"...git@developer.sourcefind.cn:tsoc/superbenchmark.git" did not exist on "57ce473a024c3fb84f6f38fd0be139f2438e3f4a"

init
Showing
{kind=link}
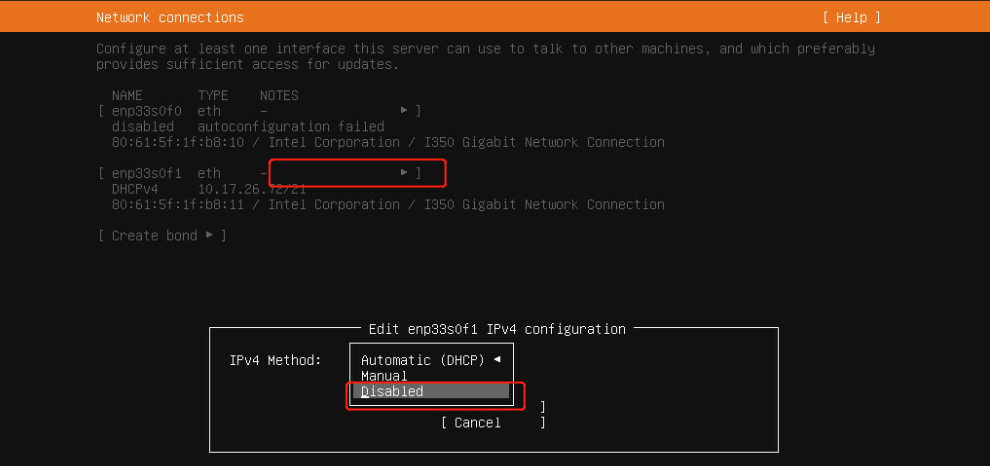
81.2 KB
{kind=link}
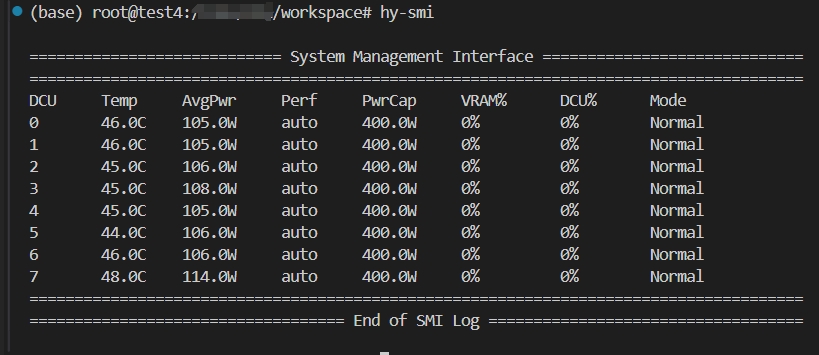
149 KB
{kind=link}

18.6 KB
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
{kind=link}
This diff is collapsed.
{kind=link}
This diff is collapsed.
This diff is collapsed.