# Yolov5-QAT
本项目旨在对Yolov5模型执行量化感知训练,将其转换为onnx模型,并在TensorRT上运行。
## 论文
无
## 模型结构
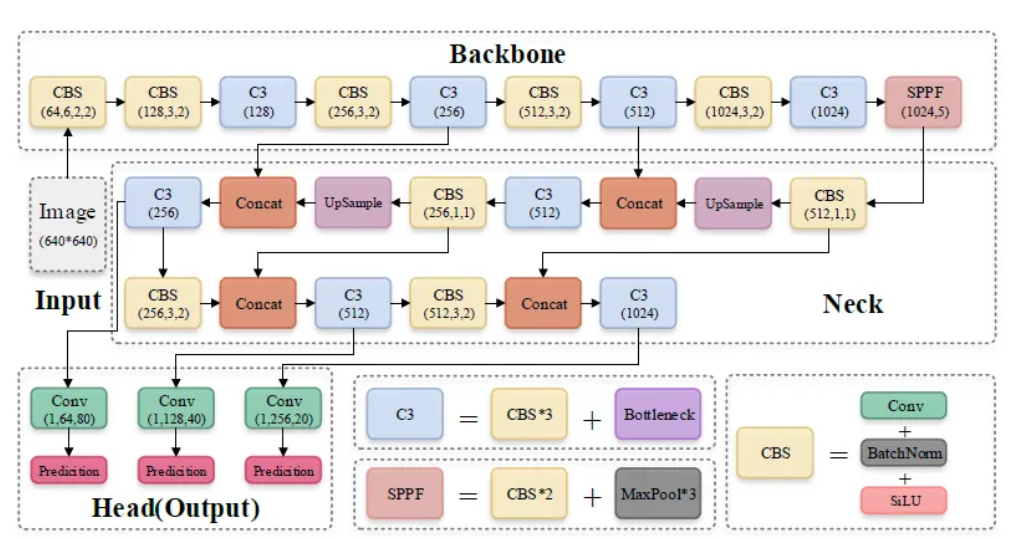
yolov5模型由三个部分组成,分别是`Backbone`,`Neck`以及`Head`。其中`Backbone`网络用于获取不同大小的特征图,`Neck`
融合这些特征,最终生成三个特征图P3、P4和P5(在YOLOv5中,维度用80×80、40×40和20×20表示),分别用于检测图片中的小、中、大物体,`Head`对特征图中的每个像素使用预设的先验锚点进行置信度计算和边界框回归,从而得到一个包含目标类别、类别置信度、边界框坐标、宽度和高度信息的多维数组(BBoxes)。
## 算法原理
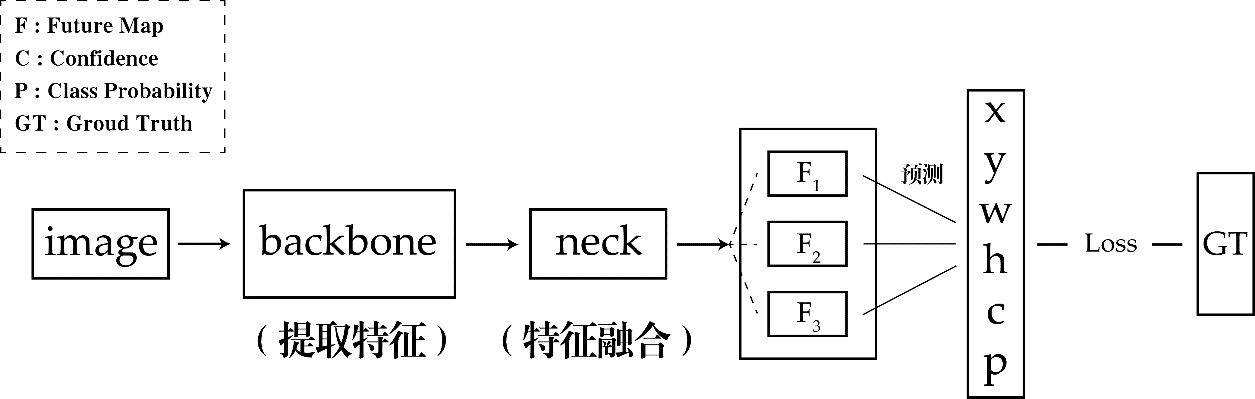
YOLOv5 是一种基于单阶段目标检测算法,通过将图像划分为不同大小的网格,预测每个网格中的目标类别和边界框,利用特征金字塔结构和自适应的模型缩放来实现高效准确的实时目标检测。
## 环境配置
### Anaconda (方法一)
1、本项目目前仅支持在N卡环境运行
python 3.9.18
torch 2.0.1
cuda 11
pip install -r requirements.txt
pip install --no-cache-dir --extra-index-url https://pypi.nvidia.com pytorch-quantization
2、TensorRT
wget https://github.com/NVIDIA/TensorRT/archive/refs/tags/8.5.3.zip
unzip [下载的压缩包] -d [解压路径]
pip install 解压路径/python/tensorrt-8.5.3.1-cp39-none-linux_x86_64.whl
ln -s 解压路径(绝对路径)/bin/trtexec /usr/local/bin/trtexec
注意:若需要`cu12`则将`requirements.txt`中的相关注释关闭,并安装。
## 数据集
本项目使用coco2017数据集.
数据结构如下
images
├── train2017s
├── val2017
labels
├── train2017
├── val2017
annotations
├── instances_train2017.json
├── instances_val2017.json
train2017.txt
val2017.txt
其中`train2017.txt, val2017.txt`可运行脚本`scripts/coco2yolo.py`生成,
python scripts/coco2yolo.py \
--json_path=path/to/instances_[val/train]2017.json \
--save_path=path/to/labels/[val/train]2017.txt
## 训练
# 训练QAT模型
python scripts/qat.py quantize yolov5[s|m|n|x|l].pt \
--qat=/path/to/save/qat/model --cocodir=/path/to/train/data --eval-origin
# 导出 onnx 模型
python scripts/qat.py export /path/to/load/qat/model --size=640 --save=/path/to/save/onnx/model
# 获取tensorrt模型
trtexec --onnx=/path/to/load/onnx/model --saveEngine=/path/to/save/trt/model --int8
注意:更多选项参考`参考资料`。
## 推理
# 指标
python evaluate.py eval --data_list=/path/to/load/trainlist --weight=/path/to/load/model --mtype=[ori|onnx|trt|qat]
# 画图
python evaluate.py draw --weight=/path/to/load/model --mtype=[ori|onnx|trt|qat] --image_path=/path/to/load/image
注意:mtype和weight类型需要严格对应,ori表示原始模型,qat表示基于原始模型得到的qat模型。
## result

### 精度
平台:A800
精度:FP32 + INT8
|模型名称|模型类型|size|map@50-95|map@50|推理速度
|:---|:---|:---|:---|:---|:---|
|yolov5n|原始
ONNX
TRT|640|0.276
0.267
0.267 | 0.453
0.444
0.443 | 8.98ms/sample
9.9ms/sample
3.9ms/sample|
|yolov5s|原始
ONNX
TRT|640| 0.369
0.361
0.362| 0.562
0.557
0.557| 10.0ms/sample
11.4ms/sample
3.74ms/sample|
|yolov5m|原始
ONNX
TRT|640|0.445
0.437
0.438| 0.633
0.628
0.628| 12.8ms/sample
13.2ms/sample
4.4ms/sample|
|yolov5l|原始
ONNX
TRT|640|0.482
0.473
0.473| 0.663
0.659
0.659| 15.6ms/sample
17ms/sample
4.73ms/sample|
|yolov5x|原始
ONNX
TRT|640|0.498
0.492
0.491| 0.679
0.676
0.675| 18ms/sample
20.2ms/sample
5.62ms/sample|
注意:该评测结果不代表模型的真正结果,仅展示不同模型之间的指标差异。
## 应用场景
### 算法类别
`目标检测`
### 热点应用行业
`金融,交通,教育`
## 源码仓库及问题反馈
* https://developer.hpccube.com/codes/modelzoo/yolov5-qat_pytorch
## 参考资料
* https://docs.nvidia.com/deeplearning/tensorrt/pytorch-quantization-toolkit/docs/index.html
* https://github.com/NVIDIA-AI-IOT/cuDLA-samples/
* https://github.com/ultralytics/yolov5