## 🔥 News
* **`2024.09.06`** 🌟 The training code, deployment code, and model weights **have been released**. Long wait!
* **`2024.08.12`** 🌟 We are very proud to launch VITA, the First-Ever open-source interactive omni multimodal LLM! We have submitted the open-source code, yet it is under review internally. We are moving the process forward as quickly as possible, stay tuned!
## Contents
- [VITA Overview](#-vita-overview)
- [Experimental Results](#-experimental-results)
- [Training](#-training)
- [Requirements and Installation](#requirements-and-installation)
- [Data Preparation](#data-preparation)
- [Continual Training](#continual-training)
- [Inference](#-inference)
- [Quick Start](#quick-start)
- [Demo](#demo)
- [Basic Demo](#-basic-demo)
- [Real-Time Interactive Demo](#-real-time-interactive-demo)
## 👀 VITA Overview
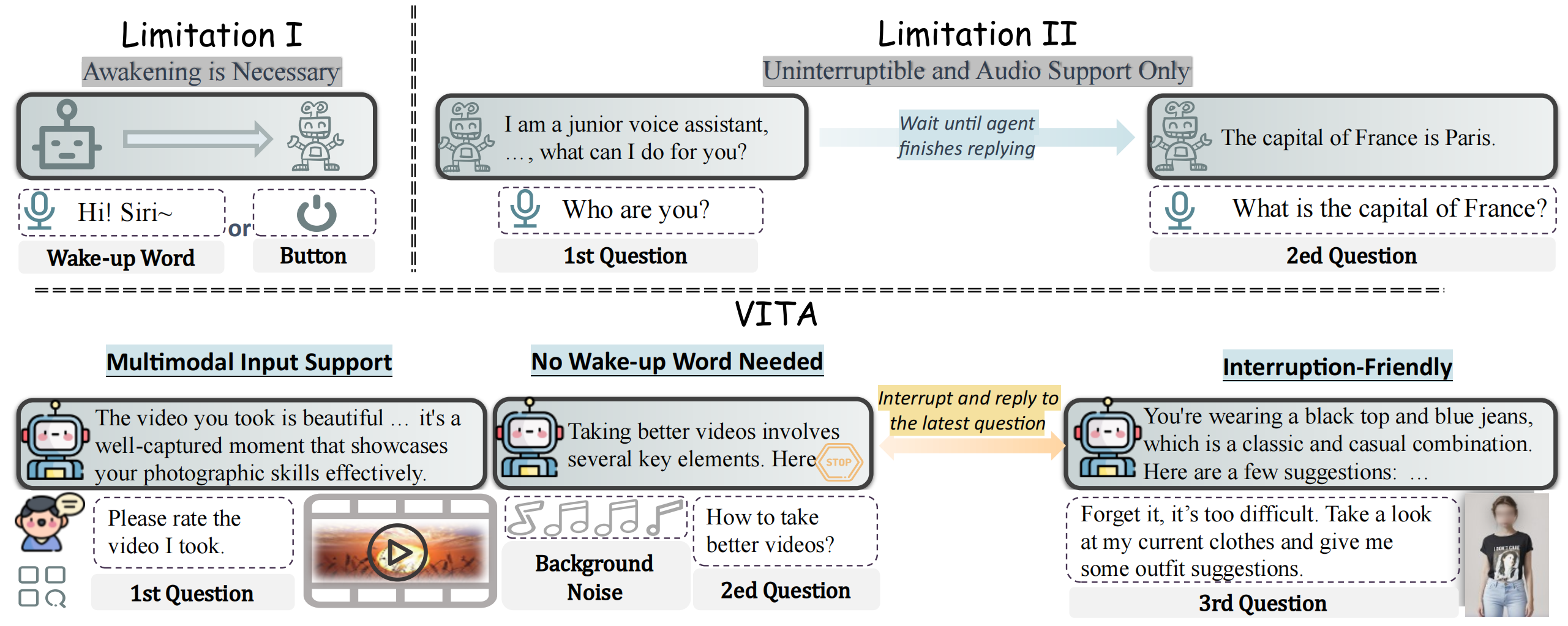
The remarkable multimodal capabilities and interactive experience of GPT-4o underscore their necessity in practical applications, yet open-source models rarely excel in both areas. In this paper, we introduce **VITA**, the first-ever open-source Multimodal Large Language Model (MLLM) adept at simultaneous processing and analysis of **V**ideo, **I**mage, **T**ext, and **A**udio modalities, and meanwhile has an advanced multimodal interactive experience. Our work distinguishes from existing open-source MLLM through **three key features**:
- **Omni Multimodal Understanding**. VITA demonstrates robust foundational capabilities of multilingual, vision, and audio understanding, as evidenced by its strong performance across a range of both unimodal and multimodal benchmarks.
- **Non-awakening Interaction**. VITA can be activated and respond to user audio questions in the environment without the need for a wake-up word or button.
- **Audio Interrupt Interaction**. VITA is able to simultaneously track and filter external queries in real-time. This allows users to interrupt the model's generation at any time with new questions, and VITA will respond to the new query accordingly.
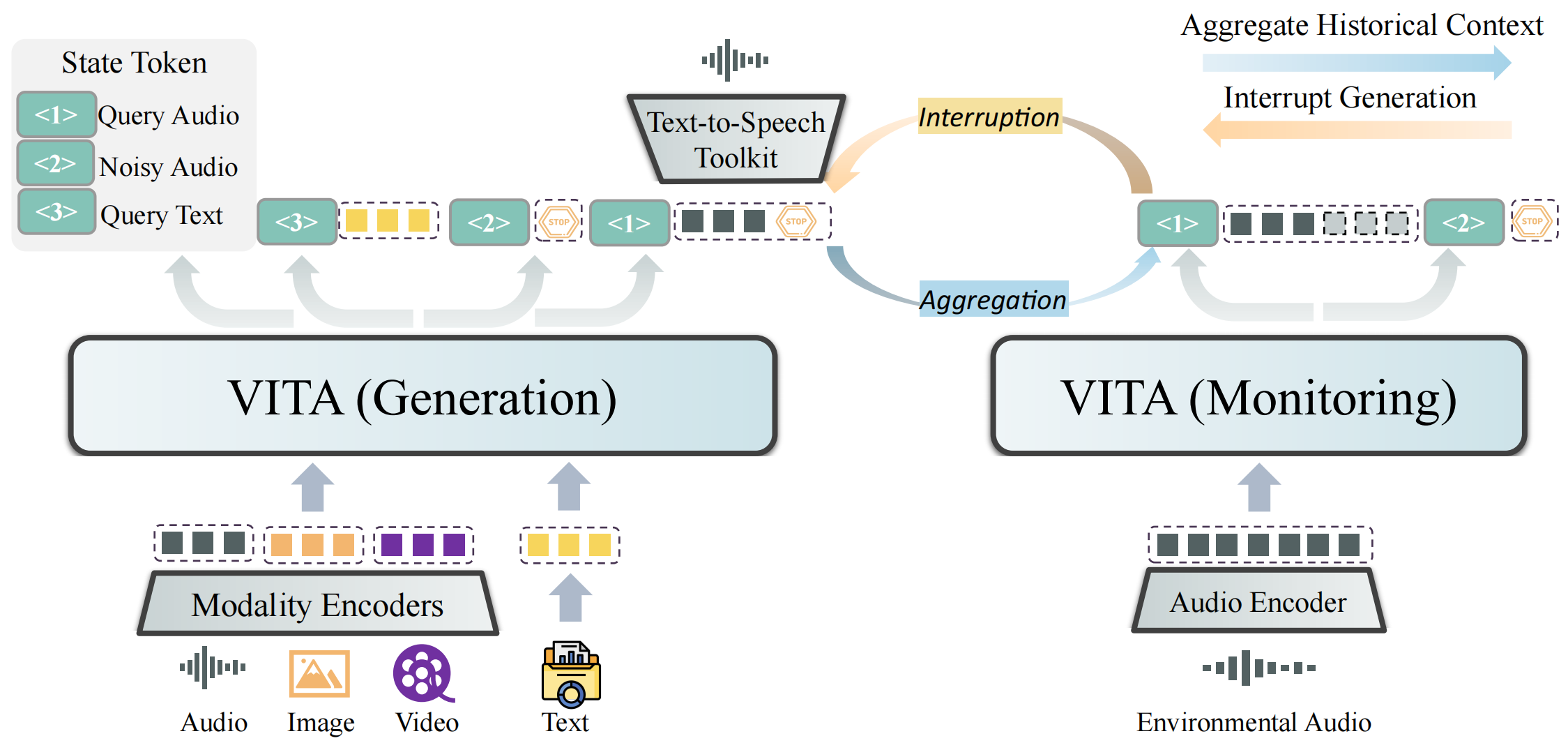
VITA is capable of processing inputs in the form of pure text/audio, as well as video/image combined with text/audio. Besides, two key techniques are adopted to advance the multimodal interactive experience:
- **State Token**. We set different state tokens for different query inputs. <1> corresponds to the effective query audio, such as “what is the biggest animal in the world?”, for which we expect a response from the model. <2> corresponds to the noisy audio, such as someone in the environment calls me to eat, for which we expect the model not to reply. <3> corresponds to the query text, i.e., the question given by the user in text form. During the training phase, we try to teach the model to automatically distinguish different input queries. During the deployment phase, with <2> we can implement non-awakening interaction.
- **Duplex Scheme**. We further introduce a duplex scheme for the audio interrupt interaction. Two models are running at the same time, where the generation model is responsible for handling user queries. When the generation model starts working, the other model monitors the environment. If the user interrupts with another effective audio query, the monitoring model aggregates the historical context to respond to the latest query, while the generation model is paused and tune to monitor, i.e., the two models swap identities.
## 📈 Experimental Results
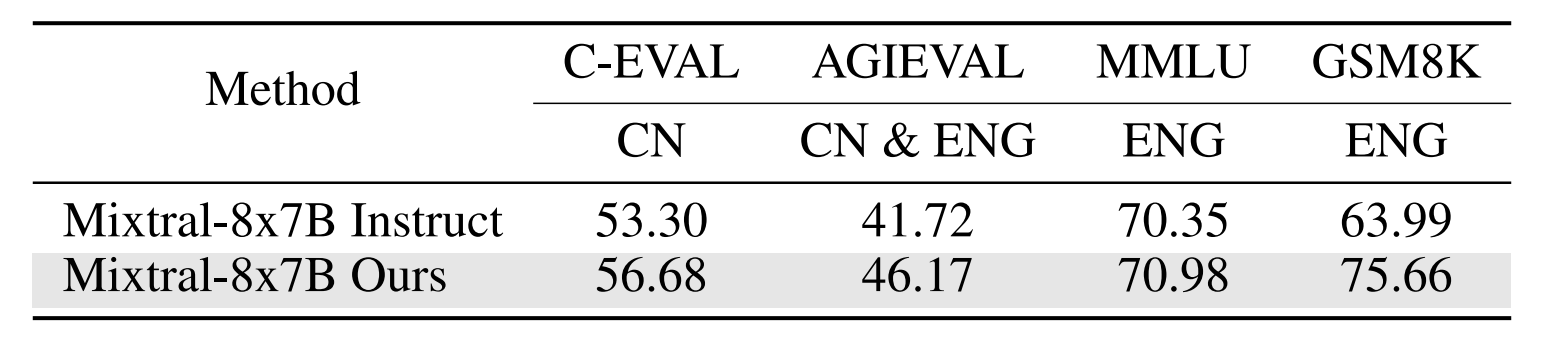
- **Comparison of official Mixtral 8x7B Instruct and our trained Mixtral 8x7B**.
- **Evaluation of Error Rate on ASR tasks.**
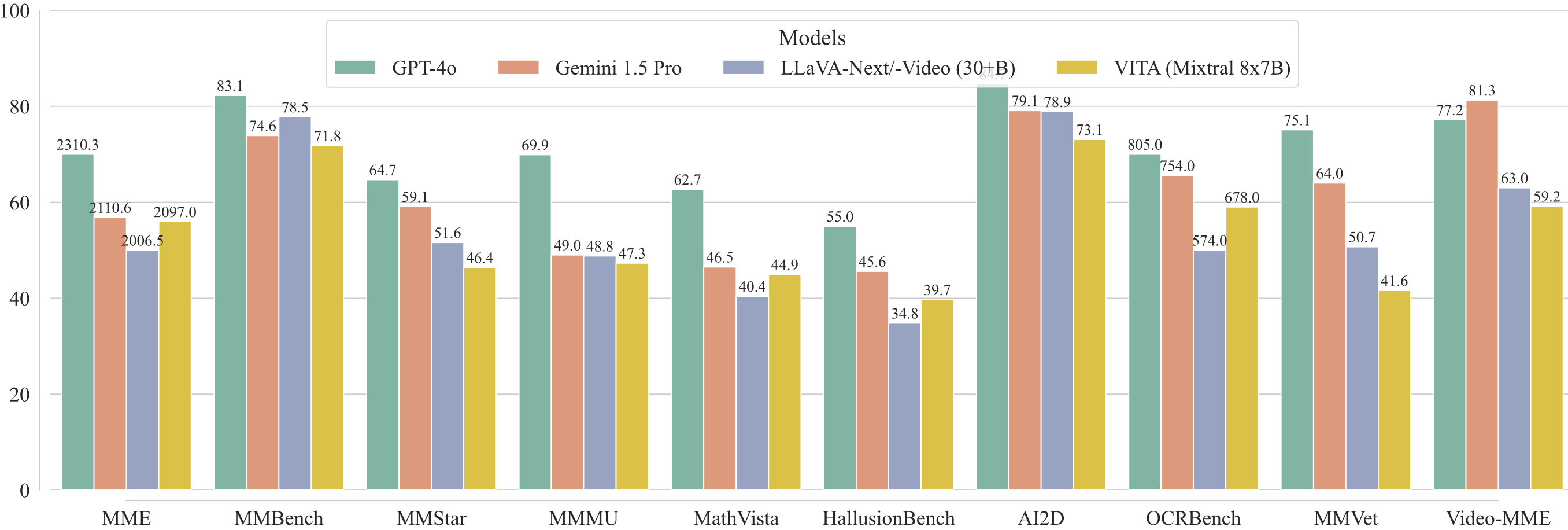
- **Evaluation on image and video understanding.**
## ⭐ Training
### Requirements and Installation
```
git clone https://github.com/VITA-MLLM/VITA
cd VITA
conda create -n vita python=3.10 -y
conda activate vita
pip install --upgrade pip
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
```
### Data Preparation
- An example json file of the training data:
```
[
...
{
"set": "sharegpt4",
"id": "000000000164",
"conversations": [
{
"from": "human",
"value": "\n