
v1.0
Showing
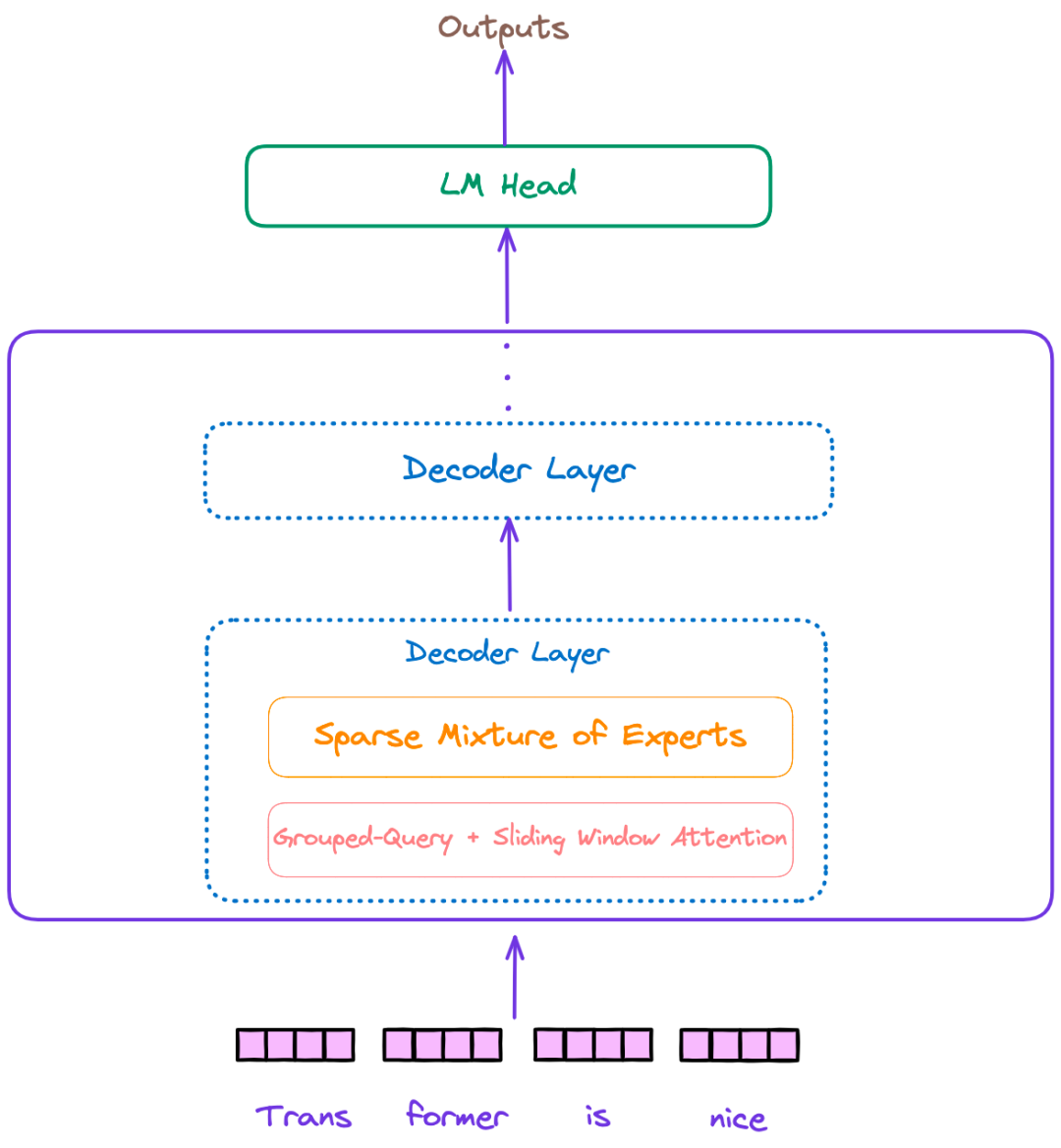
doc/Mixtral.png
0 → 100644
{kind=link}
123 KB
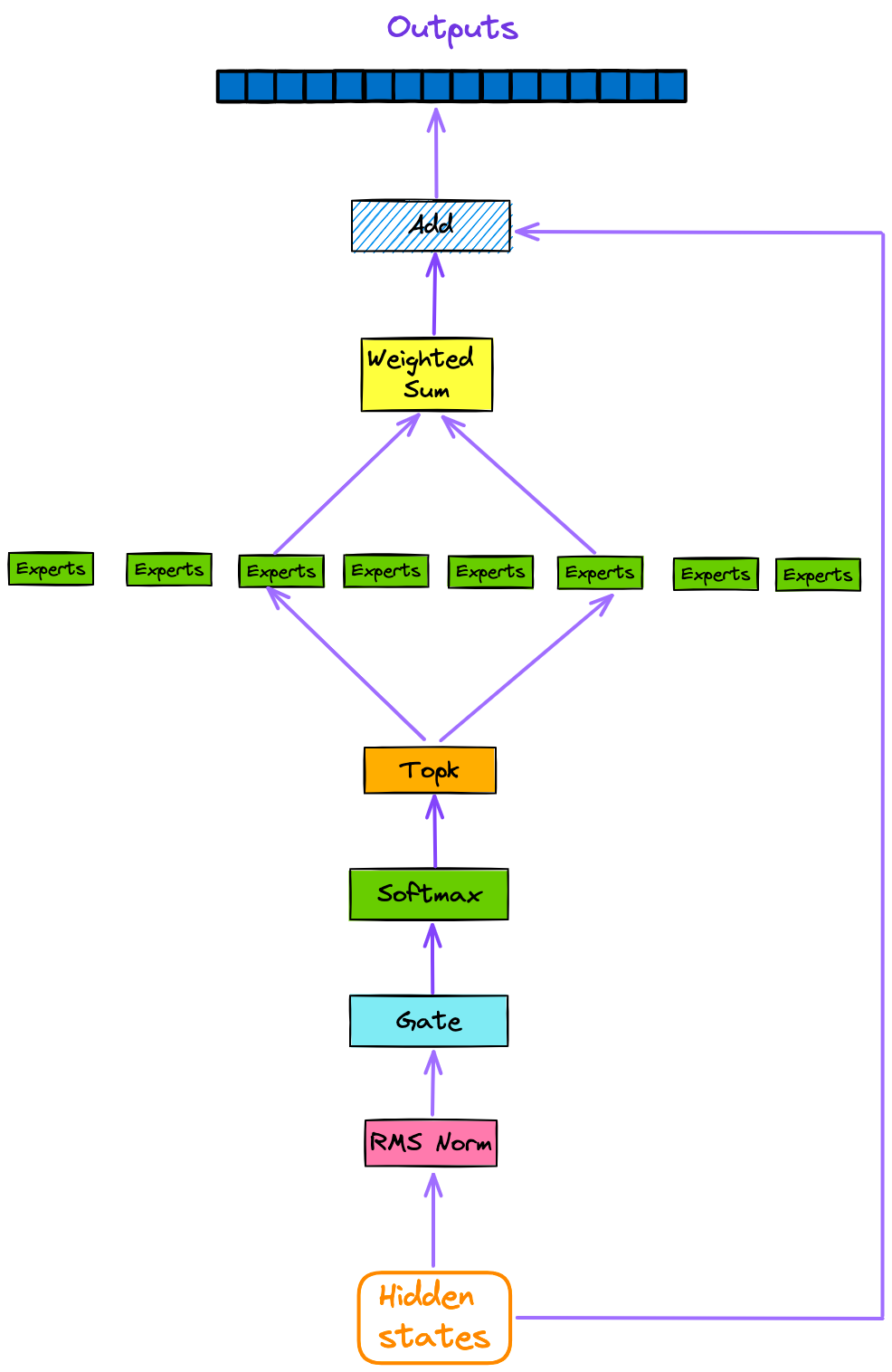
doc/SMoE.png
0 → 100644
{kind=link}
89.4 KB
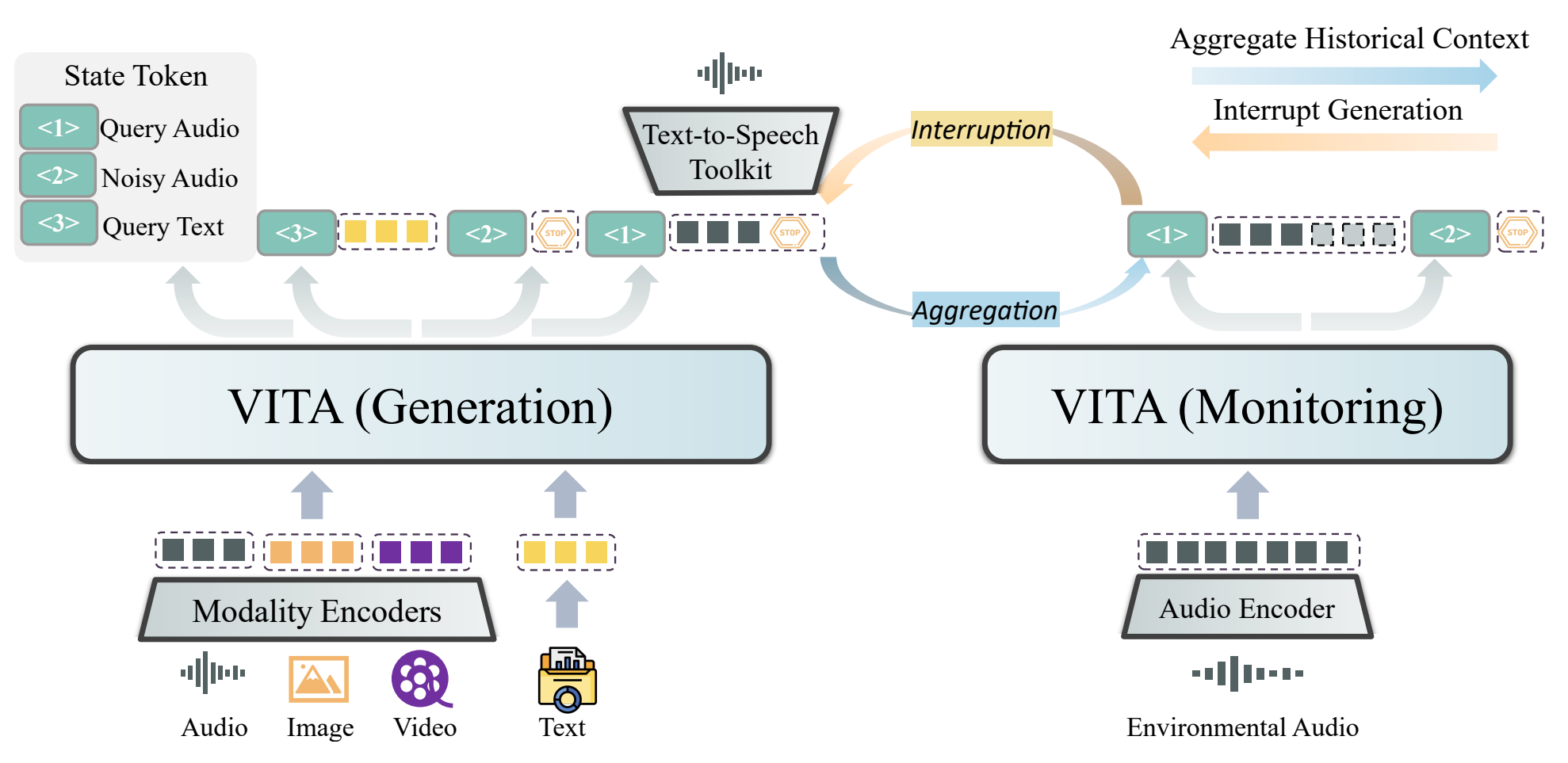
doc/vita.png
0 → 100644
{kind=link}
206 KB
docker/Dockerfile
0 → 100644
docker/requirements.txt
0 → 100644
icon.png
0 → 100644
{kind=link}
53.8 KB
infer.sh
0 → 100644
input_imgs/promp0.jpg
0 → 100644
{kind=link}
11.7 KB
input_wavs/audio/audio0.wav
0 → 100644
File added
input_wavs/promp0.wav
0 → 100644
File added
mixtral_decode.py
0 → 100644
mixtral_inference.py
0 → 100644
model.properties
0 → 100644
requirements.txt
0 → 100644
| accelerate==0.30.1 | ||
| decord==0.6.0 | ||
| #deepspeed==0.9.5 | ||
| Jinja2==3.1.4 | ||
| ninja==1.11.1.1 | ||
| numpy==1.26.4 | ||
| #torch==2.3.1 | ||
| #torchaudio==2.3.1 | ||
| #torchvision | ||
| tqdm==4.66.4 | ||
| transformers==4.41.1 | ||
| #xformers | ||
| timm | ||
| soundfile==0.12.1 |
script/deepspeed/zero2.json
0 → 100644