
Initial commit
Showing
docker/requirements.txt
0 → 100644
ds_zero3_work_dtk.sh
0 → 100644
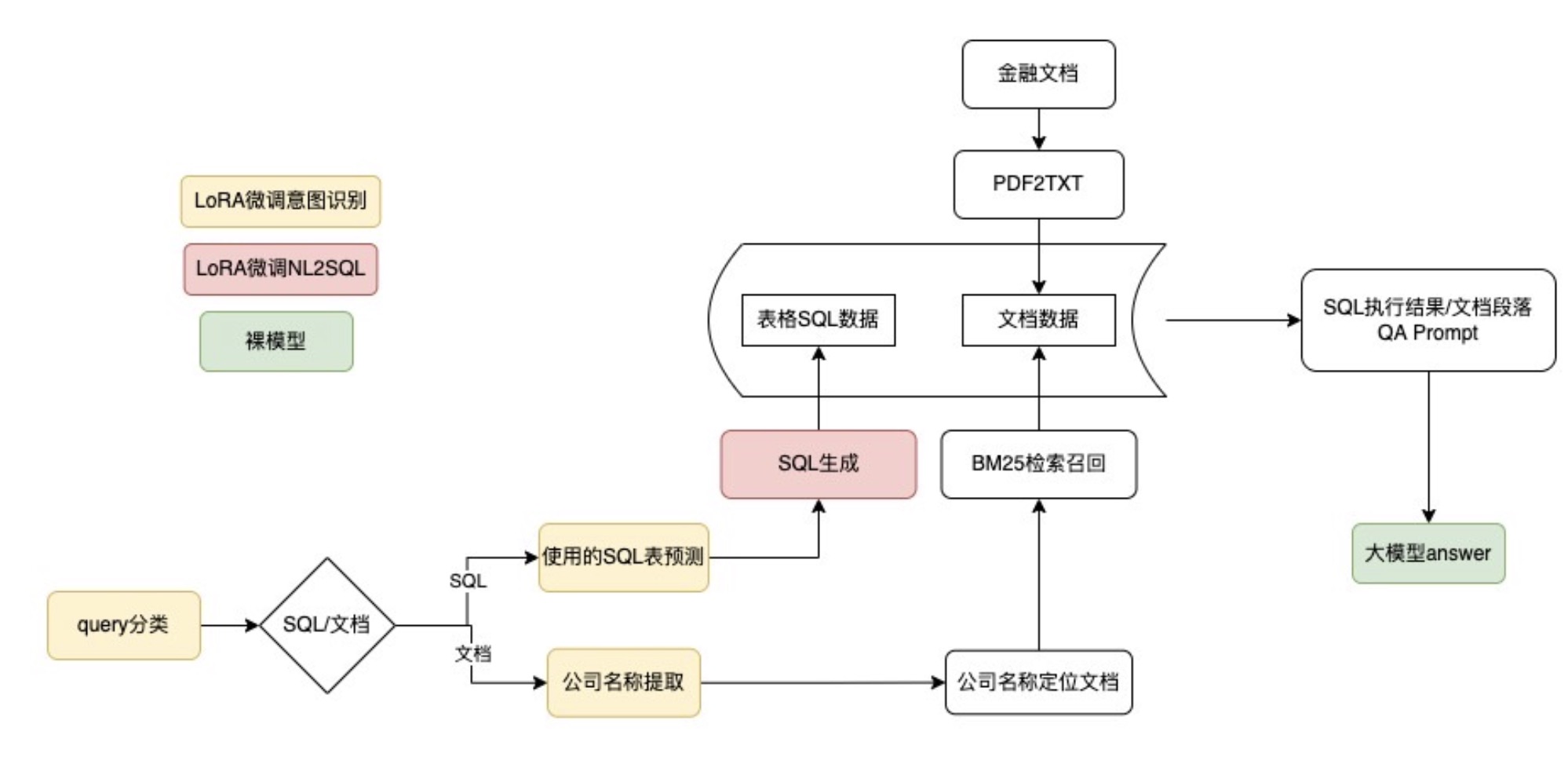
imgs/framework_1.jpg
0 → 100644
{kind=link}
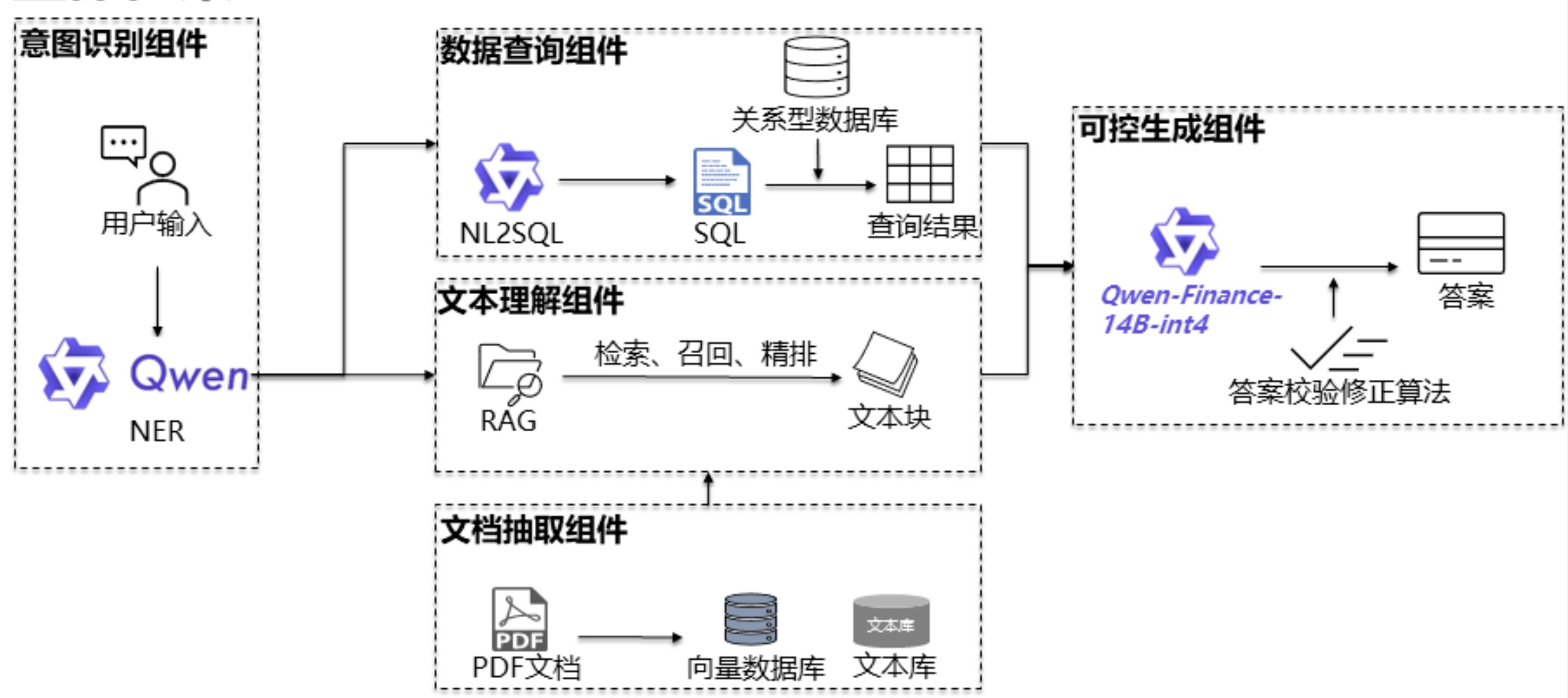
222 KB
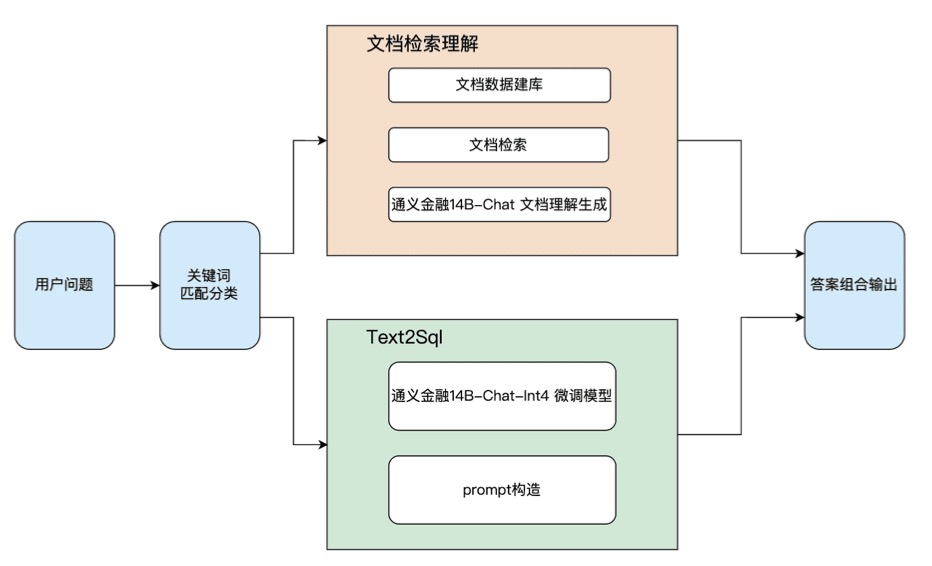
imgs/framework_2.jpg
0 → 100644
{kind=link}
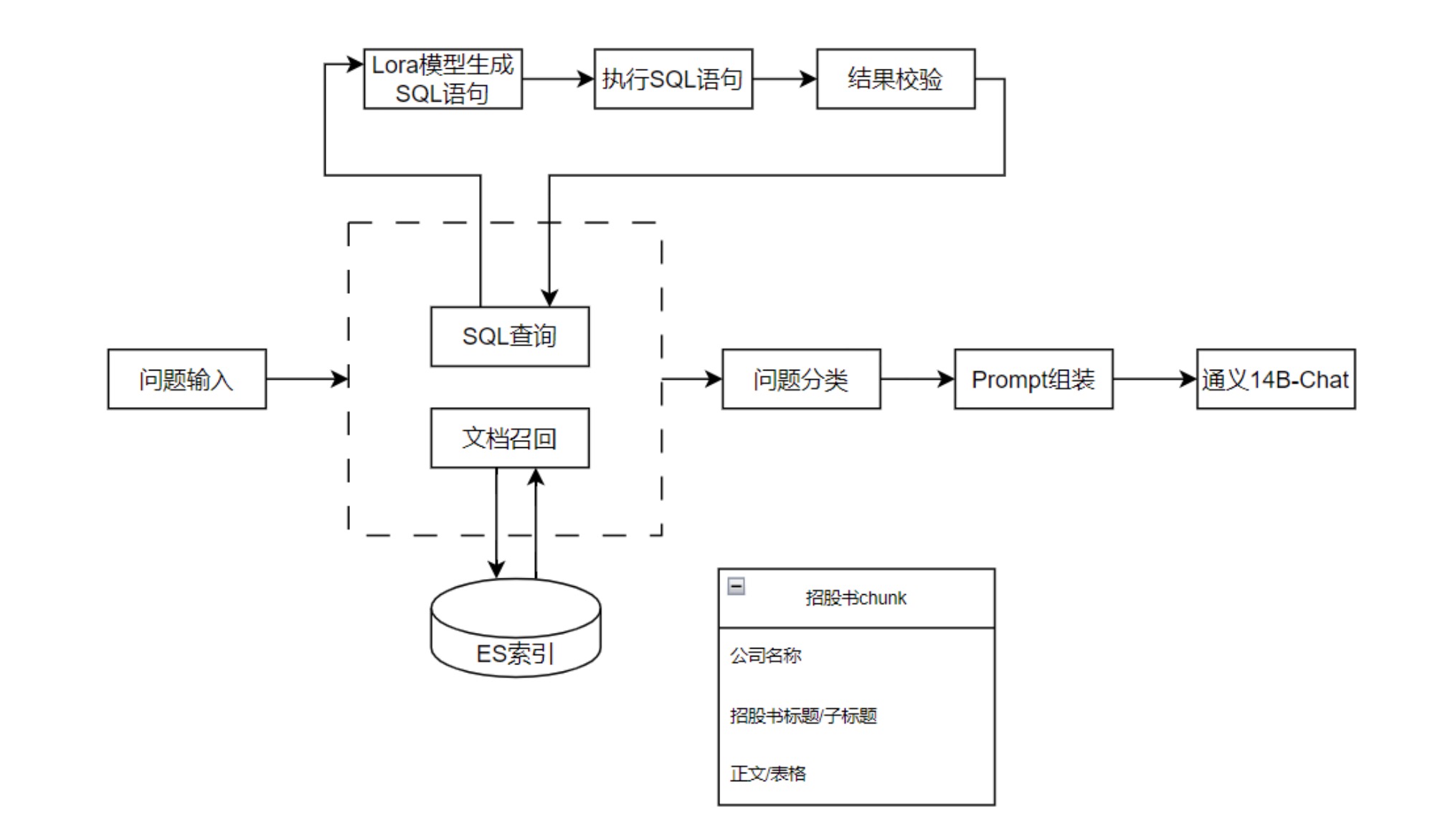
131 KB
imgs/framework_3.jpg
0 → 100644
{kind=link}
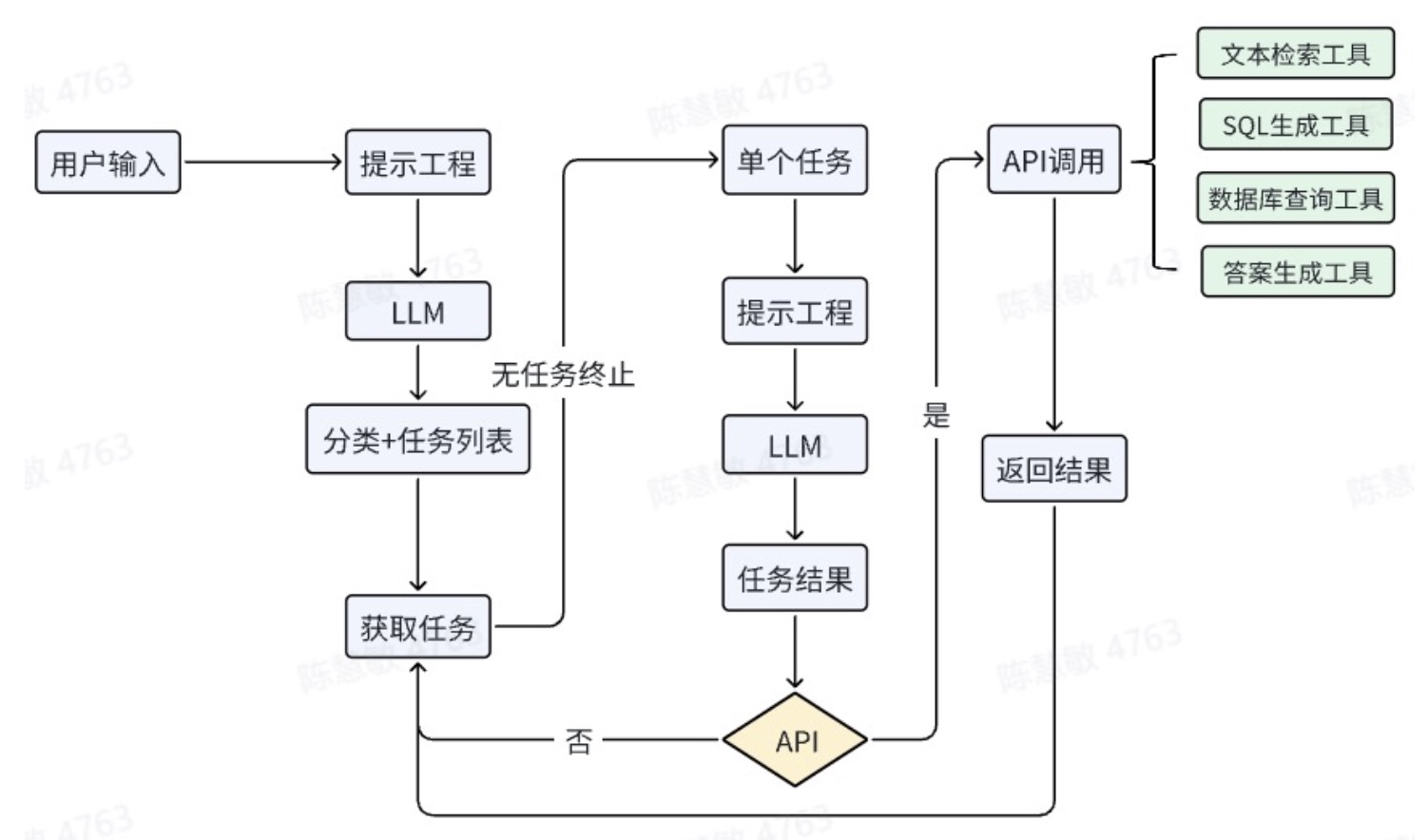
111 KB
imgs/framework_4.jpg
0 → 100644
{kind=link}
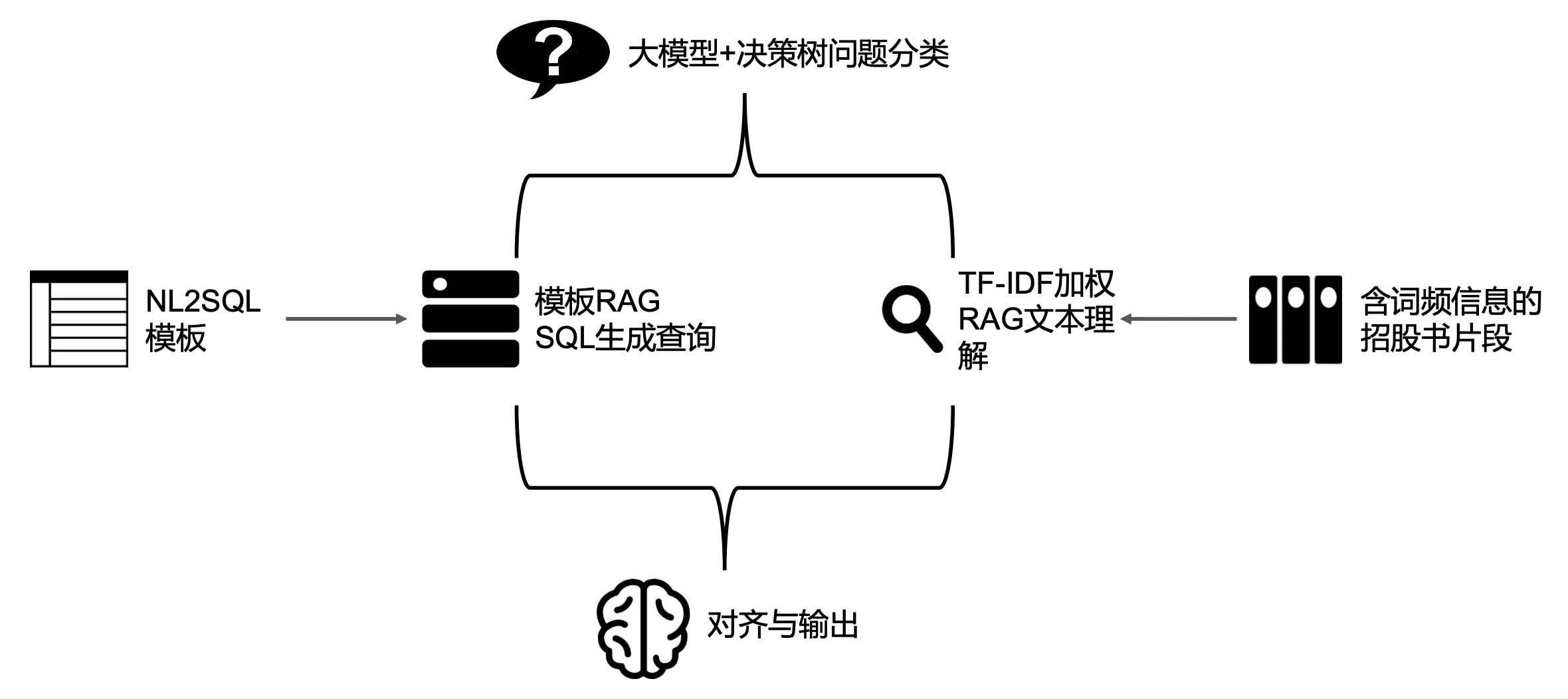
150 KB
imgs/framework_5.jpg
0 → 100644
{kind=link}
128 KB
imgs/framework_6.jpg
0 → 100644
{kind=link}
55.3 KB
imgs/result.png
0 → 100644
{kind=link}

44.4 KB
imgs/result1.png
0 → 100644
{kind=link}
31.7 KB
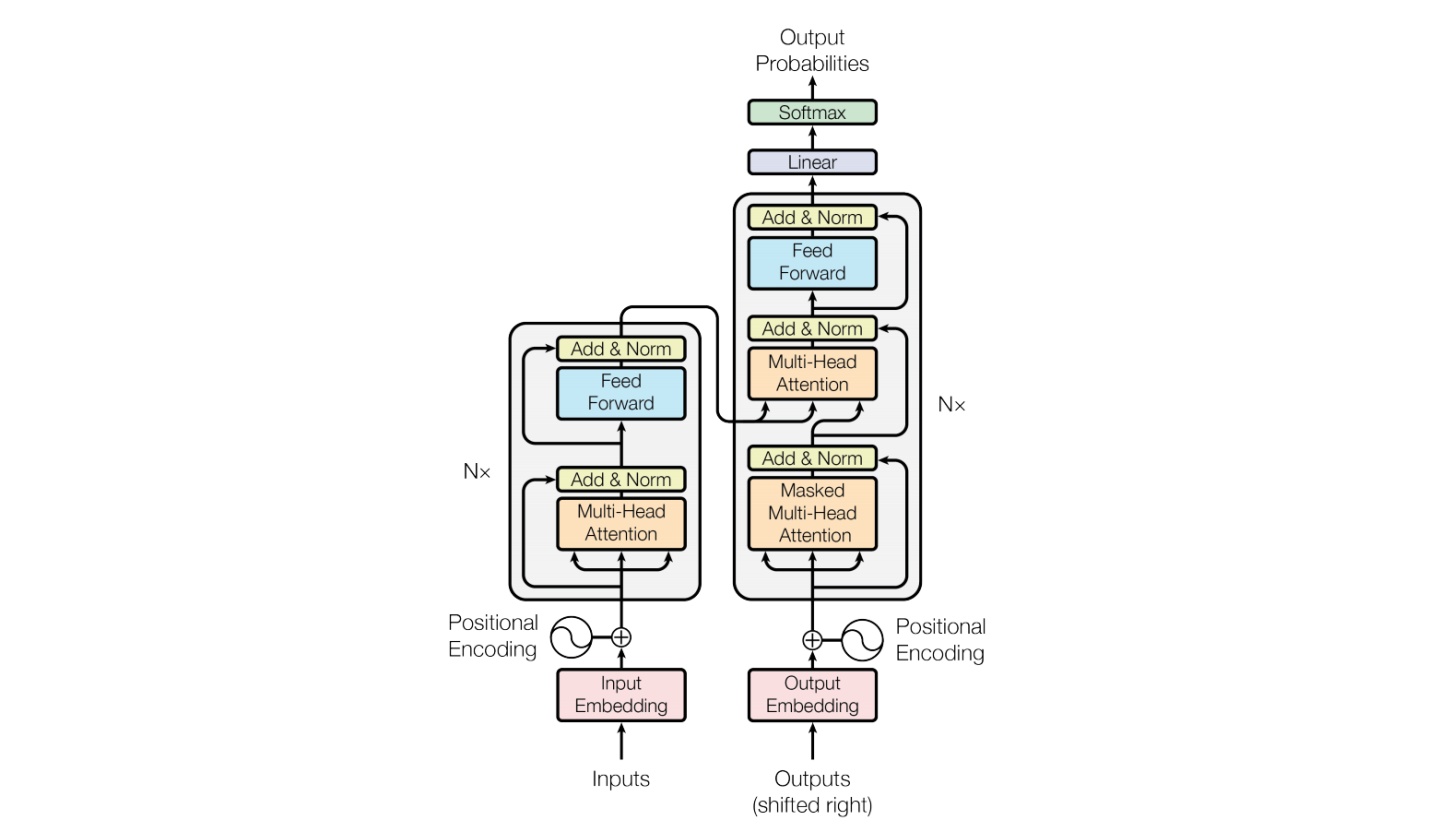
imgs/transformer.jpg
0 → 100644
{kind=link}
87.9 KB
imgs/transformer.png
0 → 100644
{kind=link}
112 KB
llm-code/.done
0 → 100644
llm-code/README.md
0 → 100644
llm-code/clear_cache.sh
0 → 100644
llm-code/config.py
0 → 100644
llm-code/dataset.py
0 → 100644
llm-code/dxm_llm_main.py
0 → 100644
llm-code/model_hook.py
0 → 100644