# YOLO-World
## 论文
`YOLO-World: Real-Time Open-Vocabulary Object Detection`
- https://arxiv.org/abs/2401.17270
## 模型结构
YOLO-World是一种实时开放词汇目标检测系统,它通过视觉-语言建模和大规模数据集上的预训练,增强了YOLO(You Only Look Once)系列检测器的开放词汇检测能力。该模型没有使用在线词汇表,而是提供了一个提示-检测范式,其中用户根据需要生成一系列提示,提示将被编码到离线词汇表中。然后可以将其重新参数化为模型权重,用于部署和进一步加速。
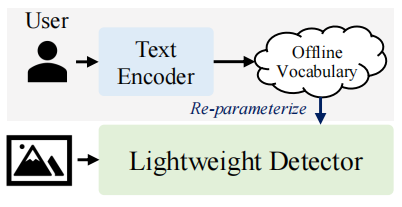
## 算法原理
YOLO-World包含一个YOLO检测器、一个文本编码器和一个可重参数化的视觉-语言路径聚合网络(RepVL-PAN)。给定输入文本,YOLO-World中的文本编码器将其编码为文本嵌入向量。YOLO检测器中的图像编码器从输入图像中提取多尺度特征,然后利用RepVL-PAN通过利用图像特征和文本嵌入向量之间的跨模态融合来增强文本和图像的表示。在推理过程中,可以移除文本编码器,并将文本嵌入重新参数化为RepVL-PAN的权重,以实现高效部署。
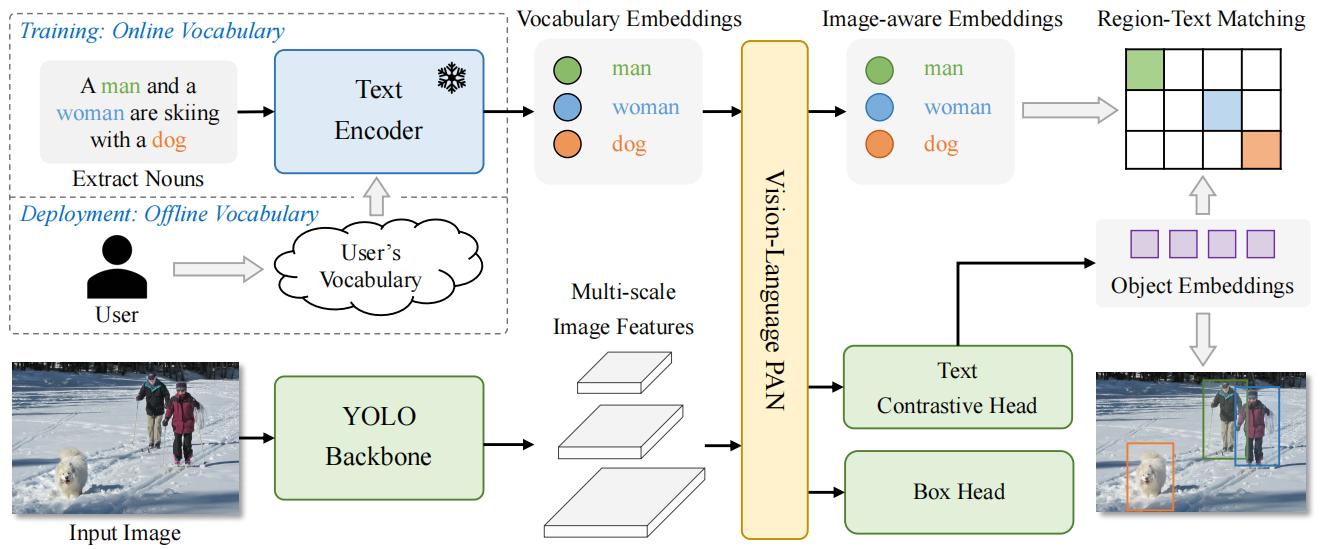
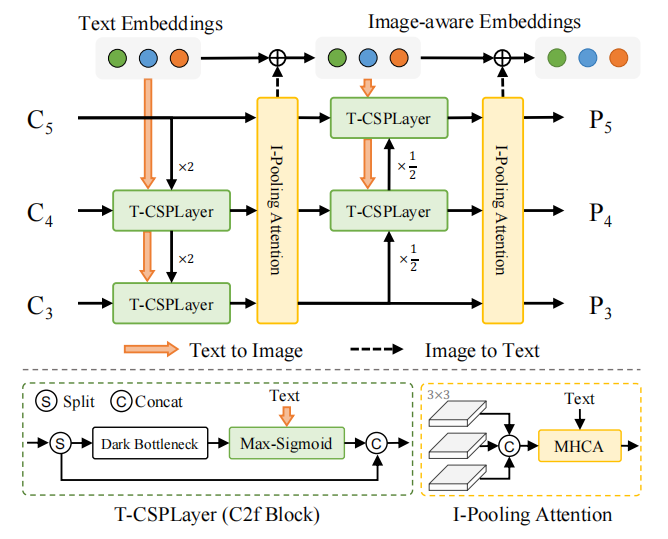
RepVL-PAN结构如下图,通过自顶向下和自底向上的方式,建立具有多尺度图像特征{C3, C4, C5}的特征金字塔{P3, P4, P5}。此外,提出了文本引导的CSPLayer(T-CSPLayer)和图像池化注意力((I-Pooling Attention)来进一步增强图像特征和文本特征之间的交互作用,从而提高开放词汇表的视觉语义表示能力。在推理过程中,可以将脱机词汇表嵌入重新参数化为卷积层或线性层的权重,以进行部署。
## 环境配置
### Docker(方法一)
此处提供[光源](https://www.sourcefind.cn/s)拉取docker镜像的地址与使用步骤,以及[光合](https://developer.sourcefind.cn/tool/)开发者社区深度学习库下载地址
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.2-py3.10
docker run -it --shm-size=128G -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name yolo_world_pytorch bash # 为以上拉取的docker的镜像ID替换
cd /path/your_code_data/yolo_world_pytorch
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip uninstall deepspeed
pip install --upgrade setuptools wheel
cd third_party
git clone https://github.com/onuralpszr/mmyolo.git
cd mmyolo
pip install -v -e .
```
### Dockerfile(方法二)
此处提供dockerfile的使用方法
```
docker build --no-cache -t yoloworld:latest .
docker run -it --shm-size=128G -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name yolo_world_pytorch yoloworld bash
cd /path/your_code_data/yolo_world_pytorch
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip uninstall deepspeed
pip install --upgrade setuptools wheel
cd third_party
git clone https://github.com/onuralpszr/mmyolo.git
cd mmyolo
pip install -v -e .
```
### Anaconda(方法三)
此处提供本地配置、编译的详细步骤,例如:
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```
DTK驱动:dtk24.04.2
python:python3.10
torch: 2.1.0
torchvision: 0.16.0
mmcv:2.0.1
conda create -n yoloworld python=3.8
conda activate yoloworld
pip install torch-2.1.0+das.opt1.dtk24042-cp310-cp310-manylinux_2_28_x86_64.whl
pip install torchvision-0.16.0+das.opt1.dtk24042-cp310-cp310-manylinux_2_28_x86_64.whl
pip install mmcv-2.0.1+das.opt1.dtk24042-cp310-cp310-manylinux_2_28_x86_64.whl
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
其它依赖环境安装如下:
```
cd /path/your_code_data/yolo_world_pytorch
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install --upgrade setuptools wheel
cd third_party
git clone https://github.com/onuralpszr/mmyolo.git
cd mmyolo
pip install -v -e .
```
## 数据集
数据集和标注文件下载链接如下表所示:
| images | SCNet快速下载链接| Annotation File |
|-------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------|--------------------------------------------------------------------------------------------|
| [Objects365 train](https://opendatalab.com/OpenDataLab/Objects365_v1)|[SCNet] | [objects365_train.json](https://opendatalab.com/OpenDataLab/Objects365_v1) |
| [GQA](https://downloads.cs.stanford.edu/nlp/data/gqa/images.zip)|[SCNet] | [final_mixed_train_no_coco.json](https://huggingface.co/GLIPModel/GLIP/tree/main/mdetr_annotations) |
| [Flickr30k](https://opendatalab.com/OpenDataLab/Flickr30k)|[SCNet] | [final_flickr_separateGT_train.json](https://huggingface.co/GLIPModel/GLIP/tree/main/mdetr_annotations) |
| [COCO val2017](https://opendatalab.com/OpenDataLab/COCO_2017)| [SCNet] | [lvis_v1_minival_inserted_image_name.json](https://huggingface.co/GLIPModel/GLIP/blob/main/lvis_v1_minival_inserted_image_name.json) |
将所有数据下载并放置于data文件夹下,数据目录如下:
注意:lvis_v1_minival_inserted_image_name.json放于coco/lvis/文件夹下,其余数据标注文件放于各数据文件的annotations文件夹下,仓库中已提供annotation文件[./data/texts](https://developer.sourcefind.cn/codes/modelzoo/yolo_world_pytorch/-/tree/master/data/texts)
mixed_grounding对应GQA数据
具体数据细节查看 [docs/data](./doc/data.md)
```
├── coco
│ ├── annotations
│ ├── lvis
│ ├── train2017
│ ├── val2017
├── flickr
│ ├── annotations
│ └── images
├── mixed_grounding
│ ├── annotations
│ ├── images
├── objects365v1
│ ├── annotations
│ ├── train
│ ├── val
```
## 训练
首先下载clip-vit模型文件,放于openai目录下:
官方下载链接:
[clip-vit-large-patch14-336下载](https://huggingface.co/openai/clip-vit-large-patch14-336)
[clip-vit-base-patch32下载](https://huggingface.co/openai/clip-vit-base-patch32)
### 单机单卡
```
cd /path/your_code_data/yolo_world_pytorch
chmod +x tools/dist_train.sh
# sample command for pre-training, use AMP for mixed-precision training
#./tools/dist_train.sh configs/pretrain/yolo_world_l_t2i_bn_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py 1 --amp
#样例如下
./tools/dist_train.sh configs/pretrain/yolo_world_v2_s_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py 1 --amp
```
### 单机多卡
```
chmod +x tools/dist_train.sh
# sample command for pre-training, use AMP for mixed-precision training
#./tools/dist_train.sh configs/pretrain/yolo_world_l_t2i_bn_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py 4 --amp
#样例如下
./tools/dist_train.sh configs/pretrain/yolo_world_v2_s_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py 4 --amp
```
## 推理
根据以下链接下载想要的模型权重文件,放到weights文件夹下:
[YOLO-World](https://hf-mirror.com/wondervictor/YOLO-World/tree/main)
注意:模型配置文件与权重文件应一一对应
### 单卡推理
Evaluated on LVIS minival:
```
chmod +x tools/dist_test.sh
#./tools/dist_test.sh path/to/config path/to/weights 1
#样例如下
./tools/dist_test.sh \
configs/pretrain/yolo_world_v2_x_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py \
weights/yolo_world_v2_x_obj365v1_goldg_cc3mlite_pretrain_1280ft-14996a36.pth 1
```
Simple_Demo:
```
#PYTHONPATH=/xxxx/YOLO-World python demo/simple_demo.py
#样例如下:
#注意需先下载模型权重文件yolo_world_v2_x_obj365v1_goldg_cc3mlite_pretrain_1280ft-14996a36.pth
PYTHONPATH=/public/home/luopl/yolo_world_pytorch python demo/simple_demo.py
```
Image_Demo:
```
#python demo/image_demo.py path/to/config path/to/weights image/path/directory 'person,dog,cat' --topk 100 --threshold 0.005 --output-dir demo_outputs
#样例如下:
PYTHONPATH=/public/home/luopl/yolo_world_pytorch \
python demo/image_demo.py configs/pretrain/yolo_world_v2_x_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py \
weights/yolo_world_v2_x_obj365v1_goldg_cc3mlite_pretrain_1280ft-14996a36.pth \
demo/sample_images/ \
'person,sky,bus' --topk 100 --threshold 0.005 --output-dir demo_outputs
```
### 多卡推理
Evaluated on LVIS minival:
```
chmod +x tools/dist_test.sh
#./tools/dist_test.sh path/to/config path/to/weights 4
#样例如下
./tools/dist_test.sh \
configs/pretrain/yolo_world_v2_x_vlpan_bn_2e-3_100e_4x8gpus_obj365v1_goldg_train_1280ft_lvis_minival.py \
weights/yolo_world_v2_x_obj365v1_goldg_cc3mlite_pretrain_1280ft-14996a36.pth 4
```
## result
Simple_demo推理可视化结果如下:
Image_demo推理可视化结果如下:
### 精度
使用四张DCU-Z100SM,Evaluated on LVIS minival
| model | Pre-train Data | size | APmini | APr | APc | APf |
|:--------------------------------------:|:--------------------------------------:|------|--------|------|------|------|
| YOLO-Worldv2-S | O365+GoldG | 1280 | 24.1 | 18.7 | 22.0 | 26.9 |
| YOLO-Worldv2-M | O365+GoldG | 1280 | 31.6 | 24.5 | 29.0 | 35.1 |
| YOLO-Worldv2-L | O365+GoldG | 1280 | 34.6 | 29.2 | 32.8 | 37.2 |
| YOLO-Worldv2-X | O365+GoldG+CC3M-Lite | 1280 | 37.6 | 29.1 | 35.8 | 40.6 |
## 应用场景
### 算法类别
`目标检测`
### 热点应用行业
`科研,制造,医疗,家居,教育`
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/yolo_world_pytorch
## 参考资料
- https://github.com/AILab-CVC/YOLO-World

