# VITA
VITA能够处理视频、图像、文本和音频,具备先进的多模态交互体验,无需使用唤醒词或按钮即可被激活。
## 论文
`VITA: Towards Open-Source Interactive Omni Multimodal LLM`
- https://arxiv.org/pdf/2408.05211
## 模型结构
VITA提取特征的主体部分是Mixtral 8×7B,外加多个分别编码音频、图像、视频的编码器,编码器与Mixtral之间用MLP进行连接。
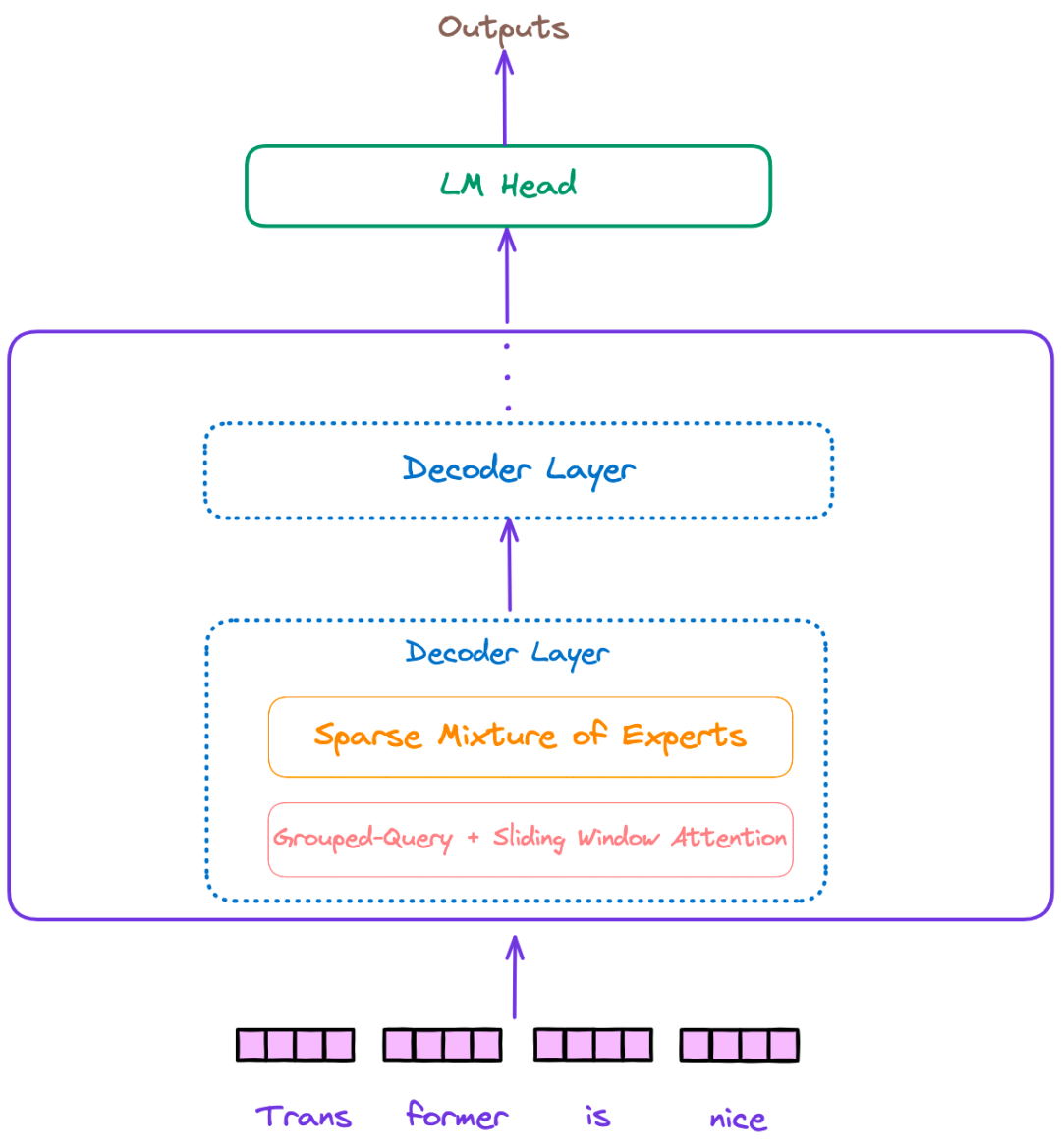
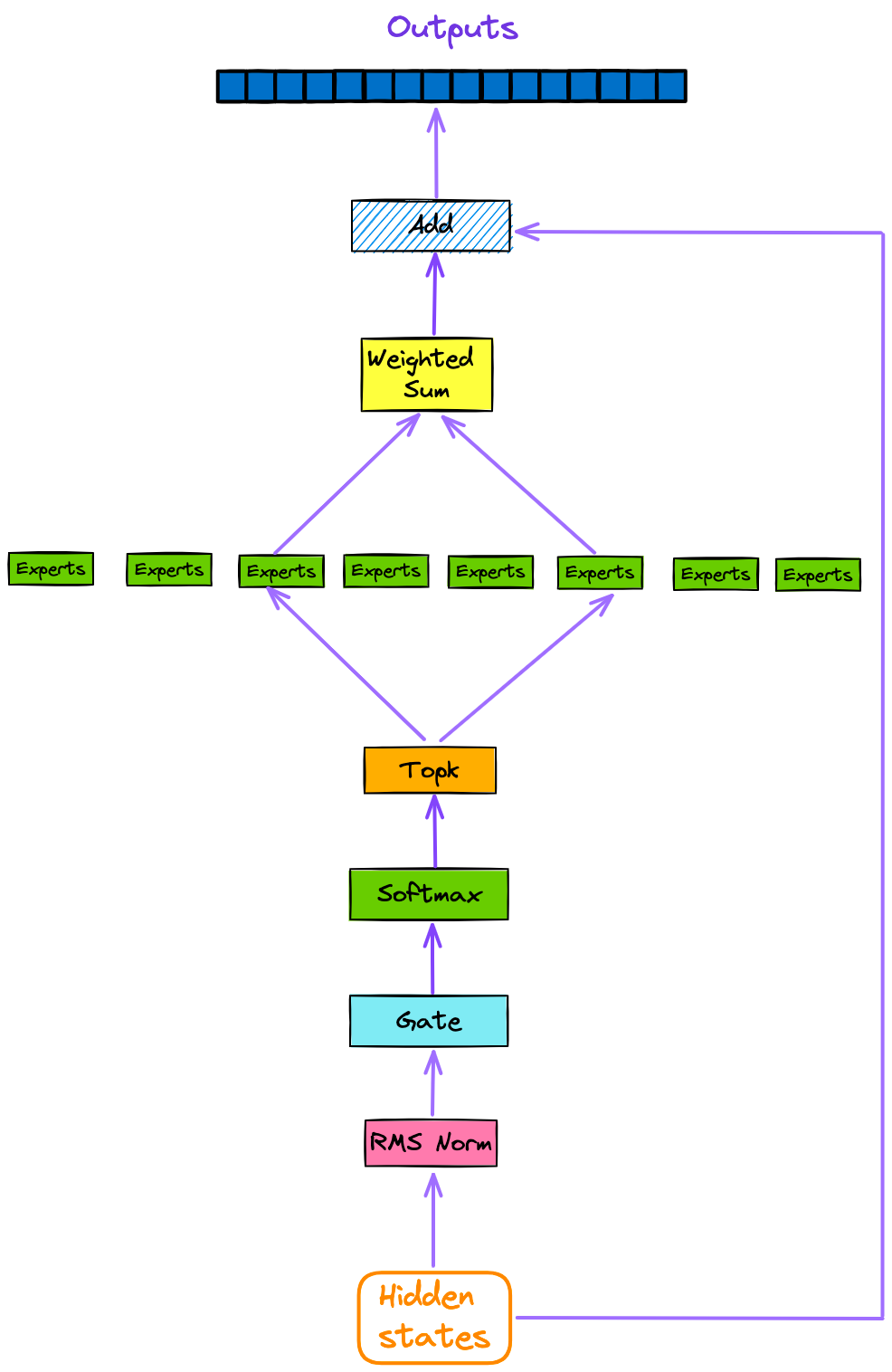
Mixtral 8×7B与llama不同的主要地方是SMoE。
## 算法原理
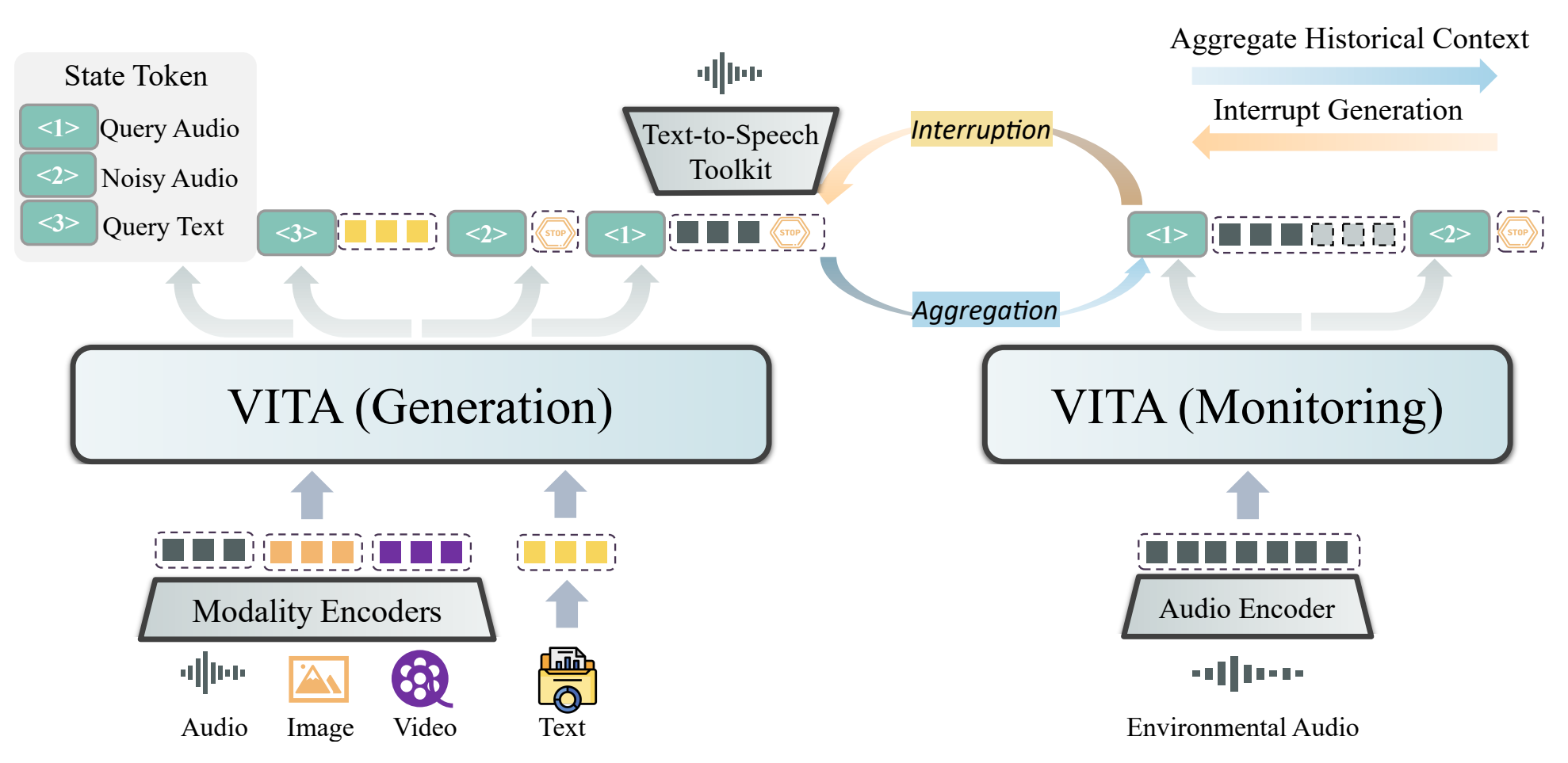
VITA以文本模态为基础无缝集成音频、图像、视频三种模态,主要采用方法是用微调实现文本与其它模态对齐,实现主要包括三个步骤:LLM的双语指令微调、多模态对齐和指令微调,联合pipeline开发。
## 环境配置
```
mv vita_pytorch VITA # 去框架名后缀
```
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-ubuntu22.04-dtk24.04.2-py3.10
# 为以上拉取的docker的镜像ID替换,本镜像为:83714c19d308
docker run -it --shm-size=64G -v $PWD/VITA:/home/VITA -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name vita bash
cd /home/VITA
pip install -r requirements.txt # requirements.txt
# 安装torchaudio读取音频所需的ffmpeg-4.4.4
sh ffmpeg_env.sh
# 安装gradio
pip install gradio==5.4.0 # gradio
cp -r frpc_linux_amd64 /usr/local/lib/python3.10/site-packages/gradio/frpc_linux_amd64_v0.3
chmod +x /usr/local/lib/python3.10/site-packages/gradio/frpc_linux_amd64_v0.3
```
### Dockerfile(方法二)
```
cd VITA/docker
docker build --no-cache -t vita:latest .
docker run --shm-size=64G --name vita -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v $PWD/../../VITA:/home/VITA -it vita bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt。
cd /home/VITA
# 安装torchaudio读取音频所需的ffmpeg-4.4.4
sh ffmpeg_env.sh
# 安装gradio
pip install gradio==5.4.0 # gradio
cp -r frpc_linux_amd64 /usr/local/lib/python3.10/site-packages/gradio/frpc_linux_amd64_v0.3
chmod +x /usr/local/lib/python3.10/site-packages/gradio/frpc_linux_amd64_v0.3
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.sourcefind.cn/tool/
```
DTK驱动:dtk24.04.2
python:python3.10
torch:2.3.0
torchvision:0.18.1
torchaudio:2.1.2
triton:2.1.0
flash-attn:2.0.4
deepspeed:0.14.2
apex:1.3.0
xformers:0.0.25
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库参照requirements.txt安装
```
cd VITA
pip install -r requirements.txt # requirements.txt
# 安装torchaudio读取音频所需的ffmpeg-4.4.4
sh ffmpeg_env.sh
# 安装gradio
pip install gradio==5.4.0 # gradio
cp -r frpc_linux_amd64 /usr/local/lib/python3.10/site-packages/gradio/frpc_linux_amd64_v0.3
chmod +x /usr/local/lib/python3.10/site-packages/gradio/frpc_linux_amd64_v0.3
```
## 数据集
[ShareGPT4V](https://huggingface.co/datasets/Lin-Chen/ShareGPT4V)、[coco2017](https://cocodataset.org/#home)、[LLaVA-Pretrain](https://huggingface.co/datasets/liuhaotian/LLaVA-Pretrain)、`sam`、`web-celebrity`等为需要的公共数据集,其中,后面一些数据集可向论文作者咨询下载源,`自建数据集custom`为用户在自己应用场景微调需要自己制作的数据集,`input_wavs`为custom需要的音频文件,`input_imgs`为custom需要的图像文件,它们用于prompt,以上数据集皆不影响推理。
1、用户在自己应用场景微调所需数据集按如下方式制作json文件`custom.json`,json中的数据为多模态配对数据,其中set:`sharegpt4`是提示加载图像或视频数据的关键字。
```
[
...
{
"set": "sharegpt4",
"id": "000000000164",
"conversations": [
{
"from": "human",
"value": "\n