# Android
[简体中文](./README.md) | English
**Disclaimer, this document was obtained through machine translation, please check the original document [here](./README.md).**
## Convert model
1. To convert your models, run `convert-ggml.py` from the root of your `Whisper-Finetune` project to convert your models to ggml format for your Android project. The models you need to convert can be original Transformers. It can also be a fine-tuned model.
```shell
python convert-ggml.py --model_dir=models/whisper-tiny-finetune/ --output_path=models/ggml-model.bin
```
2. Put the model in the Android project `app/SRC/main/assets/models` directory, and then you can use the Android open Studio project.
## Build notes
1. The default NDK version used is `25.2.9519653`, if you change the other version below, you will need to change the configuration in `app/build.gradle`.
2. **Note that in real use, be sure to release the `release` APK package so that inference is fast.**
3. This project has released the `release` APK package, please scan the code at the end of the `Whisker-finetune` project homepage to download it.
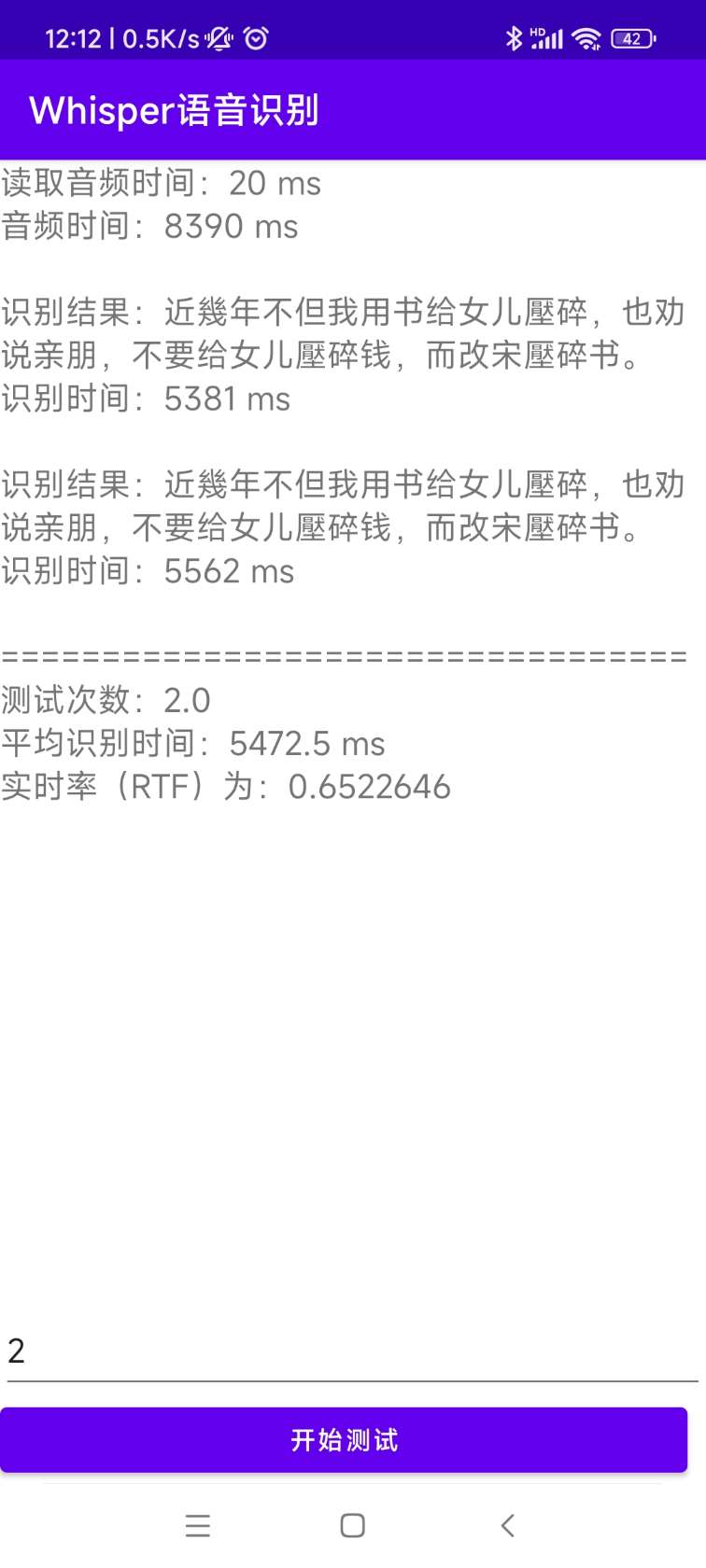
## Effect picture
The effect picture is as follows. The model used here is quantized as a half-precision tiny model, which has a low accuracy.
## Download APK
Can click here to download the [Android APK](https://yeyupiaoling.cn/whisper.apk), note that in order to install package is small, quantitative model used here for half a tiny model precision and accuracy is not high, if you want to change model, please compile the project execution.