# Yuan2.0-M32
## 论文
`Yuan 2.0-M32: Mixture of Experts with Attention Router`
- https://arxiv.org/abs/2405.17976
## 模型结构
浪潮信息 **“源2.0 M32”大模型(简称,Yuan2.0-M32)** 采用稀疏混合专家架构(MoE),以Yuan2.0-2B模型作为基底模型,通过创新的门控网络(Attention Router)实现32个专家间(Experts*32)的协同工作与任务调度,在显著降低模型推理算力需求的情况下,带来了更强的模型精度表现与推理性能;源2.0-M32在多个业界主流的评测进行了代码生成、数学问题求解、科学问答与综合知识能力等方面的能力测评。结果显示,源2.0-M32在多项任务评测中,展示出了较为先进的能力表现,MATH(数学求解)、ARC-C(科学问答)测试精度超过LLaMA3-700亿模型。**Yuan2.0-M32大模型** 基本信息如下:
+ **模型参数量:** 40B
+ **专家数量:** 32
+ **激活专家数:** 2
+ **激活参数量:** 3.7B
+ **训练数据量:** 2000B tokens
+ **支持序列长度:** 16K
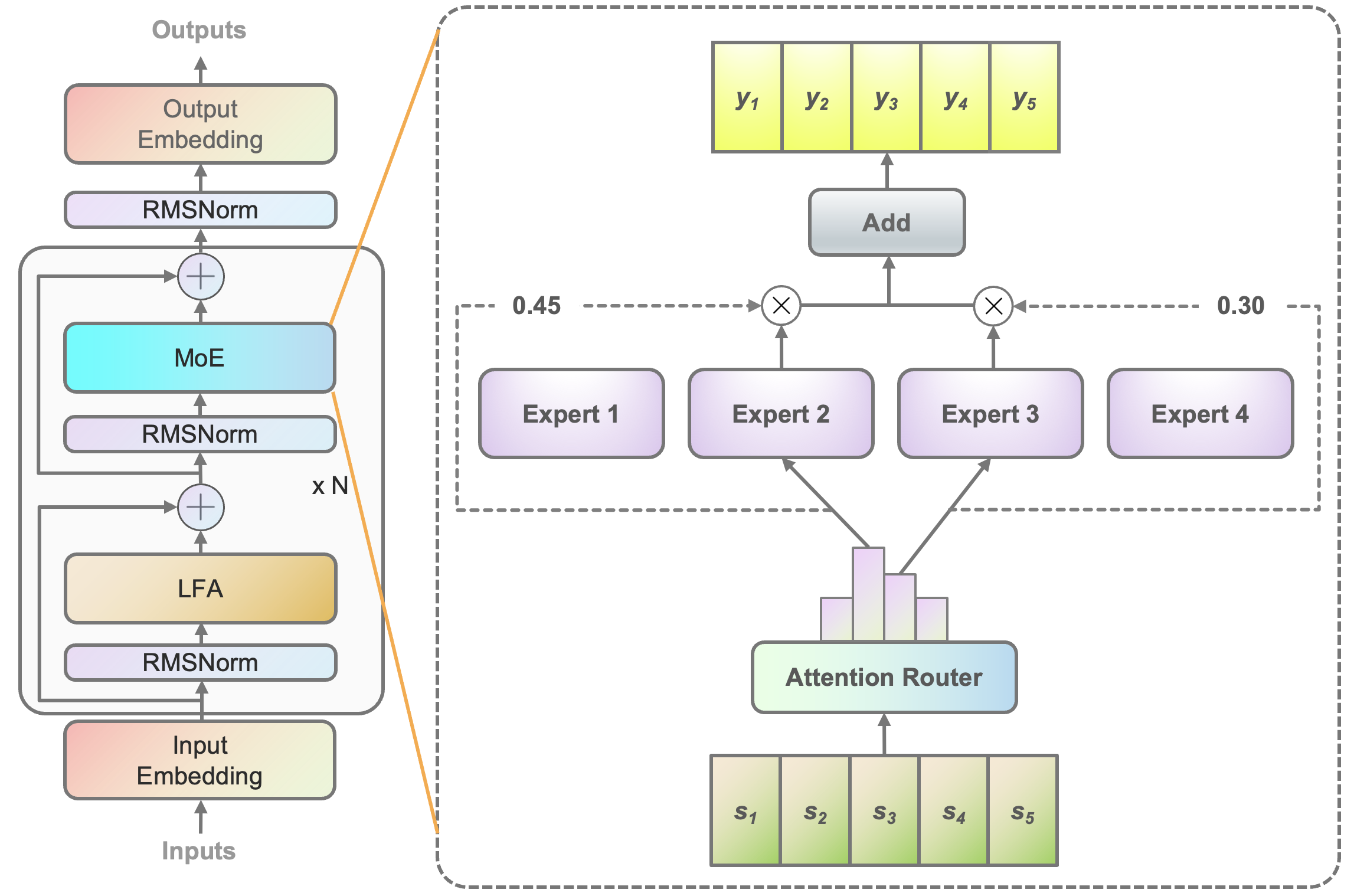
Fig.1: Yuan 2.0-M32 架构图
## 算法原理
下图左边展示了Yuan2.0架构的MoE层缩放图,在Yuan 2.0中,MoE层取代了前馈层。下图右边展示了MOE层的结构。在Yuan2.0模型中,每个输入token将分配给32个专家中的2个(而在图中,这里以4个专家为例),MOE的输出是选定专家的加权总和,N是层数。
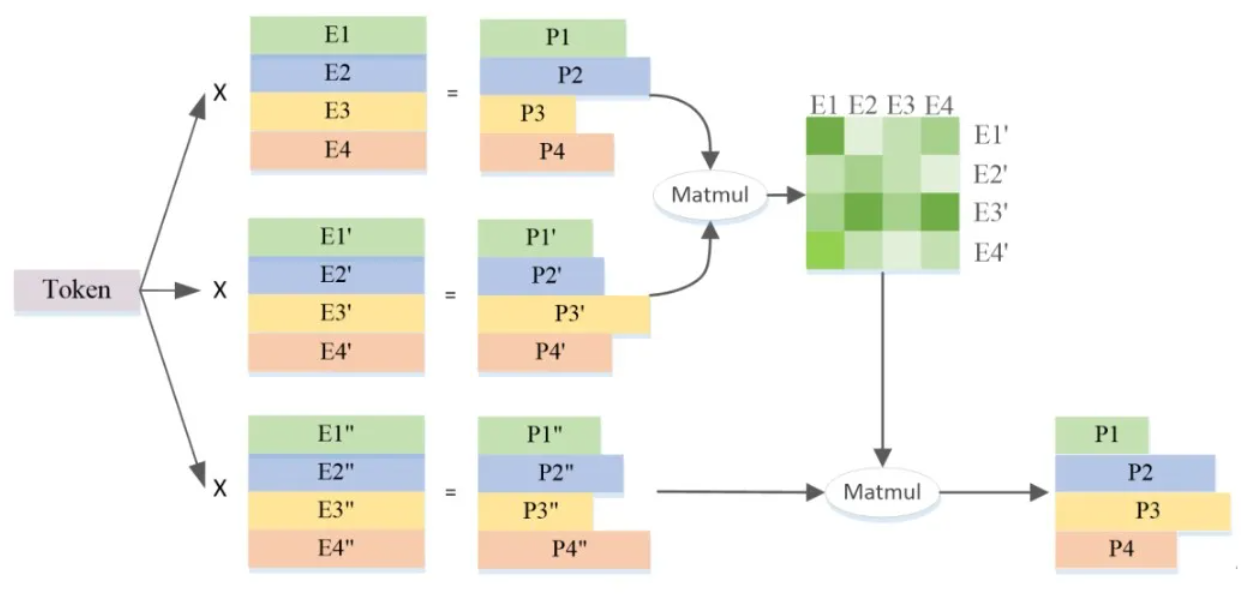
Fig.2: Attention Router
## 环境配置
-v 路径、docker_name和imageID根据实际情况修改
### Docker(方法一)
```bash
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run -it --network=host --privileged=true --name=docker_name --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=32G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro imageID /bin/bash
cd /your_code_path/yuan2.0-m32_pytorch
pip install -r requirements.txt
```
### Dockerfile(方法二)
```bash
cd ./docker
docker build --no-cache -t yuan2.0-m32:latest .
docker run -it --network=host --privileged=true --name=docker_name --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=32G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro imageID /bin/bash
cd /your_code_path/yuan2.0-m32_pytorch
pip install -r requirements.txt
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
```bash
DTK软件栈:dtk24.04.1
python:python3.10
torch:2.1
apex: 1.1.0+0dd7f68.abi0.dtk2404.torch2.1
deepspeed: 0.12.3+gita724046.abi0.dtk2404.torch2.1.0
```
Tips:以上dtk软件栈、python、torch等DCU相关工具版本需要严格一一对应
2、其他非特殊库直接按照下面步骤进行安装
```bash
pip install apex-1.1.0+das1.0+0dd7f68.abi0.dtk2404.torch2.1-cp310-cp310-manylinux2014_x86_64.whl
pip install deepspeed-0.12.3+das1.0+gita724046.abi0.dtk2404.torch2.1.0-cp310-cp310-manylinux2014_x86_64.whl
pip install -r requirements.txt
```
## 数据集
### 准备数据集
在训练之前,需要将文本语料库转换为token id并存储在二进制文件中。
1. 数据集中的样本用'\n'分隔,每个样本内的'\n'用'\'代替(程序会在预处理过程中将'\'替换回'\n'),数据集中的每一行都是一个样本;对于用于调优Yuan2.0的数据集,在 `instruction` 和 `response` 之间放一个'\'作为分隔符。下面是一个finetune数据集的示例:
```text
John买了3件衬衫,每件售价为20美元。此外,他还需要支付所有商品的10%税款。他总共支付了多少钱?John购买的3件衬衫的总价为3 \times 20 = 60美元。所有商品的税款为总价的10%,即60 \times 0.1 = 6美元。因此,John总共支付的钱数为60 + 6 = 66美元。
每年,Dani作为赢得亚马逊季度最佳买家的奖励,会得到4个一对裤子(每对裤子2条)。如果初始时他有50条裤子,计算出5年后他将拥有多少条裤子。每年Dani会得到4 \times 2 = 8条裤子,因此5年后他将得到8 \times 5 = 40条裤子。那么,5年后他总共拥有的裤子数量为初始时的50条加上5年内得到的40条,即50 + 40 = 90条裤子。因此,5年后他将拥有90条裤子。
```
2. 数据预处理的脚本[preprocess_data.py](./tools/preprocess_data.py),代码中的主要变量设置如下:
| 变量名 | 描述 |
| ------------------ | ------------------ |
| `--input` | 存储训练数据集的文件夹路径,数据集应该存储在`.txt`文件中。注意:即使只有一个`.txt`文件需要处理,路径应该是存放.txt文件的地方(即文件夹),而不是`.txt`文件的路径。|
| `--data-idx` | 这为训练数据集设置了索引。如果只有一个数据集要转换,那么`--data-idx`参数应该设置为'0'。如果有多个训练数据集,设为'0-n',其中n为训练数据集的个数。 |
| `--tokenizer_path` | tokenizer files 所在路径 |
| `--output_path` | 存储预处理数据的地址, 将为每个数据集创建一个 `.idx` 文件和一个 `.bin` 文件。 |
更多内容可以参考[数据预处理说明文档](./docs/data_process.md).
3. 如果一个数据集是被处理过的,即`--output_path` 路径下存在该数据集的`.idx` 文件和`.bin`文件,程序会自动跳过对该数据集的处理。执行数据预处理代码命令如下:
```bash
# 请根据实际路径进行修改
python ./tools/preprocess_data_yuan.py --input '' --data-idx '0-42' --tokenizer_path './tokenizer' --output_path ''
## example
# python ./tools/preprocess_data_yuan.py --input ./datasets/TOY --data-idx '0' --tokenizer_path '/path/of/tokenizer' --output_path './datasets/TOY/'
```
数据集的目录结构如下:
```
├── datasets
│ ├── xxx.idx
│ └── xxx.bin
```
## 训练
暂未支持
## 推理
如果不指定`--model_path_or_name`参数,当前默认`IEITYuan/Yuan2-M32-hf`模型进行推理。
```bash
pip install -U huggingface_hub hf_transfer
export HF_ENDPOINT=https://hf-mirror.com/
HIP_VISIBLE_DEVICES=0,1,2,3 python infer_hf.py --model_path_or_name /path/of/Yuan2-M32-hf
```
**Tips:**
- 为避免出现 `RuntimeError: FlashAttention forward only supports head dimension at most 128`错误,修改 `/path/of/Yuan2-M32-hf/config.json` 文件中 `"use_flash_attention":false`
## result
## 预训练权重
| 模型 | 序列长度 | 模型格式 | 下载链接 |
| :----------: | :------: | :-------: |:---------------------------: |
| Yuan2.0-M32-HF | 16K | HuggingFace | [SCNet](http://113.200.138.88:18080/aimodels/Yuan2-M32-hf) |
### 精度
暂无
## 应用场景
### 算法类别
对话问答
### 热点应用行业
家居,教育,科研
## 源码仓库及问题反馈
- https://developer.hpccube.com/codes/modelzoo/yuan2.0-m32_pytorch
## 参考资料
- https://github.com/IEIT-Yuan/Yuan2.0-M32

