
wan2.2
parents
Showing
INSTALL.md
0 → 100644
LICENSE.txt
0 → 100644
Makefile
0 → 100644
README.md
0 → 100644
README_origin.md
0 → 100644
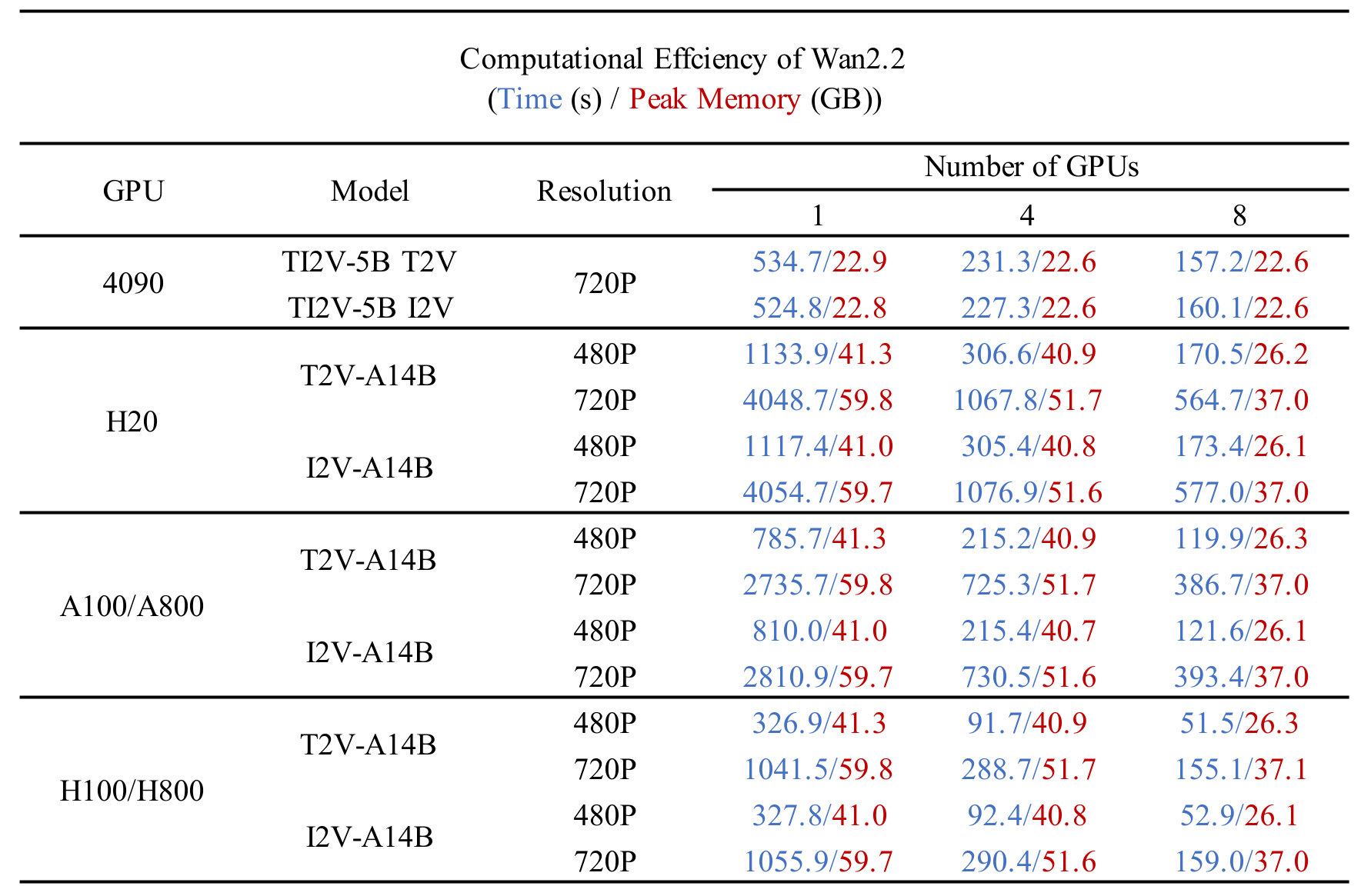
assets/comp_effic.png
0 → 100644
{kind=link}
197 KB
assets/logo.png
0 → 100644
{kind=link}
55 KB
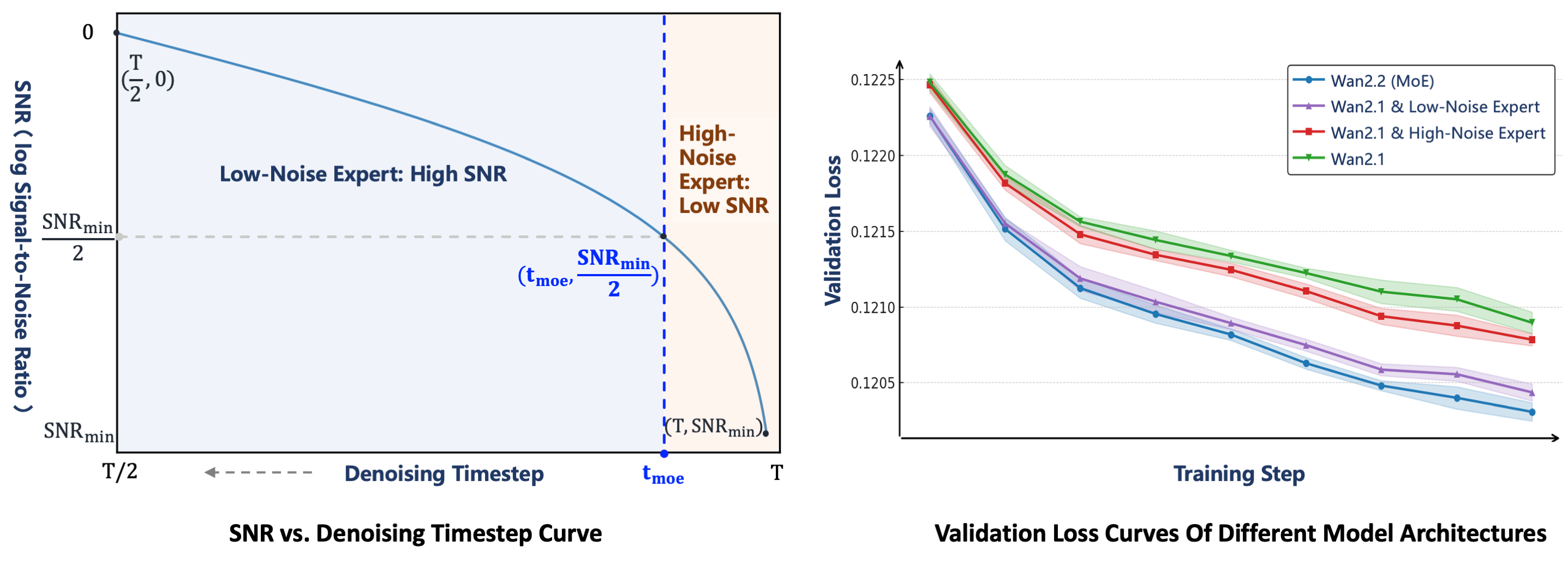
assets/moe_2.png
0 → 100644
{kind=link}
516 KB
assets/moe_arch.png
0 → 100644
{kind=link}

73.1 KB
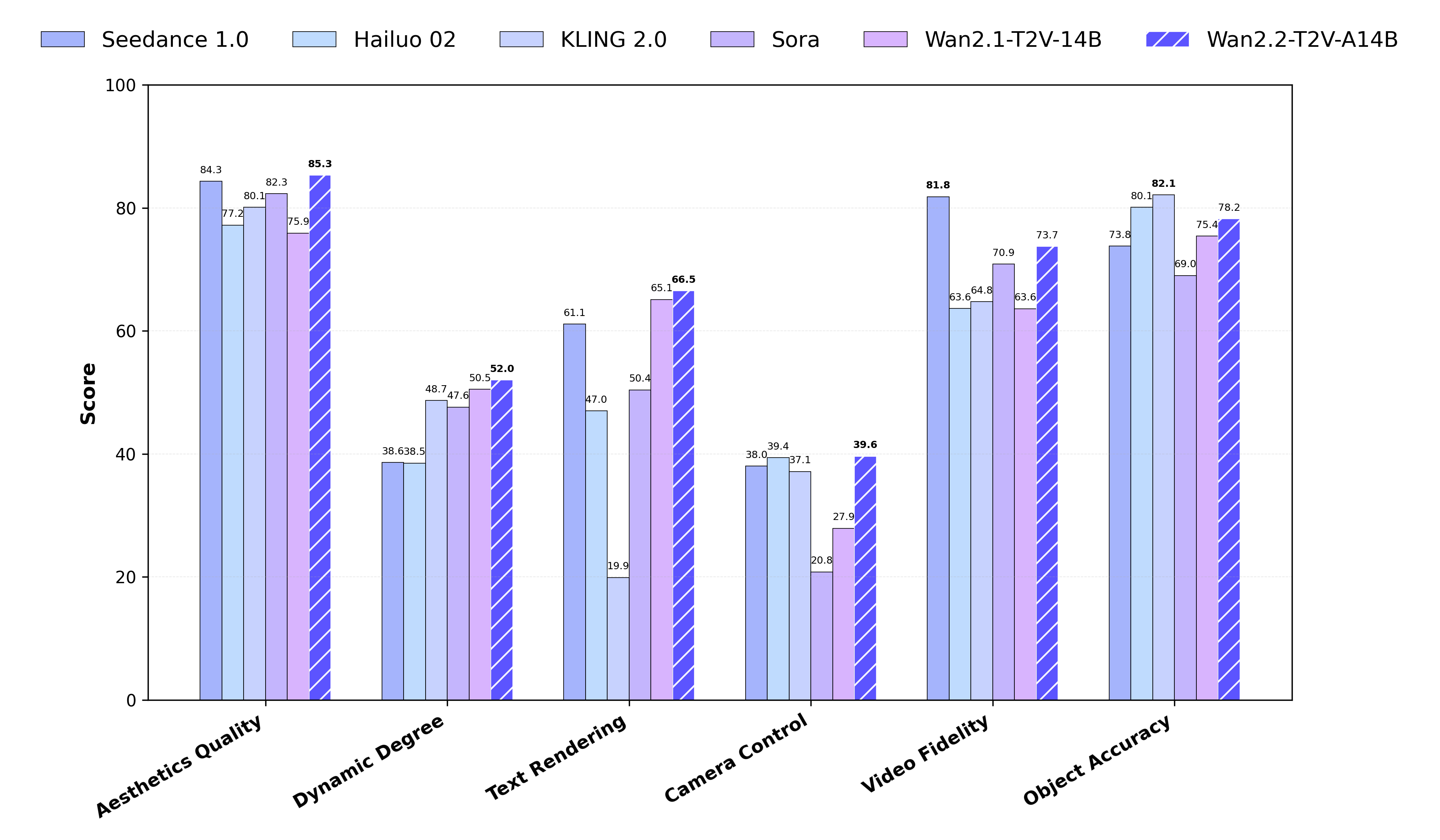
assets/performance.png
0 → 100644
{kind=link}
299 KB
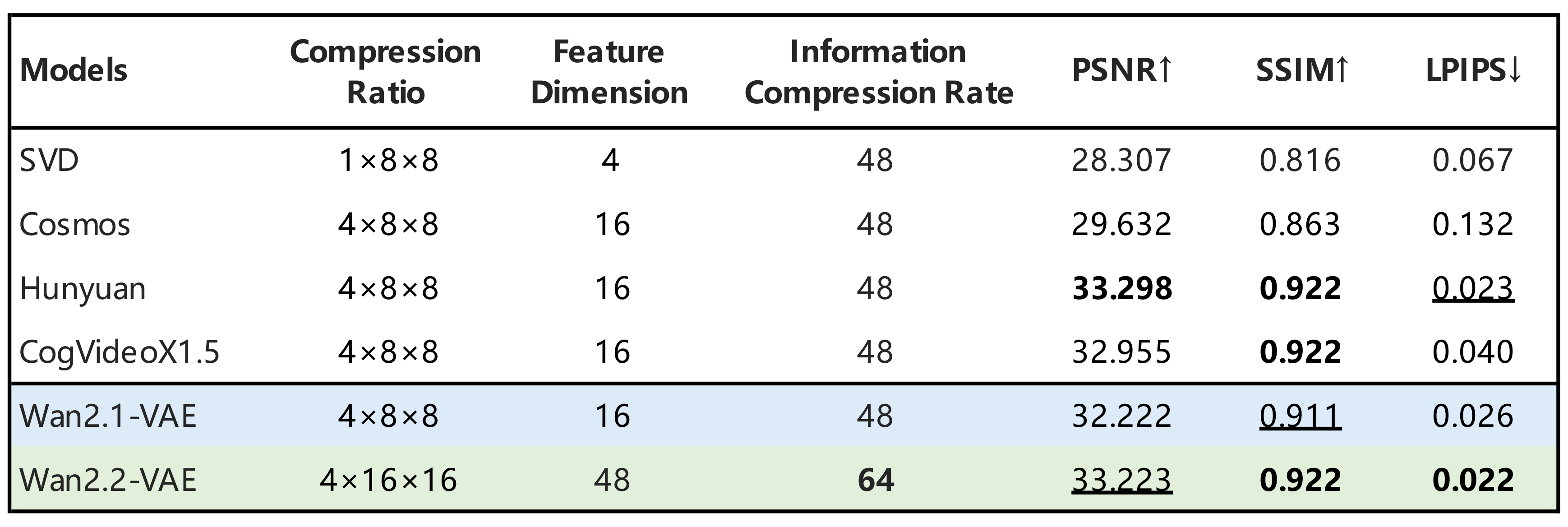
assets/vae.png
0 → 100644
{kind=link}
162 KB
doc/arch.png
0 → 100644
{kind=link}
100 KB
File added
File added
File added
{kind=link}

858 KB
examples/i2v_input.JPG
0 → 100644
{kind=link}

245 KB
examples/my.jpg
0 → 100644
{kind=link}

160 KB
examples/pose.mp4
0 → 100644
File added
examples/pose.png
0 → 100644
{kind=link}

803 KB