# YOLOv13
YOLOv13引入超图理论,其中YOLOv13-N相比YOLO11-N提升了3.0%的mAP,相比YOLOv12-N提升了1.5%的mAP。
## 论文
`YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception`
- https://arxiv.org/pdf/2506.17733
## 模型结构
遵循“骨干网络→颈部网络→检测头”的计算范式,通过超图自适应关联增强(HyperACE)机制,实现全链路特征聚合与分配(FullPAD),从而增强传统的YOLO架构。
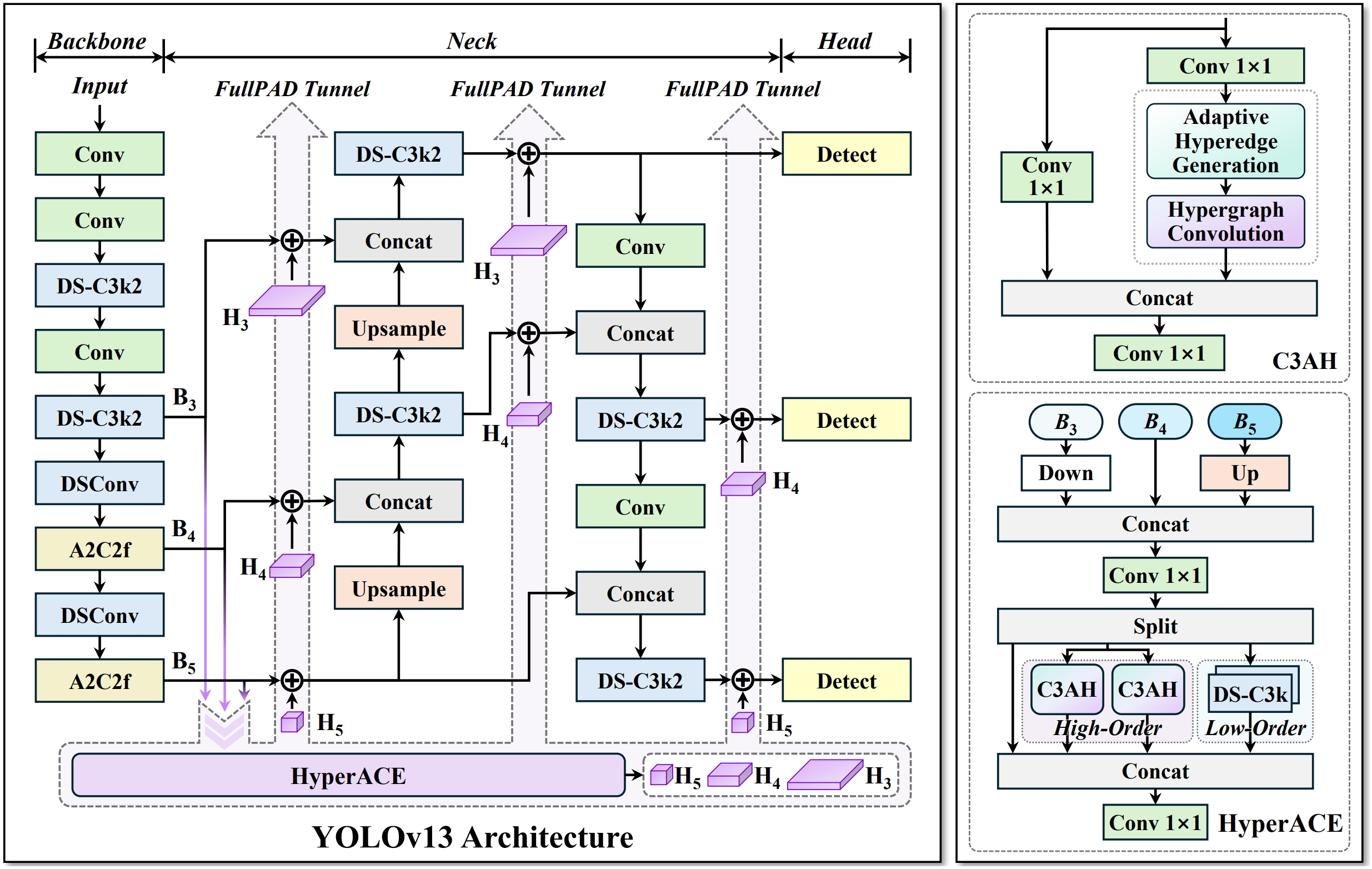
## 算法原理
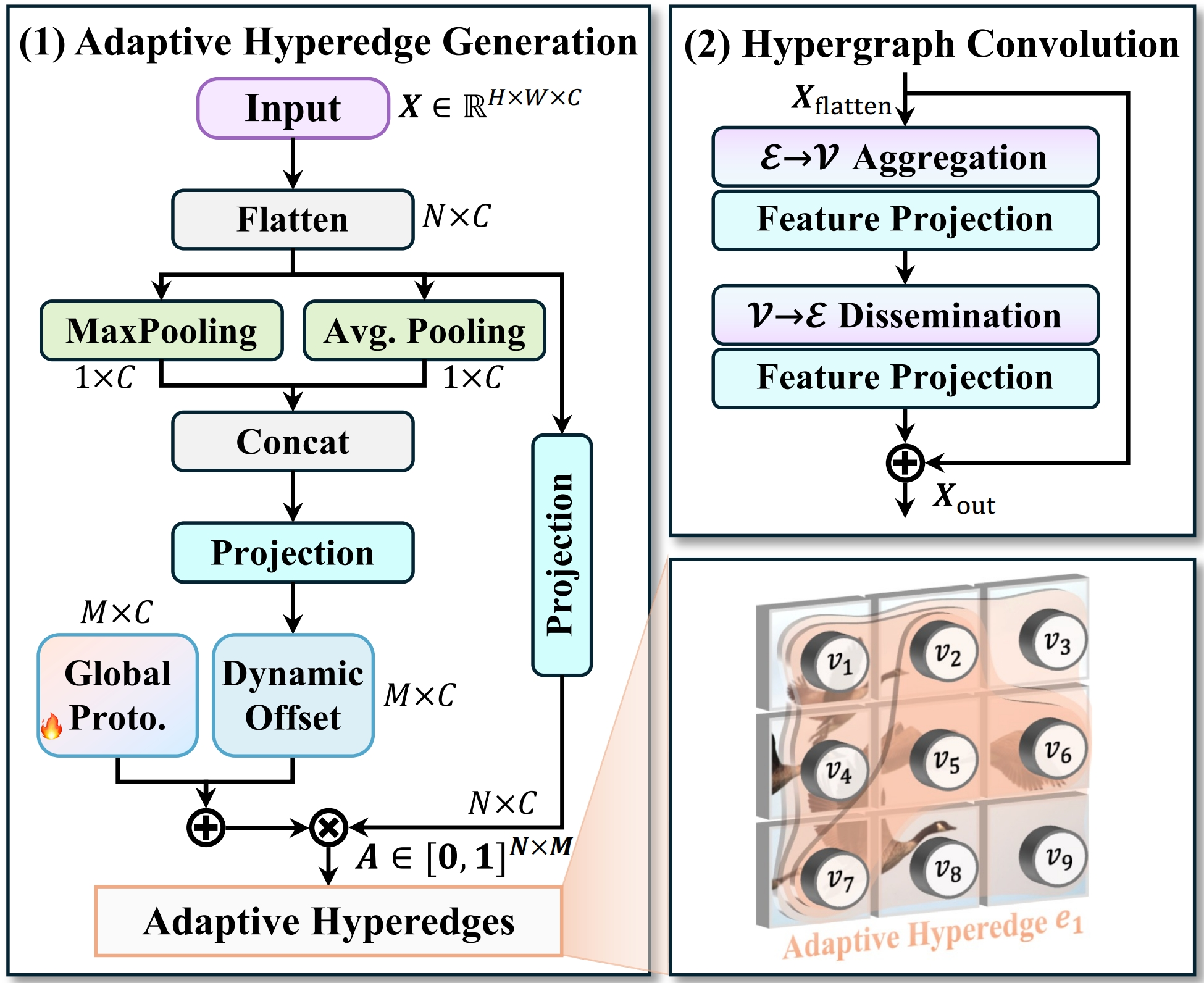
YOLOv13将图片数据送入模型后,沿用yolo系列的通用方法,依次通过backbone、neck提取特征,最后经过head预测出检测框,其中YOLOv13最大的改进是引入超图的自适应关联增强机制HyperACE,将多尺度特征图的像素视为超图顶点,HyperACE 设计了可学习的超边生成模块,自适应地学习并构建超边,动态探索不同特征顶点间的潜在关联。
## 环境配置
```
mv yolov13_pytorch yolov13
```
### 硬件需求
DCU型号:K100AI,节点数量:1 台,卡数:4 张。
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.4.1-ubuntu22.04-dtk25.04.1-py3.10
# 为以上拉取的docker的镜像ID替换,本镜像为:e50d644287fd
docker run -it --shm-size=64G -v $PWD/yolov13:/home/yolov13 -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name yolov13 bash
cd /home/yolov13
pip install -r requirements.txt # requirements.txt
pip install -e . # ultralytics==8.3.63
```
### Dockerfile(方法二)
```
cd /home/yolov13/docker
docker build --no-cache -t yolov13:latest .
docker run --shm-size=64G --name yolov13 -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v $PWD/../../yolov13:/home/yolov13 -it yolov13 bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt。
pip install -e . # ultralytics==8.3.63
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.sourcefind.cn/tool/
```
DTK驱动:25.04.1
python:python3.10
torch:2.4.1
torchvision:0.19.1
triton:3.0.0
flash-attn:2.6.1
deepspeed:0.14.2
apex:1.4.0
onnxruntime:1.19.2
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库参照requirements.txt安装
```
cd /home/yolov13
pip install -r requirements.txt # requirements.txt
pip install -e . # ultralytics==8.3.63
```
## 数据集
[COCO2017](https://modelscope.cn/datasets/PAI/COCO2017)、[coco2017labels-segments](https://github.com/ultralytics/assets/releases/download/v0.0.0/coco2017labels-segments.zip)。
数据集的构造方式:
```
# 1、创建datasets文件
mkdir /home/datasets
# 2、将coco2017labels-segments.zip放到/home/datasets/下面解压,生成数据集主体目录结构。
unzip coco2017labels-segments.zip
# 3、解压COCO2017中的train2017.zip和val2017.zip,并替换/home/datasets/coco/images/下相应的train2017和val2017即可。
```
完整的数据集目录结构如下:
```
/home/datasets/coco/
├── train2017.txt
├── val2017.txt
├── test-dev2017.txt
├── annotations/instances_val2017.json
├── images
├── train2017
├── xxx.jpg
...
└── val2017
├── xxx.jpg
...
└── labels
├── train2017
├── xxx.txt
...
└── val2017
├── xxx.txt
...
...
```
更多资料可参考源项目的[`README_origin`](./README_origin.md)
## 训练
运行训练命令时若未自动下载字体文件,使用以下命令放置即可:
```
cp Arial.ttf /root/.config/yolov13/Arial.ttf
```
### 单机多卡
```
export HIP_VISIBLE_DEVICES=0,1,2,3
cd /home/yolov13
python train.py # 此处以yolov13n为例,其它参数量的模型以此类推。
```
## 推理
### 单机多卡
```
export HIP_VISIBLE_DEVICES=0,1,2,3
cd /home/yolov13
python prediction.py # 此处以yolov13n为例,其它参数量的模型以此类推。
```
更多资料可参考源项目的[`README_origin`](./README_origin.md)
## result
`输入: `
```
/home/yolov13/ultralytics/assets/bus.jpg
/home/yolov13/ultralytics/assets/zidane.jpg
```
`输出:`
```
image 1/2 /home/yolov13/ultralytics/assets/bus.jpg: 640x480 5 persons, 1 bus
image 2/2 /home/yolov13/ultralytics/assets/zidane.jpg: 384x640 2 persons, 1 tie
```
### 精度
测试数据:`/home/datasets/coco/images/val2017`,测试权重为训练结束的`/home/yolov13/runs/detect/train/weights/best.pt`,使用的加速卡:K100AI,max epoch为600,推理框架:pytorch。
| device | mAP50 | mAP75 | mAP50-95 |
| :------: | :------: | :------: | :------: |
| DCU K100AI | 0.567 | 0.445 | 0.411 |
| GPU A800 | 0.564 | 0.441 | 0.41 |
## 应用场景
### 算法类别
`目标检测`
### 热点应用行业
`制造,电商,医疗,能源,教育`
## 预训练权重
`weights/yolov13n.pt`
## 源码仓库及问题反馈
- http://developer.sourcefind.cn/codes/modelzoo/yolov13_pytorch.git
## 参考资料
- https://github.com/iMoonLab/yolov13.git