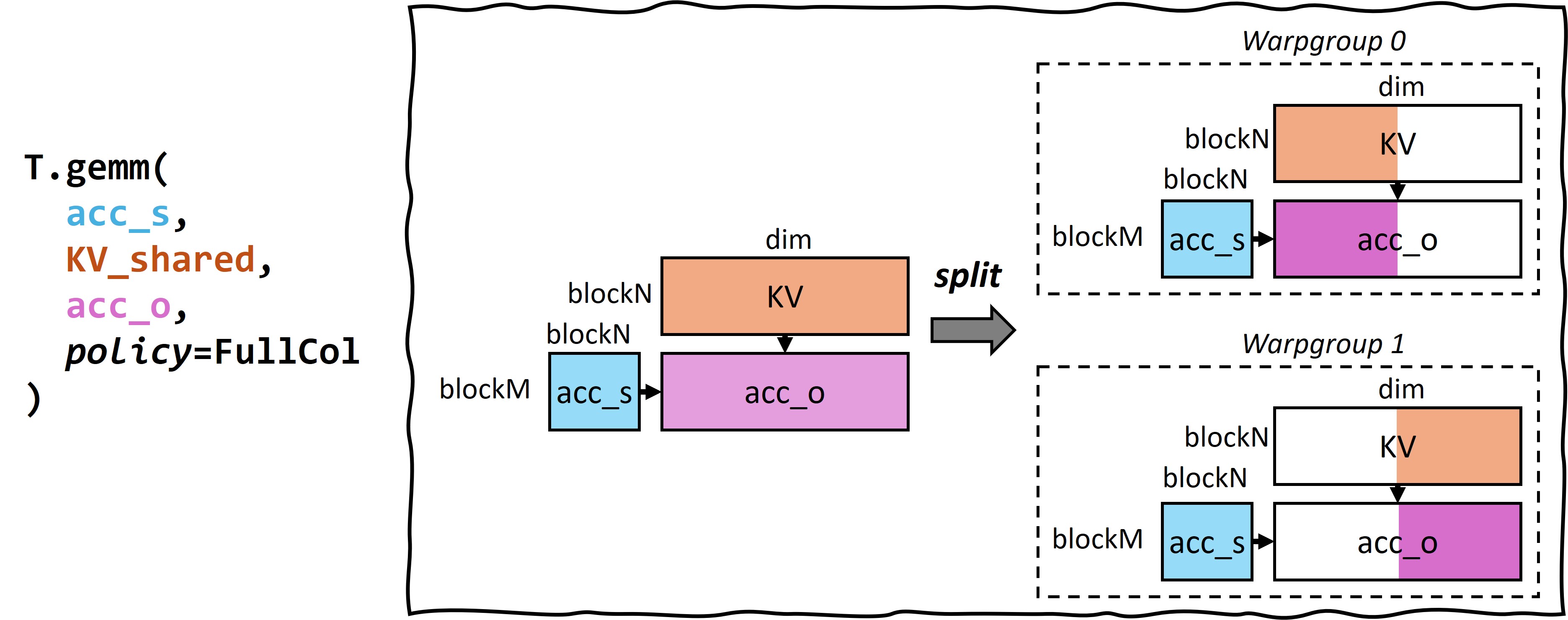
{kind=link}