+ OpenMMLab website
+
+
+ HOT
+
+
+
+ OpenMMLab platform
+
+
+ TRY IT OUT
+
+
+
+  +
+English | [简体中文](/README_zh-CN.md)
+
+
+
+English | [简体中文](/README_zh-CN.md)
+
+
+
+[English](/README.md) | 简体中文
+
+
+
+English | [简体中文](/README_zh-CN.md)
+
+
+
+English | [简体中文](/README_zh-CN.md)
+
+
+
+[English](/README.md) | 简体中文
+
+
 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
++ The page you are looking for cannot be found. +
++ If you just switched documentation versions, it is likely that the page you were on is moved. You can look for it in + the content table left, or go to the homepage. +
++ If you cannot find documentation you want, please open an issue to tell us! +
+ +{% endblock %} diff --git a/docs/en/_templates/autosummary/class.rst b/docs/en/_templates/autosummary/class.rst new file mode 100644 index 0000000000000000000000000000000000000000..4c3a7a9abf5c5b14ac3ef3b00a2f070480295358 --- /dev/null +++ b/docs/en/_templates/autosummary/class.rst @@ -0,0 +1,13 @@ +.. role:: hidden + :class: hidden-section +.. currentmodule:: {{ module }} + + +{{ name | underline}} + +.. autoclass:: {{ name }} + :members: + +.. + autogenerated from _templates/autosummary/class.rst + note it does not have :inherited-members: diff --git a/docs/en/_templates/callable.rst b/docs/en/_templates/callable.rst new file mode 100644 index 0000000000000000000000000000000000000000..3a7b9d2b96c76dfa3eb1d8bef56f58f219fe7760 --- /dev/null +++ b/docs/en/_templates/callable.rst @@ -0,0 +1,14 @@ +.. role:: hidden + :class: hidden-section +.. currentmodule:: {{ module }} + + +{{ name | underline}} + +.. autoclass:: {{ name }} + :members: + :special-members: __call__ + +.. + autogenerated from _templates/callable.rst + note it does not have :inherited-members: diff --git a/docs/en/_templates/data_transform.rst b/docs/en/_templates/data_transform.rst new file mode 100644 index 0000000000000000000000000000000000000000..376bfe9db6c305e681f265dd0e20b7b7ea6e500f --- /dev/null +++ b/docs/en/_templates/data_transform.rst @@ -0,0 +1,13 @@ +.. role:: hidden + :class: hidden-section +.. currentmodule:: {{ module }} + + +{{ name | underline}} + +.. autoclass:: {{ name }} + :members: transform + +.. + autogenerated from _templates/callable.rst + note it does not have :inherited-members: diff --git a/docs/en/advanced_guides/convention.md b/docs/en/advanced_guides/convention.md new file mode 100644 index 0000000000000000000000000000000000000000..9edd04c1d5685aaa353e10d04e7a609d9fc9adf4 --- /dev/null +++ b/docs/en/advanced_guides/convention.md @@ -0,0 +1,120 @@ +# Convention in MMPretrain + +## Model Naming Convention + +We follow the below convention to name models. Contributors are advised to follow the same style. The model names are divided into five parts: algorithm info, module information, pretrain information, training information and data information. Logically, different parts are concatenated by underscores `'_'`, and words in the same part are concatenated by dashes `'-'`. + +```text +{algorithm info}_{module info}_{pretrain info}_{training info}_{data info} +``` + +- `algorithm info` (optional): The main algorithm information, it's includes the main training algorithms like MAE, BEiT, etc. +- `module info`: The module information, it usually includes the backbone name, such as resnet, vit, etc. +- `pretrain info`: (optional): The pretrain model information, such as the pretrain model is trained on ImageNet-21k. +- `training info`: The training information, some training schedule, including batch size, lr schedule, data augment and the like. +- `data info`: The data information, it usually includes the dataset name, input size and so on, such as imagenet, cifar, etc. + +### Algorithm information + +The main algorithm name to train the model. For example: + +- `simclr` +- `mocov2` +- `eva-mae-style` + +The model trained by supervised image classification can omit this field. + +### Module information + +The modules of the model, usually, the backbone must be included in this field, and the neck and head +information can be omitted. For example: + +- `resnet50` +- `vit-base-p16` +- `swin-base` + +### Pretrain information + +If the model is a fine-tuned model from a pre-trained model, we need to record some information of the +pre-trained model. For example: + +- The source of the pre-trained model: `fb`, `openai`, etc. +- The method to train the pre-trained model: `clip`, `mae`, `distill`, etc. +- The dataset used for pre-training: `in21k`, `laion2b`, etc. (`in1k` can be omitted.) +- The training duration: `300e`, `1600e`, etc. + +Not all information is necessary, only select the necessary information to distinguish different pre-trained +models. + +At the end of this field, use a `-pre` as an identifier, like `mae-in21k-pre`. + +### Training information + +Training schedule, including training type, `batch size`, `lr schedule`, data augment, special loss functions and so on: + +- format `{gpu x batch_per_gpu}`, such as `8xb32` + +Training type (mainly seen in the transformer network, such as the `ViT` algorithm, which is usually divided into two training type: pre-training and fine-tuning): + +- `ft` : configuration file for fine-tuning +- `pt` : configuration file for pretraining + +Training recipe. Usually, only the part that is different from the original paper will be marked. These methods will be arranged in the order `{pipeline aug}-{train aug}-{loss trick}-{scheduler}-{epochs}`. + +- `coslr-200e` : use cosine scheduler to train 200 epochs +- `autoaug-mixup-lbs-coslr-50e` : use `autoaug`, `mixup`, `label smooth`, `cosine scheduler` to train 50 epochs + +If the model is converted from a third-party repository like the official repository, the training information +can be omitted and use a `3rdparty` as an identifier. + +### Data information + +- `in1k` : `ImageNet1k` dataset, default to use the input image size of 224x224; +- `in21k` : `ImageNet21k` dataset, also called `ImageNet22k` dataset, default to use the input image size of 224x224; +- `in1k-384px` : Indicates that the input image size is 384x384; +- `cifar100` + +### Model Name Example + +```text +vit-base-p32_clip-openai-pre_3rdparty_in1k +``` + +- `vit-base-p32`: The module information +- `clip-openai-pre`: The pre-train information. + - `clip`: The pre-train method is clip. + - `openai`: The pre-trained model is come from OpenAI. + - `pre`: The pre-train identifier. +- `3rdparty`: The model is converted from a third-party repository. +- `in1k`: Dataset information. The model is trained from ImageNet-1k dataset and the input size is `224x224`. + +```text +beit_beit-base-p16_8xb256-amp-coslr-300e_in1k +``` + +- `beit`: The algorithm information +- `beit-base`: The module information, since the backbone is a modified ViT from BEiT, the backbone name is + also `beit`. +- `8xb256-amp-coslr-300e`: The training information. + - `8xb256`: Use 8 GPUs and the batch size on each GPU is 256. + - `amp`: Use automatic-mixed-precision training. + - `coslr`: Use cosine annealing learning rate scheduler. + - `300e`: To train 300 epochs. +- `in1k`: Dataset information. The model is trained from ImageNet-1k dataset and the input size is `224x224`. + +## Config File Naming Convention + +The naming of the config file is almost the same with the model name, with several difference: + +- The training information is necessary, and cannot be `3rdparty`. +- If the config file only includes backbone settings, without neither head settings nor dataset settings. We + will name it as `{module info}_headless.py`. This kind of config files are usually used for third-party + pre-trained models on large datasets. + +## Checkpoint Naming Convention + +The naming of the weight mainly includes the model name, date and hash value. + +```text +{model_name}_{date}-{hash}.pth +``` diff --git a/docs/en/advanced_guides/datasets.md b/docs/en/advanced_guides/datasets.md new file mode 100644 index 0000000000000000000000000000000000000000..1a018e441a1a1e820b02602dec0f85f553ec8eb0 --- /dev/null +++ b/docs/en/advanced_guides/datasets.md @@ -0,0 +1,72 @@ +# Adding New Dataset + +You can write a new dataset class inherited from `BaseDataset`, and overwrite `load_data_list(self)`, +like [CIFAR10](https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/datasets/cifar.py) and [ImageNet](https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/datasets/imagenet.py). +Typically, this function returns a list, where each sample is a dict, containing necessary data information, e.g., `img` and `gt_label`. + +Assume we are going to implement a `Filelist` dataset, which takes filelists for both training and testing. The format of annotation list is as follows: + +```text +000001.jpg 0 +000002.jpg 1 +``` + +## 1. Create Dataset Class + +We can create a new dataset in `mmpretrain/datasets/filelist.py` to load the data. + +```python +from mmpretrain.registry import DATASETS +from .base_dataset import BaseDataset + + +@DATASETS.register_module() +class Filelist(BaseDataset): + + def load_data_list(self): + assert isinstance(self.ann_file, str), + + data_list = [] + with open(self.ann_file) as f: + samples = [x.strip().split(' ') for x in f.readlines()] + for filename, gt_label in samples: + img_path = add_prefix(filename, self.img_prefix) + info = {'img_path': img_path, 'gt_label': int(gt_label)} + data_list.append(info) + return data_list +``` + +## 2. Add to the package + +And add this dataset class in `mmpretrain/datasets/__init__.py` + +```python +from .base_dataset import BaseDataset +... +from .filelist import Filelist + +__all__ = [ + 'BaseDataset', ... ,'Filelist' +] +``` + +## 3. Modify Related Config + +Then in the config, to use `Filelist` you can modify the config as the following + +```python +train_dataloader = dict( + ... + dataset=dict( + type='Filelist', + ann_file='image_list.txt', + pipeline=train_pipeline, + ) +) +``` + +All the dataset classes inherit from [`BaseDataset`](https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/datasets/base_dataset.py) have **lazy loading** and **memory saving** features, you can refer to related documents of {external+mmengine:doc}`BaseDataset| Original | ++ +```python +optimizer = dict( + type='AdamW', + lr=0.0015, + weight_decay=0.3, + paramwise_cfg = dict( + norm_decay_mult=0.0, + bias_decay_mult=0.0, + )) + +optimizer_config = dict(grad_clip=dict(max_norm=1.0)) +``` + + | +
| New | ++ +```python +optim_wrapper = dict( + optimizer=dict(type='AdamW', lr=0.0015, weight_decay=0.3), + paramwise_cfg = dict( + norm_decay_mult=0.0, + bias_decay_mult=0.0, + ), + clip_grad=dict(max_norm=1.0), +) +``` + + | +
| Original | ++ +```python +lr_config = dict( + policy='CosineAnnealing', + min_lr=0, + warmup='linear', + warmup_iters=5, + warmup_ratio=0.01, + warmup_by_epoch=True) +``` + + | +
| New | ++ +```python +param_scheduler = [ + # warmup + dict( + type='LinearLR', + start_factor=0.01, + by_epoch=True, + end=5, + # Update the learning rate after every iters. + convert_to_iter_based=True), + # main learning rate scheduler + dict(type='CosineAnnealingLR', by_epoch=True, begin=5), +] +``` + + | +
| Original | ++ +```python +runner = dict(type='EpochBasedRunner', max_epochs=100) +``` + + | +
| New | ++ +```python +# The `val_interval` is the original `evaluation.interval`. +train_cfg = dict(by_epoch=True, max_epochs=100, val_interval=1) +val_cfg = dict() # Use the default validation loop. +test_cfg = dict() # Use the default test loop. +``` + + | +
| Original | ++ +```python +log_config = dict( + interval=100, + hooks=[ + dict(type='TextLoggerHook'), + dict(type='TensorboardLoggerHook'), + ]) +``` + + | +
| New | ++ +```python +default_hooks = dict( + ... + logger=dict(type='LoggerHook', interval=100), +) + +visualizer = dict( + type='UniversalVisualizer', + vis_backends=[dict(type='LocalVisBackend'), dict(type='TensorboardVisBackend')], +) +``` + + | +
| Original | ++ +```python +model = dict( + ... + train_cfg=dict(augments=[ + dict(type='BatchMixup', alpha=0.8, num_classes=1000, prob=0.5), + dict(type='BatchCutMix', alpha=1.0, num_classes=1000, prob=0.5) + ] +) +``` + + | +
| New | ++ +```python +model = dict( + ... + train_cfg=dict(augments=[ + dict(type='Mixup', alpha=0.8), dict(type='CutMix', alpha=1.0)] +) +``` + + | +
| Original | ++ +```python +data = dict( + samples_per_gpu=32, + workers_per_gpu=2, + train=dict(...), + val=dict(...), + test=dict(...), +) +``` + + | +
| New | ++ +```python +train_dataloader = dict( + batch_size=32, + num_workers=2, + dataset=dict(...), + sampler=dict(type='DefaultSampler', shuffle=True) # necessary +) + +val_dataloader = dict( + batch_size=32, + num_workers=2, + dataset=dict(...), + sampler=dict(type='DefaultSampler', shuffle=False) # necessary +) + +test_dataloader = val_dataloader +``` + + | +
| Original | ++ +```python +img_norm_cfg = dict( + mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True) + +train_pipeline = [ + dict(type='LoadImageFromFile'), + dict(type='RandomResizedCrop', size=224), + dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'), + dict(type='Normalize', **img_norm_cfg), + dict(type='ImageToTensor', keys=['img']), + dict(type='ToTensor', keys=['gt_label']), + dict(type='Collect', keys=['img', 'gt_label']) +] +``` + + | +
| New | ++ +```python +data_preprocessor = dict( + mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True) + +train_pipeline = [ + dict(type='LoadImageFromFile'), + dict(type='RandomResizedCrop', scale=224), + dict(type='RandomFlip', prob=0.5, direction='horizontal'), + dict(type='PackInputs'), +] +``` + + | +
| Original | ++ +```python +evaluation = dict( + interval=1, + metric='accuracy', + metric_options=dict(topk=(1, 5)) +) +``` + + | +
| New | ++ +```python +val_evaluator = dict(type='Accuracy', topk=(1, 5)) +test_evaluator = val_evaluator +``` + + | +
| Original | ++ +```python +evaluation = dict( + interval=1, + metric=['mAP', 'CP', 'OP', 'CR', 'OR', 'CF1', 'OF1'], + metric_options=dict(thr=0.5), +) +``` + + | +
| New | ++ +```python +val_evaluator = [ + dict(type='AveragePrecision'), + dict(type='MultiLabelMetric', + items=['precision', 'recall', 'f1-score'], + average='both', + thr=0.5), +] +test_evaluator = val_evaluator +``` + + | +
| Original | ++ +```python +data = dict( + samples_per_gpu=32, # total 32*8(gpu)=256 + workers_per_gpu=4, + train=dict( + type=dataset_type, + data_source=dict( + type=data_source, + data_prefix='data/imagenet/train', + ann_file='data/imagenet/meta/train.txt', + ), + num_views=[1, 1], + pipelines=[train_pipeline1, train_pipeline2], + prefetch=prefetch, + ), + val=...) +``` + + | + +
| New | ++ +```python +train_dataloader = dict( + batch_size=32, + num_workers=4, + persistent_workers=True, + sampler=dict(type='DefaultSampler', shuffle=True), + collate_fn=dict(type='default_collate'), + dataset=dict( + type=dataset_type, + data_root=data_root, + ann_file='meta/train.txt', + data_prefix=dict(img_path='train/'), + pipeline=train_pipeline)) +val_dataloader = ... +``` + + | +































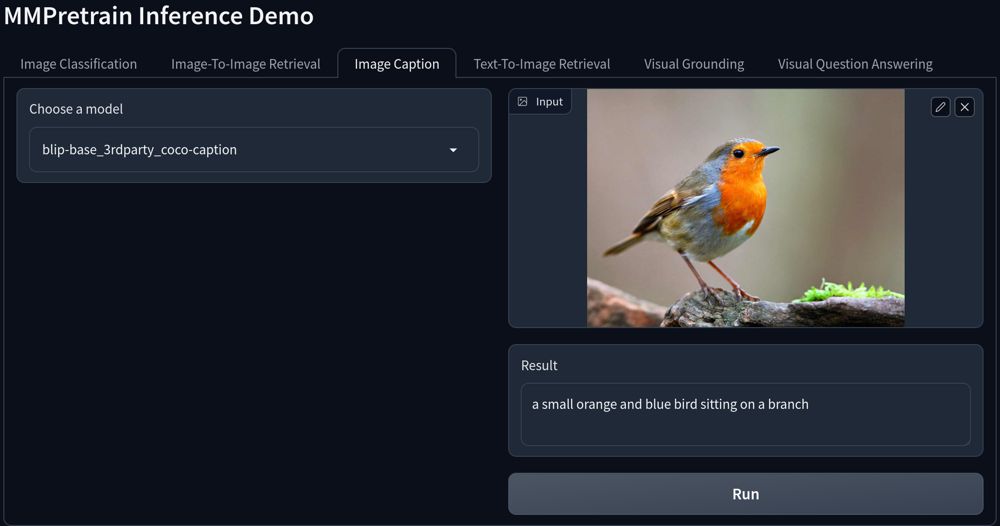 +
+## Extract Features From Image
+
+Compared with `model.extract_feat`, `FeatureExtractor` is used to extract features from the image files directly, instead of a batch of tensors.
+In a word, the input of `model.extract_feat` is `torch.Tensor`, the input of `FeatureExtractor` is images.
+
+```python
+>>> from mmpretrain import FeatureExtractor, get_model
+>>> model = get_model('resnet50_8xb32_in1k', backbone=dict(out_indices=(0, 1, 2, 3)))
+>>> extractor = FeatureExtractor(model)
+>>> features = extractor('https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG')[0]
+>>> features[0].shape, features[1].shape, features[2].shape, features[3].shape
+(torch.Size([256]), torch.Size([512]), torch.Size([1024]), torch.Size([2048]))
+```
diff --git a/docs/en/user_guides/test.md b/docs/en/user_guides/test.md
new file mode 100644
index 0000000000000000000000000000000000000000..65ec073ea96762a0e5c6c850b7bdbd3fd3e67dac
--- /dev/null
+++ b/docs/en/user_guides/test.md
@@ -0,0 +1,123 @@
+# Test
+
+For image classification task and image retrieval task, you could test your model after training.
+
+## Test with your PC
+
+You can use `tools/test.py` to test a model on a single machine with a CPU and optionally a GPU.
+
+Here is the full usage of the script:
+
+```shell
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
+```
+
+````{note}
+By default, MMPretrain prefers GPU to CPU. If you want to test a model on CPU, please empty `CUDA_VISIBLE_DEVICES` or set it to -1 to make GPU invisible to the program.
+
+```bash
+CUDA_VISIBLE_DEVICES=-1 python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
+```
+````
+
+| ARGS | Description |
+| ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | The path to the config file. |
+| `CHECKPOINT_FILE` | The path to the checkpoint file (It can be a http link, and you can find checkpoints [here](https://mmpretrain.readthedocs.io/en/latest/modelzoo_statistics.html)). |
+| `--work-dir WORK_DIR` | The directory to save the file containing evaluation metrics. |
+| `--out OUT` | The path to save the file containing test results. |
+| `--out-item OUT_ITEM` | To specify the content of the test results file, and it can be "pred" or "metrics". If "pred", save the outputs of the model for offline evaluation. If "metrics", save the evaluation metrics. Defaults to "pred". |
+| `--cfg-options CFG_OPTIONS` | Override some settings in the used config, the key-value pair in xxx=yyy format will be merged into the config file. If the value to be overwritten is a list, it should be of the form of either `key="[a,b]"` or `key=a,b`. The argument also allows nested list/tuple values, e.g. `key="[(a,b),(c,d)]"`. Note that the quotation marks are necessary and that no white space is allowed. |
+| `--show-dir SHOW_DIR` | The directory to save the result visualization images. |
+| `--show` | Visualize the prediction result in a window. |
+| `--interval INTERVAL` | The interval of samples to visualize. |
+| `--wait-time WAIT_TIME` | The display time of every window (in seconds). Defaults to 1. |
+| `--no-pin-memory` | Whether to disable the `pin_memory` option in dataloaders. |
+| `--tta` | Whether to enable the Test-Time-Aug (TTA). If the config file has `tta_pipeline` and `tta_model` fields, use them to determine the TTA transforms and how to merge the TTA results. Otherwise, use flip TTA by averaging classification score. |
+| `--launcher {none,pytorch,slurm,mpi}` | Options for job launcher. |
+
+## Test with multiple GPUs
+
+We provide a shell script to start a multi-GPUs task with `torch.distributed.launch`.
+
+```shell
+bash ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+| ARGS | Description |
+| ----------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | The path to the config file. |
+| `CHECKPOINT_FILE` | The path to the checkpoint file (It can be a http link, and you can find checkpoints [here](https://mmpretrain.readthedocs.io/en/latest/modelzoo_statistics.html)). |
+| `GPU_NUM` | The number of GPUs to be used. |
+| `[PY_ARGS]` | The other optional arguments of `tools/test.py`, see [here](#test-with-your-pc). |
+
+You can also specify extra arguments of the launcher by environment variables. For example, change the
+communication port of the launcher to 29666 by the below command:
+
+```shell
+PORT=29666 bash ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+If you want to startup multiple test jobs and use different GPUs, you can launch them by specifying
+different port and visible devices.
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_test.sh ${CONFIG_FILE1} ${CHECKPOINT_FILE} 4 [PY_ARGS]
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 bash ./tools/dist_test.sh ${CONFIG_FILE2} ${CHECKPOINT_FILE} 4 [PY_ARGS]
+```
+
+## Test with multiple machines
+
+### Multiple machines in the same network
+
+If you launch a test job with multiple machines connected with ethernet, you can run the following commands:
+
+On the first machine:
+
+```shell
+NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_test.sh $CONFIG $CHECKPOINT_FILE $GPUS
+```
+
+On the second machine:
+
+```shell
+NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_test.sh $CONFIG $CHECKPOINT_FILE $GPUS
+```
+
+Comparing with multi-GPUs in a single machine, you need to specify some extra environment variables:
+
+| ENV_VARS | Description |
+| ------------- | ---------------------------------------------------------------------------- |
+| `NNODES` | The total number of machines. |
+| `NODE_RANK` | The index of the local machine. |
+| `PORT` | The communication port, it should be the same in all machines. |
+| `MASTER_ADDR` | The IP address of the master machine, it should be the same in all machines. |
+
+Usually it is slow if you do not have high speed networking like InfiniBand.
+
+### Multiple machines managed with slurm
+
+If you run MMPretrain on a cluster managed with [slurm](https://slurm.schedmd.com/), you can use the script `tools/slurm_test.sh`.
+
+```shell
+[ENV_VARS] ./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${CHECKPOINT_FILE} [PY_ARGS]
+```
+
+Here are the arguments description of the script.
+
+| ARGS | Description |
+| ----------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `PARTITION` | The partition to use in your cluster. |
+| `JOB_NAME` | The name of your job, you can name it as you like. |
+| `CONFIG_FILE` | The path to the config file. |
+| `CHECKPOINT_FILE` | The path to the checkpoint file (It can be a http link, and you can find checkpoints [here](https://mmpretrain.readthedocs.io/en/latest/modelzoo_statistics.html)). |
+| `[PY_ARGS]` | The other optional arguments of `tools/test.py`, see [here](#test-with-your-pc). |
+
+Here are the environment variables can be used to configure the slurm job.
+
+| ENV_VARS | Description |
+| --------------- | ---------------------------------------------------------------------------------------------------------- |
+| `GPUS` | The number of GPUs to be used. Defaults to 8. |
+| `GPUS_PER_NODE` | The number of GPUs to be allocated per node. |
+| `CPUS_PER_TASK` | The number of CPUs to be allocated per task (Usually one GPU corresponds to one task). Defaults to 5. |
+| `SRUN_ARGS` | The other arguments of `srun`. Available options can be found [here](https://slurm.schedmd.com/srun.html). |
diff --git a/docs/en/user_guides/train.md b/docs/en/user_guides/train.md
new file mode 100644
index 0000000000000000000000000000000000000000..9cc618b038b4c44e46904ccca5c80731653ab1fc
--- /dev/null
+++ b/docs/en/user_guides/train.md
@@ -0,0 +1,121 @@
+# Train
+
+In this tutorial, we will introduce how to use the scripts provided in MMPretrain to start a training task. If
+you need, we also have some practice examples about [how to pretrain with custom dataset](../notes/pretrain_custom_dataset.md)
+and [how to finetune with custom dataset](../notes/finetune_custom_dataset.md).
+
+## Train with your PC
+
+You can use `tools/train.py` to train a model on a single machine with a CPU and optionally a GPU.
+
+Here is the full usage of the script:
+
+```shell
+python tools/train.py ${CONFIG_FILE} [ARGS]
+```
+
+````{note}
+By default, MMPretrain prefers GPU to CPU. If you want to train a model on CPU, please empty `CUDA_VISIBLE_DEVICES` or set it to -1 to make GPU invisible to the program.
+
+```bash
+CUDA_VISIBLE_DEVICES=-1 python tools/train.py ${CONFIG_FILE} [ARGS]
+```
+````
+
+| ARGS | Description |
+| ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | The path to the config file. |
+| `--work-dir WORK_DIR` | The target folder to save logs and checkpoints. Defaults to a folder with the same name of the config file under `./work_dirs`. |
+| `--resume [RESUME]` | Resume training. If specify a path, resume from it, while if not specify, try to auto resume from the latest checkpoint. |
+| `--amp` | Enable automatic-mixed-precision training. |
+| `--no-validate` | **Not suggested**. Disable checkpoint evaluation during training. |
+| `--auto-scale-lr` | Auto scale the learning rate according to the actual batch size and the original batch size. |
+| `--no-pin-memory` | Whether to disable the `pin_memory` option in dataloaders. |
+| `--no-persistent-workers` | Whether to disable the `persistent_workers` option in dataloaders. |
+| `--cfg-options CFG_OPTIONS` | Override some settings in the used config, the key-value pair in xxx=yyy format will be merged into the config file. If the value to be overwritten is a list, it should be of the form of either `key="[a,b]"` or `key=a,b`. The argument also allows nested list/tuple values, e.g. `key="[(a,b),(c,d)]"`. Note that the quotation marks are necessary and that no white space is allowed. |
+| `--launcher {none,pytorch,slurm,mpi}` | Options for job launcher. |
+
+## Train with multiple GPUs
+
+We provide a shell script to start a multi-GPUs task with `torch.distributed.launch`.
+
+```shell
+bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+| ARGS | Description |
+| ------------- | ---------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | The path to the config file. |
+| `GPU_NUM` | The number of GPUs to be used. |
+| `[PY_ARGS]` | The other optional arguments of `tools/train.py`, see [here](#train-with-your-pc). |
+
+You can also specify extra arguments of the launcher by environment variables. For example, change the
+communication port of the launcher to 29666 by the below command:
+
+```shell
+PORT=29666 bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+If you want to startup multiple training jobs and use different GPUs, you can launch them by specifying
+different ports and visible devices.
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_train.sh ${CONFIG_FILE1} 4 [PY_ARGS]
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 bash ./tools/dist_train.sh ${CONFIG_FILE2} 4 [PY_ARGS]
+```
+
+## Train with multiple machines
+
+### Multiple machines in the same network
+
+If you launch a training job with multiple machines connected with ethernet, you can run the following commands:
+
+On the first machine:
+
+```shell
+NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_train.sh $CONFIG $GPUS
+```
+
+On the second machine:
+
+```shell
+NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_train.sh $CONFIG $GPUS
+```
+
+Comparing with multi-GPUs in a single machine, you need to specify some extra environment variables:
+
+| ENV_VARS | Description |
+| ------------- | ---------------------------------------------------------------------------- |
+| `NNODES` | The total number of machines. |
+| `NODE_RANK` | The index of the local machine. |
+| `PORT` | The communication port, it should be the same in all machines. |
+| `MASTER_ADDR` | The IP address of the master machine, it should be the same in all machines. |
+
+Usually it is slow if you do not have high speed networking like InfiniBand.
+
+### Multiple machines managed with slurm
+
+If you run MMPretrain on a cluster managed with [slurm](https://slurm.schedmd.com/), you can use the script `tools/slurm_train.sh`.
+
+```shell
+[ENV_VARS] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR} [PY_ARGS]
+```
+
+Here are the arguments description of the script.
+
+| ARGS | Description |
+| ------------- | ---------------------------------------------------------------------------------- |
+| `PARTITION` | The partition to use in your cluster. |
+| `JOB_NAME` | The name of your job, you can name it as you like. |
+| `CONFIG_FILE` | The path to the config file. |
+| `WORK_DIR` | The target folder to save logs and checkpoints. |
+| `[PY_ARGS]` | The other optional arguments of `tools/train.py`, see [here](#train-with-your-pc). |
+
+Here are the environment variables can be used to configure the slurm job.
+
+| ENV_VARS | Description |
+| --------------- | ---------------------------------------------------------------------------------------------------------- |
+| `GPUS` | The number of GPUs to be used. Defaults to 8. |
+| `GPUS_PER_NODE` | The number of GPUs to be allocated per node.. |
+| `CPUS_PER_TASK` | The number of CPUs to be allocated per task (Usually one GPU corresponds to one task). Defaults to 5. |
+| `SRUN_ARGS` | The other arguments of `srun`. Available options can be found [here](https://slurm.schedmd.com/srun.html). |
diff --git a/docs/zh_CN/Makefile b/docs/zh_CN/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..d4bb2cbb9eddb1bb1b4f366623044af8e4830919
--- /dev/null
+++ b/docs/zh_CN/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = .
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/docs/zh_CN/_static/css/readthedocs.css b/docs/zh_CN/_static/css/readthedocs.css
new file mode 100644
index 0000000000000000000000000000000000000000..39dc689e8a97b22a48e9d6badbb729faa4335d3c
--- /dev/null
+++ b/docs/zh_CN/_static/css/readthedocs.css
@@ -0,0 +1,61 @@
+.header-logo {
+ background-image: url("../image/mmpt-logo.png");
+ background-size: 183px 50px;
+ height: 50px;
+ width: 183px;
+}
+
+@media screen and (min-width: 1100px) {
+ .header-logo {
+ top: -12px;
+ }
+}
+
+pre {
+ white-space: pre;
+}
+
+@media screen and (min-width: 2000px) {
+ .pytorch-content-left {
+ width: 1200px;
+ margin-left: 30px;
+ }
+ article.pytorch-article {
+ max-width: 1200px;
+ }
+ .pytorch-breadcrumbs-wrapper {
+ width: 1200px;
+ }
+ .pytorch-right-menu.scrolling-fixed {
+ position: fixed;
+ top: 45px;
+ left: 1580px;
+ }
+}
+
+article.pytorch-article section code {
+ padding: .2em .4em;
+ background-color: #f3f4f7;
+ border-radius: 5px;
+}
+
+/* Disable the change in tables */
+article.pytorch-article section table code {
+ padding: unset;
+ background-color: unset;
+ border-radius: unset;
+}
+
+table.autosummary td {
+ width: 50%
+}
+
+img.align-center {
+ display: block;
+ margin-left: auto;
+ margin-right: auto;
+}
+
+article.pytorch-article p.rubric {
+ font-weight: bold;
+}
diff --git a/docs/zh_CN/_static/image/confusion-matrix.png b/docs/zh_CN/_static/image/confusion-matrix.png
new file mode 120000
index 0000000000000000000000000000000000000000..7b0b377272ca60968b14e3b30e5cb8545f13534b
--- /dev/null
+++ b/docs/zh_CN/_static/image/confusion-matrix.png
@@ -0,0 +1 @@
+../../../en/_static/image/confusion-matrix.png
\ No newline at end of file
diff --git a/docs/zh_CN/_static/image/mmpt-logo.png b/docs/zh_CN/_static/image/mmpt-logo.png
new file mode 100644
index 0000000000000000000000000000000000000000..f4e060716520ece5db7e85df3c3ad8fd9e0eda57
Binary files /dev/null and b/docs/zh_CN/_static/image/mmpt-logo.png differ
diff --git a/docs/zh_CN/_static/image/tools/analysis/analyze_log.jpg b/docs/zh_CN/_static/image/tools/analysis/analyze_log.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..8eb1a27d6464d255b84b23a7460a5f622f51712f
Binary files /dev/null and b/docs/zh_CN/_static/image/tools/analysis/analyze_log.jpg differ
diff --git a/docs/zh_CN/_static/js/custom.js b/docs/zh_CN/_static/js/custom.js
new file mode 100644
index 0000000000000000000000000000000000000000..96f0679385f616f29f7d7106f0507a5f120019be
--- /dev/null
+++ b/docs/zh_CN/_static/js/custom.js
@@ -0,0 +1,20 @@
+var collapsedSections = ['进阶教程', '模型库', '可视化', '分析工具', '部署', '其他说明'];
+
+$(document).ready(function () {
+ $('.model-summary').DataTable({
+ "stateSave": false,
+ "lengthChange": false,
+ "pageLength": 20,
+ "order": [],
+ "language": {
+ "info": "显示 _START_ 至 _END_ 条目(总计 _TOTAL_ )",
+ "infoFiltered": "(筛选自 _MAX_ 条目)",
+ "search": "搜索:",
+ "zeroRecords": "没有找到任何条目",
+ "paginate": {
+ "next": "下一页",
+ "previous": "上一页"
+ },
+ }
+ });
+});
diff --git a/docs/zh_CN/_templates/404.html b/docs/zh_CN/_templates/404.html
new file mode 100644
index 0000000000000000000000000000000000000000..abf3356cf4413269b82439f28b6884fc8e51376f
--- /dev/null
+++ b/docs/zh_CN/_templates/404.html
@@ -0,0 +1,16 @@
+{% extends "layout.html" %}
+
+{% block body %}
+
+
+
+## Extract Features From Image
+
+Compared with `model.extract_feat`, `FeatureExtractor` is used to extract features from the image files directly, instead of a batch of tensors.
+In a word, the input of `model.extract_feat` is `torch.Tensor`, the input of `FeatureExtractor` is images.
+
+```python
+>>> from mmpretrain import FeatureExtractor, get_model
+>>> model = get_model('resnet50_8xb32_in1k', backbone=dict(out_indices=(0, 1, 2, 3)))
+>>> extractor = FeatureExtractor(model)
+>>> features = extractor('https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG')[0]
+>>> features[0].shape, features[1].shape, features[2].shape, features[3].shape
+(torch.Size([256]), torch.Size([512]), torch.Size([1024]), torch.Size([2048]))
+```
diff --git a/docs/en/user_guides/test.md b/docs/en/user_guides/test.md
new file mode 100644
index 0000000000000000000000000000000000000000..65ec073ea96762a0e5c6c850b7bdbd3fd3e67dac
--- /dev/null
+++ b/docs/en/user_guides/test.md
@@ -0,0 +1,123 @@
+# Test
+
+For image classification task and image retrieval task, you could test your model after training.
+
+## Test with your PC
+
+You can use `tools/test.py` to test a model on a single machine with a CPU and optionally a GPU.
+
+Here is the full usage of the script:
+
+```shell
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
+```
+
+````{note}
+By default, MMPretrain prefers GPU to CPU. If you want to test a model on CPU, please empty `CUDA_VISIBLE_DEVICES` or set it to -1 to make GPU invisible to the program.
+
+```bash
+CUDA_VISIBLE_DEVICES=-1 python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
+```
+````
+
+| ARGS | Description |
+| ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | The path to the config file. |
+| `CHECKPOINT_FILE` | The path to the checkpoint file (It can be a http link, and you can find checkpoints [here](https://mmpretrain.readthedocs.io/en/latest/modelzoo_statistics.html)). |
+| `--work-dir WORK_DIR` | The directory to save the file containing evaluation metrics. |
+| `--out OUT` | The path to save the file containing test results. |
+| `--out-item OUT_ITEM` | To specify the content of the test results file, and it can be "pred" or "metrics". If "pred", save the outputs of the model for offline evaluation. If "metrics", save the evaluation metrics. Defaults to "pred". |
+| `--cfg-options CFG_OPTIONS` | Override some settings in the used config, the key-value pair in xxx=yyy format will be merged into the config file. If the value to be overwritten is a list, it should be of the form of either `key="[a,b]"` or `key=a,b`. The argument also allows nested list/tuple values, e.g. `key="[(a,b),(c,d)]"`. Note that the quotation marks are necessary and that no white space is allowed. |
+| `--show-dir SHOW_DIR` | The directory to save the result visualization images. |
+| `--show` | Visualize the prediction result in a window. |
+| `--interval INTERVAL` | The interval of samples to visualize. |
+| `--wait-time WAIT_TIME` | The display time of every window (in seconds). Defaults to 1. |
+| `--no-pin-memory` | Whether to disable the `pin_memory` option in dataloaders. |
+| `--tta` | Whether to enable the Test-Time-Aug (TTA). If the config file has `tta_pipeline` and `tta_model` fields, use them to determine the TTA transforms and how to merge the TTA results. Otherwise, use flip TTA by averaging classification score. |
+| `--launcher {none,pytorch,slurm,mpi}` | Options for job launcher. |
+
+## Test with multiple GPUs
+
+We provide a shell script to start a multi-GPUs task with `torch.distributed.launch`.
+
+```shell
+bash ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+| ARGS | Description |
+| ----------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | The path to the config file. |
+| `CHECKPOINT_FILE` | The path to the checkpoint file (It can be a http link, and you can find checkpoints [here](https://mmpretrain.readthedocs.io/en/latest/modelzoo_statistics.html)). |
+| `GPU_NUM` | The number of GPUs to be used. |
+| `[PY_ARGS]` | The other optional arguments of `tools/test.py`, see [here](#test-with-your-pc). |
+
+You can also specify extra arguments of the launcher by environment variables. For example, change the
+communication port of the launcher to 29666 by the below command:
+
+```shell
+PORT=29666 bash ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+If you want to startup multiple test jobs and use different GPUs, you can launch them by specifying
+different port and visible devices.
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_test.sh ${CONFIG_FILE1} ${CHECKPOINT_FILE} 4 [PY_ARGS]
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 bash ./tools/dist_test.sh ${CONFIG_FILE2} ${CHECKPOINT_FILE} 4 [PY_ARGS]
+```
+
+## Test with multiple machines
+
+### Multiple machines in the same network
+
+If you launch a test job with multiple machines connected with ethernet, you can run the following commands:
+
+On the first machine:
+
+```shell
+NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_test.sh $CONFIG $CHECKPOINT_FILE $GPUS
+```
+
+On the second machine:
+
+```shell
+NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_test.sh $CONFIG $CHECKPOINT_FILE $GPUS
+```
+
+Comparing with multi-GPUs in a single machine, you need to specify some extra environment variables:
+
+| ENV_VARS | Description |
+| ------------- | ---------------------------------------------------------------------------- |
+| `NNODES` | The total number of machines. |
+| `NODE_RANK` | The index of the local machine. |
+| `PORT` | The communication port, it should be the same in all machines. |
+| `MASTER_ADDR` | The IP address of the master machine, it should be the same in all machines. |
+
+Usually it is slow if you do not have high speed networking like InfiniBand.
+
+### Multiple machines managed with slurm
+
+If you run MMPretrain on a cluster managed with [slurm](https://slurm.schedmd.com/), you can use the script `tools/slurm_test.sh`.
+
+```shell
+[ENV_VARS] ./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${CHECKPOINT_FILE} [PY_ARGS]
+```
+
+Here are the arguments description of the script.
+
+| ARGS | Description |
+| ----------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `PARTITION` | The partition to use in your cluster. |
+| `JOB_NAME` | The name of your job, you can name it as you like. |
+| `CONFIG_FILE` | The path to the config file. |
+| `CHECKPOINT_FILE` | The path to the checkpoint file (It can be a http link, and you can find checkpoints [here](https://mmpretrain.readthedocs.io/en/latest/modelzoo_statistics.html)). |
+| `[PY_ARGS]` | The other optional arguments of `tools/test.py`, see [here](#test-with-your-pc). |
+
+Here are the environment variables can be used to configure the slurm job.
+
+| ENV_VARS | Description |
+| --------------- | ---------------------------------------------------------------------------------------------------------- |
+| `GPUS` | The number of GPUs to be used. Defaults to 8. |
+| `GPUS_PER_NODE` | The number of GPUs to be allocated per node. |
+| `CPUS_PER_TASK` | The number of CPUs to be allocated per task (Usually one GPU corresponds to one task). Defaults to 5. |
+| `SRUN_ARGS` | The other arguments of `srun`. Available options can be found [here](https://slurm.schedmd.com/srun.html). |
diff --git a/docs/en/user_guides/train.md b/docs/en/user_guides/train.md
new file mode 100644
index 0000000000000000000000000000000000000000..9cc618b038b4c44e46904ccca5c80731653ab1fc
--- /dev/null
+++ b/docs/en/user_guides/train.md
@@ -0,0 +1,121 @@
+# Train
+
+In this tutorial, we will introduce how to use the scripts provided in MMPretrain to start a training task. If
+you need, we also have some practice examples about [how to pretrain with custom dataset](../notes/pretrain_custom_dataset.md)
+and [how to finetune with custom dataset](../notes/finetune_custom_dataset.md).
+
+## Train with your PC
+
+You can use `tools/train.py` to train a model on a single machine with a CPU and optionally a GPU.
+
+Here is the full usage of the script:
+
+```shell
+python tools/train.py ${CONFIG_FILE} [ARGS]
+```
+
+````{note}
+By default, MMPretrain prefers GPU to CPU. If you want to train a model on CPU, please empty `CUDA_VISIBLE_DEVICES` or set it to -1 to make GPU invisible to the program.
+
+```bash
+CUDA_VISIBLE_DEVICES=-1 python tools/train.py ${CONFIG_FILE} [ARGS]
+```
+````
+
+| ARGS | Description |
+| ------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | The path to the config file. |
+| `--work-dir WORK_DIR` | The target folder to save logs and checkpoints. Defaults to a folder with the same name of the config file under `./work_dirs`. |
+| `--resume [RESUME]` | Resume training. If specify a path, resume from it, while if not specify, try to auto resume from the latest checkpoint. |
+| `--amp` | Enable automatic-mixed-precision training. |
+| `--no-validate` | **Not suggested**. Disable checkpoint evaluation during training. |
+| `--auto-scale-lr` | Auto scale the learning rate according to the actual batch size and the original batch size. |
+| `--no-pin-memory` | Whether to disable the `pin_memory` option in dataloaders. |
+| `--no-persistent-workers` | Whether to disable the `persistent_workers` option in dataloaders. |
+| `--cfg-options CFG_OPTIONS` | Override some settings in the used config, the key-value pair in xxx=yyy format will be merged into the config file. If the value to be overwritten is a list, it should be of the form of either `key="[a,b]"` or `key=a,b`. The argument also allows nested list/tuple values, e.g. `key="[(a,b),(c,d)]"`. Note that the quotation marks are necessary and that no white space is allowed. |
+| `--launcher {none,pytorch,slurm,mpi}` | Options for job launcher. |
+
+## Train with multiple GPUs
+
+We provide a shell script to start a multi-GPUs task with `torch.distributed.launch`.
+
+```shell
+bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+| ARGS | Description |
+| ------------- | ---------------------------------------------------------------------------------- |
+| `CONFIG_FILE` | The path to the config file. |
+| `GPU_NUM` | The number of GPUs to be used. |
+| `[PY_ARGS]` | The other optional arguments of `tools/train.py`, see [here](#train-with-your-pc). |
+
+You can also specify extra arguments of the launcher by environment variables. For example, change the
+communication port of the launcher to 29666 by the below command:
+
+```shell
+PORT=29666 bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+If you want to startup multiple training jobs and use different GPUs, you can launch them by specifying
+different ports and visible devices.
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_train.sh ${CONFIG_FILE1} 4 [PY_ARGS]
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 bash ./tools/dist_train.sh ${CONFIG_FILE2} 4 [PY_ARGS]
+```
+
+## Train with multiple machines
+
+### Multiple machines in the same network
+
+If you launch a training job with multiple machines connected with ethernet, you can run the following commands:
+
+On the first machine:
+
+```shell
+NNODES=2 NODE_RANK=0 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_train.sh $CONFIG $GPUS
+```
+
+On the second machine:
+
+```shell
+NNODES=2 NODE_RANK=1 PORT=$MASTER_PORT MASTER_ADDR=$MASTER_ADDR bash tools/dist_train.sh $CONFIG $GPUS
+```
+
+Comparing with multi-GPUs in a single machine, you need to specify some extra environment variables:
+
+| ENV_VARS | Description |
+| ------------- | ---------------------------------------------------------------------------- |
+| `NNODES` | The total number of machines. |
+| `NODE_RANK` | The index of the local machine. |
+| `PORT` | The communication port, it should be the same in all machines. |
+| `MASTER_ADDR` | The IP address of the master machine, it should be the same in all machines. |
+
+Usually it is slow if you do not have high speed networking like InfiniBand.
+
+### Multiple machines managed with slurm
+
+If you run MMPretrain on a cluster managed with [slurm](https://slurm.schedmd.com/), you can use the script `tools/slurm_train.sh`.
+
+```shell
+[ENV_VARS] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR} [PY_ARGS]
+```
+
+Here are the arguments description of the script.
+
+| ARGS | Description |
+| ------------- | ---------------------------------------------------------------------------------- |
+| `PARTITION` | The partition to use in your cluster. |
+| `JOB_NAME` | The name of your job, you can name it as you like. |
+| `CONFIG_FILE` | The path to the config file. |
+| `WORK_DIR` | The target folder to save logs and checkpoints. |
+| `[PY_ARGS]` | The other optional arguments of `tools/train.py`, see [here](#train-with-your-pc). |
+
+Here are the environment variables can be used to configure the slurm job.
+
+| ENV_VARS | Description |
+| --------------- | ---------------------------------------------------------------------------------------------------------- |
+| `GPUS` | The number of GPUs to be used. Defaults to 8. |
+| `GPUS_PER_NODE` | The number of GPUs to be allocated per node.. |
+| `CPUS_PER_TASK` | The number of CPUs to be allocated per task (Usually one GPU corresponds to one task). Defaults to 5. |
+| `SRUN_ARGS` | The other arguments of `srun`. Available options can be found [here](https://slurm.schedmd.com/srun.html). |
diff --git a/docs/zh_CN/Makefile b/docs/zh_CN/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..d4bb2cbb9eddb1bb1b4f366623044af8e4830919
--- /dev/null
+++ b/docs/zh_CN/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = .
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/docs/zh_CN/_static/css/readthedocs.css b/docs/zh_CN/_static/css/readthedocs.css
new file mode 100644
index 0000000000000000000000000000000000000000..39dc689e8a97b22a48e9d6badbb729faa4335d3c
--- /dev/null
+++ b/docs/zh_CN/_static/css/readthedocs.css
@@ -0,0 +1,61 @@
+.header-logo {
+ background-image: url("../image/mmpt-logo.png");
+ background-size: 183px 50px;
+ height: 50px;
+ width: 183px;
+}
+
+@media screen and (min-width: 1100px) {
+ .header-logo {
+ top: -12px;
+ }
+}
+
+pre {
+ white-space: pre;
+}
+
+@media screen and (min-width: 2000px) {
+ .pytorch-content-left {
+ width: 1200px;
+ margin-left: 30px;
+ }
+ article.pytorch-article {
+ max-width: 1200px;
+ }
+ .pytorch-breadcrumbs-wrapper {
+ width: 1200px;
+ }
+ .pytorch-right-menu.scrolling-fixed {
+ position: fixed;
+ top: 45px;
+ left: 1580px;
+ }
+}
+
+article.pytorch-article section code {
+ padding: .2em .4em;
+ background-color: #f3f4f7;
+ border-radius: 5px;
+}
+
+/* Disable the change in tables */
+article.pytorch-article section table code {
+ padding: unset;
+ background-color: unset;
+ border-radius: unset;
+}
+
+table.autosummary td {
+ width: 50%
+}
+
+img.align-center {
+ display: block;
+ margin-left: auto;
+ margin-right: auto;
+}
+
+article.pytorch-article p.rubric {
+ font-weight: bold;
+}
diff --git a/docs/zh_CN/_static/image/confusion-matrix.png b/docs/zh_CN/_static/image/confusion-matrix.png
new file mode 120000
index 0000000000000000000000000000000000000000..7b0b377272ca60968b14e3b30e5cb8545f13534b
--- /dev/null
+++ b/docs/zh_CN/_static/image/confusion-matrix.png
@@ -0,0 +1 @@
+../../../en/_static/image/confusion-matrix.png
\ No newline at end of file
diff --git a/docs/zh_CN/_static/image/mmpt-logo.png b/docs/zh_CN/_static/image/mmpt-logo.png
new file mode 100644
index 0000000000000000000000000000000000000000..f4e060716520ece5db7e85df3c3ad8fd9e0eda57
Binary files /dev/null and b/docs/zh_CN/_static/image/mmpt-logo.png differ
diff --git a/docs/zh_CN/_static/image/tools/analysis/analyze_log.jpg b/docs/zh_CN/_static/image/tools/analysis/analyze_log.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..8eb1a27d6464d255b84b23a7460a5f622f51712f
Binary files /dev/null and b/docs/zh_CN/_static/image/tools/analysis/analyze_log.jpg differ
diff --git a/docs/zh_CN/_static/js/custom.js b/docs/zh_CN/_static/js/custom.js
new file mode 100644
index 0000000000000000000000000000000000000000..96f0679385f616f29f7d7106f0507a5f120019be
--- /dev/null
+++ b/docs/zh_CN/_static/js/custom.js
@@ -0,0 +1,20 @@
+var collapsedSections = ['进阶教程', '模型库', '可视化', '分析工具', '部署', '其他说明'];
+
+$(document).ready(function () {
+ $('.model-summary').DataTable({
+ "stateSave": false,
+ "lengthChange": false,
+ "pageLength": 20,
+ "order": [],
+ "language": {
+ "info": "显示 _START_ 至 _END_ 条目(总计 _TOTAL_ )",
+ "infoFiltered": "(筛选自 _MAX_ 条目)",
+ "search": "搜索:",
+ "zeroRecords": "没有找到任何条目",
+ "paginate": {
+ "next": "下一页",
+ "previous": "上一页"
+ },
+ }
+ });
+});
diff --git a/docs/zh_CN/_templates/404.html b/docs/zh_CN/_templates/404.html
new file mode 100644
index 0000000000000000000000000000000000000000..abf3356cf4413269b82439f28b6884fc8e51376f
--- /dev/null
+++ b/docs/zh_CN/_templates/404.html
@@ -0,0 +1,16 @@
+{% extends "layout.html" %}
+
+{% block body %}
+
++ 未找到你要打开的页面。 +
++ 如果你是从旧版本文档跳转至此,可能是对应的页面被移动了。请从左侧的目录中寻找新版本文档,或者跳转至首页。 +
++ 如果你找不到希望打开的文档,欢迎在 Issue 中告诉我们! +
+ +{% endblock %} diff --git a/docs/zh_CN/_templates/autosummary/class.rst b/docs/zh_CN/_templates/autosummary/class.rst new file mode 100644 index 0000000000000000000000000000000000000000..4c3a7a9abf5c5b14ac3ef3b00a2f070480295358 --- /dev/null +++ b/docs/zh_CN/_templates/autosummary/class.rst @@ -0,0 +1,13 @@ +.. role:: hidden + :class: hidden-section +.. currentmodule:: {{ module }} + + +{{ name | underline}} + +.. autoclass:: {{ name }} + :members: + +.. + autogenerated from _templates/autosummary/class.rst + note it does not have :inherited-members: diff --git a/docs/zh_CN/_templates/callable.rst b/docs/zh_CN/_templates/callable.rst new file mode 100644 index 0000000000000000000000000000000000000000..3a7b9d2b96c76dfa3eb1d8bef56f58f219fe7760 --- /dev/null +++ b/docs/zh_CN/_templates/callable.rst @@ -0,0 +1,14 @@ +.. role:: hidden + :class: hidden-section +.. currentmodule:: {{ module }} + + +{{ name | underline}} + +.. autoclass:: {{ name }} + :members: + :special-members: __call__ + +.. + autogenerated from _templates/callable.rst + note it does not have :inherited-members: diff --git a/docs/zh_CN/_templates/data_transform.rst b/docs/zh_CN/_templates/data_transform.rst new file mode 100644 index 0000000000000000000000000000000000000000..376bfe9db6c305e681f265dd0e20b7b7ea6e500f --- /dev/null +++ b/docs/zh_CN/_templates/data_transform.rst @@ -0,0 +1,13 @@ +.. role:: hidden + :class: hidden-section +.. currentmodule:: {{ module }} + + +{{ name | underline}} + +.. autoclass:: {{ name }} + :members: transform + +.. + autogenerated from _templates/callable.rst + note it does not have :inherited-members: diff --git a/docs/zh_CN/advanced_guides/convention.md b/docs/zh_CN/advanced_guides/convention.md new file mode 100644 index 0000000000000000000000000000000000000000..941236b698bf0861d1547227c7671c76a59e3075 --- /dev/null +++ b/docs/zh_CN/advanced_guides/convention.md @@ -0,0 +1,114 @@ +# MMPretrain 中的约定 + +## 模型命名规则 + +MMPretrain 按照以下风格进行模型命名,代码库的贡献者需要遵循相同的命名规则。模型名总体分为五个部分:算法信息,模块信息,预训练信息,训练信息和数据信息。逻辑上属于不同部分的单词之间用下划线 `'_'` 连接,同一部分有多个单词用短横线 `'-'` 连接。 + +```text +{algorithm info}_{module info}_{pretrain info}_{training info}_{data info} +``` + +- `algorithm info`(可选):算法信息,表示用以训练该模型的主要算法,如 MAE、BEiT 等 +- `module info`:模块信息,主要包含模型的主干网络名称,如 resnet、vit 等 +- `pretrain info`(可选):预训练信息,比如预训练模型是在 ImageNet-21k 数据集上训练的等 +- `training info`:训练信息,训练策略设置,包括 batch size,schedule 以及数据增强等; +- `data info`:数据信息,数据集名称、模态、输入尺寸等,如 imagenet, cifar 等; + +### 算法信息 + +指用以训练该模型的算法名称,例如: + +- `simclr` +- `mocov2` +- `eva-mae-style` + +使用监督图像分类任务训练的模型可以省略这个字段。 + +### 模块信息 + +指模型的结构信息,一般主要包含模型的主干网络结构,`neck` 和 `head` 信息一般被省略。例如: + +- `resnet50` +- `vit-base-p16` +- `swin-base` + +### 预训练信息 + +如果该模型是在预训练模型基础上,通过微调获得的,我们需要记录预训练模型的一些信息。例如: + +- 预训练模型的来源:`fb`、`openai`等。 +- 训练预训练模型的方法:`clip`、`mae`、`distill` 等。 +- 用于预训练的数据集:`in21k`、`laion2b`等(`in1k`可以省略) +- 训练时长:`300e`、`1600e` 等。 + +并非所有信息都是必要的,只需要选择用以区分不同的预训练模型的信息即可。 + +在此字段的末尾,使用 `-pre` 作为标识符,例如 `mae-in21k-pre`。 + +### 训练信息 + +训练策略的一些设置,包括训练类型、 `batch size`、 `lr schedule`、 数据增强以及特殊的损失函数等等,比如: +Batch size 信息: + +- 格式为`{gpu x batch_per_gpu}`, 如 `8xb32` + +训练类型(主要见于 transformer 网络,如 `ViT` 算法,这类算法通常分为预训练和微调两种模式): + +- `ft` : Finetune config,用于微调的配置文件 +- `pt` : Pretrain config,用于预训练的配置文件 + +训练策略信息,训练策略以复现配置文件为基础,此基础不必标注训练策略。但如果在此基础上进行改进,则需注明训练策略,按照应用点位顺序排列,如:`{pipeline aug}-{train aug}-{loss trick}-{scheduler}-{epochs}` + +- `coslr-200e` : 使用 cosine scheduler, 训练 200 个 epoch +- `autoaug-mixup-lbs-coslr-50e` : 使用了 `autoaug`、`mixup`、`label smooth`、`cosine scheduler`, 训练了 50 个轮次 + +如果模型是从官方仓库等第三方仓库转换过来的,训练信息可以省略,使用 `3rdparty` 作为标识符。 + +### 数据信息 + +- `in1k` : `ImageNet1k` 数据集,默认使用 `224x224` 大小的图片 +- `in21k` : `ImageNet21k` 数据集,有些地方也称为 `ImageNet22k` 数据集,默认使用 `224x224` 大小的图片 +- `in1k-384px` : 表示训练的输出图片大小为 `384x384` +- `cifar100` + +### 模型命名案例 + +```text +vit-base-p32_clip-openai-pre_3rdparty_in1k +``` + +- `vit-base-p32`: 模块信息 +- `clip-openai-pre`:预训练信息 + - `clip`:预训练方法是 clip + - `openai`:预训练模型来自 OpenAI + - `pre`:预训练标识符 +- `3rdparty`:模型是从第三方仓库转换而来的 +- `in1k`:数据集信息。该模型是从 ImageNet-1k 数据集训练而来的,输入大小为 `224x224` + +```text +beit_beit-base-p16_8xb256-amp-coslr-300e_in1k +``` + +- `beit`: 算法信息 +- `beit-base`:模块信息,由于主干网络来自 BEiT 中提出的修改版 ViT,主干网络名称也是 `beit` +- `8xb256-amp-coslr-300e`:训练信息 + - `8xb256`:使用 8 个 GPU,每个 GPU 的批量大小为 256 + - `amp`:使用自动混合精度训练 + - `coslr`:使用余弦退火学习率调度器 + - `300e`:训练 300 个 epoch +- `in1k`:数据集信息。该模型是从 ImageNet-1k 数据集训练而来的,输入大小为 `224x224` + +## 配置文件命名规则 + +配置文件的命名与模型名称几乎相同,有几点不同: + +- 训练信息是必要的,不能是 `3rdparty` +- 如果配置文件只包含主干网络设置,既没有头部设置也没有数据集设置,我们将其命名为`{module info}_headless.py`。这种配置文件通常用于大型数据集上的第三方预训练模型。 + +### 权重命名规则 + +权重的命名主要包括模型名称,日期和哈希值。 + +```text +{model_name}_{date}-{hash}.pth +``` diff --git a/docs/zh_CN/advanced_guides/datasets.md b/docs/zh_CN/advanced_guides/datasets.md new file mode 100644 index 0000000000000000000000000000000000000000..83b7959b9f136e0938c89fe6f171f33c2eedde35 --- /dev/null +++ b/docs/zh_CN/advanced_guides/datasets.md @@ -0,0 +1,73 @@ +# 添加新数据集 + +用户可以编写一个继承自 [BasesDataset](https://mmpretrain.readthedocs.io/zh_CN/latest/_modules/mmpretrain/datasets/base_dataset.html#BaseDataset) 的新数据集类,并重载 `load_data_list(self)` 方法,类似 [CIFAR10](https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/datasets/cifar.py) 和 [ImageNet](https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/datasets/imagenet.py)。 + +通常,此方法返回一个包含所有样本的列表,其中的每个样本都是一个字典。字典中包含了必要的数据信息,例如 `img` 和 `gt_label`。 + +假设我们将要实现一个 `Filelist` 数据集,该数据集将使用文件列表进行训练和测试。注释列表的格式如下: + +```text +000001.jpg 0 +000002.jpg 1 +... +``` + +## 1. 创建数据集类 + +我们可以在 `mmpretrain/datasets/filelist.py` 中创建一个新的数据集类以加载数据。 + +```python +from mmpretrain.registry import DATASETS +from .base_dataset import BaseDataset + + +@DATASETS.register_module() +class Filelist(BaseDataset): + + def load_data_list(self): + assert isinstance(self.ann_file, str) + + data_list = [] + with open(self.ann_file) as f: + samples = [x.strip().split(' ') for x in f.readlines()] + for filename, gt_label in samples: + img_path = add_prefix(filename, self.img_prefix) + info = {'img_path': img_path, 'gt_label': int(gt_label)} + data_list.append(info) + return data_list +``` + +## 2. 添加到库 + +将新的数据集类加入到 `mmpretrain/datasets/__init__.py` 中: + +```python +from .base_dataset import BaseDataset +... +from .filelist import Filelist + +__all__ = [ + 'BaseDataset', ... ,'Filelist' +] +``` + +### 3. 修改相关配置文件 + +然后在配置文件中,为了使用 `Filelist`,用户可以按以下方式修改配置 + +```python +train_dataloader = dict( + ... + dataset=dict( + type='Filelist', + ann_file='image_list.txt', + pipeline=train_pipeline, + ) +) +``` + +所有继承 [`BaseDataset`](https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/datasets/base_dataset.py) 的数据集类都具有**懒加载**以及**节省内存**的特性,可以参考相关文档 {external+mmengine:doc}`BaseDataset
 +
+ 



