
First add
Showing
Too many changes to show.
To preserve performance only 315 of 315+ files are displayed.
docs/checkpoint_process.md
0 → 100644
docs/data_process.md
0 → 100644
docs/data_process_cn.md
0 → 100644
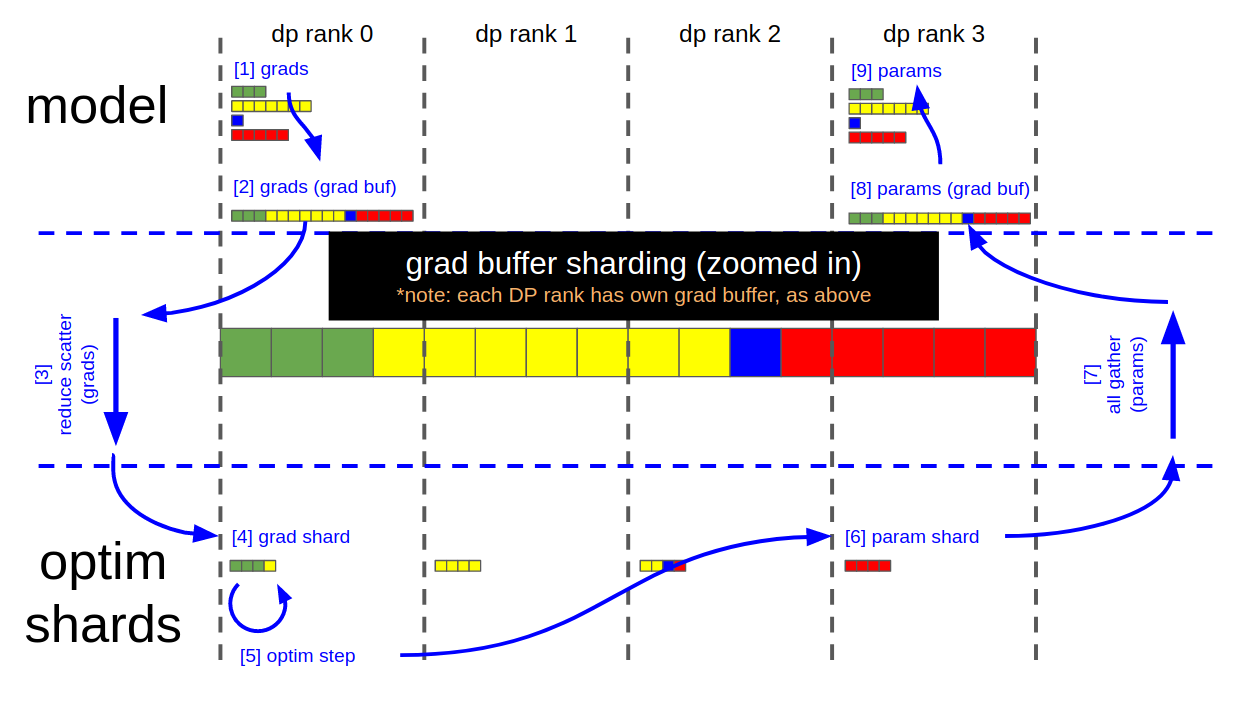
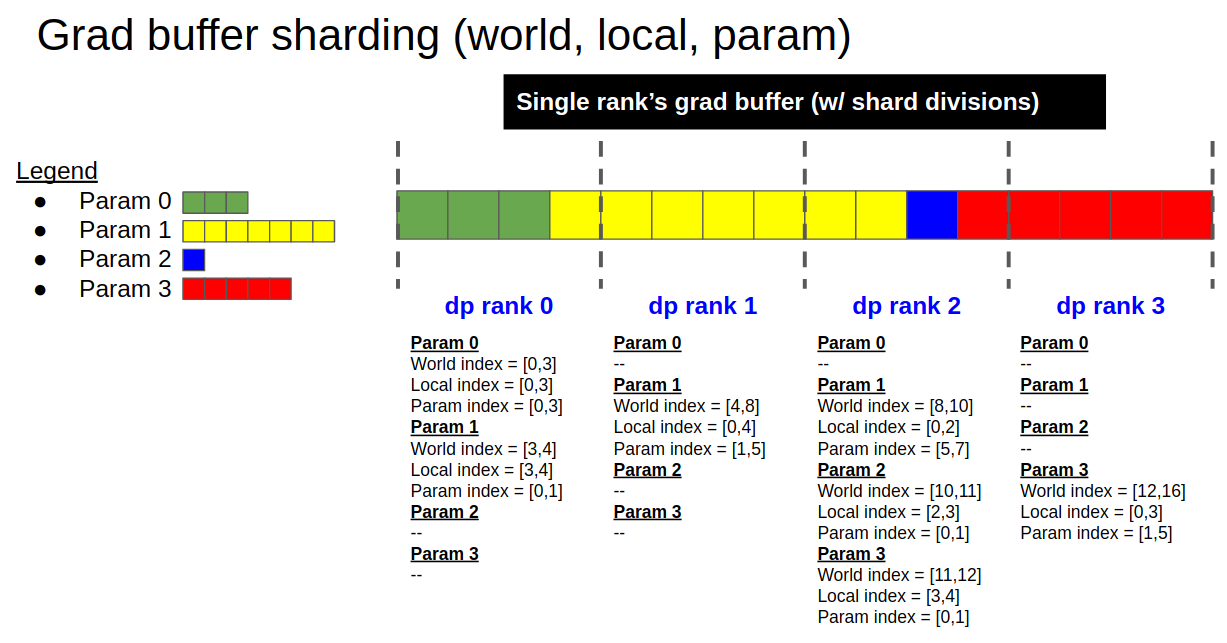
docs/distrib_optimizer.md
0 → 100644
docs/eval_arc.md
0 → 100644
docs/eval_arc_cn.md
0 → 100644
docs/eval_gsm8k.md
0 → 100644
docs/eval_gsm8k_cn.md
0 → 100644
docs/eval_humaneval.md
0 → 100644
docs/eval_humaneval_cn.md
0 → 100644
docs/eval_math.md
0 → 100644
docs/eval_math_cn.md
0 → 100644
docs/eval_mmlu.md
0 → 100644
docs/eval_mmlu_cn.md
0 → 100644
{kind=link}
87.9 KB
{kind=link}
96.8 KB
docs/inference_server.md
0 → 100644
docs/inference_server_cn.md
0 → 100644
docs/instruct_tuning.md
0 → 100644