
update
Showing
Too many changes to show.
To preserve performance only 288 of 288+ files are displayed.
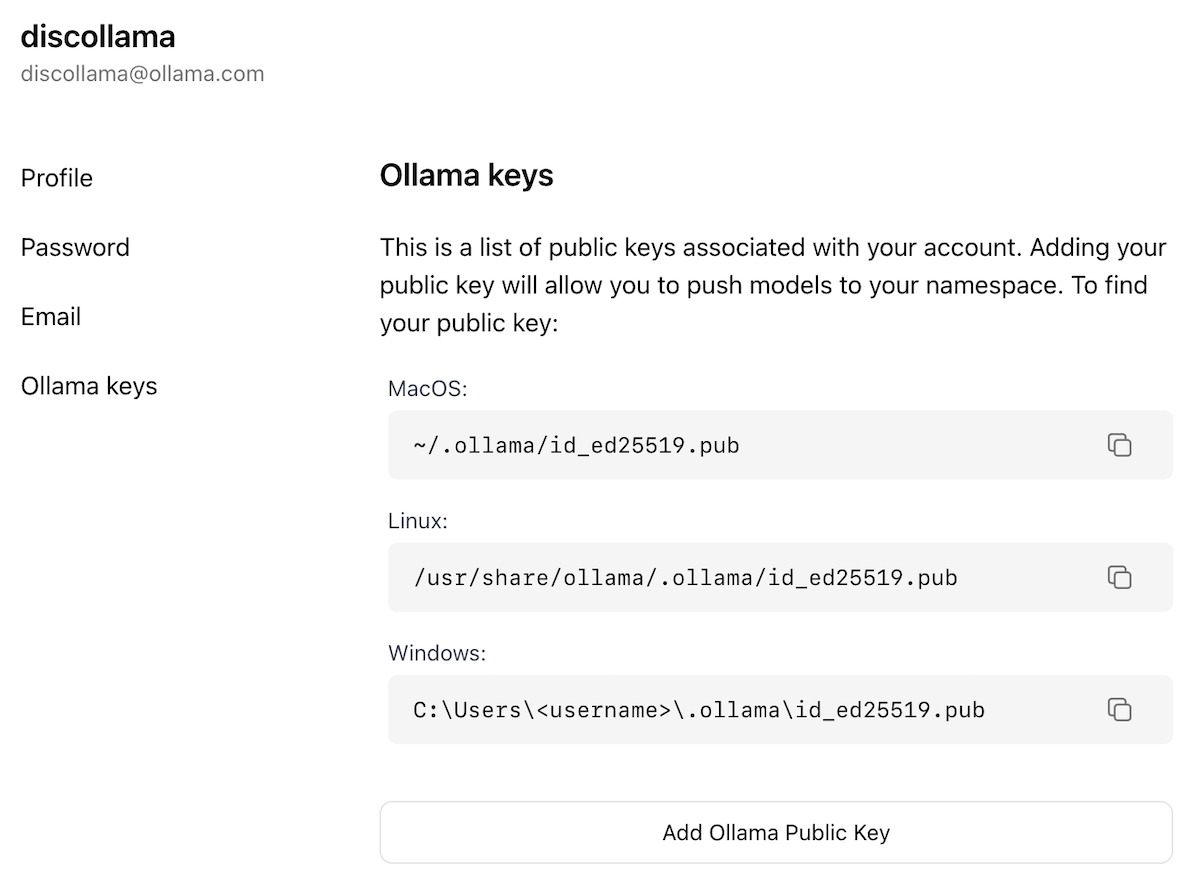
docs/images/ollama-keys.png
0 → 100644
{kind=link}
150 KB
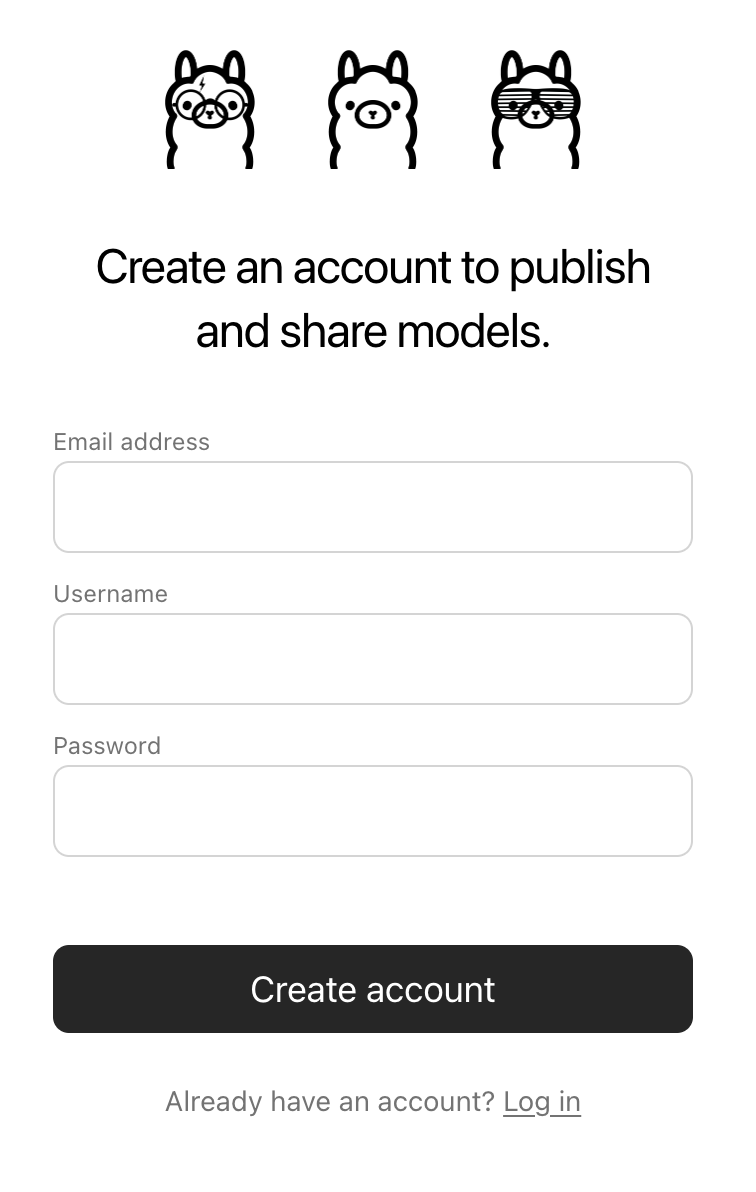
docs/images/signup.png
0 → 100644
{kind=link}
79.5 KB
150 KB
79.5 KB