
init
Showing
Too many changes to show.
To preserve performance only 257 of 257+ files are displayed.
{kind=link}
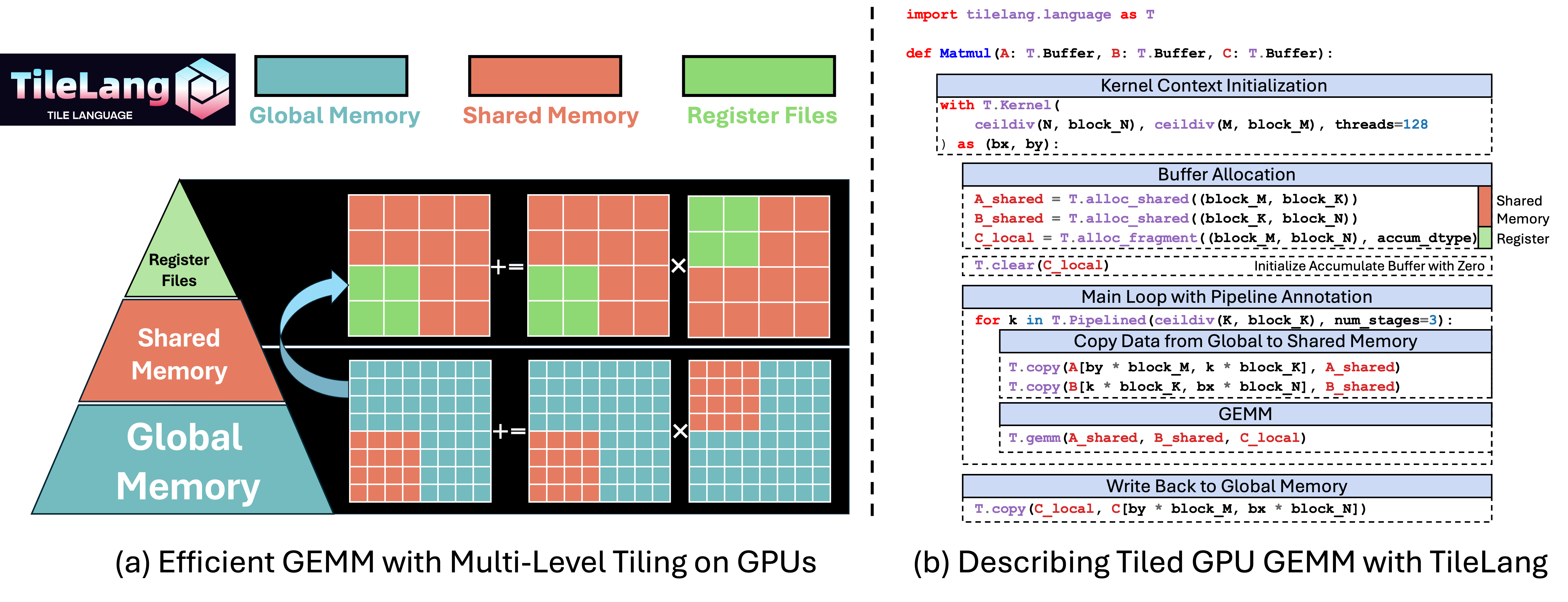
807 KB
{kind=link}
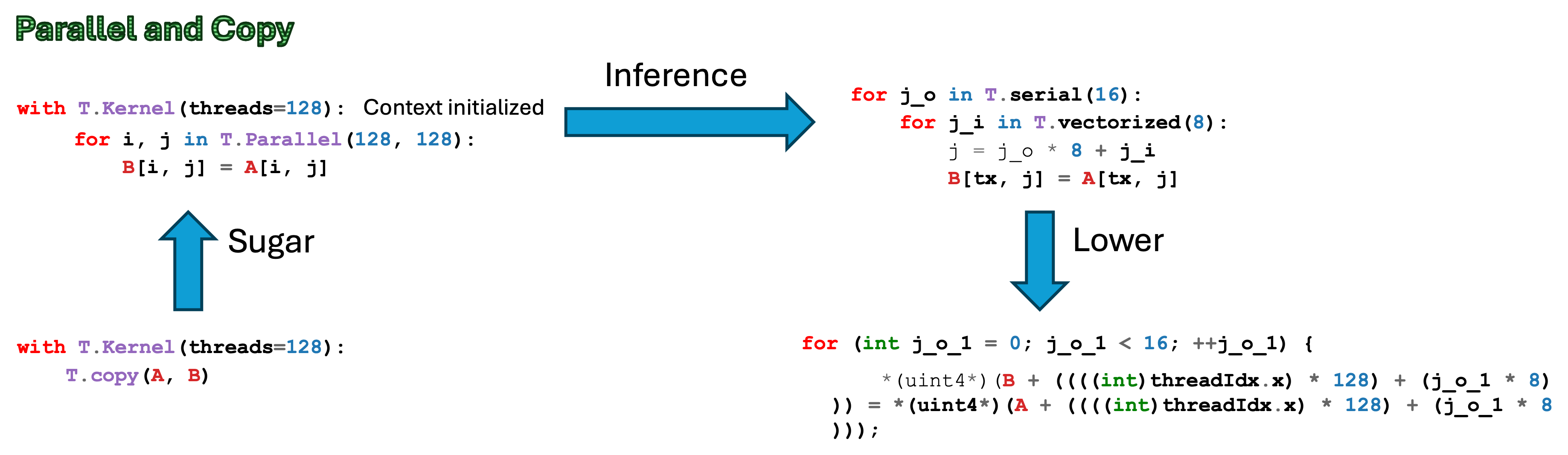
253 KB
{kind=link}
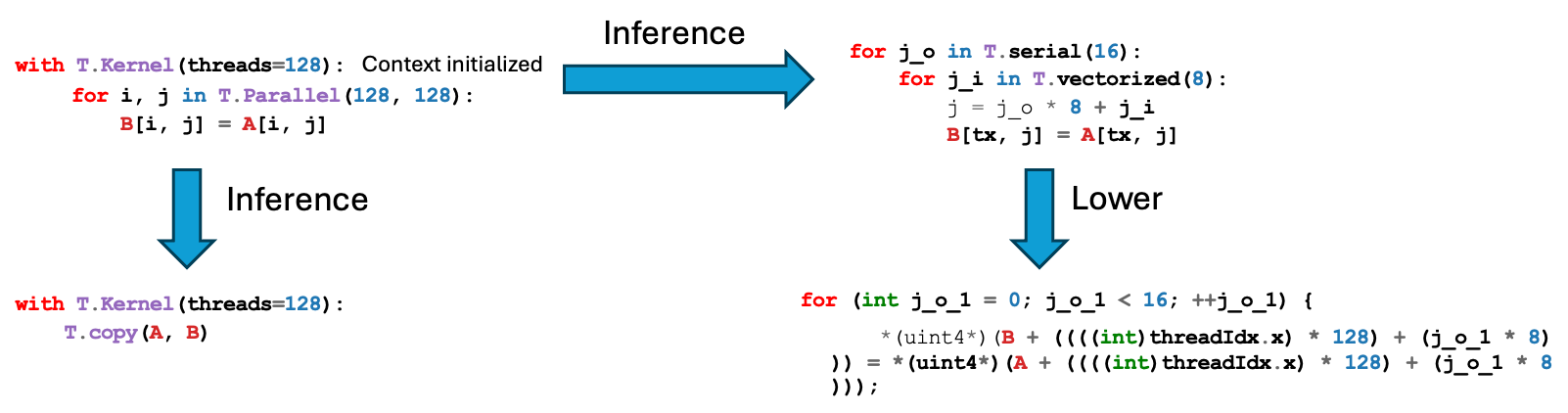
83.5 KB
{kind=link}
{kind=link}
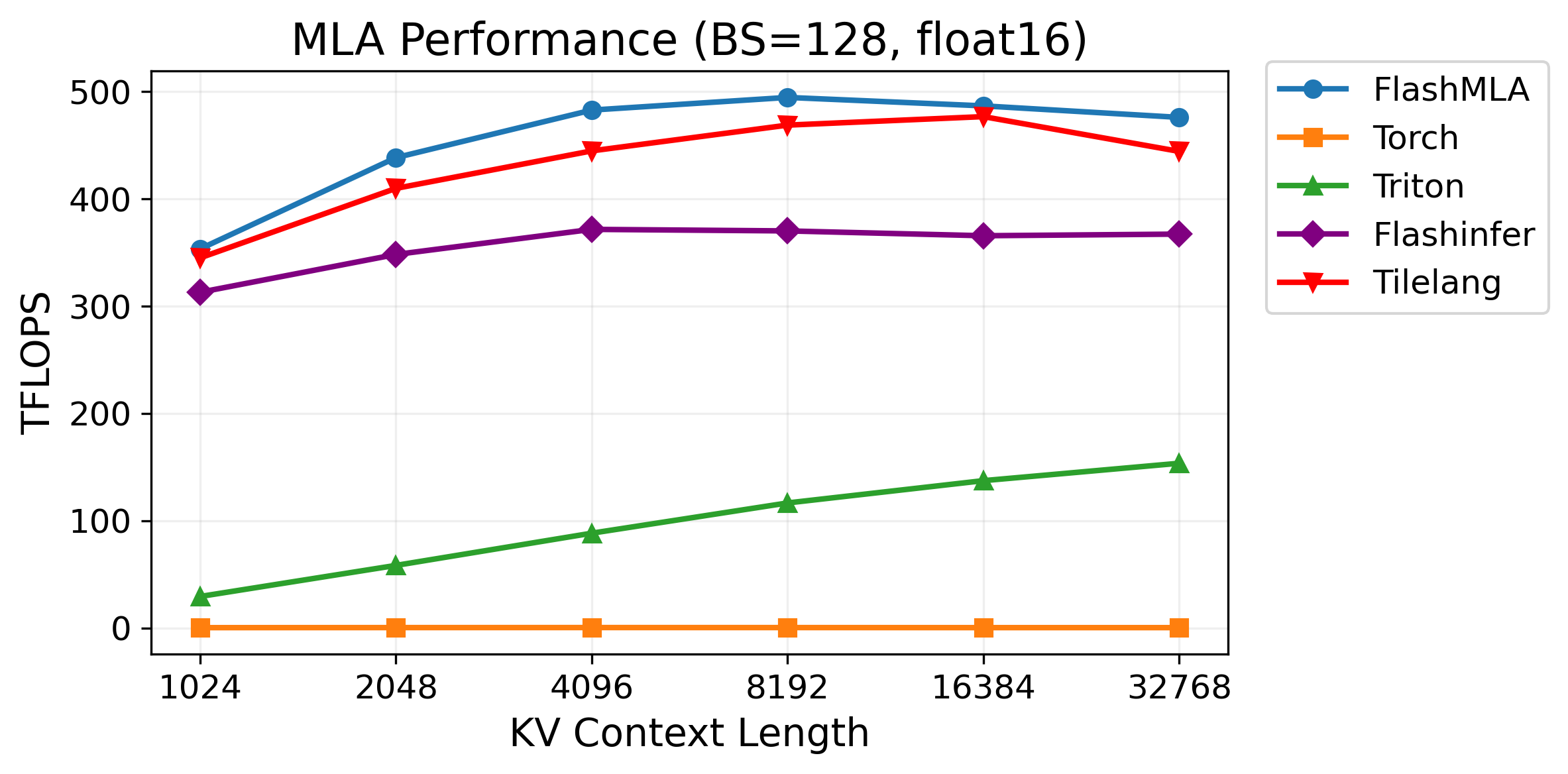
153 KB
{kind=link}
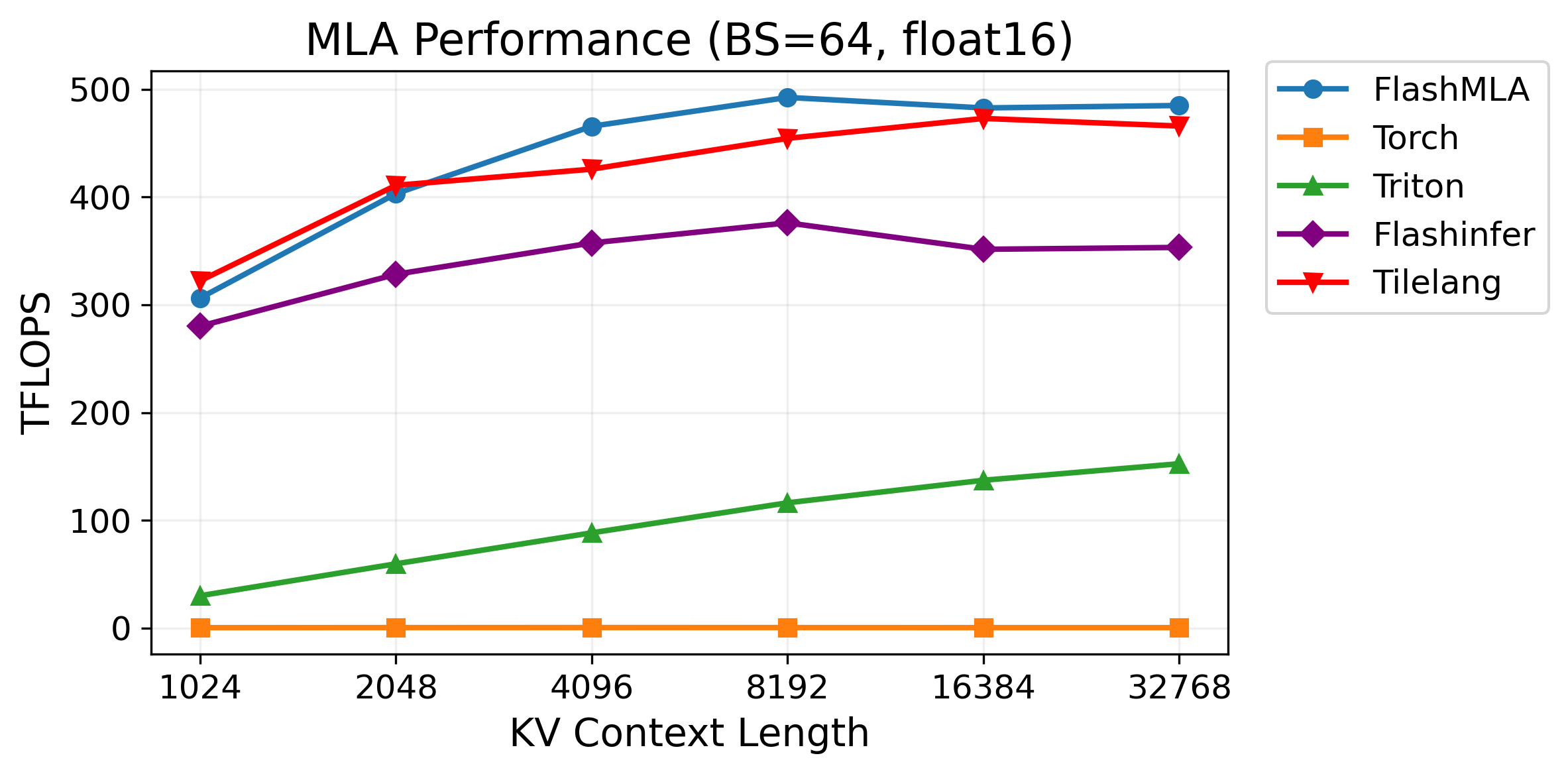
154 KB
{kind=link}
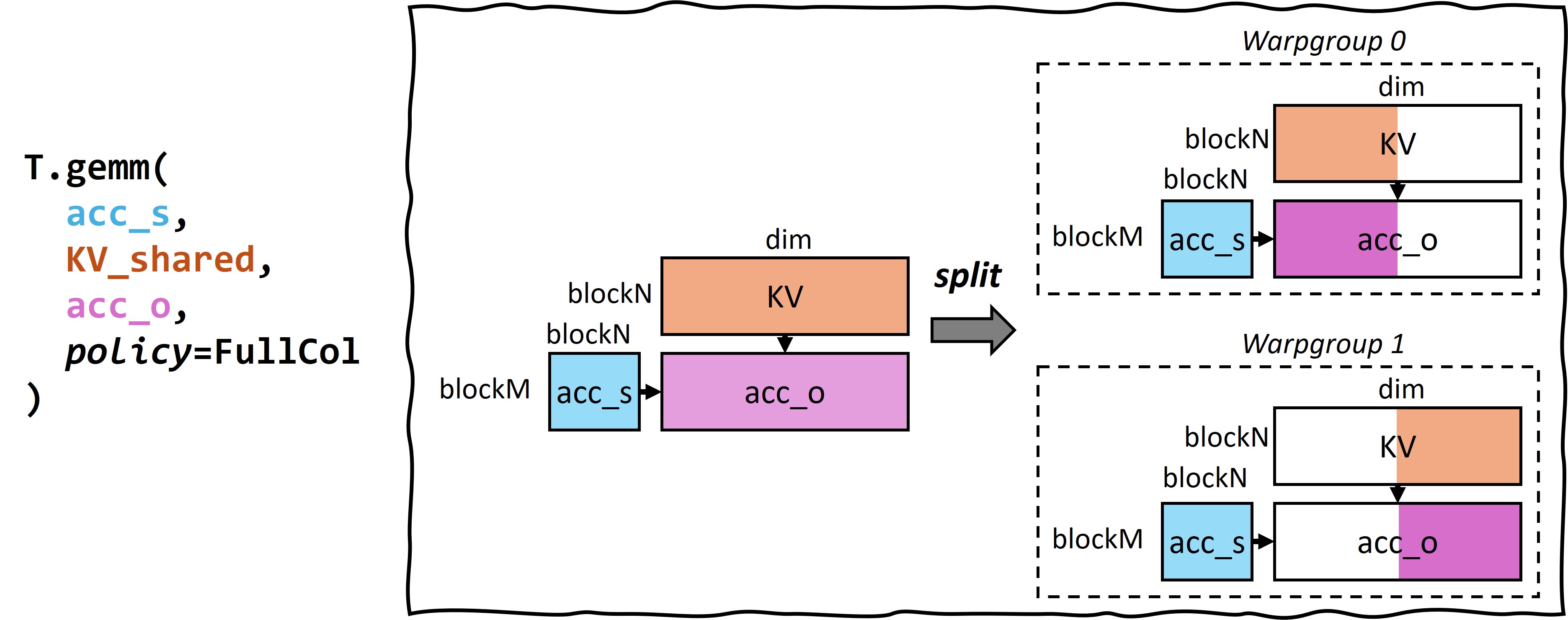
394 KB
{kind=link}
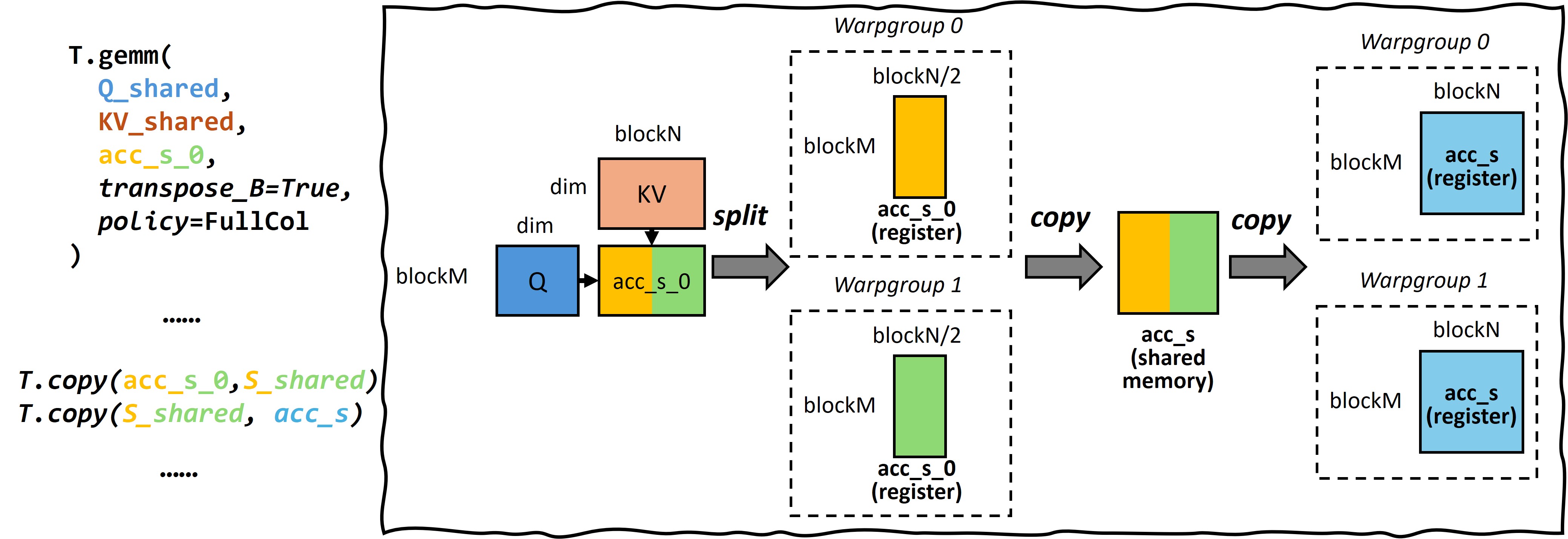
496 KB
{kind=link}

295 KB
{kind=link}
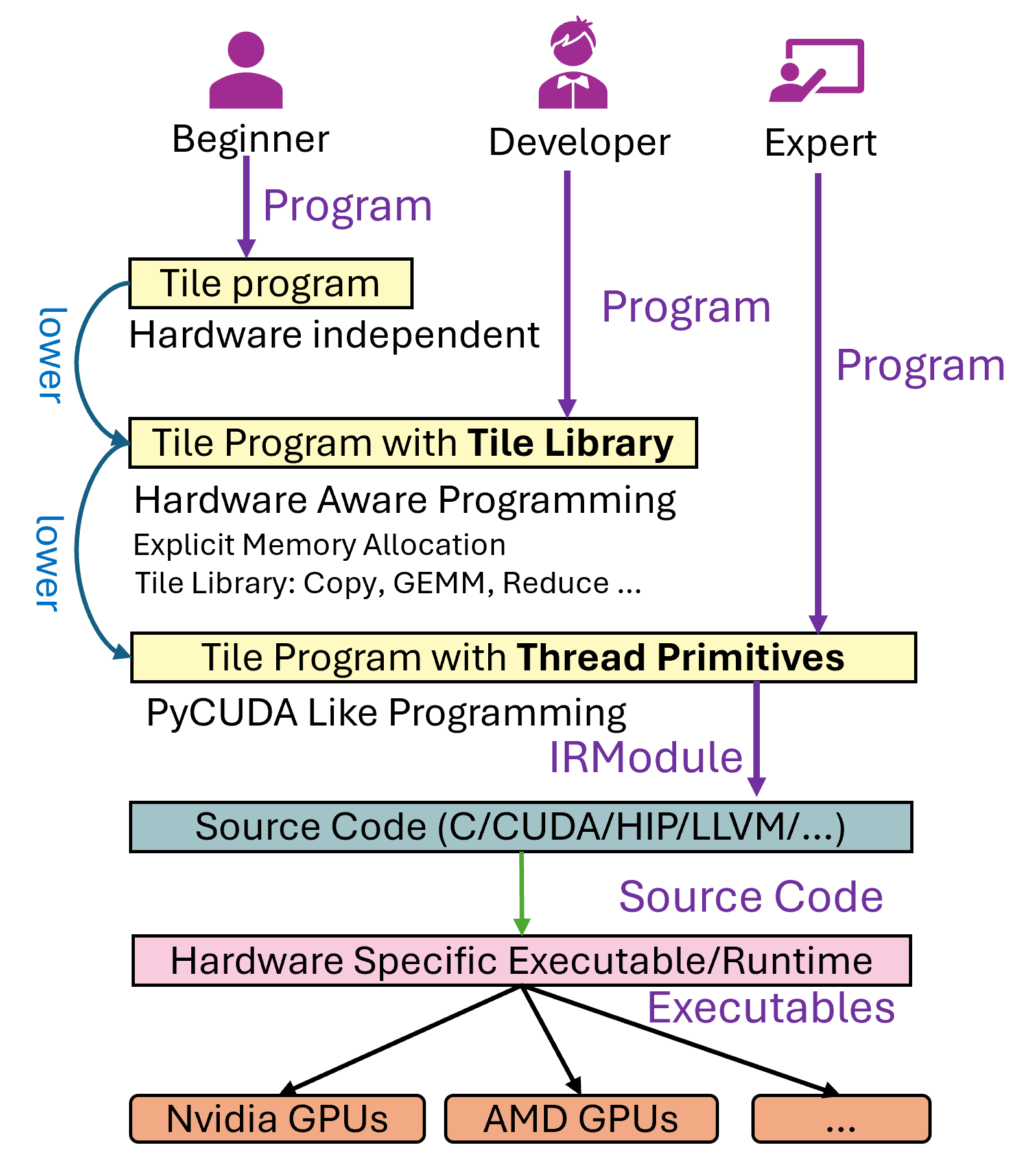
142 KB
{kind=link}
263 KB
docs/conf.py
0 → 100644
docs/get_started/overview.md
0 → 100644