# wav2vec
## 论文
wav2vec: Unsupervised Pre-training for Speech Recognition
- https://arxiv.org/abs/1904.05862
## 模型结构
wav2vec系列工作是由facebook AI Research团队提出的,,包括wav2vec、vq-wav2vec、wav2vec2.0,效仿nlp上的word2vec,是语音的一种通用特征提取器。模型结构如图:
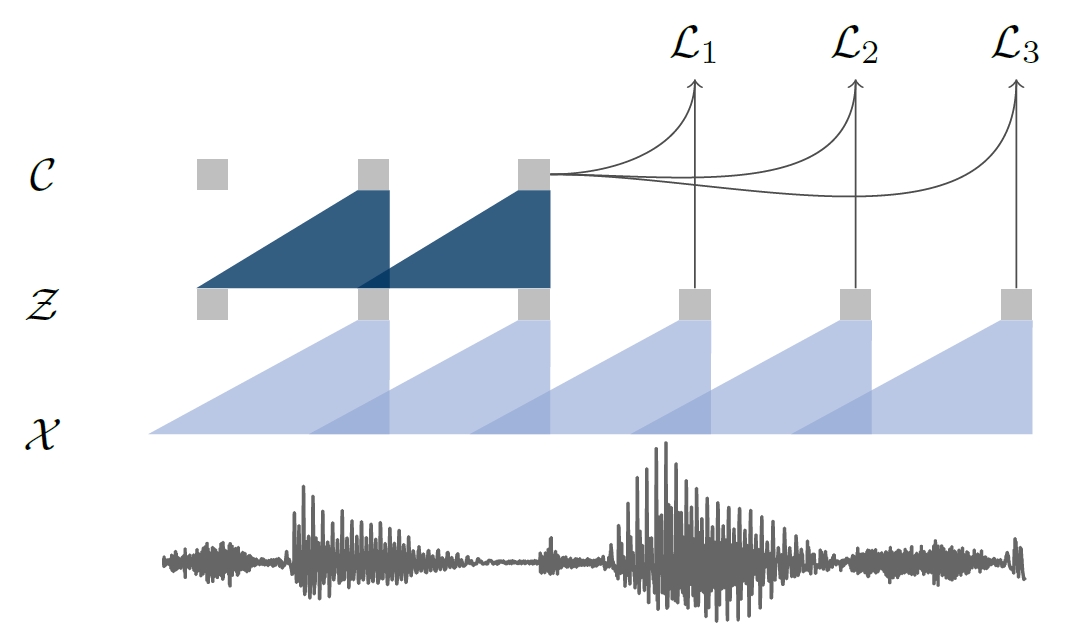
## 算法原理
模型包含两部分,分别是将原始音频x编码为潜在空间z的 encoder network(默认为5层卷积),和将z转换为深层特征的的 context network(默认为9层卷积),最终特征维度为512*帧数,
## 环境配置
### Docker(方法一)
此处提供[光源](https://sourcefind.cn/#/main-page)拉取镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal:ro --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd fairseq
pip3 install --editable ./
pip install soundfile
```
### Dockerfile(方法二)
此处提供dockerfile的使用方法:
```
cd ./docker
docker build --no-cache -t wav2vec:latest
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal:ro --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.sourcefind.cn/tool/
```
DTK软件栈:dtk24.04.1
Python:3.10
touch:2.1.0
torchvision:0.16.0
```
Tips:以上dtk软件栈、python、torch等DCU相关工具版本需要严格一一对应
## 数据集
在本模型的训练和测试使用的是LibriSpeech数据集:
- 官方下载链接:
- [LibriSpeech_asr数据集官方下载](https://www.openslr.org/12)
librisspeech是大约1000小时的16kHz英语阅读演讲语料库,数据来源于LibriVox项目的有声读物,并经过仔细分割和整理,其中的音频文件以flac格式存储,语音对应的文本转炉内容以txt格式存储。
数据集的目录结构如下:
```
LibriSpeech
├── train-clean-100
│ ├── 19
│ │ ├── 19-198
│ │ │ ├── 19-198-0000.flac
│ │ │ ├── 19-198-0001.flac
│ │ │ ├── 19-198-0002.flac
│ │ │ ├── 19-198-0003.flac
│ │ │ ├── ...
│ │ │ ├── 19-198.trans.txt
│ │ └── ...
│ └── ...
├── train-clean-360
├── train-other-500
├── dev-clean
├── dev-other
├── test-clean
└── test-othe
```
项目提供了一些小数据集供用户测试,所在文件夹为:```dataset/test-clean```。
## 训练
首先准备包含用于训练的wav文件或者flac文件的目录。
- 生成准备训练数据的清单(manifest)
```
cd ./fairseq/
python examples/wav2vec/wav2vec_manifest.py /path/to/waves --dest /manifest/path --ext flac
```
- 训练 wav2vec 模型
```
python fairseq/train.py manifest/path --save-dir model-save/ --num-workers 6 --fp16 --max-update 400000 --save-interval 1 --no-epoch-checkpoints \
--arch wav2vec --task audio_pretraining --lr 1e-06 --min-lr 1e-09 --optimizer adam --max-lr 0.005 --lr-scheduler cosine \
--conv-feature-layers "[(512, 10, 5), (512, 8, 4), (512, 4, 2), (512, 4, 2), (512, 4, 2), (512, 1, 1), (512, 1, 1)]" \
--conv-aggregator-layers "[(512, 2, 1), (512, 3, 1), (512, 4, 1), (512, 5, 1), (512, 6, 1), (512, 7, 1), (512, 8, 1), (512, 9, 1), (512, 10, 1), (512, 11, 1), (512, 12, 1), (512, 13, 1)]" \
--skip-connections-agg --residual-scale 0.5 --log-compression --warmup-updates 500 --warmup-init-lr 1e-07 --criterion wav2vec --num-negatives 10 \
--max-sample-size 150000 --max-tokens 1500000 --skip-invalid-size-inputs-valid-test
```
- HIP_VISIBLE_DEVICES:用于训练的卡的序号
- --device-id:用于设置训练所需的卡的数量通过搭配HIP_VISIBLE_DEVICES实现单卡/多卡训练。
- 若遇到 Error: argument --batch-size: invalid Optional value: ,则解决办法为直接到定义--batch-size和--max-tokens的地方,将其类型改为 int (原本为Optional[int],这个在较高的python版本上不支持),或者降低python版本。
### result
成功运行则会在终端输出类似如下信息。
## 推理
### 对语音文件进行特征提取
首先安装h5py用于读取模型文件:
```
pip install h5py
```
```
PYTHONPATH=/path/to/fairseq python examples/wav2vec/wav2vec_featurize.py --input path/to/task/waves --ext flac --output /path/to/output \
--model /model/path/checkpoint_best.pt --split dir1 dir2
```
Tips:
- --split 参数设置的数量理论上无上限(dir1、dir2至dirn)。
- 上述参数的 --input 和 --split 的dir1、dir2等组合起来应该是.flac的语音文件所在文件夹。即.flac的语音文件位于path/to/task/waves/dir1中。
- 若是.wav文件则 --ext设置为 wav
### result:
程序成功运行则应在终端输出类似如下信息:
可从本项目的data文件夹下查看示例文件。
- 输入文件 ./datasets/LibriSpeech/dev-clean/84/121123/84-121123-0000.flac
- 输出 path/to/output/84-121123-0000.h5context
### 精度
无
## 应用场景
### 算法分类
语音特征提取
### 热点应用行业
语音识别、教育、医疗
## 源码仓库及问题反馈
https://developer.sourcefind.cn/codes/modelzoo/wav2vec_pytorch
## 参考资料
https://github.com/facebookresearch/fairseq/tree/main/examples/wav2vec