
Initial commit
Showing
llm-code/pretrain_run.sh
0 → 100644
llm-code/requirements.txt
0 → 100644
llm-code/sft_run.sh
0 → 100644
model.properties
0 → 100644
requirements.txt
0 → 100644
| transformers>=4.41.2 | |||
| datasets>=2.16.0 | |||
| accelerate>=0.30.1 | |||
| peft>=0.11.1 | |||
| trl>=0.8.6 | |||
| gradio>=4.0.0 | |||
| pandas>=2.0.0 | |||
| scipy | |||
| einops | |||
| sentencepiece | |||
| tiktoken | |||
| protobuf | |||
| uvicorn | |||
| pydantic | |||
| fastapi | |||
| sse-starlette | |||
| matplotlib>=3.7.0 | |||
| fire | |||
| packaging | |||
| pyyaml | |||
| numpy<2.0.0 | |||
| transformers_stream_generator | |||
| modelscope |
resources/.DS_Store
0 → 100644
File added
resources/13b1.png
0 → 100644
{kind=link}
206 KB
resources/13b2.png
0 → 100644
{kind=link}
20.5 KB
resources/13b3.png
0 → 100644
{kind=link}
8.55 MB
resources/6b_all_eval.png
0 → 100644
{kind=link}
22.7 KB
{kind=link}
36.2 KB
{kind=link}
38.3 KB
resources/6b_ins_gen.png
0 → 100644
{kind=link}

206 KB
{kind=link}

165 KB
resources/6b_self_qa.png
0 → 100644
{kind=link}
369 KB
resources/6b_stru_cha.png
0 → 100644
{kind=link}
57 KB
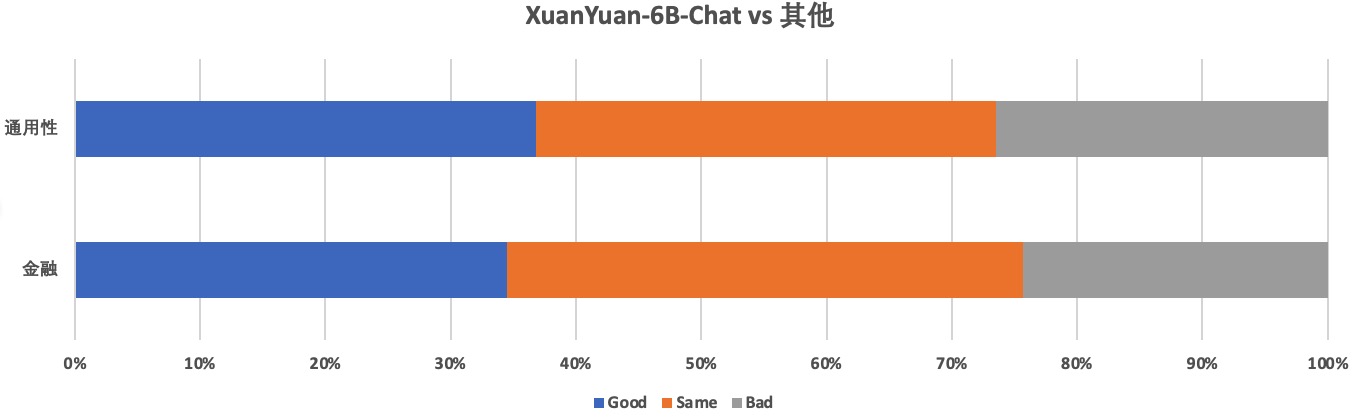
resources/6b_vs_other.jpg
0 → 100644
{kind=link}
45.6 KB
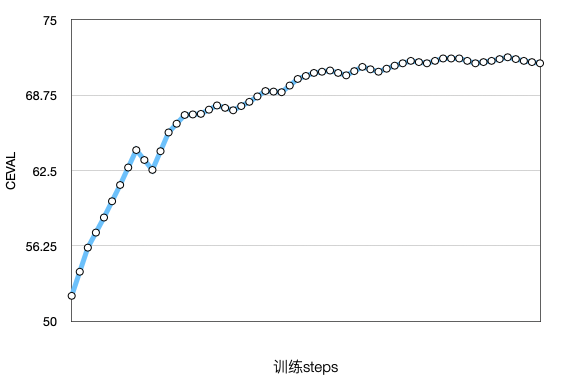
resources/CEVAL-curve.png
0 → 100644
{kind=link}
31.3 KB
resources/Wechat.jpeg
0 → 100644
{kind=link}

134 KB