# VTimeLLM
## 论文
`VTimeLLM: Empower LLM to Grasp Video Moments`
- https://arxiv.org/abs/2311.18445
## 模型结构
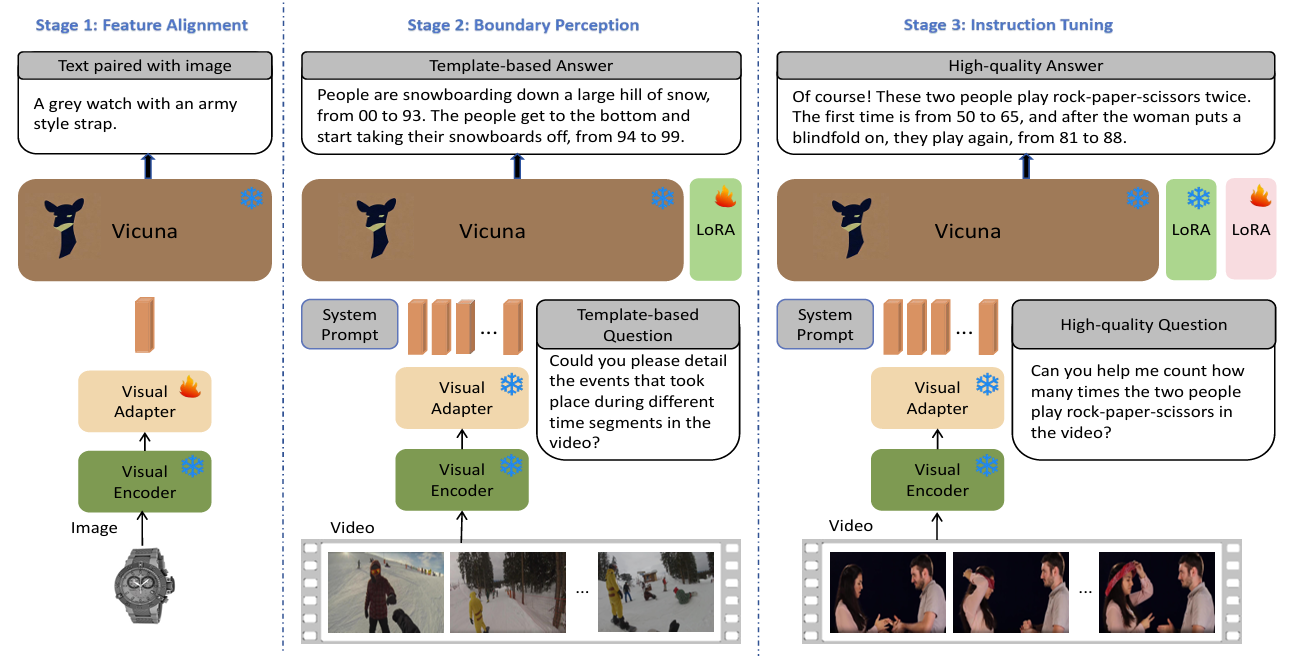
VTimeLLM有以下两个部分组成:1、一个视觉编码器和一个视觉适配器来处理输入视频;2、 一个特制的LLM过三阶段预训练来使模型同时具有grounding和chat能力
阶段一:图文对齐,通过图片-文本对训练将视觉特征与LLM在语义空间对齐;
阶段二:设计了密集Video Caption的单轮QA任务和包括片段描述&时序grounding的多轮的QA任务,使VTimeLLM具有时序感知的能力,可以定位视频的segmentation;
阶段三:创造了一个高质量的对话数据集来指令微调,来和人类意图对齐。
## 算法原理
Visual Encoder:利用CLIP ViT-L/14模型对每一帧获取cls token的feature和每个patch的feature,其中采用cls token的特征v_cls作为图片的feature
Visual Adapter:一个线性层,对每一帧的v_cls做变换,映射到LLM空间,最后视频由N*d的特征Z表示(N为帧数,d为LLM的隐层维度),这里均匀采样100帧
Vicuna:即LLM,用