| Model Name |
CogView3-Base-3B |
CogView3-Base-3B-distill |
CogView3-Plus-3B |
| Model Description |
The base and relay stage models of CogView3, supporting 512x512 text-to-image generation and 2x super-resolution generation. |
The distilled version of CogView3, with 4 and 1 step sampling in two stages (or 8 and 2 steps). |
The DiT version image generation model, supporting image generation ranging from 512 to 2048. |
| Resolution |
512 * 512 |
512 <= H, W <= 2048
H * W <= 2^{21}
H, W \mod 32 = 0
|
| Inference Precision |
FP16 (recommended), BF16, FP32 |
BF16* (recommended), FP16, FP32 |
| Memory Usage (bs = 4) |
17G |
64G |
30G (2048 * 2048)
20G (1024 * 1024) |
| Prompt Language |
English* |
| Maximum Prompt Length |
225 Tokens |
224 Tokens |
| Download Link (SAT) |
SAT |
| Download Link (Diffusers) |
Not Adapted |
🤗 HuggingFace
🤖 ModelScope
🟣 WiseModel
|
**Data Explanation**
+ All inference tests were conducted on a single A100 GPU with a batch size of 4,
using `PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True` to save memory.
+ The models only support English input. Other languages can be translated into English when refining with large models.
+ This test environment uses the `SAT` framework. Many optimization points are not yet complete, and we will work with
the community to create a version of the model for the `diffusers` library. Once the `diffusers` repository is
supported, we will test using `diffusers`. The release is expected in November 2024.
## Quick Start
### Prompt Optimization
Although CogView3 series models are trained with long image descriptions, we highly recommend rewriting prompts using
large language models (LLMs) before generating text-to-image, as this will significantly improve generation quality.
We provide an [example script](prompt_optimize.py). We suggest running this script to refine the prompt:
```shell
python prompt_optimize.py --api_key "Zhipu AI API Key" --prompt {your prompt} --base_url "https://open.bigmodel.cn/api/paas/v4" --model "glm-4-plus"
```
### Inference Model (Diffusers)
First, ensure the `diffusers` library is installed **from source**.
```
pip install git+https://github.com/huggingface/diffusers.git
```
Then, run the following code:
```python
from diffusers import CogView3PlusPipeline
import torch
pipe = CogView3PlusPipeline.from_pretrained("THUDM/CogView3-Plus-3B", torch_dtype=torch.float16).to("cuda")
# Enable it to reduce GPU memory usage
pipe.enable_model_cpu_offload()
pipe.vae.enable_slicing()
pipe.vae.enable_tiling()
prompt = "A vibrant cherry red sports car sits proudly under the gleaming sun, its polished exterior smooth and flawless, casting a mirror-like reflection. The car features a low, aerodynamic body, angular headlights that gaze forward like predatory eyes, and a set of black, high-gloss racing rims that contrast starkly with the red. A subtle hint of chrome embellishes the grille and exhaust, while the tinted windows suggest a luxurious and private interior. The scene conveys a sense of speed and elegance, the car appearing as if it's about to burst into a sprint along a coastal road, with the ocean's azure waves crashing in the background."
image = pipe(
prompt=prompt,
guidance_scale=7.0,
num_images_per_prompt=1,
num_inference_steps=50,
width=1024,
height=1024,
).images[0]
image.save("cogview3.png")
```
For more inference code, please refer to [inference](inference/cli_demo.py). This folder also contains a simple WEBUI code wrapped with Gradio.
### Inference Model (SAT)
Please check the [sat](sat/README.md) tutorial for step-by-step instructions on model inference.
### Open Source Plan
Since the project is in its early stages, we are working on the following:
+ [ ] Fine-tuning the SAT version of CogView3-Plus-3B, including SFT and LoRA fine-tuning
+ [X] Inference with the Diffusers library version of the CogView3-Plus-3B model
+ [ ] Fine-tuning the Diffusers library version of the CogView3-Plus-3B model
+ [ ] Related work for the CogView3-Plus-3B model, including ControlNet and other tasks.
## CogView3 (ECCV'24)
Official paper
repository: [CogView3: Finer and Faster Text-to-Image Generation via Relay Diffusion](https://arxiv.org/abs/2403.05121)
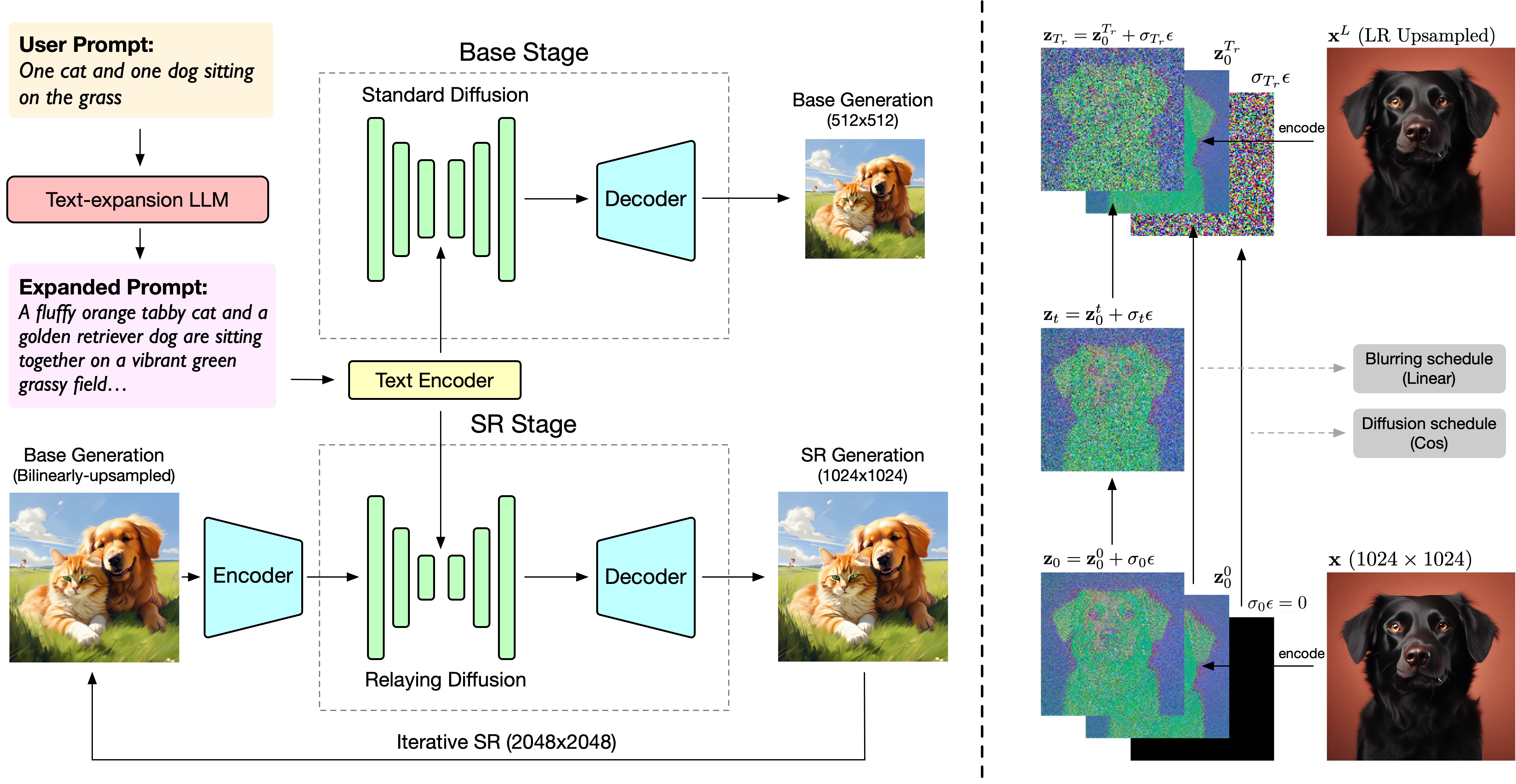
CogView3 is a novel text-to-image generation system using relay diffusion. It breaks down the process of generating
high-resolution images into multiple stages. Through the relay super-resolution process, Gaussian noise is added to
low-resolution generation results, and the diffusion process begins from these noisy images. Our results show that
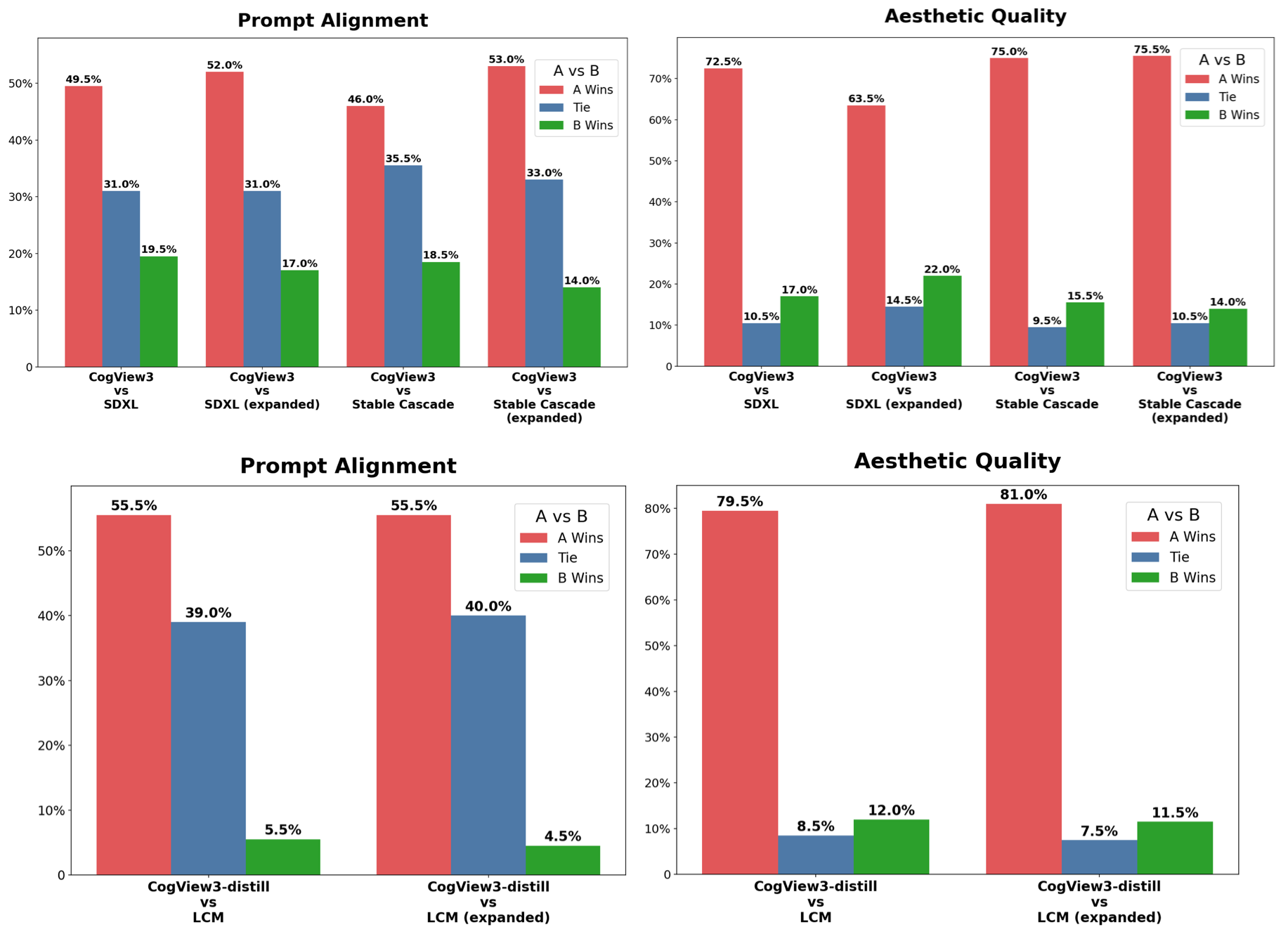
CogView3 outperforms SDXL with a winning rate of 77.0%. Additionally, through progressive distillation of the diffusion
model, CogView3 can generate comparable results while reducing inference time to only 1/10th of SDXL's.

Comparison results from human evaluations:
## Citation
🌟 If you find our work helpful, feel free to cite our paper and leave a star.
```
@article{zheng2024cogview3,
title={Cogview3: Finer and faster text-to-image generation via relay diffusion},
author={Zheng, Wendi and Teng, Jiayan and Yang, Zhuoyi and Wang, Weihan and Chen, Jidong and Gu, Xiaotao and Dong, Yuxiao and Ding, Ming and Tang, Jie},
journal={arXiv preprint arXiv:2403.05121},
year={2024}
}
```
We welcome your contributions! Click [here](resources/contribute.md) for more information.
## Model License
This codebase is released under the [Apache 2.0 License](LICENSE).
The CogView3-Base, CogView3-Relay, and CogView3-Plus models (including the UNet module, Transformers module, and VAE
module) are released under the [Apache 2.0 License](LICENSE).