
v1.0.2
Showing
{kind=link}
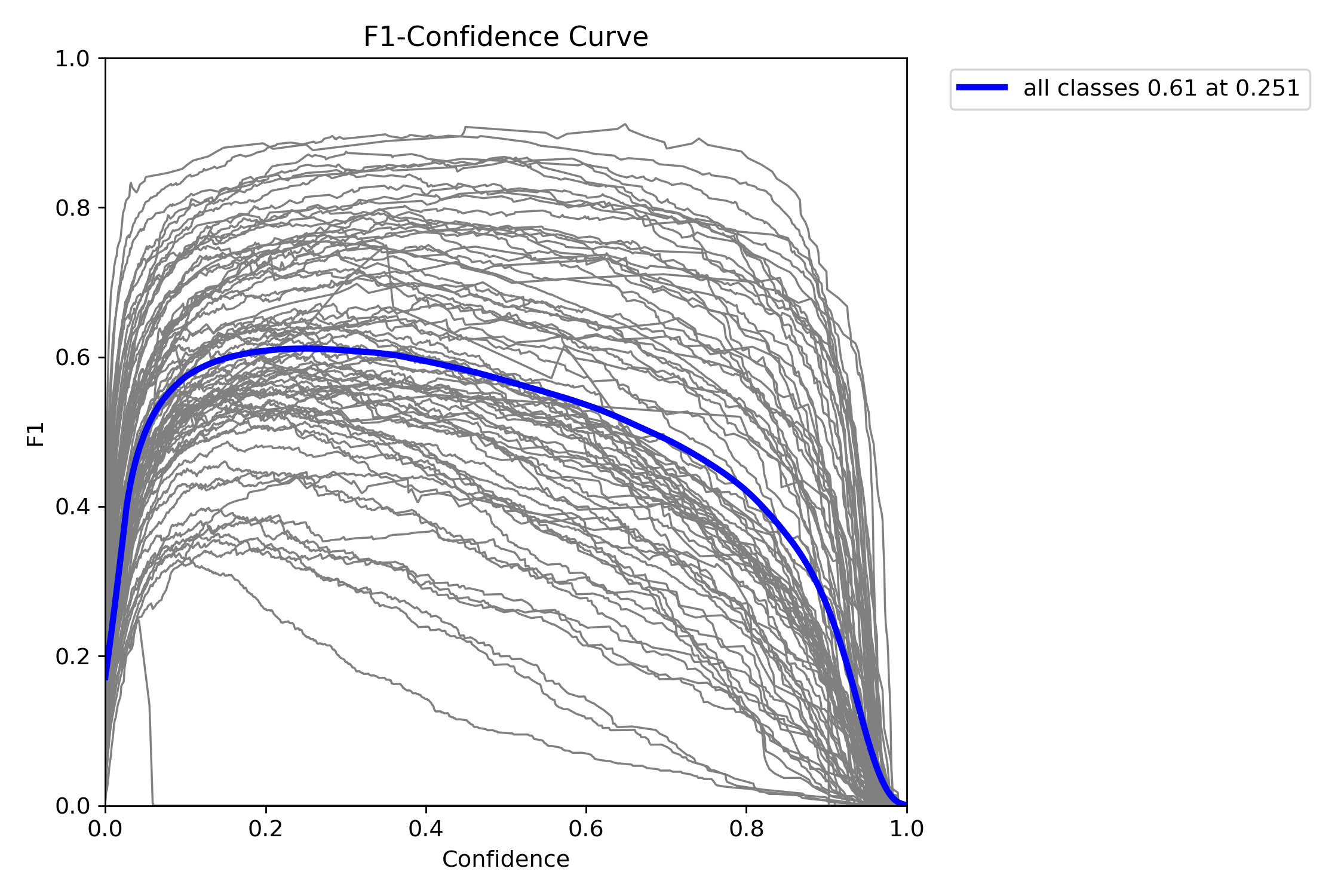
995 KB
{kind=link}
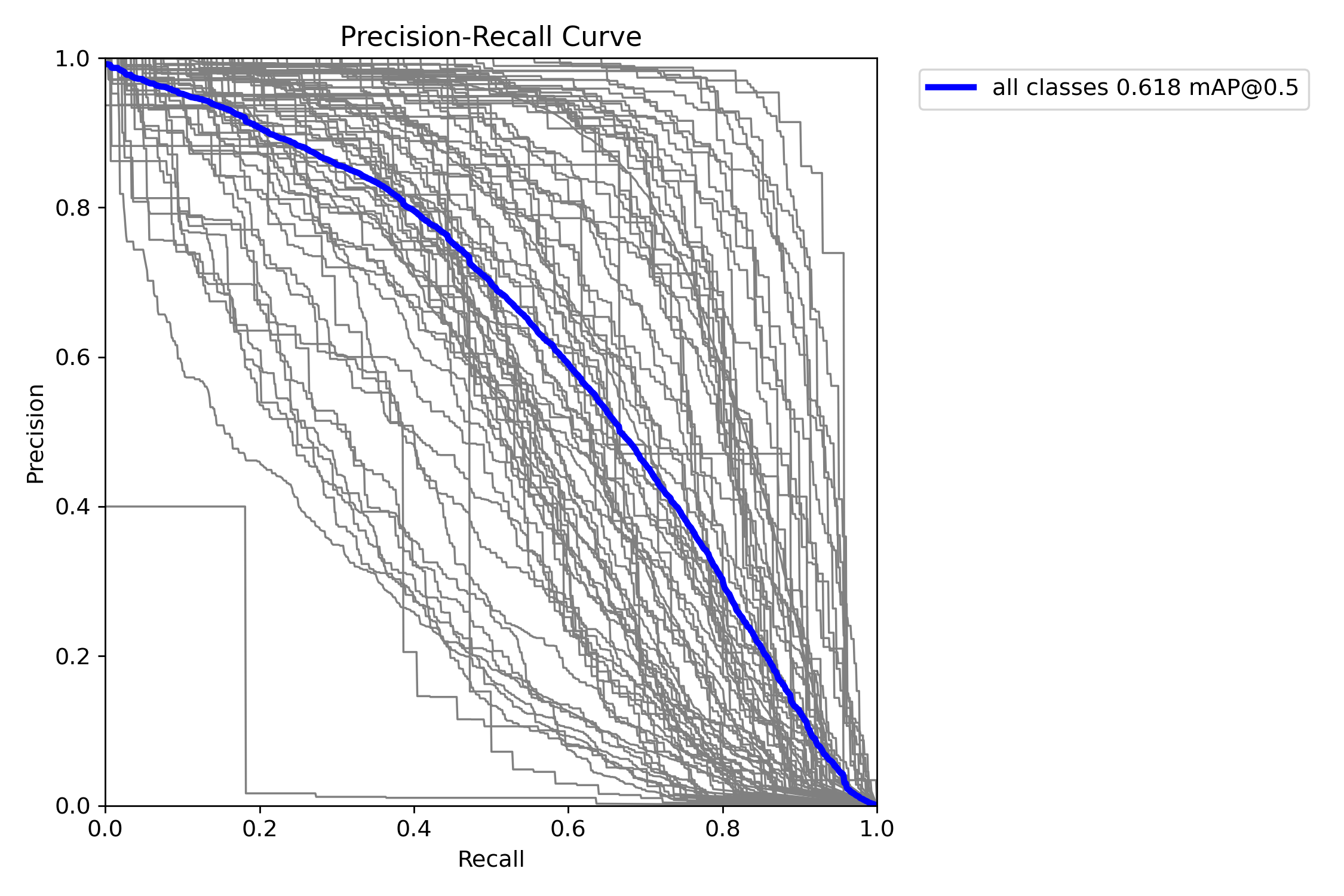
738 KB
{kind=link}
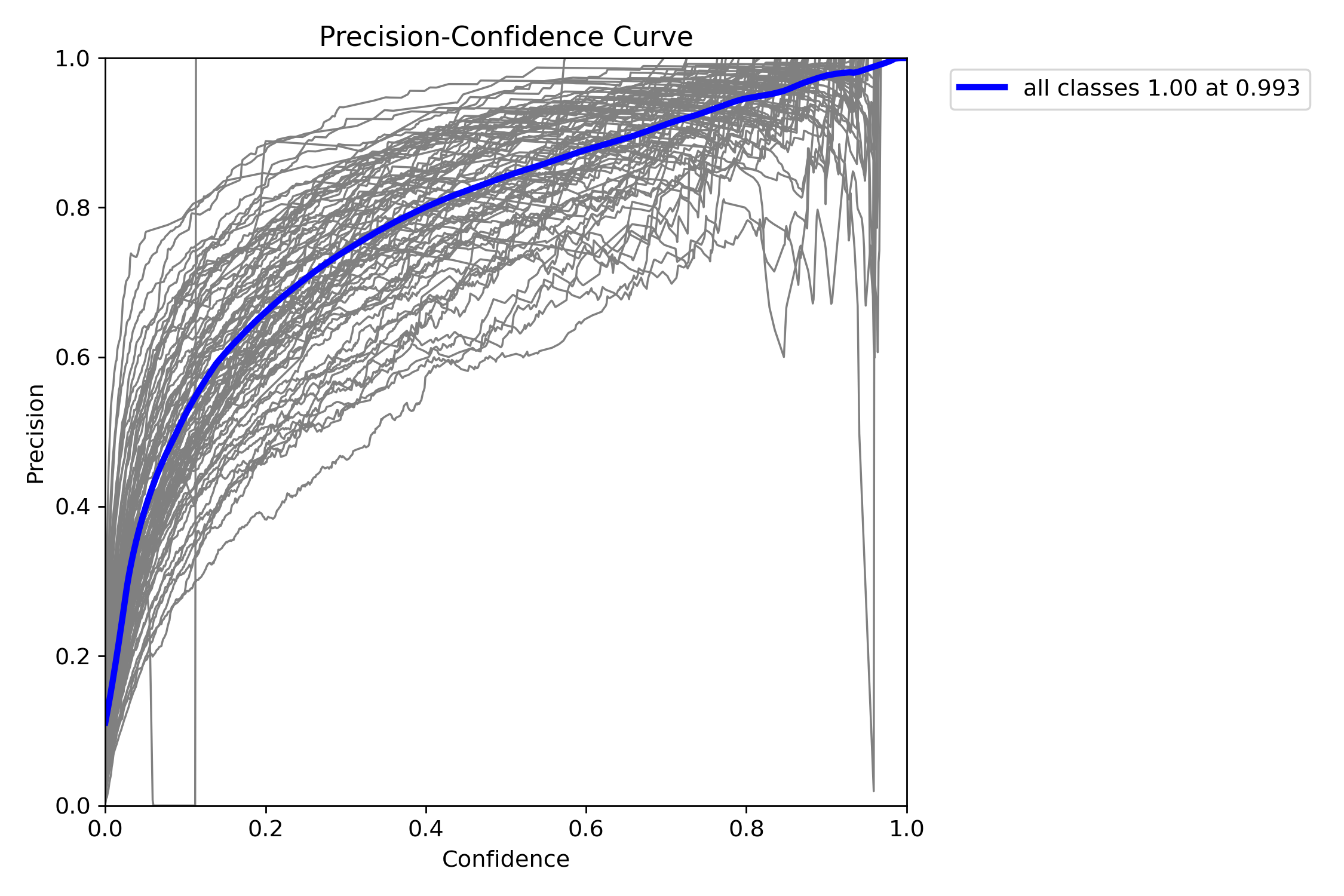
623 KB
{kind=link}
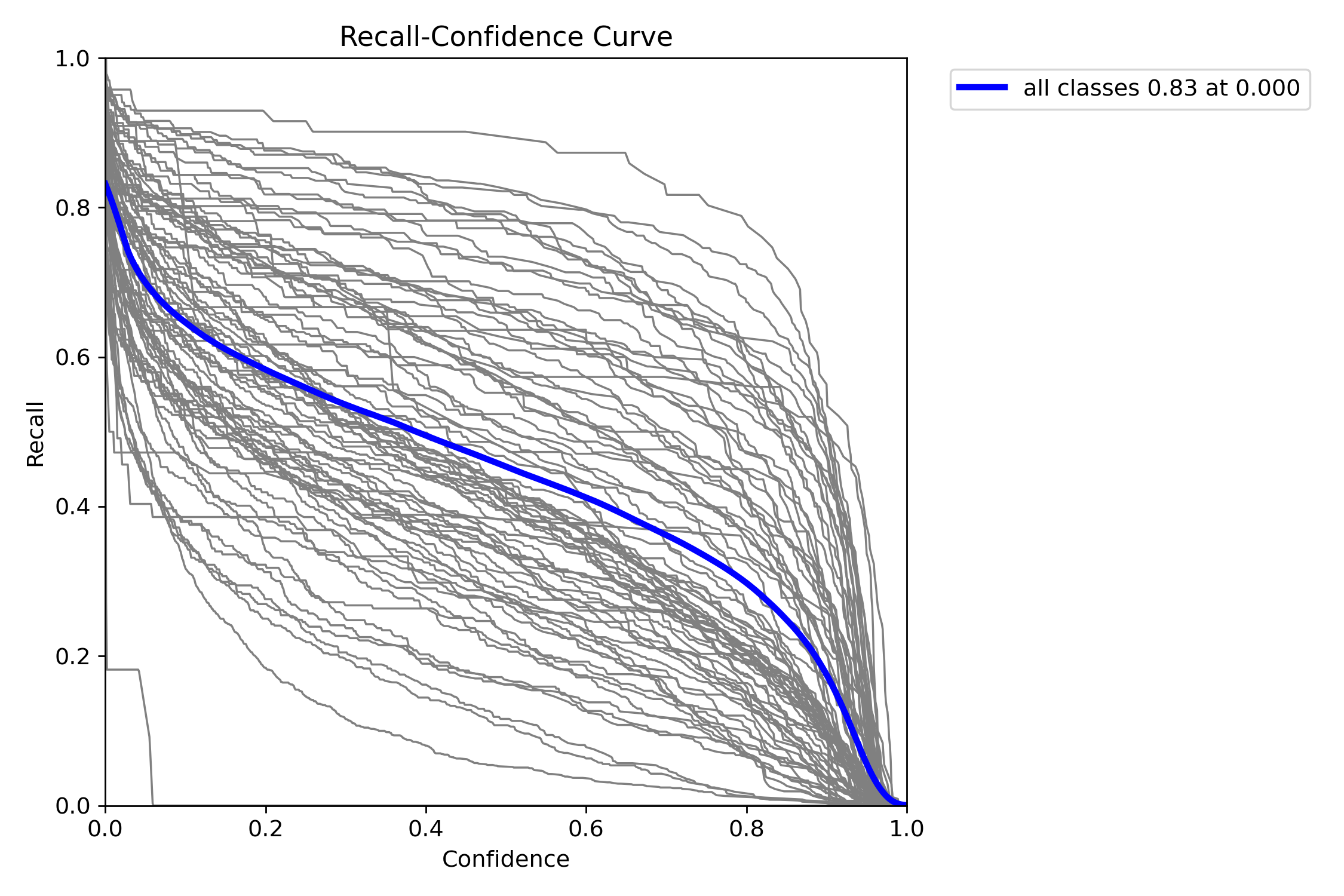
872 KB
runs/detect/train/args.yaml
0 → 100644
This source diff could not be displayed because it is too large. You can view the blob instead.
{kind=link}
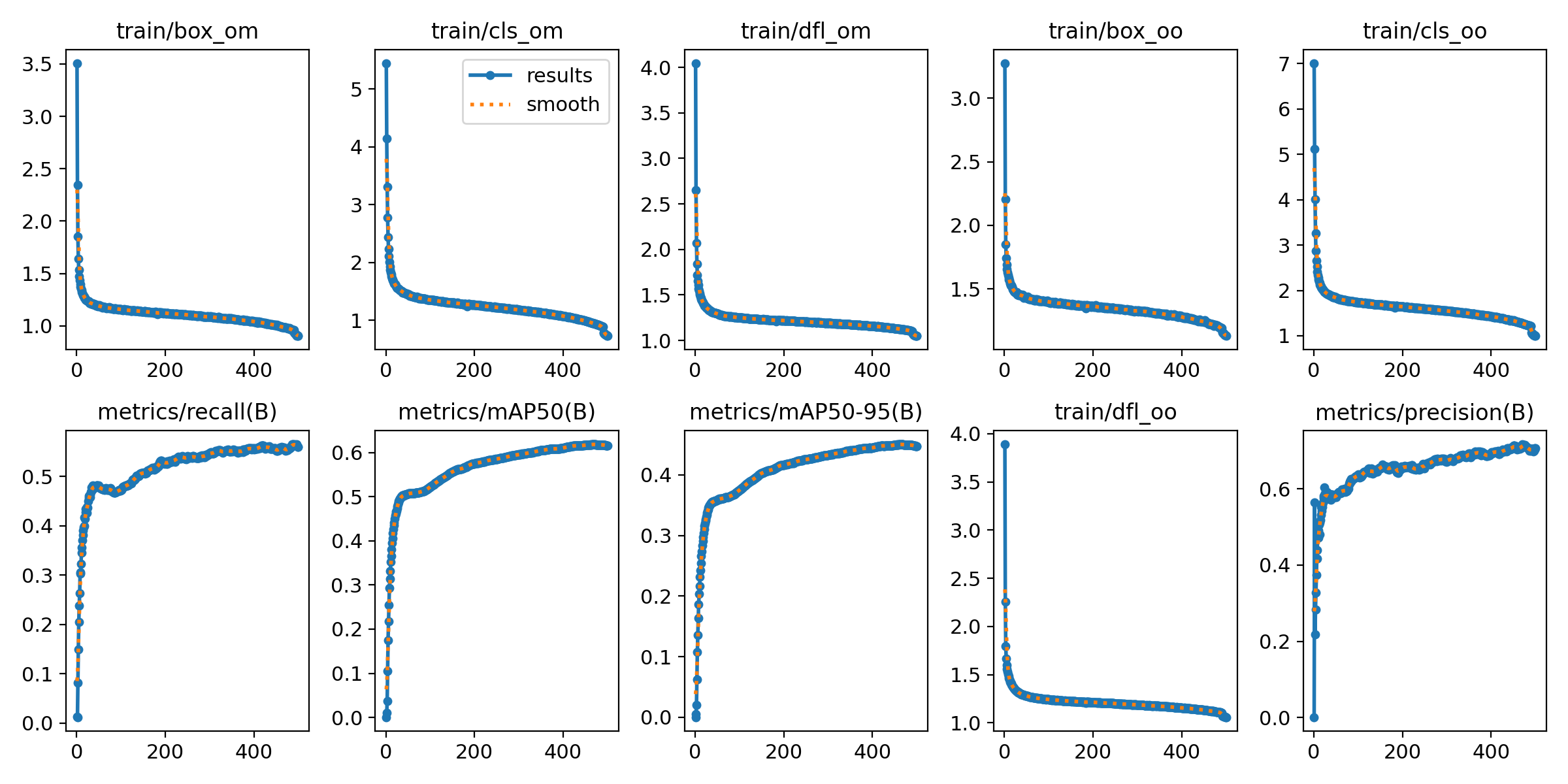
225 KB
{kind=link}

665 KB
{kind=link}

684 KB
{kind=link}

685 KB
{kind=link}

479 KB
{kind=link}
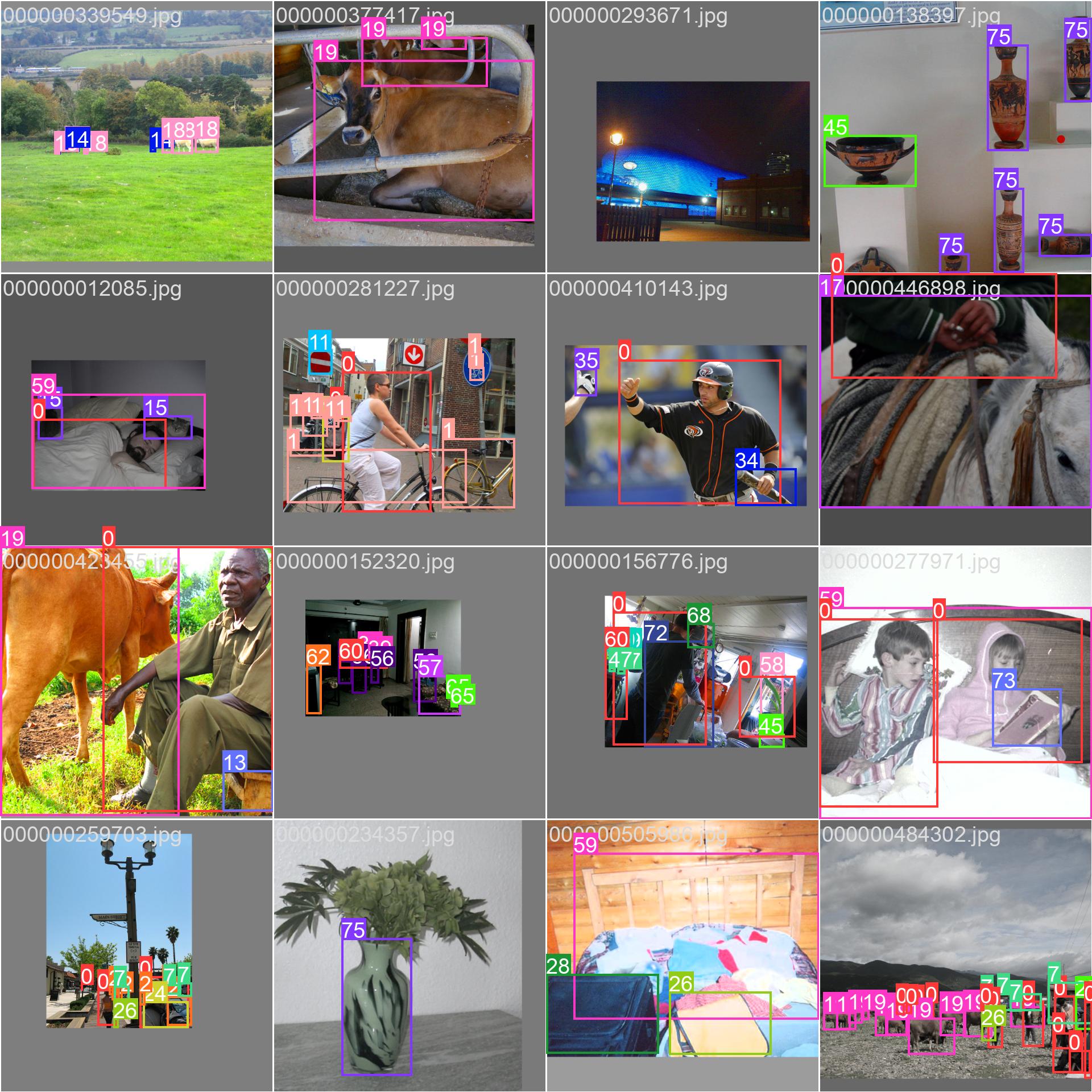
522 KB
{kind=link}

585 KB
{kind=link}

356 KB