
v1.0
Showing
File added
VITA/util/s2wrapper/core.py
0 → 100644
VITA/util/s2wrapper/utils.py
0 → 100644
VITA/util/utils.py
0 → 100644
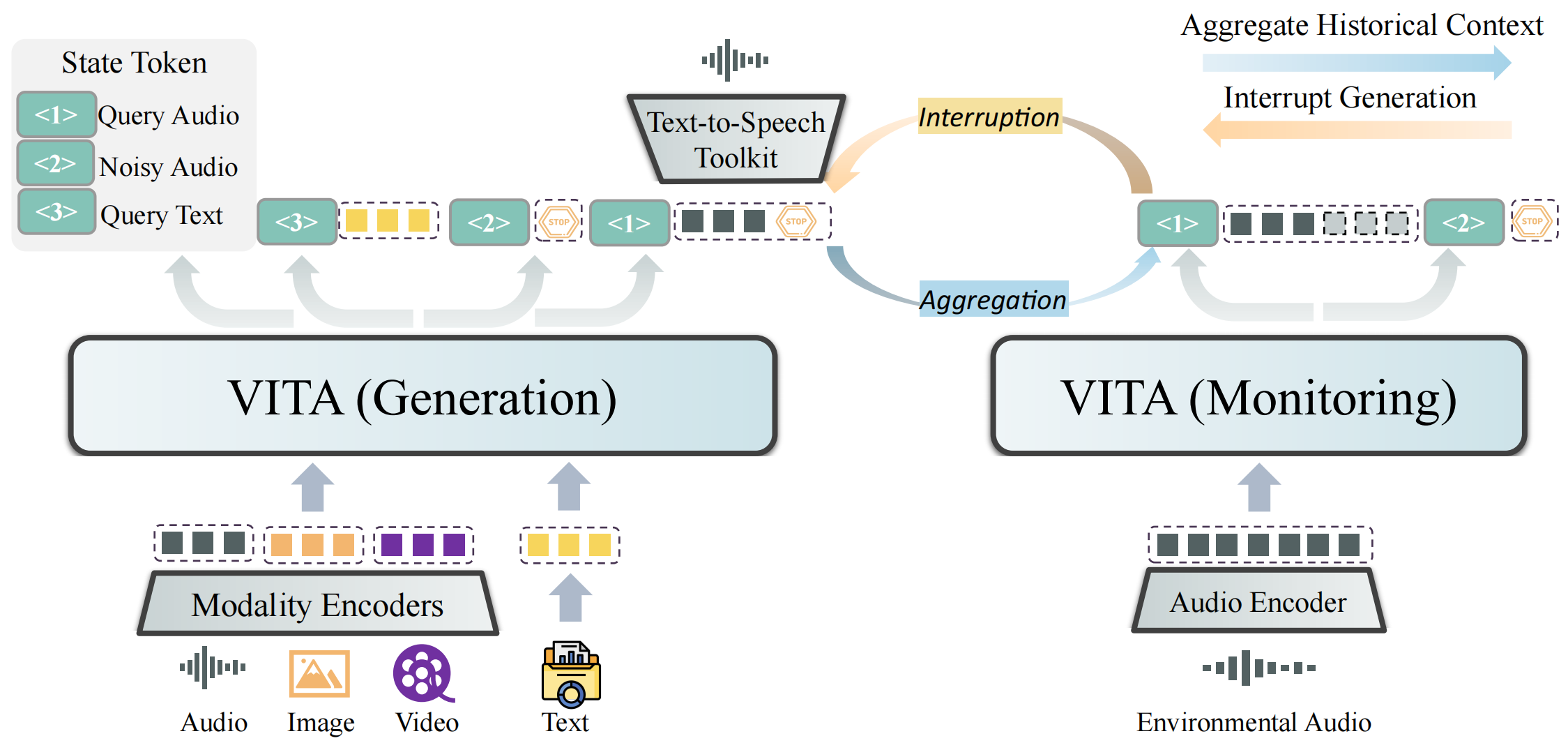
asset/VITA_duplex.png
0 → 100644
{kind=link}
318 KB
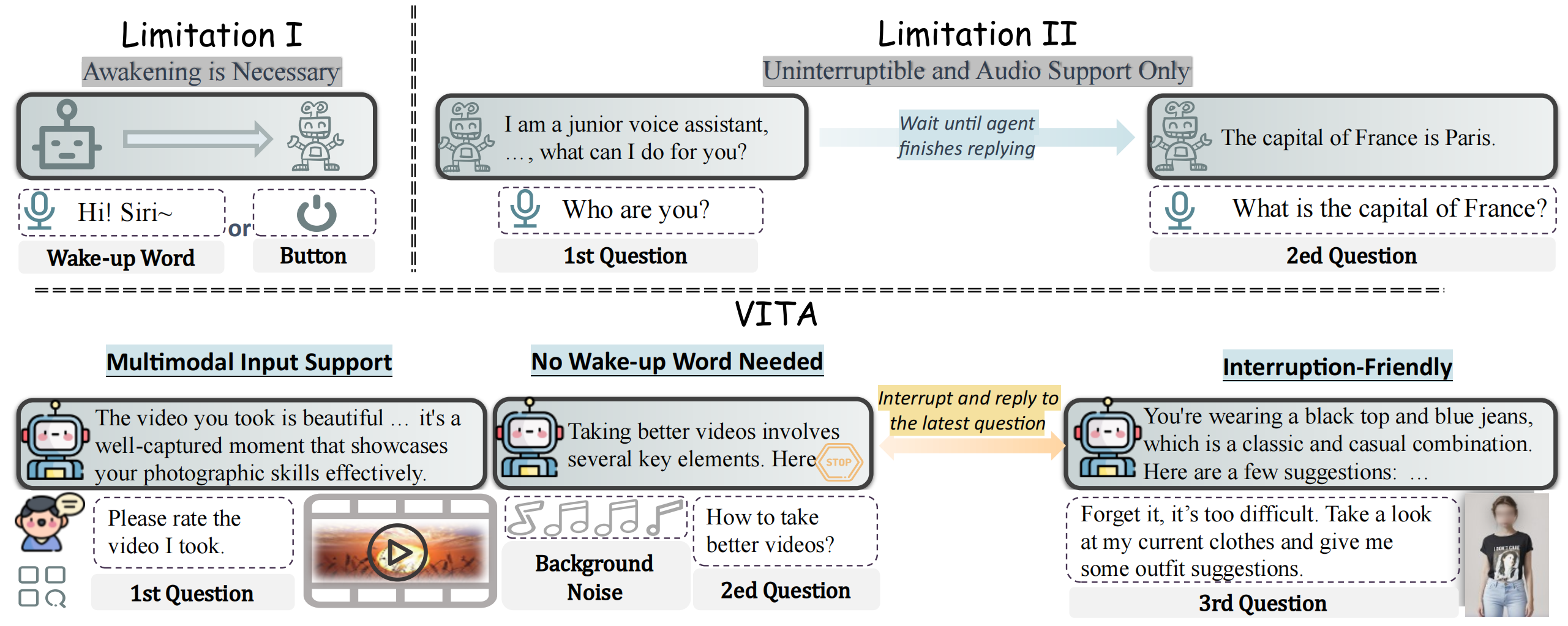
asset/VITA_features.png
0 → 100644
{kind=link}
731 KB
asset/audio_eval.jpg
0 → 100644
{kind=link}

78.3 KB
asset/demo1.jpg
0 → 100644
{kind=link}
178 KB
asset/demo2.jpg
0 → 100644
{kind=link}
63.9 KB
asset/demo_1.mp4
0 → 100644
File added
asset/language_eval.png
0 → 100644
{kind=link}

63.3 KB
asset/language_eval2.png
0 → 100644
{kind=link}
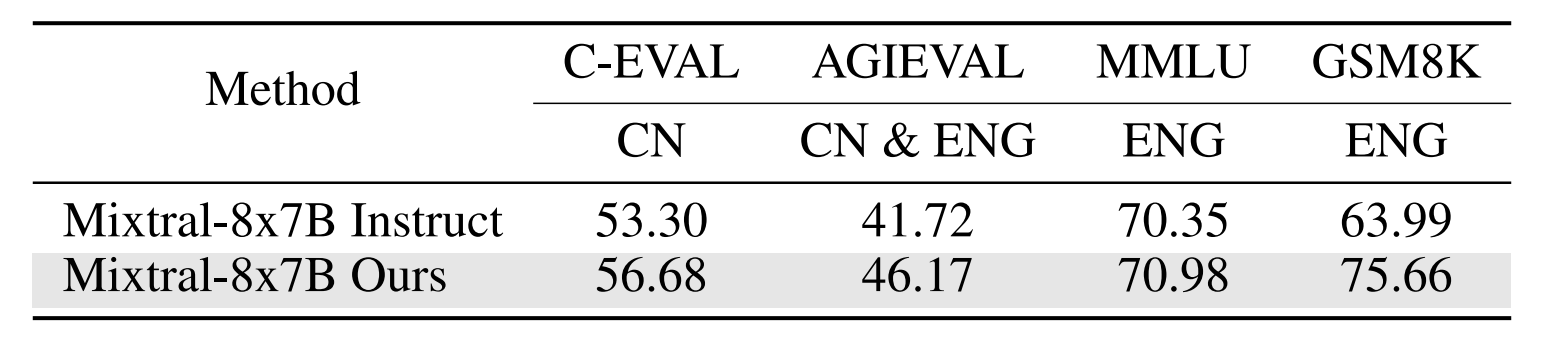
59.9 KB
asset/q1.wav
0 → 100644
File added
asset/q2.wav
0 → 100644
File added
asset/visual_eval.jpg
0 → 100644
{kind=link}
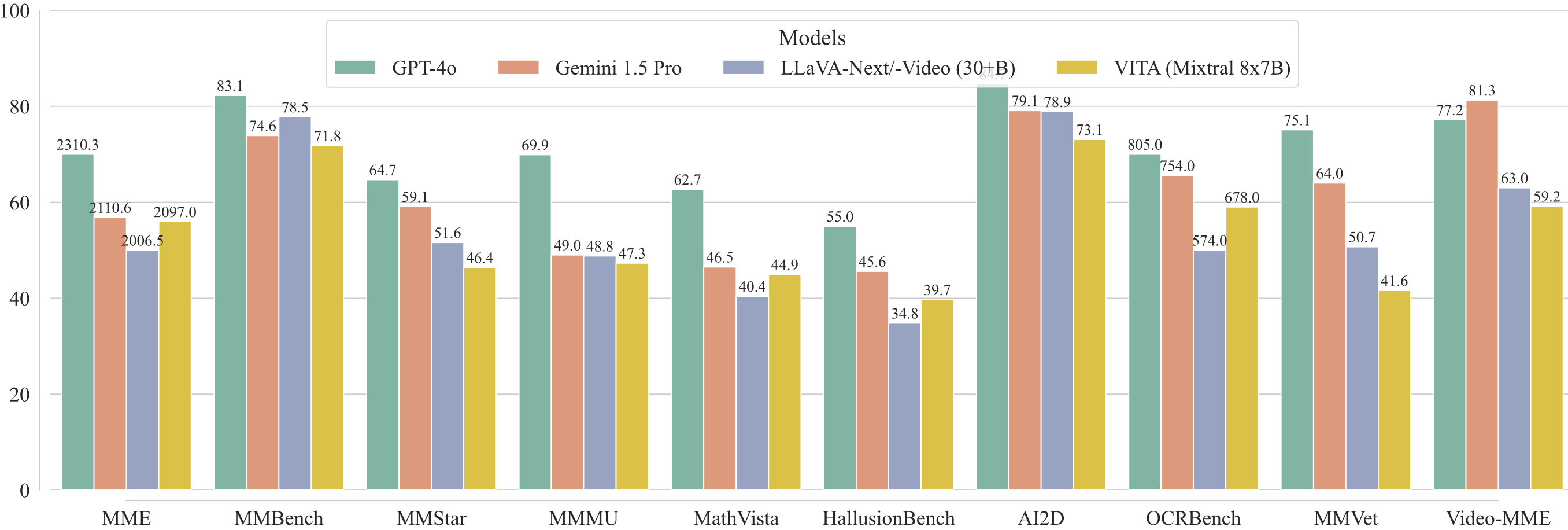
170 KB
asset/vita.png
0 → 100644
{kind=link}

2.22 MB
asset/vita_log2.png
0 → 100644
{kind=link}

98.5 KB
asset/wechat_4.jpg
0 → 100644
{kind=link}

148 KB
This source diff could not be displayed because it is too large. You can view the blob instead.
coco/README.md
0 → 100644